如何通过追踪代码自动发现网站之间的“关联”
几年前Lawrence Alexander发表了一篇使用Google Analytics查找网页之间的关联的文章,去年,我也发布了一个关于如何使用Python自动挖掘信息,然后将其可视化的帖子,不幸的是Meanpath API被关闭了,所以这样的技术便不再有用了。
幸运的是,Spyonweb.com的还在正常提供服务。就在前不久,南非记者Jan Cronje就在努力地挖掘一些他正在研究的东西的关联(点击这里阅读),这是重组以前的代码的一个完美的机会:使用Spyonweb来找到这些连接,最后再将其可视化。
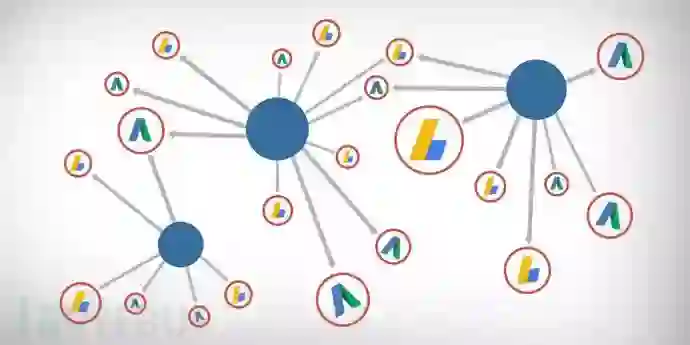
给你敲代码的手指热热身,并准备好享受一些乐趣,因为我们即将要探索如何使用Python自动发现网页之间的关联。
使用SpyOnWeb API
SpyOnWeb.com是一个不断抓取网站追踪代码,名称服务器和其他信息的网站,所以它能帮助显示网站之间的连接。他们的API有许多定价层,从免费开始(对于这篇文章,免费的简直完美),一直到每月69.95美元。
点击这里前往api.Spyonweb.com
在这里注册一个账号,然后主控制面板上就会出现一个access token,我们在下面的文章中会用到。
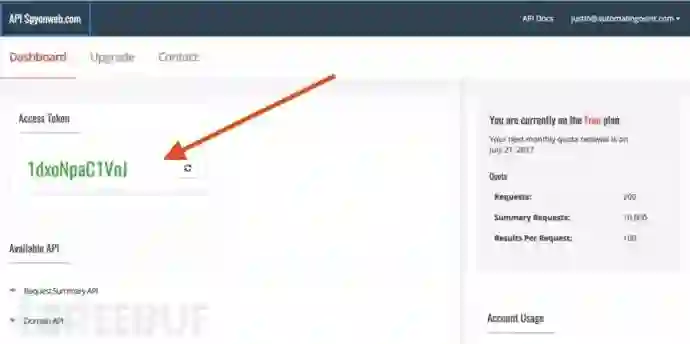
要注意的是,你最好不要和其他人共享你的access token,如果你不小心泄露了,点击上图红色箭头旁的小按钮,它会为你重新生成access token。
现在我们有了Spyonweb的access token,接下来就是写代码了。
准备
在这篇文章里,你需要一些Python库,可以使用pip安装
pip install networkx requests requests[security]另外,你如果想在最后进行可视化,那就需要额外下载Gephi。
代码与解析
热热身,启动你最喜欢的IDE(我使用的是WingIDE,用着真的不错),新建一个叫website_connections.py的文件,完整源码【阅读原文下载】。
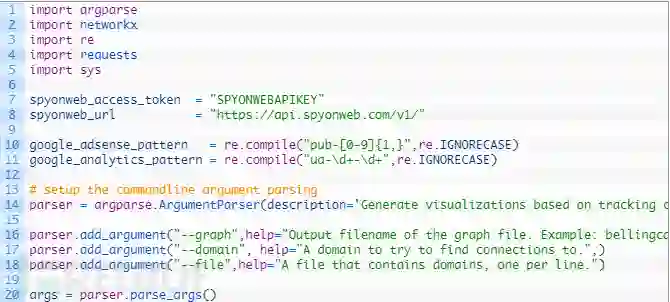
第1-5行:我们正在导入我们的脚本中所需要的所有相关Python模块。
第7-8行:我们定义了一个变量spyonweb_access_token,你需要把之前获取的access token粘贴到这里,然后我们定义了一个变量来保存Spyonweb API调用的URL。
第10-11行:这里为Google Adsense和Google Analyse准备了两个正则表达式模式,我们将通过脚本在目标域名中提取这些代码。
第13-20行:在这里我们设置命令行参数解析,以便轻松地传递一个域名,一个包含域名列表的文件,并允许为我们的图形输出指定的文件名。
