清华刘知远:大模型「十问」,寻找新范式下的研究方向

来源:智源社区
本文为约4054字,建议阅读8分钟
本文介绍了
在大模型时代
十个值得深入探索的问题。

大模型的出现迎来了AI研究的新时代,其所带来的结果提升十分显著,超越了很多领域中针对研究问题设计特定算法实现的提升。
具体而言,预训练到Finetune的新范式最本质的特点是统一框架以及统一模型。首先,更加统一的架构,在预训练出现之前,CNN、RNN、Gate、Attention等在内的算法框架层出不穷。2017年 Transformer出现之后,取代各种流行框架的是一个统一框架。其次,这种统一框架通过预训练机制带来了统一的模型,因而我们现在可以用一个统一模型进行微调,使其同时用在非常多的下游任务上。
那么,在大模型时代有哪些新问题亟待关注和探索?
由此,我想和大家分享一下十个值得深入探索的问题。希望有更多研究者在大模型时代找到自己的研究方向。
01. 理论:大模型的基础理论是什么?
首先,我认为在大模型当中第一个非常重要的问题就是它的基础理论问题。大模型的一个非常重要的特点就是可以利用非常少的下游任务数据进行相关下游任务的适配,无论是全量下游任务的训练数据还是few-shot learning,甚至zero-shot learning,都能达到相当不错的效果。同时在预训练到下游任务适配过程当中,需要要调整的参数量可以非常少,这两个特点都是大模型给我们带来的新现象。
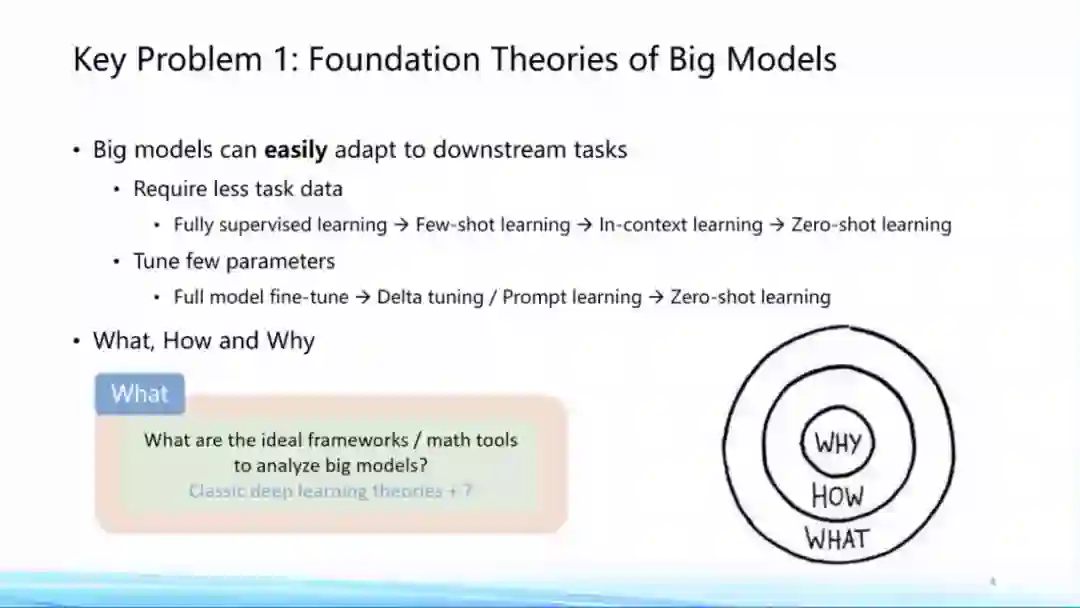
针对这个现象我们有非常多的问题可以去问:
第一,What——大模型到底是什么?我们应该有什么样比较好的数学或者分析工具对大模型进行定量分析或者理论分析,这本身就是一个非常重要的问题。
第二,How——大模型为什么好?大模型是如何做到这一点的?Pre-training和Fine-tuning是如何关联在一起的?以及大模型到底学到了什么?这些是How的问题。
最后,Why——大模型为什么会学得很好?这方面已经有一些非常重要的研究理论,包括过参数化等理论,但终极理论框架的面纱仍然没有被揭开。面向这三个方面,即What、How和Why,大模型时代有着非常多值得探索的理论问题。

