【AAAI2018】基于注意力机制的交易上下文感知推荐,悉尼科技大学和电子科技大学最新工作
【导读】注意力机制近年来开始被广泛应用,从最初用于自然语言处理领域的机器翻译等任务,延伸到图像处理以及推荐系统中。由于attention可以建模上下文不同元素的重要性,在序列建模问题上卓有成效。本文提出了一种基于注意力机制的交易数据上下文嵌入方法,实验证明模型在真实世界数据上有效。
【论文】Attention-based Transactional Context Embedding for Next-Item Recommendation

▌摘要
在交易上下文中向用户推荐下一项(item)是切实可行的,但在市场营销等应用中具有挑战性。交易上下文是指在交易中可观察到的项,大多数现有的基于交易数据的推荐系统(TBRS)进行推荐时,主要考虑的是最近发生的项目,而不是当前上下文中观察到的所有项目。此外,它们通常假设交易中的项之间存在严格的顺序,但其实并不太实际。更重要的是,一笔长期交易往往包含许多和下一个选择不相关的项目,这往往会压制一些真正相关的项目的影响力。因此,作者认为,一个好的TBRS不仅要考虑当前交易中的所有观察到的项目,而且还要对它们进行不同的加权,以建立一个具有注意力(attention)的上下文,从而以很高的概率输出合适的下一个项目。为此,作者设计了一种有效的基于注意力的交易嵌入模型(ATEM),用于上下文嵌入,使交易中的每个观察到的项在不设顺序的情况下加权。对真实世界交易数据集的实证研究证明,ATEM在准确性和新颖性方面都明显优于现有的方法。
▌简介
目前,推荐系统(RSs)在现实生活中尤其是电子商务领域发挥着重要的作用.。然而,大多数现有的RS理论面临各种问题,例如倾向于重复用户可能已经选择的内容。在现实中,用户可能更喜欢那些新颖的,目前并未拥有的东西。为解决这一问题,本文需要通过分析交易内部依赖关系来推荐交易上下文(context)的下一项。在这里,推荐下一项的上下文引用了相应的与项目相关的交易,例如,由多个选定的物品组成的购物篮记录。
学习交易上下文中项之间的相关性和转换是很有挑战性的。在TBRSs中,一个普遍的挑战是建立一个专注的环境,以很高的概率输出真正的下一个选择。一些现有的方法旨在以交易为背景进行推荐,然而,大多数现有的TBRS使用的是部分上下文,并且有排序假设。序列模式挖掘使用刚性顺序的项目之间的关联来预测下一个项目。但是,上下文中的项可能是任意的,这可能与任何挖掘的模式不匹配。
马尔可夫链(MC)是模拟顺序数据的另一种方法,然而,MC只捕获从一个项到下一个项的转换,而不是从上下文序列中捕获,也就是说,它只捕获一阶转换。最近,一种基于矩阵分解(MF)的方法将从当前项到下一项的转移概率矩阵分解为潜在因素,然而,MF由于现实世界中的幂律分布数据,很容易受到稀疏问题的影响。受深层网络巨大成功的启发,许多工作采用深度递归神经网络(RNN)对序列数据进行建模,但复杂结构造成的计算量大,阻碍了其在大数据中的应用。此外,MC、MF和RNN最初都是为具有严格自然顺序的时间序列数据而设计的,因此,它们不适合无序交易。此外,现有的方法并不能有效地在上下文中对项目进行加权,即更多地关注这些相关项目。这种注意力的区分是非常重要的,特别是对于长时间的交易来说,这些交易往往包含许多与下一个选择无关的项目。
本文针对上述问题,提出一个基于注意力的交易嵌入模型(ATEM)。ATEM可以识别与下一个选择高度相关的上下文项。考虑到在现实世界中item数量巨大,通常超过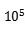
▌贡献
1. 一个基于注意力的模型学习出注意力感知的上下文嵌入表示,这种嵌入表示强化了相关的项目,但忽略了那些与下一个选择无关的内容。作者提出的方法不涉及对交易中的项进行严格的排序假设。
2. 一个浅层wide-in-wide-out网络实现ATEM,对大数量级数据的学习和预测更加高效且有效。
3. 实验表明:(1)在两个真实世界的数据集上,ATEM在准确性和新颖性方面都明显优于最新的TBRSs;(2)通过比较有无注意力机制的方法,发现注意力机制对TBRSs有显著的影响。
▌模型
模型框架如下图所示,从下到上,作者的ATEM模型包括输入层、项目(item)嵌入层、上下文嵌入层、输出层,以及项目嵌入层和上下文嵌入层之间的注意力层。接下来我们从输入到输出逐层解释模型的工作原理。
项目嵌入层 (Item Embedding)
将上下文项集c输入到输入层,图1底部的输入单元构成一个one-hot编码向量,其中只有相应item位置的单元被设置为1,所有其他单元都设置为0。对于项集中的每一个元素i, 作者都用同样的方法将其表示为向量形式,由此可以得到每个item的长度为|I|(I是所有item的总数)的向量表示。
