ICCV2019|基于Anchor point的手势及人体3D姿态估计方法A2J
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
本文转自CSDN,仅供学术交流,侵删,遵循 CC 4.0 BY-SA 版权协议
作者:zhangboshen
原文链接:https://blog.csdn.net/zhangboshen/article/details/100920779
论文:A2J: Anchor-to-Joint Regression Network for 3D Articulated Pose Estimation from a Single Depth Image
链接:https://arxiv.org/abs/1908.09999
GitHub(即将开源):https://github.com/zhangboshen/A2J
简介
这是ICCV 2019的一篇论文,文章主要解决的是基于单张深度图像的手势以及人体的3D姿态估计问题,我们首次提出了将经典目标检测的anchor的概念应用到姿态估计任务中来,设计了一种简洁有效的方法,最终在包括三个手势姿态估计数据集(HANDS2019,ICVL,NYU)以及两个人体姿态估计数据集(ITOP,K2HPD)上取得了state-of-the-art的效果。
Anchor-to-Joint
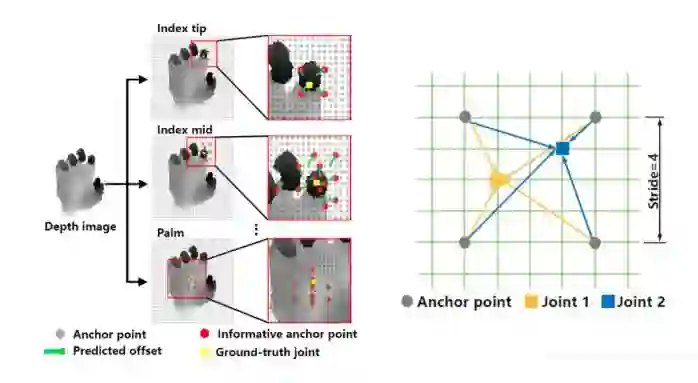
首先给出两张paper中的示意图。左图是我们技术方案的一个流程示意,对于一张给定的输入深度图片(这里假设输入仅包含单个手或人体,前面需要一个检测器的预处理步骤,类似于human pose的Top-down思路),我们密集的在图像上设立anchor point,如右图所示,每隔stride=4个像素点就会设立一个anchor point,最终的关节点预测将会通过这些anchor point去完成。具体而言,每个锚点需要针对所有关节点预测一个图像坐标下的偏移量(左图中的绿色箭头)以及一个深度值,最终的关节点坐标将由所有锚点加权投票得出(权重是可学习的,左图中红色的anchor point就是权重值比较大的点,我们称之为informative anchor point)。
技术实现
为了实现上面的思路,我们采取的技术流程如下图所示。Backbone我们在实验中主要基于ResNet50,也对比进行了其他的网络结构。输出包含三个分支,一个是图像坐标系下面的偏移量输出,一个是深度值输出,最后一个是对anchor point进行加权的anchor proposal分支输出。第三支的输出结果经过softmax之后直接乘在前面两支的输出结果上对anchor point投票进行权重赋值。
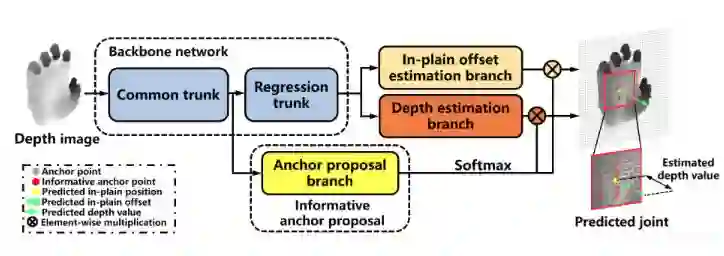
上面的技术方案有几个特点:
1)Anchor proposal分支可学习,对于不同的关节点,Informative anchor point的分布是不一样的,因此,A2J具有针对不同关节点的自适应性;
2)网络中不包含Deconv层,这里区别于目前主流的Heatmap的做法,不需要上采样使得我们的算法速度更快,结构更简单;