第二个问题,目前大模型使用的主流基础架构,Transformer的提出距离我们已经有5年的时间(2017年提出)。我们看到,随着模型规模的不断增长,性能提升也逐渐出现边际效益递减的情况,那么Transformer是不是终极框架呢?有没有可能会找到比Transformer更好更高效的框架?这也是一个值得探索的问题。
神经网络本身是受到了神经科学的启发,我们可以通过其他学科的支持去探索下一代大模型框架。其中来自数学学科的启发包括,非欧空间Manifold的框架,以及如何将一些几何先验放到模型里,这些都是最近比较新的研究方向。

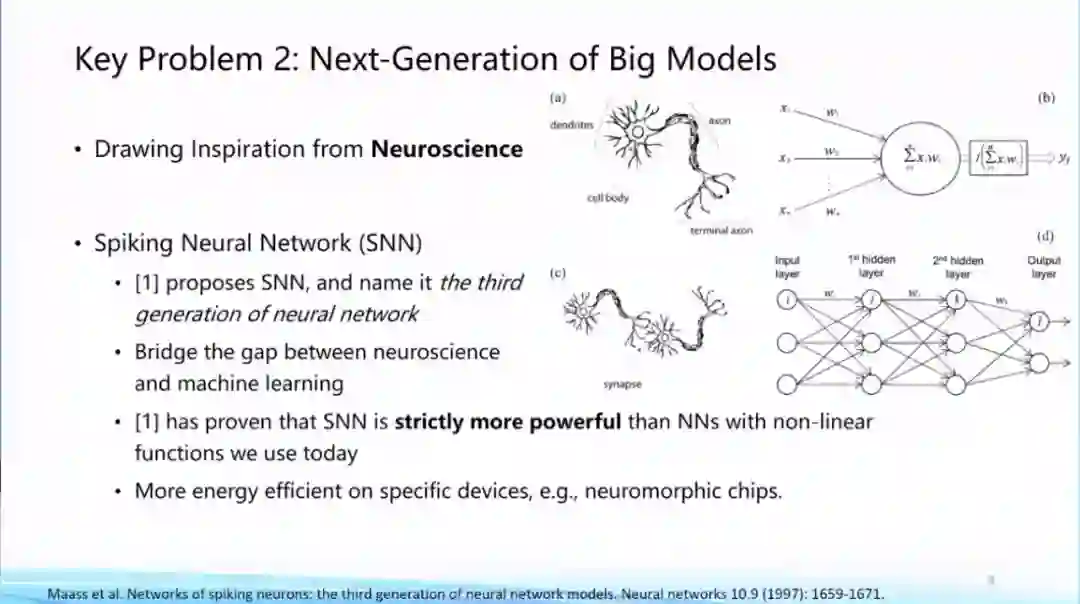
我们还可以从工程和物理角度去考虑这个问题,比如State Space Model,以及动态系统的角度去考虑等等;第三个方面来自于神经科学,面向类脑最近一直有人在研究Spiking Neural Network,上述这些都是新型架构的前沿研究。到底下一代大模型框架是什么?还没有一个标准答案,这本身就是一个亟待探索的问题。

03. 能效:如何使大模型更加高效?
第三个问题,大模型的性能问题。随着大模型越变越大,对计算和存储成本的消耗自然也越来越大。最近有人提出GreenAI的概念,即需要考虑计算能耗的情况来综合设计和训练人工智能模型。面向这个问题,我们认为,随着模型变大,AI会越来越需要跟计算机系统进行结合,从而提出一个更高效面向大模型的支持体系。一方面,我们需要去建设更加高效分布式训练的算法,在这方面国内外都有非常多的相关探索,包括国际上比较有名的DeepSpeed 以及悟道团队在开发的一些加速算法。

