基于ES的人才搜索架构
背景&问题
Elastic Search(后面简称ES)是一个开源的文本检索服务框架,为很多公司提供了检索服务。ES目前功能比较多,使用方便,但肯定不能解决所有问题,只用它来做检索服务可能会更合适。比如我们公司的人才搜索服务,简单来说就是给定查询搜索出相关的人才。 这里ES会有些点没有很好的覆盖或不够有效。
中文分词默认不提供
这个一般都会配置相关中文分词插件,我们也是采用使用JNI封装好自己的分词器,以插件形式提供给每个ES节点不包含查询意图分析
或者说具体一个业务,需要自己在开发查询分析摘要不包含,高亮特性比较鸡肋
没有文档摘要服务,高亮支持比较粗暴,直接在索引上支持,为了高亮特性,你需要开启正向索引,索引大小会剧增。 而且对于Nested object,高亮支持比较所限。缺少业务相关性的计算机制
一个搜索过去,返回就是一堆文档,以及一些文本相关性得分,可以调整的空间有限。
一般一个具体业务,query更文档的相关性会有些更多的考量,希望更精细的控制相关性。人才搜索架构
针对以上提到的问题,我们的人才搜索在ES上补充些组件来完成业务需求,架构图如下:
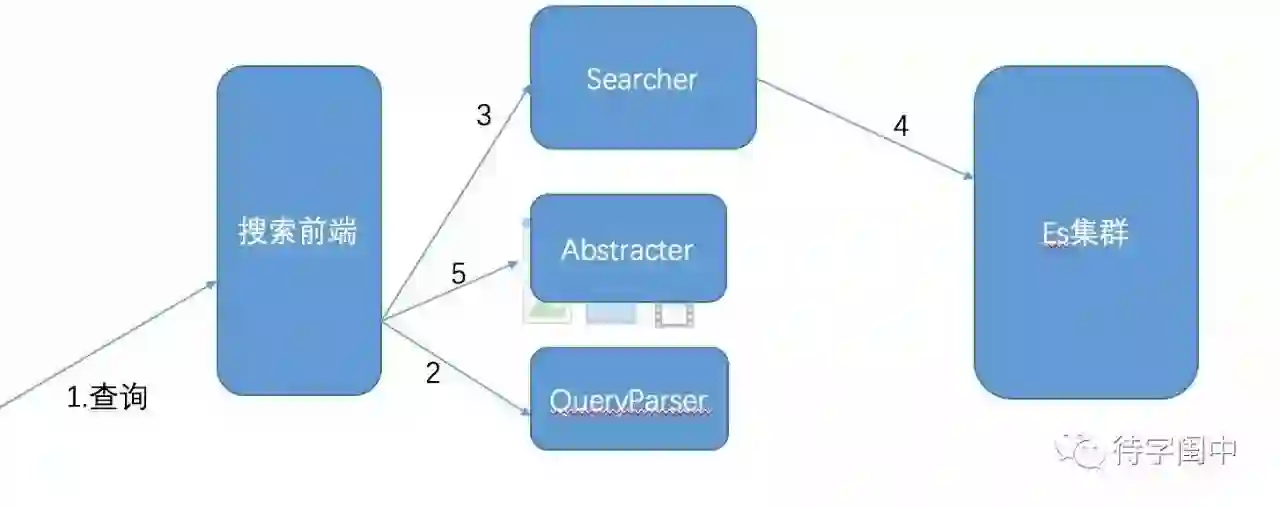
搜索前端
这个服务收取来自其他系统的查询请求,带有一个LRU Cache,可以缓存比如10分钟以内的相同查询结果。 其他他就是一个中控作用,发查询给Query分析服务,得到分析结果后发给Searcher,从Searcher得到结果后,又发分析结果以及指定页文档ID给Abstracter,Abstracter给出摘要高亮结果,最后返回
QueryParser
查询分析是最重要的一个服务,这里会看这个查询的意图,某个query是否公司名查询,职位查询等等。 同时,查询中哪些是核心词必须命中,哪些非强制命中,哪些词是需要高亮,那些词可以做哪种扩展,哪些可以不用高亮,哪些词对应文档中哪些字段高亮等, 最后如果一次检索结果数不够,二次检索策略的一些提示都可以在这一步完成
Searcher
这个服务接收来自搜索前端的query分析结果, 调用查组装(Query Composer)的组件,根据查询意图等组装出需要发给ES集群的Query。
ES集群给出结果后,这边会对前几页结果调用Ranker组件来根据业务需求排序。
这个排序可以是由Learning To Rank 算法学出来的模型来完成,会综合各种业务场景,特征来排序。
细心的同学可能会问,在这里排序怎么保证全局的排序是对的, 一般而言,我们在Searcher发出的请求是直接请求前200条结果的,翻页之类的由搜索前端缓存来解决。另外,ES的文本相关性机制来保证这头部的200条是大致相关的,我们这里的Ranker相当于最顶层的一个排序器。
Abstracter
摘要服务根据query解析结果,对命中结果计算最合适的高亮结果,提供给业务一个摘要信息
ES自定义分词插件
前文提到了,ES本身不支持中文分词,不过ES有一套完整的插件机制。提供了一个很好的机制,方便开发者集成不同的分词。这里给一个例子,集成jieba分词的中文版本,github地址:https://github.com/sing1ee/elasticsearch-jieba-plugin 有完整的文档介绍。随着ES的升级,插件的实现机制也在变化,稍微有些麻烦,希望这个例子可以帮助到到家。自定义插件,有几个要点:
plugin.xml配置文件
plugin-descriptor.properties配置文件
集成抽象类Plugin,实现接口AnalysisPlugin。
以上的配置文件,要注意版本,经常加载插件的时候,会出现版本不一致的问题。
ES自定义相似度插件
除了可以自定义分词插件之外,我们也可以根据需求,自定义相似度的插件,也是非常方便的。当然,如果排序的需求比较复杂,建议大家采用LTR的算法,普适性更强,当然也需要更强的实现。我们这里说一个场景,比如我们Query提示,AutoComplete这个功能,ES就可以很好的实现,方法也有多种,但是如果我们要求排序呢?比方说,全部匹配的排在前面,匹配长度占总长度越小的排在越后面,该如何处理呢?大家如果有经验的话,可以发现,默认的BM25是无法实现这个场景的排序需求的,因为他们的长度差不多,在Norm之后,分数都是一样的。我们先了解一下BM25的公式,如下图:

根据我们的需求,我们只需要做到以下几点:
idf返回固定值1f
avgFieldLength返回固定值1f
encodeNormValue公式,默认是要对fieldLength开根号的,降低了长度的影响,在我们的场景中要加强,所以直接用fieldLength本身,详情见:https://github.com/sing1ee/elasticsearch-similarity-plugin
其他&总结
以上这些服务需要一个通信协议,gRPC是一个很好的选择。 另外一些服务的A/B测试,负债均衡可以在gRPC层面来支持。
总结下,ES作为一个通用检索服务非常强大,针对某个特定业务,一般还是需要单独开发一些组件来配合这个检索服务,从来更好的满足各种业务需求。
最后,打个广告,我们正在围绕人才大数据做一系列工作,人才画像,人工匹配,人才推荐,知识图谱构建等都开始展开,有兴趣的同学欢迎砸简历到chenyw AT inmindglobal DOT com