移动端机器学习模型压缩也自动化了:腾讯新框架为自家模型加速50%
夏乙 发自 凹非寺
量子位 出品 | 公众号 QbitAI

把深度学习模型压缩部署到手机上直接本地运行的趋势,愈演愈烈。从Google的TensorFlow Lite、苹果的Core ML,到小米今年6月推出的MACE,移动端深度学习框架几乎已成科技巨头标配。
可是,究竟用哪个框架?选哪个模型压缩算法?超参数怎样取值?众多工具摆到开发者面前的同时,问题也纷纷出现了。
腾讯AI Lab给出了一个答案:自动模型压缩框架PocketFlow。
这个模型,腾讯自己已经用上了,最近还将开源。
全球首个自动模型压缩框架
PocketFlow被腾讯AI Lab称为世界首款自动化深度学习模型压缩框架,它集成了腾讯自己研发的和来自其他同行的主流的模型压缩与训练算法,还引入了自研的超参数优化组件,实现了自动托管式模型压缩与加速。
所谓“自动化”,就是说模型的压缩和加速过程都是自动完成的。就像Google AutoML用户不用自己选择模型架构一样,使用PocketFlow也不用自己选择模型压缩算法和超参数取值,只要设定对性能指标的期待,让框架自己完成剩下的工作就好。
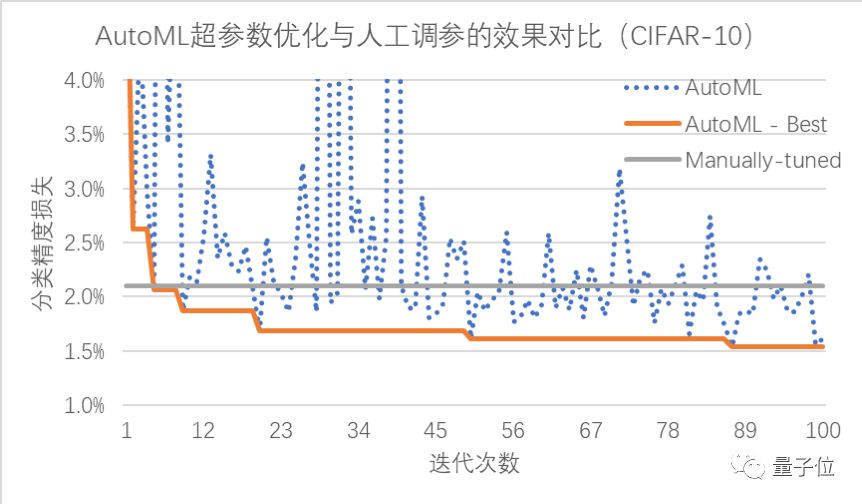
人类需要费时费力调参才能达到的性能,对于PocketFlow来说,只需要十几次迭代。
不仅省人工,效果还不错。