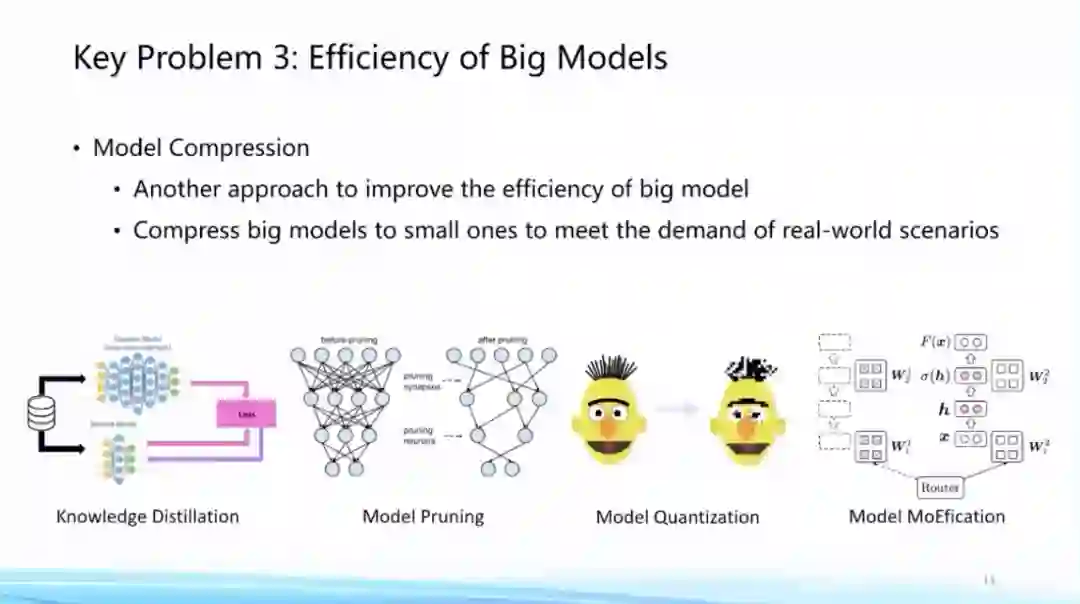
另一个方面,大模型一旦训练好去使用时,模型的“大”会让推理过程变得十分缓慢,因此另外一个前沿方向就是如何高效将模型进行尽可能的压缩,在加速推理的同时保持它的效果。这方面的主要技术路线包括剪枝、蒸馏、量化等等。同时最近我们发现,大模型里面具有非常强的稀疏发放的现象,这对于模型的高效压缩和计算有着非常大的帮助,这方面需要一些专门算法的支持。

第四个问题,大模型一旦训好之后如何适配到下游的任务?模型越大,在已知任务上效果越好,同时也展现出支持未定义过的复杂任务的潜力。同时我们会发现随着大模型变得越来越大,适配到下游任务的计算和存储开销会显著增大。大家看我们统计结果从2020年到2021年顶会上的论文,你会发现越来越多的论文在使用预训练模型,但是真正去使用大模型的论文还是处在非常低的水平。