我们现在添加一个简单的函数,它将在绘制之前清理追踪代码。让我们先来看看:
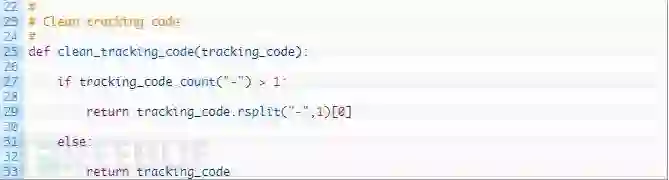
完美!现在我们我们开始第一个函数,用于从目标域名直接提取追踪代码。将以下片段添加进代码中:
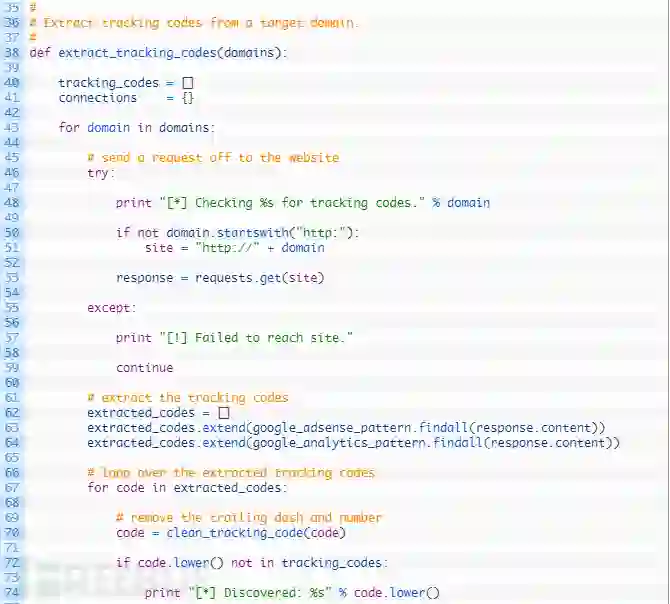

第38行:我们定义了extract_tracking_codes函数来接受我们要遍历的域名列表来执行提取。
第43行之后:我们开始遍历域名列表(43行),然后在向目标域名发送Web请求(53行)之前构建适当的URL(50-51行),如果未能成功连接,则转到下一个域名(57行)。
第62-64行:如果我们成功连接到目标站点,那么就设置一个空白列表来保存我们提取的代码(62行),我们尝试使用正则表达式(63行)来找到所有Google Adsense代码,然后对Google Analyse代码做相同的事情(64行)。
第67-69行:我们遍历提取代码的列表(67行),然后将其通过clean_tracking_code函数将其传递到清理和规范代码部分,接下来测试我们是否已经有了这个代码(72行),如果没有,就将其添加到连接字典中,然后我们就可以对目标域名进行追踪了。
第82行:我们返回连接字典,以便稍后处理结果。
现在我们构建一个函数来向Spyonweb API发送请求,现在继续添加以下代码:
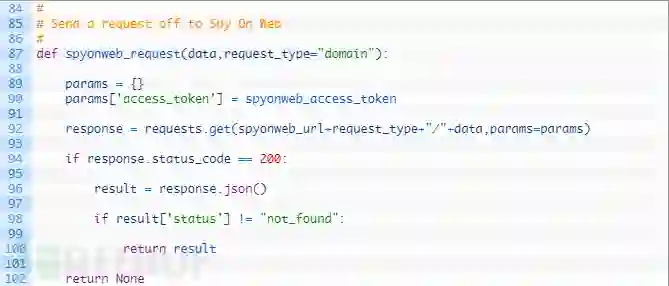
第87行:我们构建spyonweb_request来接收数据,可以是一个域名,追踪代码,也可以是其他支持的输入,我们还构建了request_type参数,该参数将构成Spyonweb请求格式的URL的一部分。
第89-90行:我们创建一个字典,其中包含Spyonweb的access token,它将在HTTP请求中传给Spyonweb。
第92行:我们使用动态构建的URL将请求发送给Spyonweb,并传入params字典。
第94-102行:我们进行检查以确保收到一个有效的HTTP响应(94行),如果请求成功,就解析JSON(96行)。然后测试字典结果(98行)来看看我们是否收到了Spyonweb的有效结果,如果是,返回整个字典。如果没有得到任何结果,就返回None(102行)。
现在我们将构建一个函数来处理向Spyonweb发送特定请求的分析代码。
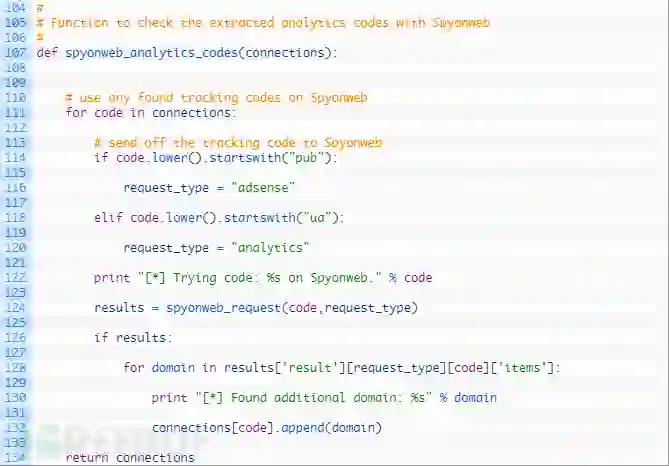
第107行:我们定义spyonweb_analytics_codes函数来采用单个参数连接,即跟踪代码的字典以及它们如何映射到托管它们的域。
第111-120行:我们开始循环(111行),然后测试是否为Adsense代码或Analyse代码,一旦确定了类型,就开始设置request_type。
