Google解决单摄像头和物体都运动下的深度估计
点击上方“计算机视觉life”,选择“星标”
快速获得第一手干货
人类视觉系统有一个我们习以为然但其实极其强大的功能,那就是可以从平面图像反推出对应的三维世界的样子。即便在有多个物体同时移动的复杂环境中,人类也能够对这些物体的几何形状、深度关系做出合理的推测。

然而类似的事情对计算机视觉来说就有相当大的挑战,在摄像头和被拍摄物品都静止的情况下尚不能稳定地解决所有的情况,摄像头和物体都在空间中自由运动的情况就更难以得到正确的结果了。
原因是,传统的三维重建算法依赖三角计算,需要假设同一个物体可以从至少两个不同的角度同时观察,通过拍摄的图像之间的区别(视差)解算三维模型。想要满足这样的前提,要么需要一个多摄像头阵列,要么要保持被拍摄物体完全静止不动,允许单个摄像头在空间中移动观察。那么,在只有单个摄像头的情况下,深度计算中要么会忽略掉移动物体,要么无法计算出正确的结果。
在谷歌的新研究《Learning the Depths of Moving People by Watching Frozen People》中,他们提出了一种新的基于深度学习的方法来解决单个摄像头+摄像头和物体都在移动的状况下的深度预测,在任意视频上都有很好的效果。这个方法中用人类姿态、常见物体形态的先验学习替代了对于图像的直接三角计算。
值得指出的是,用机器学习的方法「学习」三维重建/深度预测并不是什么新鲜事,不过谷歌的这项研究专门针对的是摄像头和被摄物体都在移动的场景,而且重点关注的被摄物体是人物,毕竟人物的深度估计可以在 AR、三维视频特效中都派上用场。


巧妙地寻找训练数据
正如绝大多数此类方法一样,谷歌选择了用有监督方法训练这个模型。那么他们就需要找到移动的摄像头拍摄的自然场景视频,同时还带有准确的深度图。找到大量这样的视频并不容易。如果选择生成视频的方法,这需要非常逼真的建模,而且在多种场景、光照、复杂度的组合下呈现自然的人物动作,不仅有很高的难度,而且想要泛化到真实场景中仍然有一定难度。另一方法是在真实世界中拍摄这样的视频,需要摄像头支持 RGBD (彩色图像+深度图),微软的 Kinect 就是一种常用的低价方案;但这个方案的问题是,这类摄像头通常只适用于室内环境,而且在三维重建过程中也通常有各自的问题,难以得到理想的精度。
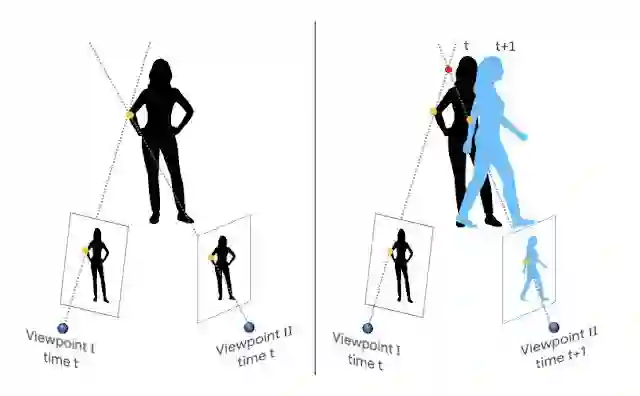
机智的研究人员们想到了利用 YouTube 上面的视频。YouTube 上的海量视频中,各种题材、场景、拍摄手法的都有,有一类视频对这个任务极其有帮助:视频中的人假装时间静止,保持位置和姿态不动,然后一个摄像机在空间中移动,拍下整个场景。由于整个场景中的物体都是固定的,就可以用传统的基于三角计算的方法精确地还原整个三维场景,也就得到了高精度的深度图。谷歌的研究人员们搜集了大概 2000 个这样的视频,包括了不同数量的人们在各种各样不同的真实场景中摆出各种姿势。


为正在移动的人估算距离
上面说到的「时间静止」视频提供了移动的摄像头+静止的物体的训练数据,但是研究的最终目标是解决摄像头和物体同时运动的情况。为了应对这个区别,谷歌的研究人员们需要把网络的输入结构化。
一种简单的解决方案是为视频中的每一帧分别推理深度图(也就是说模型的输入是单帧画面)。虽然用「时间静止」视频训练出的模型已经可以在单帧图像的深度预测中取得顶尖的表现,但谷歌的研究人员们认为,他们还可以利用多个帧的信息进一步提升模型的表现。比如,对于同样的固定物体,摄像头的移动形成了不同视角的两帧画面,就可以为深度估计提供非常有用的线索(视差)。为了利用这种信息,研究人员们计算了每个输入帧和另一帧之间的二维光流(两帧之间的像素位移)。光流同时取决于场景的深度和摄像头的相对位置,不过由于摄像头的位置是未知的,就可以从光流场中消去两者间的依赖,从而得到了初始深度图。这样得到的深度图只对场景中静态的部分有效,为了还能处理移动的人,研究人员们增加了一个人物分割网络,把人从初始深度图中遮蔽掉。那么,网络的输入就由这三部分组成:RGB 彩色图像,人物掩蔽,以及通过视差计算的带有掩蔽的深度图。
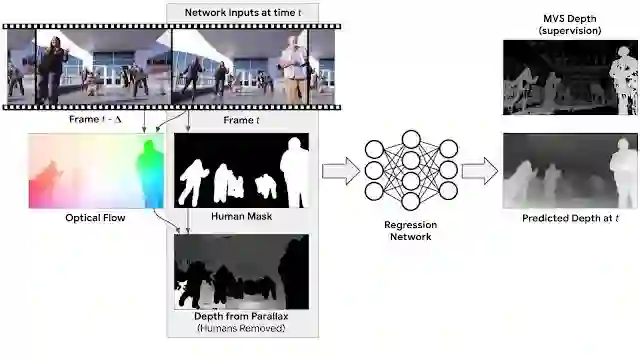
对于这样的输入,网络的任务就是补上有人的区域的深度图,以及对整幅画面的深度图做一些完善。由于人体有较为固定的形状和尺寸,网络可以很容易地从训练数据中学到这些先验,并给出较为准确的深度估计。在训练完毕后,模型就可以处理摄像头和人物动作都任意变化的自然拍摄视频了。
与当前的其它优秀方法的对比如下图。

通过深度图实现三维视频效果
得到准确的深度图之后,一种简单、常见的使用方法就是实现景深和虚焦效果,如下图。

其它的用法还比如可以用原图结合深度图进行小幅视角变换,合成「三维画面」,如下图;甚至在画面中增加具有准确深度和尺寸的三维元素也不难。

论文地址:https://arxiv.org/abs/1904.11111
推荐阅读
从零开始学习SLAM,扫描查看介绍,3天内无条件退款


最新AI干货,我在看