非常重要的原因就在于即使全世界已经开源了非常多的大模型,但是对于很多研究机构来讲,他们其实还是没有办法很好把大模型适配到下游任务上,这方面是大模型一个非常重要的研究前沿,一个非常重要的方向其实就是唐杰老师有提到的Prompt Tuning,通过把下游任务形式更改成一个跟预训练过程中所谓masked language model相似的形式,让适配过程变得更加平滑和容易。
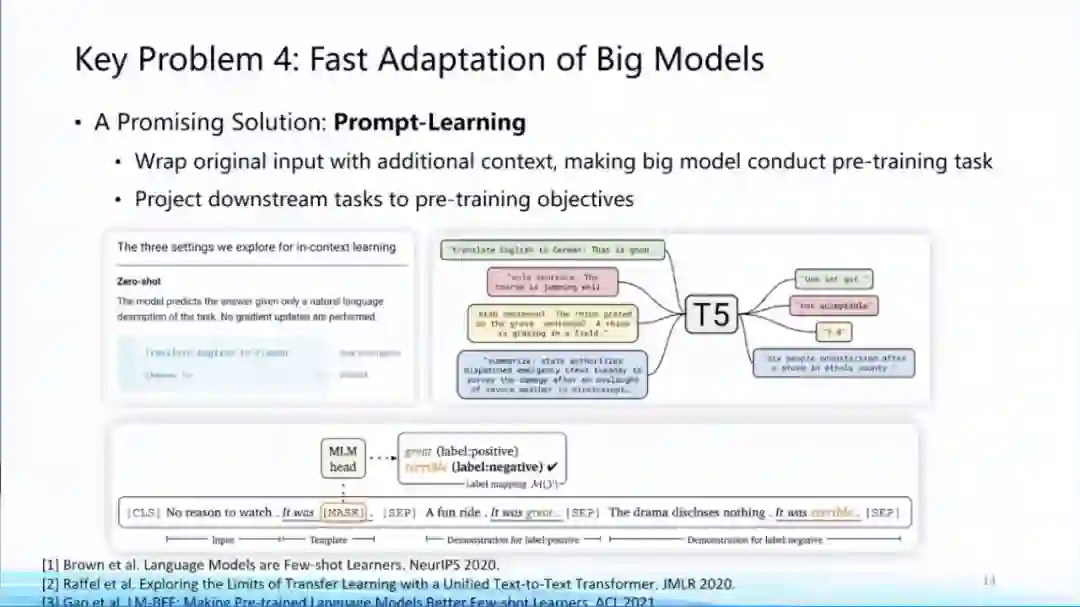
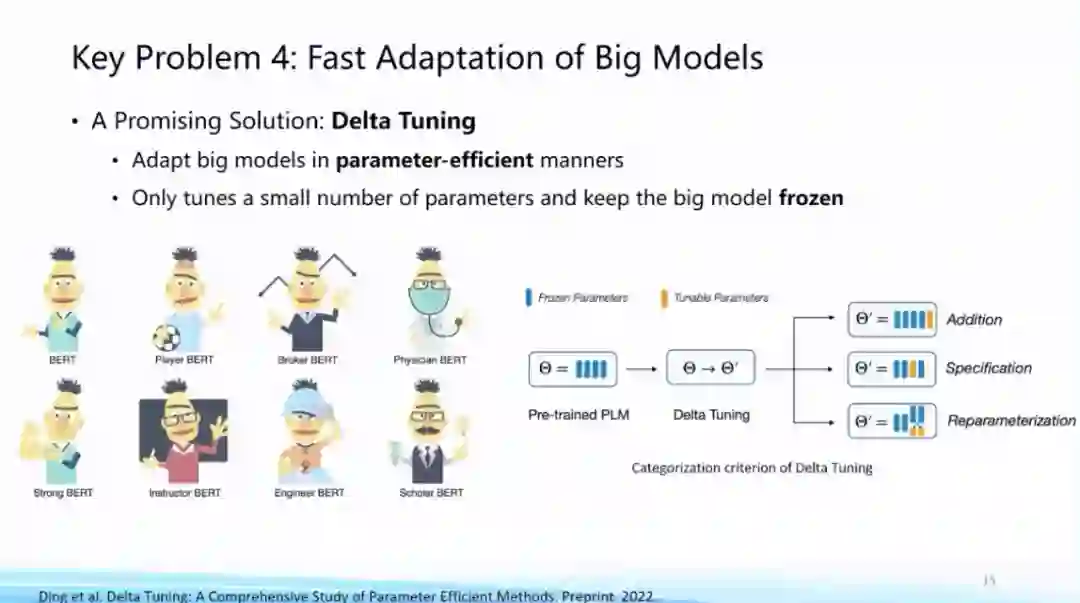
另外非常重要的一个前沿其实就是parameter-effcient learning或者Delta Tuning,基本思想就是只去调整大模型里非常小的一些参数,从而让这个模型非常快的适配到下游任务,会让适配过程不会变得那么困难,这方面是我们认为如何去把大模型快速适配到下游任务的关键问题,这是一个非常前沿的方向。