3)End-to-end training,我们最终的loss来自于anchor point加权投票之后的预测输出以及GT之间的差异,不需要对GT进行任何形式的变换。
4)快。网络结构简单,前向推理的速度很快,我们在NVIDIA 1080Ti的实测速度超过100fps。
网络结构
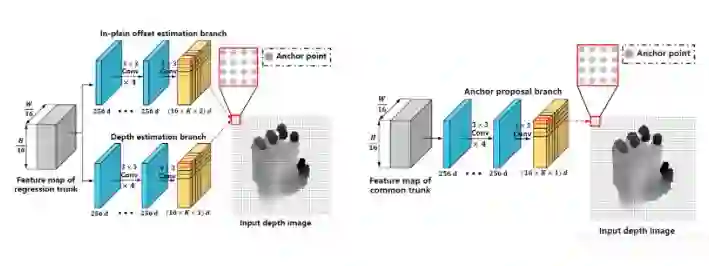
上面提到Backbone基于ResNet来提取特征,事实上我们对ResNet的结构进行了一些小的调整,使得最终编码得到的特征是经过16倍下采样的(而不是32倍)。对于三个输出分支,我们的结构选择如下所示,即4个3×3的卷积就直接进行输出。最终的输出是对于每一个anchor point都会有上面提到的offset、depth以及置信度输出。
损失函数
对于损失函数的选择,我们使用SmoothL1作为距离衡量标准,最终的损失包括loss1和loss2两项,loss1用于衡量预测值与GT之间的差异:
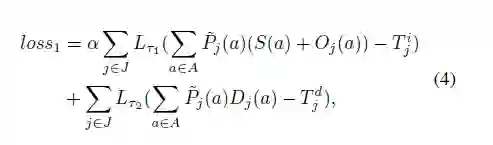
loss2我们称之为Informative anchor point surrounding loss,这个loss的意义在于控制Informative anchor point的空间分布,我们希望最终的Informative anchor point可以从关节点的各个角度去观察预测,进而加以下面的约束:
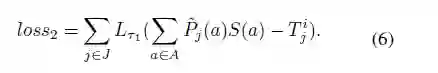
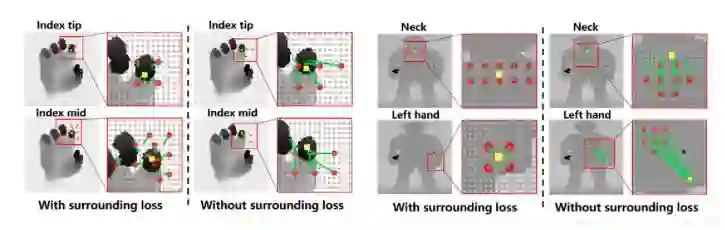
loss2实际是上是一个正则项,可以有效地缓解过拟合现象,最终的效果也非常显著,如下图所示,有无loss2的时候Informative anchor point的位置分布差异很大:
实验
实验部分我们在包括三个手势姿态估计数据集(HANDS2019,ICVL,NYU)以及两个人体姿态估计数据集(ITOP,K2HPD)上进行,最终的结果都已经达到或接近了现在的state-of-the-art。
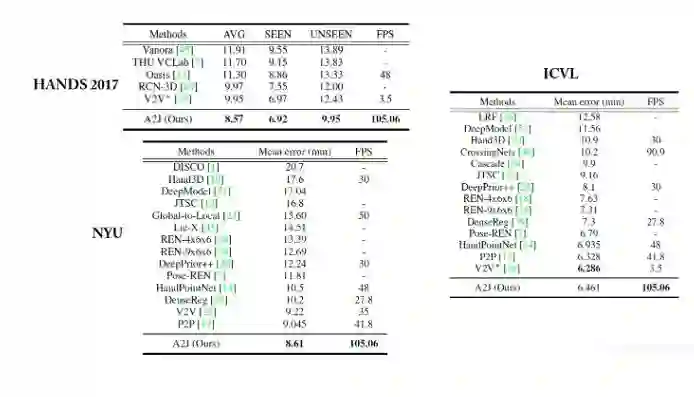
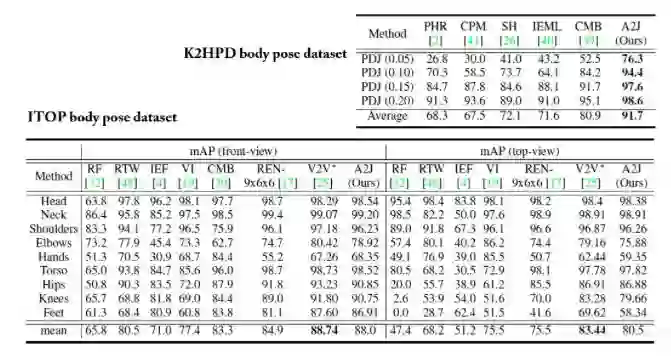
Ablation study依次验证了我们对于每一个component的选择的有效性(详细结果请参见我们的论文)。
总结
我们的工作创新点在于以一种简单的方式来使得anchor point的概念在姿态估计这个任务上得以实现。方法简单有效。A2J区别于现在主流的基于Heatmap的2D人体姿态估计方法以及手势3D姿态估计的方法(3D CNN,PointNet),拥有以上提到的许多优点。同时,A2J可以很容易的拓展到许多类似的任务中去,比如基于RGB图的2D/3D人体以及手势的姿态估计。此外,A2J的速度优势明显,未来可以考虑应用到一些耗时要求较高的嵌入式设备中。
-End-
*延伸阅读
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台
觉得有用麻烦给个在看啦~