第124行:我们向Spyonweb API发送请求来看看是否有其他域名也被映射到了当前的追踪代码。
第126-134行:如果我们从Spyonweb获取到了有效的结果,那么就会循环遍历域名,并将其添加到与当前跟踪代码相关联的域列表中,完成后,返回更新后的字典。
现在我们将添加一个函数来从Spyonweb中检索域名报告。域名报告可以告诉我们与域名相关联的其他AdSense或Google Analytics(分析)代码,以及其他可能感兴趣域名的连接。
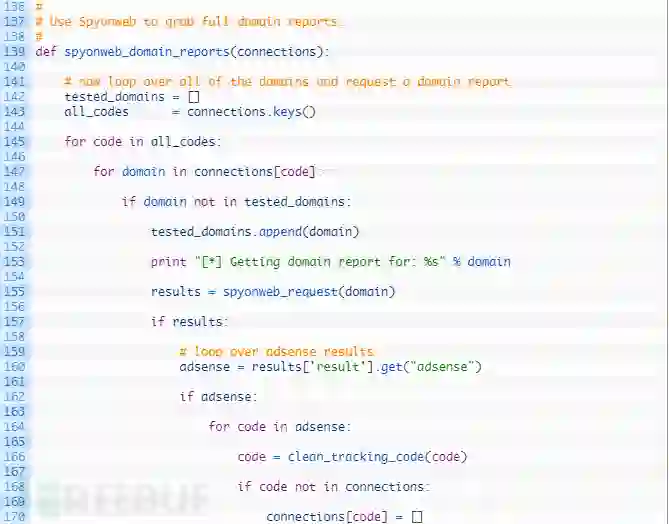
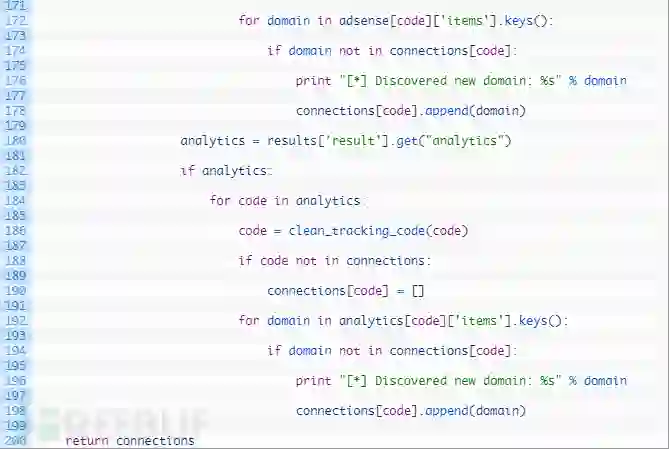
第139行:我们定义spyonweb_domain_reports函数来接收单一的连接参数。
第142-143行:我们设置一个空列表来跟踪我们检查的域名(142行),并将所有跟踪代码加载到列表中(143行)。
第145-155行:循环遍历所有的代码(145行),然后循环遍历与该代码关联的每个域名(147行)。如果我们还没有检查此域名(149行),就将域名添加到测试列表(151行),然后我们向Spyonweb发送请求以获取当前域名的域名报告(155)。
第157-170行:如果我们从Spyonweb(157行)收到有效的结果,就尝试检查任何Adsense代码(160行)。如果有Adsense(162行)的结果,那么开始循环返回所有的Adsense代码(164行),然后将其清理(166行),如果字典中还没有这代码,就将其添加为新密钥(170行)。
第172-178行:我们循环与Adsense代码相关联的域名(172行),如果还没有跟踪域名(174行),那么将其添加到我们的连接字典中,将其与当前跟踪代码相关联。
下一段代码与157-170行和172-178行几乎相同(除了对Google Analyse代码进行处理),我知道一些Python纯粹主义者会调出来抱怨说我们正在重复代码,但是唉,我们就是在这么做。
接下来我们就开始添加最终函数,负责绘制域名之间的连接并跟踪代码,之后我们就可以通过Gephi或其他工具打开图形文件来检查结果。
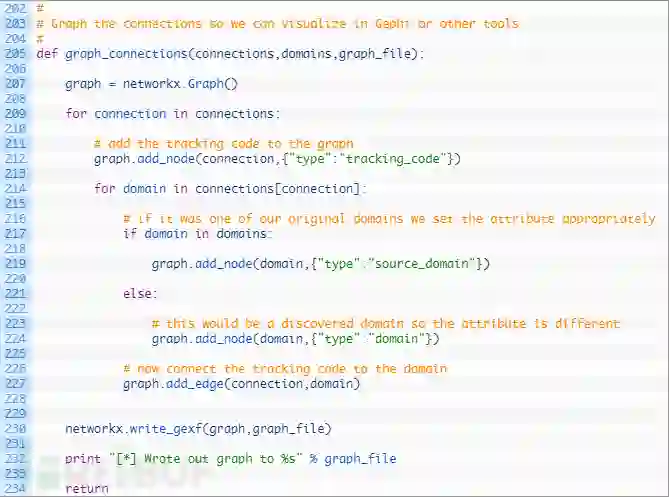
第205行:我们定义了graph_connections函数,它接收连接字典,起始域名列表和要输出图形的文件名。
第207行:我们初始化一个新的networkx Graph对象。
第209-212行:我们开始循环连接字典(209行),然后将跟踪代码添加为图形中的一个节点,之后将选项节点属性设置为“tracking_code”的类型。此属性将允许我们稍后在Gephi中绘制图形。
第214-227行:我们循环查找与当前跟踪代码相关联的所有域名(214行),并且检查域名是否是我们的起始域名之一(217行),如果是,我们将域名添加为图中的节点,设置为“源域名”。如果它不是,我们将节点添加到图中,只将其设置为正常的“域名”(224行)。最后一步是在跟踪代码和域名之间添加一条线(227行)。