刚才唐老师提到,我们其实开源了两个工具包括OpenPrompt和OpenDelta来支持这个方面的快速研究,也是欢迎大家使用、相关意见和建议甚至可以贡献。
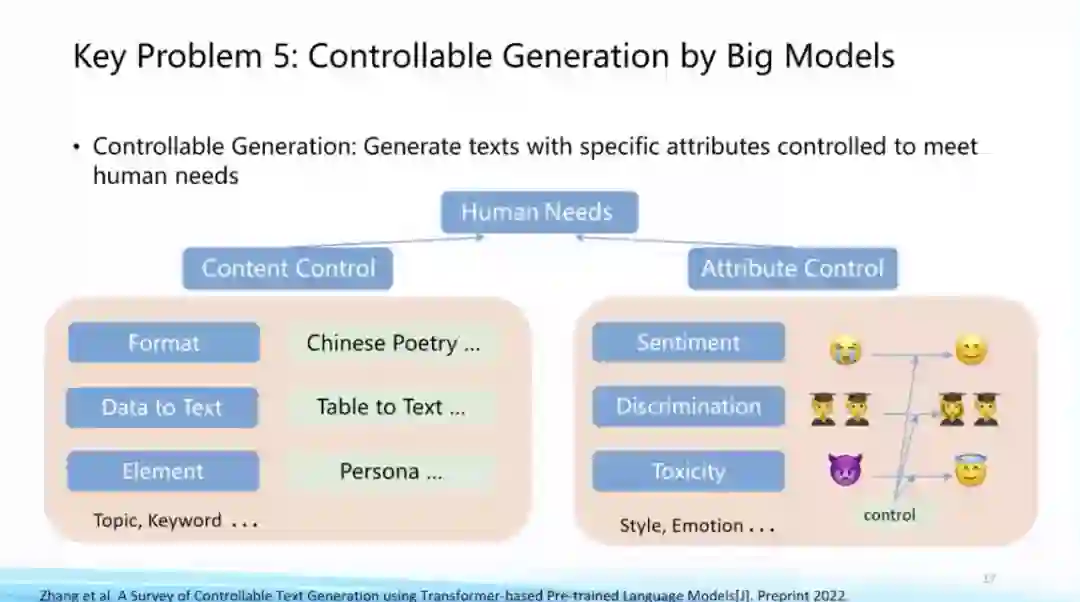
05. 可控性:如何实现大模型的可控生成?
第五个问题,大模型的可控生成。目前大模型已经可以生成一些新的文本或图像,但如何精确地将我们想要的条件或者约束加入到生成过程中,这是大模型非常重要的研究方向。
这个方向也有很多技术方案,其中包括唐老师提到的思路,把一些prompt加入进来,让生成的过程接受我们提供的条件。
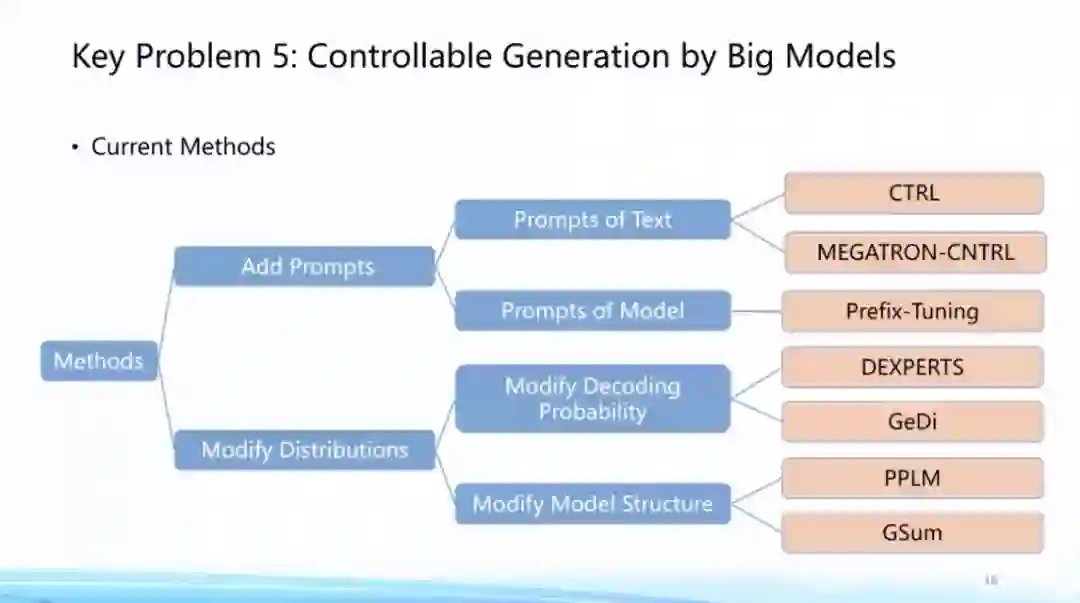
这方面也有一些开放性问题,比如如何建立一个统一的可控生成框架,如何实现比较好的评测方法,对生成的文本进行概念性甚至事实性的自洽检测,以及如何针对新的数据进行相关的生成。

