实战 PK!RTX2080Ti 对比 GTX1080Ti 的 CIFAR100 混合精度训练

AI 科技评论按:本文作者 Sanyam Bhutani 是一名机器学习和计算机视觉领域的自由职业者兼 Fast.ai 研究员。在文章中,他将 2080Ti 与 1080Ti 就训练时长进行了全方位的对比。AI 科技评论对此进行了详尽编译。

前言
特别感谢:如果没有来自 Tuatini GODARD(他是我的一名好朋友,同时也是一名活跃的自由职业者)的帮助,这个基准比较工作是不可能完成的。如果你想了解更多关于他的信息,可以阅读这篇访谈:
链接:
https://hackernoon.com/interview-with-deep-learning-freelancer-tuatini-godard-e661a3995fb1
还要感谢 Laurae 给这篇文章提出许多有价值的修改建议。
对了,最新版的 fastai(2019 版)刚推出,你们肯定都很感兴趣:可以访问 course.fast.ai
备注:这篇文章并没有接受来自 fastai 的赞助,我只是在上头学习到很多东西。从个人角度来说,如果你是刚开始接触深度学习,强烈向你推荐这个平台。
让我们进入正题。这是一个能够说明 FP16 本质的简单操作演示,并且展示了基于基准测试的混合精度训练是怎么进行的(我承认,大部分时候我只是通过这个向朋友吹嘘我的显卡集群比他的要快,然后才是出于研究目的)。
注意:这并非关乎基准性能比较的文章,而是 2080Ti 与 1080Ti 之间基于 2 builds 的训练时长对比。
对此,文章里会有更详细的介绍。
在此之前,我们先快速浏览一下中子的造型:
FP16 是何方神圣?为何你需要关注它?
简单来说,深度学习是基于 GPU 处理的一堆矩阵操作,操作的背后有赖于 FP32 / 32 位浮点矩阵。
随着新版架构与 CUDA 的发布,FP32 / 32 位浮点矩阵的运算正变得越来越简单。这也意味着,只要使用与过去相比只有一半大小的张量,我们却能通过增加批尺寸(batch_size)来处理更多案例;此外,相比使用 FP32(也被称为 Full Precision Training)进行训练,FP16 可以有效降低 GPU RAM 的使用量。
用简单的英语来表示,就是能够在代码中以 (batch_size)*2 替代 (batch_size)。
FP16 运算的张量核心如今在速度上变得更快了,只需使用少量的 GPU RAM ,就能在速度与性能方面有所提升。
等等,这可没那么简单
我们依然存在半精度问题(这是因为 16 位浮点变量的精度是 32 位浮点变量的一半),说明:
更新的权重数据是不精确的。
梯度会下溢。
无论激活或丢失都可能导致溢出。
有明显的精度损失。
接下来,我将和大家谈一谈混合精度训练。
混合精度训练
为了避免上述提及的问题,我们在运行 FP16 的过程中,会在可能导致精度损失的部分及时切换回 FP32。这就是所谓的混合精度训练。
第 1 步:使用 FP16 尽可能加快运算速度:
将输入张量换成 fp16 张量,以加快系统的运行速度。