第230行:现在我们已经添加了所有跟踪代码和域名,并在它们之间绘制了一条线,之后只需使用write_gexf函数将图形写入文件即可。
现在我们来添加最后的代码段,将所有的函数都绑在一起。已经几乎完成了!

这一小段代码很简单。如果我们收到一个文件名作为命令行参数,我们打开该文件,并逐行读取。如果没有,那么我们只需要脚本中传递的域名参数。
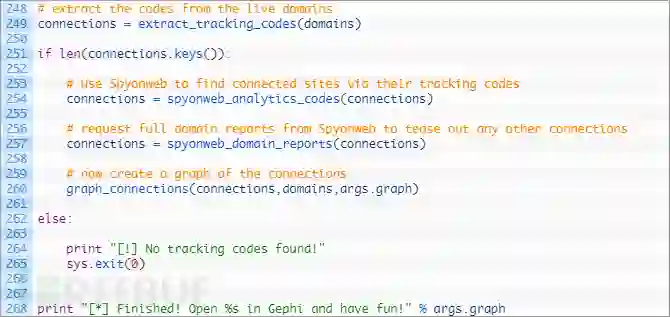
就是这样,你可以试试看了。
运行
使用类似以下命令运行:
python website_connections.py --domain southafricabuzz.co.za --graph southafrica.gexf效果如下:
[*] Checking southafricabuzz.co.za for tracking codes.
[*] Discovered: pub-8264869885899896
[*] Discovered: pub-8264869885899896
[*] Discovered: ua-101199457-1
[*] Trying code: UA-101199457 on Spyonweb.
[*] Trying code: pub-8264869885899896 on Spyonweb.
[*] Found additional domain: www.indiatravelmantra.com
[*] Found additional domain: www.societyindia.com
…
[*] Discovered new domain: 022office.com
[*] Getting domain report for: indiayatraa.com
[*] Getting domain report for: www.mantraa.com
[*] Wrote out graph to southafrica.gexf
[*] Finished! Open southafrica.gexf in Gephi and have fun!
然后你就可以打开gexf文件来查看细节了,可以看看下方示例视频
(阅读原文查看视频链接)
拓展
你完全可以增强这个脚本,例如,你可以查询Wayback machine来跟踪网站过去的代码,或者可以从Spyonweb递归地请求来发现的任何新域名的域名报告,这会产生一个大图,不过可以潜在地增加你的整体覆盖。
有问题或者想联系作者?请联系justin@automatingosint.com。
*参考来源:automatingosint,Covfefe编译,转载请注明来自FreeBuf.COM