06. 安全性:如何改善
大模型中的安全伦理问题?
第六个问题,现在的大模型本身在安全伦理方面考虑的比较少。实际上会容易出现大模型被攻击的情况,可能稍微改一改输入就不work。另外,大模型的使用过程也会存在一定的伦理问题,这些问题都需要我们对大模型进行有针对性的约束。

在这个方面,包括黄民烈老师等团队也在开展一些工作,我们发现大模型特别容易被有意识地植入一些后门(backdoor),从而让大模型专门在某些特定场景下做出特定响应,这是非常重要的安全性问题。

另外,此前的研究表明模型越变越大之后,会变得越来越有偏见,越来越不值得被信任,这种信任度降低的趋势就是我们需要探索的问题。
07. 认知:如何使大模型获得高级认知能力?
第七个问题,人的高级认知能力是否可以让大模型学到?能不能让大模型像人一样完成一些任务?人去完成任务一般会进行几个方面的工作:一,我们会把这项任务尝试拆分成若干个简单任务,第二,针对这些任务去做一些相关信息的获取,最后我们会进行所谓的高级推理,从而完成更加复杂的任务。

这也是一个非常值得探索的前沿方向,在国际上有WebGPT等方法的尝试已经开始让大模型学会使用搜索引擎等等。我们甚至会问,可不可以让大模型学会像人一样网上冲浪,去有针对性地获取一些相关信息,进而完成任务。
08. 应用:大模型有哪些创新应用?
第八个问题,大模型在众多领域的创新应用。近年来《Nature》封面文章已经出现了五花八门的各种应用,大模型也开始在这当中扮演至关重要的角色。这方面一个耳熟能详的工作就是AlphaFold,对整个蛋白质结构预测产生了天翻地覆的影响。
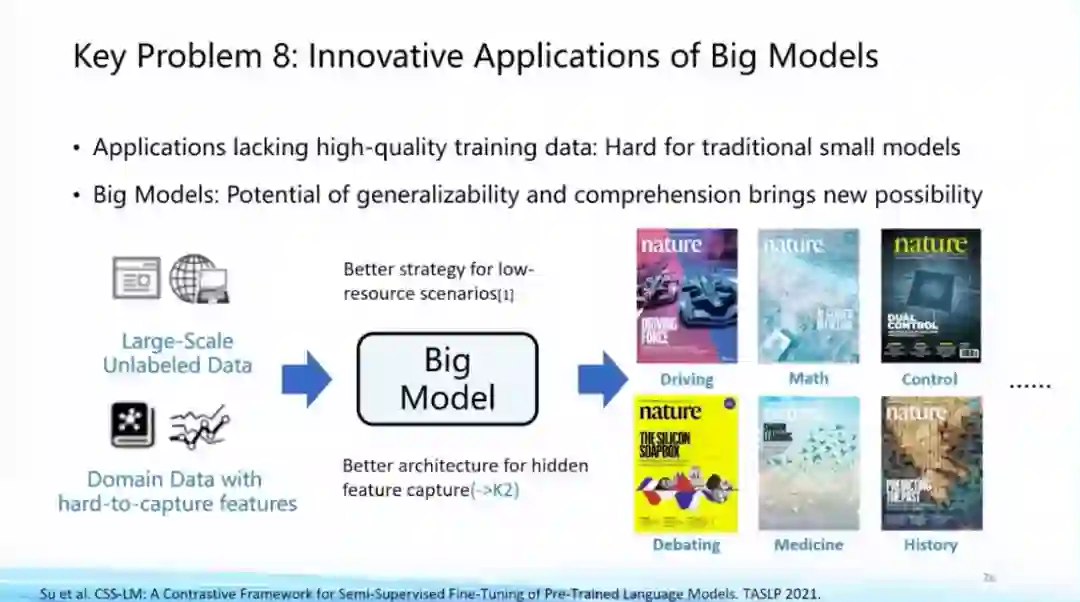
未来在这个方向上,关键问题就是如何将领域知识加入AI擅长的大规模数据建模以及大模型生成过程中,这是利用大模型进行创新应用的重要命题。

09. 评估:如何评估大模型的性能?
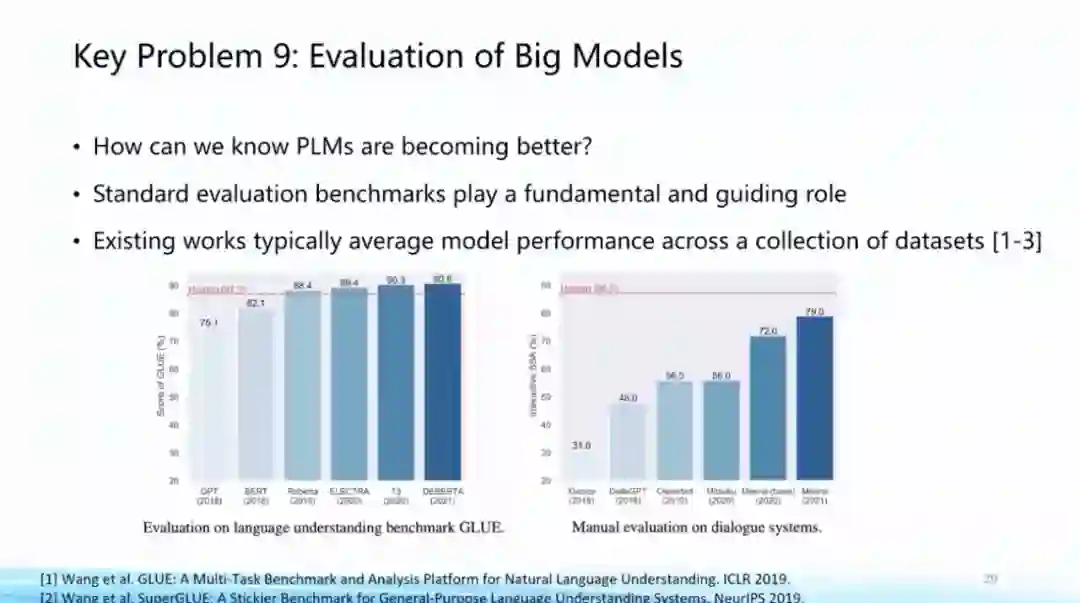
第九个问题,大模型建得越来越大,结构种类、数据源种类、训练目标种类也越来越多,这些模型的性能提升到底有多少?在哪些方面我们仍需努力?有关大模型性能评价的问题,我们需要一个科学的标准去判断大模型的长处和不足,在这方面智源也有相应的努力,因此我们提出了“智源指数”的概念。