第 2 步:使用 FP32 计算损耗值(避免下溢/溢出):
将张量换回 FP32 以计算损耗值,以免出现下溢/溢出的情况。
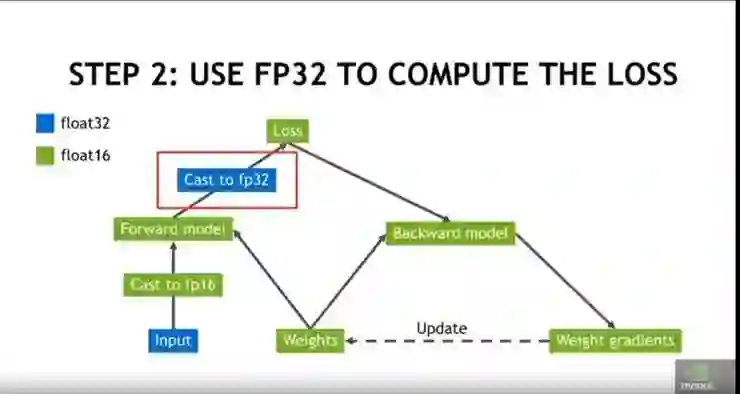
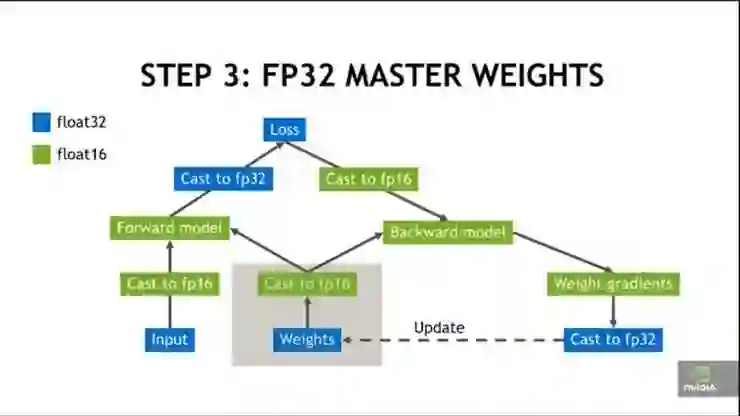
第 3 步:
先用 FP32 张量进行权重更新,然后再换回 FP16 进行前向与反向迭代。
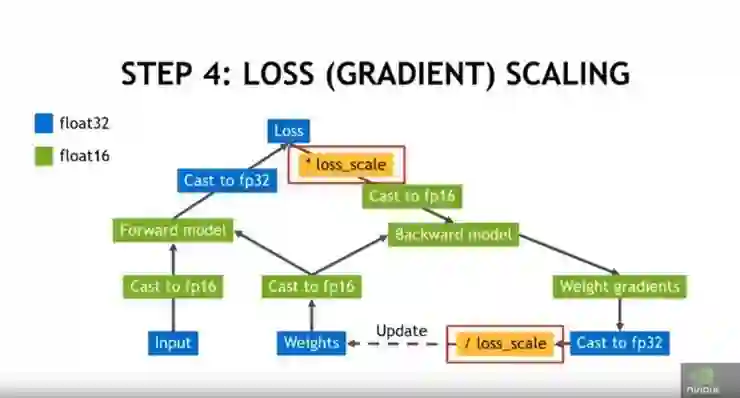
第4步:通过乘以或除以缩放因子来完成损耗缩放:
通过乘以或除以损耗比例因子来缩放损耗。
总结就是:

fast.ai 上的混合精度训练
正如人们所期待的的,在库中进行混合精确训练有如将

转换成
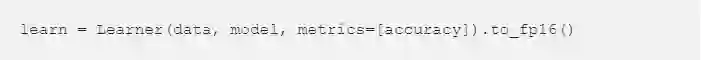
一样简单。
如果你想了解操作过程当中的细节,可以点进:
https://docs.fast.ai/callbacks.fp16.html
该模块允许我们使用 FP16 更改训练过程中的前向与反向迭代,且附有提速效果。
就内部而言,回调函数能确保所有模型参数(除去智能使用 FP32 的 batchnorm layers)都转换成 FP16,且保存了 FP32 副本。FP 32 副本(主参数)主要用于优化器上的更新;FP 16 的参数则用于梯度计算。这些能有效避免低学习率下溢现象的发生。
RTX 2080Ti 与 GTX 1080Ti 的混合精度训练结果对比