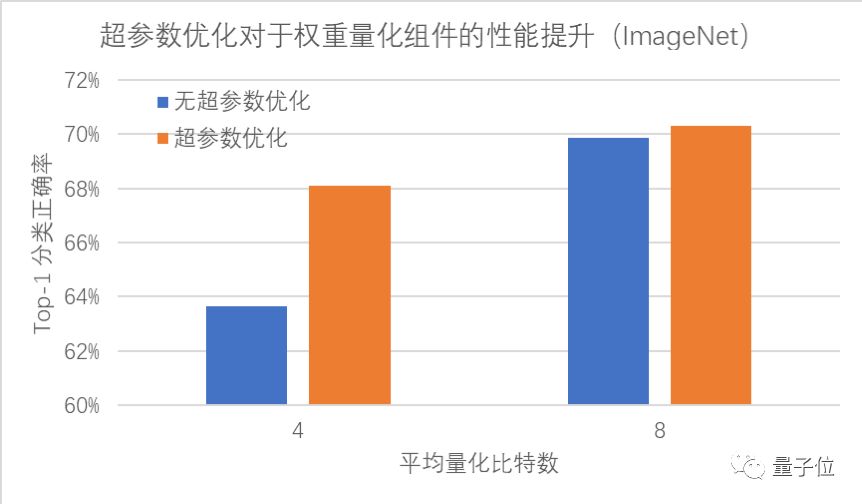
PocketFlow经过100次迭代后搜索得到的超参数组合,可以降低约0.6%的精度损失;通过使用超参数优化组件自动地确定网络中各层权重的量化比特数,PocketFlow在对用于ImageNet图像分类任务的ResNet-18模型进行压缩时,取得了一致性的性能提升;当平均量化比特数为4比特时,超参数优化组件的引入可以将分类精度从63.6%提升至68.1%(原始模型的分类精度为70.3%)。
腾讯展示了PocketFlow对ResNet、MobileNet等CNN网络进行压缩和加速的效果。
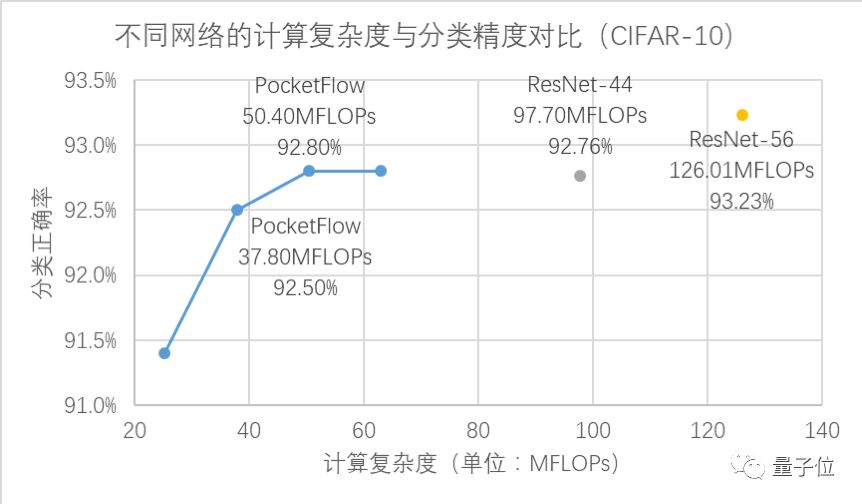
在CIFAR-10数据集上,PocketFlow压缩的ResNet-56模型,实现了2.5倍加速下分类精度损失0.4%,3.3倍加速下精度损失0.7%,且显著优于未压缩的ResNet-44模型。
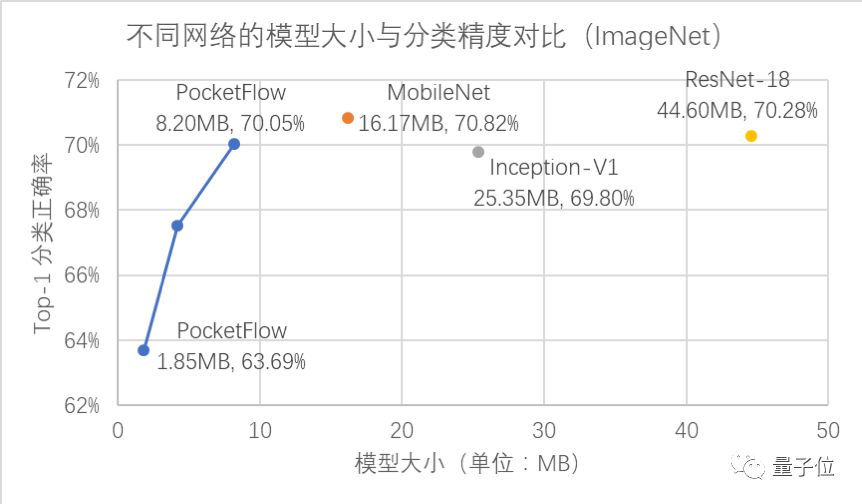
在ImageNet数据集上,PocketFlow可以把MobileNet模型压缩到更小,但分类精度基本不变。在分类精度毫不逊于Inception-V1、ResNet-18等模型的条件下,PocketFlow压缩的MobileNet模型大小只有它们的20 - 40%。
模型压缩算法+超参数优化
PocketFlow框架是怎样压缩深度学习模型的?