10. 易用性:如何降低大模型的使用门槛?
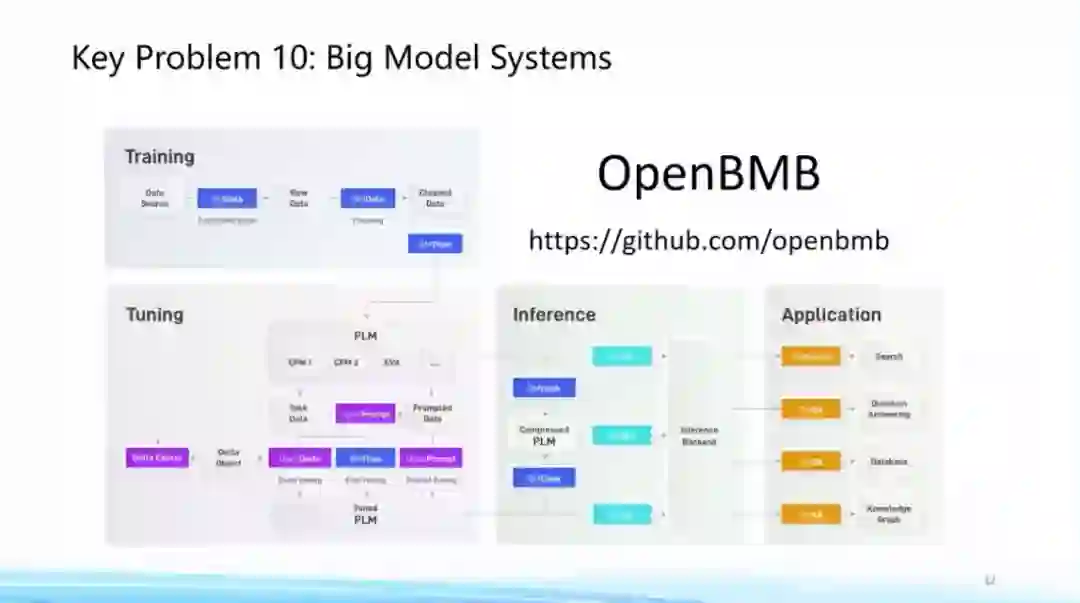
最后,我们认为大模型已经在统一框架和统一模型支持下展现出非常强大的实力,未来有希望广泛应用在各种各样的场景中。而为了更广泛的应用,需要解决的问题是如何降低它的使用门槛。在这方面,我们应该受到历史上数据库系统以及大数据分析系统的启发,需要构建大模型的系统,并在底层相关计算设备、系统的支持、用户接口以及应用普世性等方面进行统一的考量。

在这方面,在清华大学和智源研究院支持下,我们最近在开发一套面向大模型的支持系统,在训练、微调、推理到后处理等各个方面都能提供全流程的高效计算支持,该系统预计将在3月底正式发布。现在个别套件已经可以在网上获取,欢迎大家利用大模型系统,更好地遨游在大模型的时代,做出前沿的探索和应用。
总结来看,上述十个问题是我认为非常重要值得探索的方向,希望更多同学、更多研究者在大模型的时代去发现值得研究的问题。这是一个全新的时代,有些老的问题消失了,也有更多新的问题出现,期待我们一起去探索它们。