设置详情
可以从这里获知笔记本的基准设置
软件设置:
Cuda 10 + 对应最新版的 Cudnn
PyTorch + fastai 库(从源头进行编译)
最新版的 Nvidia 驱动程序(截至文章撰写时间)
硬件配置:
我们的硬件配置略有不同,对于最终数值要有所保留。
Tuatini 的配置:
i7-7700K
32GB RAM
GTX 1080Ti(EVGA)
我的配置:
i7-8700K
64GB RAM
RTX 2080Ti(MSI Gaming Trio X)
由于运算过程并非 RAM 密集型或者 CPU 密集型任务,所以我们选择在此处分享我们的结果。
让我们快速过一遍:
输入 CIFAR-100 数据
调整图像的大小,启用数据增强
在 fastai 支持的所有 Resnet 上运行
预期输出:
在所有的混合精度训练测试中取得更好的结果。
图表结果
以下展示的是在各个 ResNets 上的训练时间对比总表。
注意:数值越小越好(X 轴代表秒时间单位与缩放时间)
Resnet 18
体积最小的 Resnet。
秒时间单位:
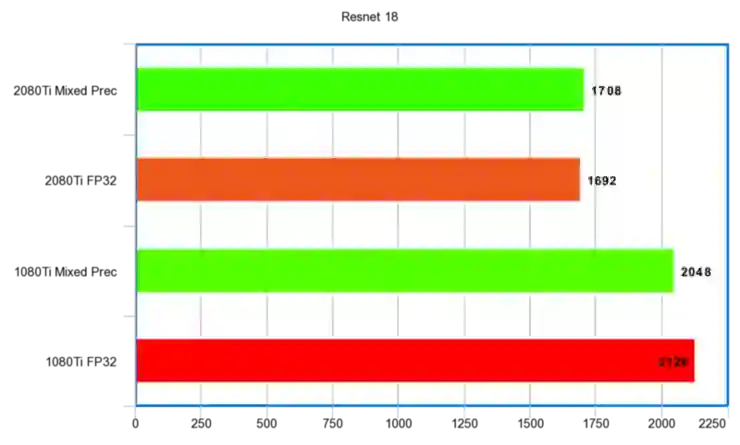
性能比例:
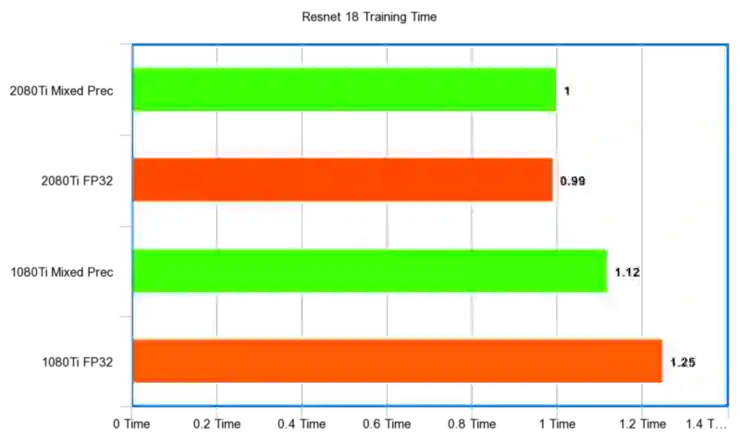
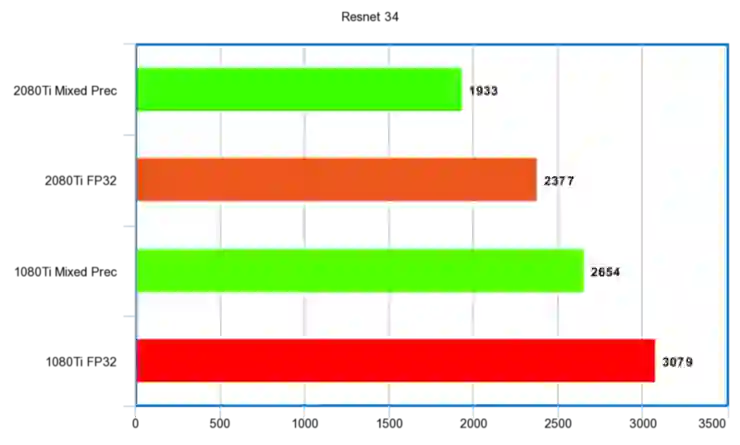
Resnet 34
秒时间单位:
性能比例:

Resnet 50
秒时间单位:
性能比例:


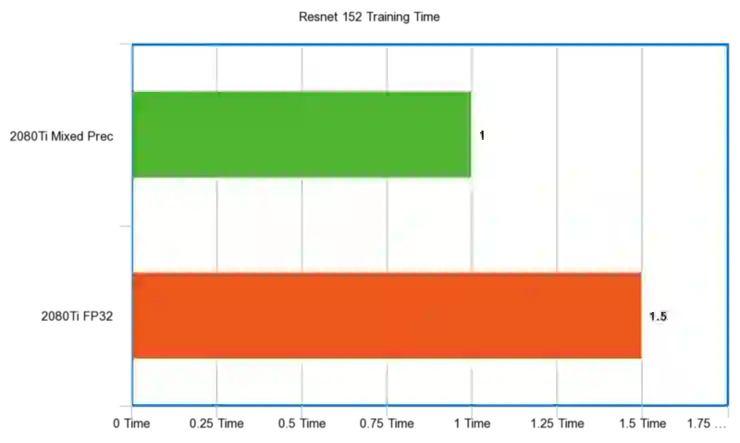
Resnet 152
秒时间单位:
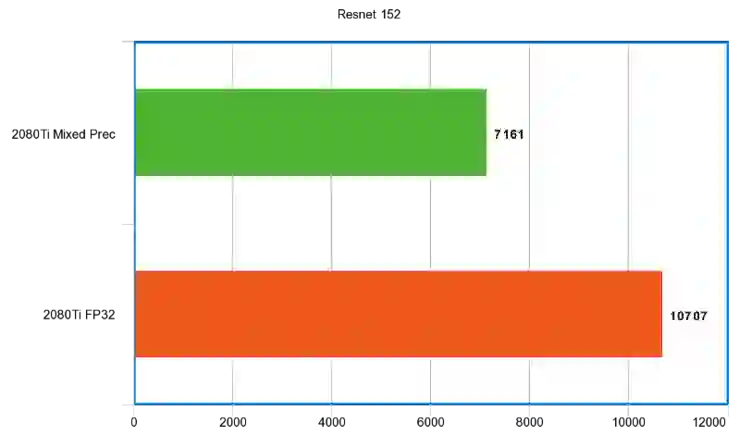
性能比例:
使用 Nvidia Apex 进行世界级语言建模工作
为了使混合精度训练与 FP16 训练的实验成为可能,Nvidia 专门发布了一套维护 Nvidia 的实用工具 Nvidia apex,用于简化 Pytorch 中的混合精度训练与分布式训练。Apex 最主要的目的是尽可能快速地为用户提供最新的实用工具。
开源网址:
https://github.com/NVIDIA/apex
它通过一些例子向我们展示,不需要经过太多调整便可以直接运行工具——看来又是另一个针对高速旋转的好测试。
语言模型对比:
Github 开源中的例子基于语言建模任务训练了一个多层 RNN(Elman,GRU 或 LSTM)。该训练脚本默认使用 Wikitext-2 数据集。训练模型可以用来生成产生新文本的脚本。
我们其实并不关心测试的生成结果 - 我们主要想比较基于混合精度训练的 30 轮次(epochs)训练例子,以及同样批量大小却是不同设置的全精度训练(Full Precision)。
启用 fp16 就和运行代码时传递「—fp16」参数一样简单,APEX 可以在我们已经设置好的 PyTorch 环境上运行。综合来看,这似乎是个完美的选择。
以下是相关结果:
秒时间单位
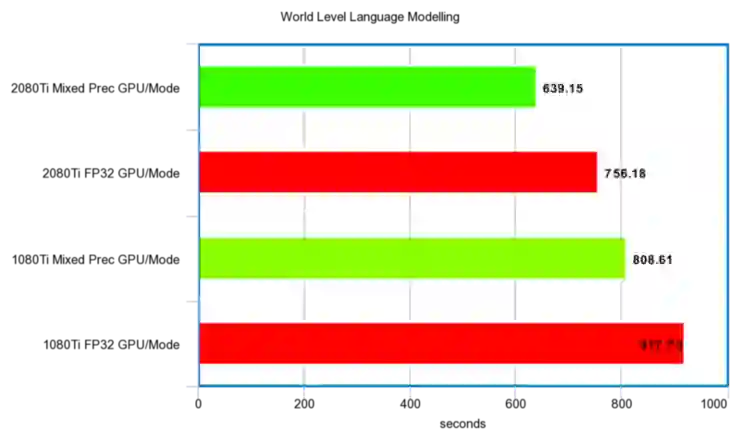
性能比例:

结论
虽然在性能方面 RTX 卡要比 1080Ti 强大得多,尤其就小型网络而言,然而训练时间的差异并不如预期般的明显。
如果你决定尝试混合精度训练,我在这里给你提供几个重点提示:
更大批量:
在笔记本基准测试中,我们发现在 batch_size 方面有近乎 1.8 倍的提高,这与我们尝试过的所有 Resnet 示例结果保持一致。
速度比全精度训练更快:
我们以结果差距最大的 Resnet 101 为例(用的是 CIFAR-100 数据集),全精度训练在 2080Ti 上的花费时间是混合精度训练的 1.18 倍,在 2080Ti 上的花费时间是混合精度训练的 1.13 倍。即便是体积「较小」的 Resnet34 和 Resnet50,我们发现混合精度训练在训练期间存在小幅度的加速效果。
相同的精确值:
我们并未发现混合精度训练导致精确度下降的现象出现。
确保你使用最新版的 CUDA(>9)和 Nvidia 驱动程序。
这里需要强调的是,在测试期间,如果环境没更新好是无法运行代码的。
多多关注 fastai 和 Nvidia APEX
via https://hackernoon.com/rtx-2080ti-vs-gtx-1080ti-fastai-mixed-precision-training-comparisons-on-cifar-100-761d8f615d7f
AI 科技评论报道
【AI求职百题斩 - 每日一题】
【预告】春节期间,百题斩每日一题栏目将推出春节特别版,敬请关注!

想知道正确答案?
点击公众号菜单栏【每日一题】→【每日一题】或在公众号回复“0130”即可答题获取!