由于one-hot向量表示方法太稀疏,因此作者加入了一个embedding层,利用一个权重W将稀疏的one-hot向量投影到一个连续实值的低维向量空间,用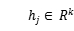
基于注意力机制的交易上下文嵌入层 (Transactional Context Embedding with Attention)
当上下文c中所有项的embedding就绪时,通过集成C中所有项的embedding,可以得到上下文c的嵌入表示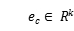
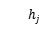
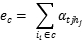
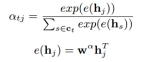
在该模型中,为了更好地捕捉不同上下文项目的不同贡献尺度,作者设置了一个attention层来自动有效地学习集成权重。与手动分配权重或者没有注意力机制直接学习权重的方法相比,作者认为本文方法不仅更灵活,而且更专注于关键项目,减少了无关项的干扰。
目标项目预测
在获得上下文c的表示之后,将其输入到预测任务的输出层,如图1顶部所示。这里的输出权重矩阵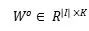
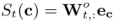
综合得分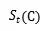
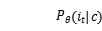
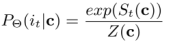
其中,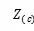
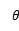
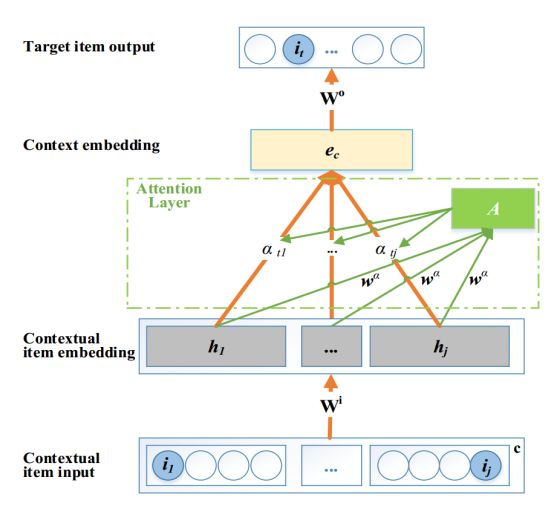
图1. ATEM模型框架
▌实验
数据集
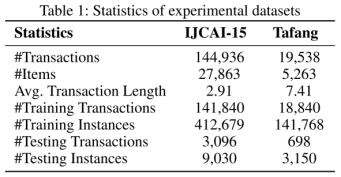
本文所用的数据集如下图所示:
开源链接:IJCAI-15:
https://tianchi.aliyun.com/datalab/dataSet.htm?id=1
Tafang:
http://stackoverflow.com/questions/25014904/download-linkfor-ta-feng-grocery-dataset
Baseline方法
1. PBRS:基于模式的推荐系统
2. FPMC:基于矩阵分解和马尔可夫链的推荐方法
3. PRME:个性化排序度量嵌入方法
4. GRU4Rec:一种基于RNN的基于会话的推荐方法,通过使用由gru单元组成的深度rnn对会话进行建模
5. TEM:一种类似于本文ATEM的模型,但它使用了基于距离的指数衰减取代注意力机制,手动分配权重。
评价指标
1. REC@K:测量推荐列表中所有测试实例中Top-K项的召回率。
2. MRR:测量所有测试实例中真实目标项的预测位置的排名取倒数再求平均作为准确度。
实验结果
表1所示为REC@10,REC@50和MRR在IJCAI-15上的实验结果。
表1. IJCAI-15数据集上的准确率对比
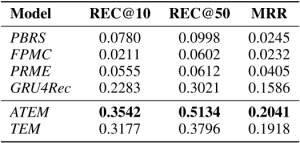
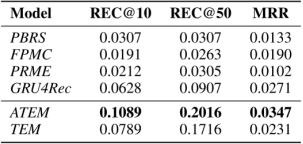
表2所示为REC@10,REC@50和MRR在Tafang上的实验结果。
表2. Tafang数据集上的准确率对比
▌总结
为了有效地推荐交易上下文中的下一项,而现有的next-basket和next-item系统无法解决这些问题,作者提出了一种基于注意力的交易嵌入模型ATEM。ATEM是一种wide-in-wide-out的神经网络,它学习到一个与下一个选择最相关的注意力上下文嵌入。在现实世界交易数据上的实证评估表明,它在弥补最先进方法的差距方面具有显著的优势。在以后的工作中,作者表示会探讨ATME在其他问题上的应用,例如作者-主题关系学习(author-topic relation learning)等。
论文链接:
http://educationdocbox.com/Language_Learning/71463104-Attention-based-transactional-context-embedding-for-next-item-recommendation.html
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!