靠的是两部分组件:一是模型压缩/加速算法,二是超参数优化器。
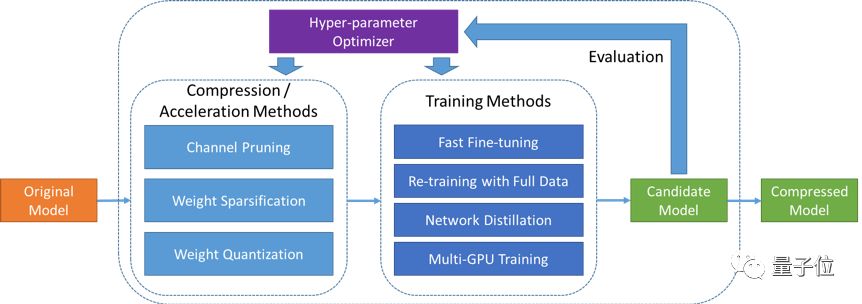
将未压缩的原始模型输入到PocketFlow框架中,设置期望的性能指标,比如模型的压缩、加速倍数等等,PocketFlow就可以开始工作了。
在每一轮迭代过程中,超参数优化器选取一组超参数取值组合,之后模型压缩/加速算法组件基于该超参数取值组合,对原始模型进行压缩,得到一个压缩后的候选模型;基于对候选模型进行性能评估的结果,超参数优化组件调整自身的模型参数,并选取一组新的超参数取值组合,以开始下一轮迭代过程;当迭代终止时,PocketFlow选取最优的超参数取值组合以及对应的候选模型,作为最终输出,返回给开发者用作移动端的模型部署。
在整个过程中,发挥作用的一共可以总结为六大组件:
通道剪枝(channel pruning)组件:
在CNN网络中,通过对特征图中的通道维度进行剪枝,可以同时降低模型大小和计算复杂度,并且压缩后的模型可以直接基于现有的深度学习框架进行部署。在CIFAR-10图像分类任务中,通过对ResNet-56模型进行通道剪枝,可以实现2.5倍加速下分类精度损失0.4%,3.3倍加速下精度损失0.7%。
这一组件的背后,是腾讯AI Lab团队提出的基于判别力最大化准则的通道剪枝算法,相关论文Discrimination-aware Channel Pruning for Deep Neural Networks发表于NIPS 2018,即将公布。权重稀疏化(weight sparsification)组件:
通过对网络权重引入稀疏性约束,可以大幅度降低网络权重中的非零元素个数;压缩后模型的网络权重可以以稀疏矩阵的形式进行存储和传输,从而实现模型压缩。对于MobileNet图像分类模型,在删去50%网络权重后,在ImageNet数据集上的Top-1分类精度损失仅为0.6%。权重量化(weight quantization)组件:
通过对网络权重引入量化约束,可以降低用于表示每个网络权重所需的比特数;团队同时提供了对于均匀和非均匀两大类量化算法的支持,可以充分利用ARM和FPGA等设备的硬件优化,以提升移动端的计算效率,并为未来的神经网络芯片设计提供软件支持。以用于ImageNet图像分类任务的ResNet-18模型为例,在8比特定点量化下可以实现精度无损的4倍压缩。网络蒸馏(network distillation)组件:
对于上述各种模型压缩组件,通过将未压缩的原始模型的输出作为额外的监督信息,指导压缩后模型的训练,在压缩/加速倍数不变的前提下均可以获得0.5%-2.0%不等的精度提升。多GPU训练(multi-GPU training)组件:
深度学习模型训练过程对计算资源要求较高,单个GPU难以在短时间内完成模型训练,因此团队提供了对于多机多卡分布式训练的全面支持,以加快使用者的开发流程。无论是基于ImageNet数据的Resnet-50图像分类模型还是基于WMT14数据的Transformer机器翻译模型,均可以在一个小时内训练完毕。
另外,团队还提出了一种误差补偿的量化随机梯度下降算法,通过引入量化误差的补偿机制加快模型训练的收敛速度,能够在没有性能损失的前提下实现一到两个数量级的梯度压缩,降低分布式优化中的梯度通信量,从而加快训练速度,相关论文Error Compensated Quantized SGD and its Applications to Large-scale Distributed Optimization发表于ICML 2018。
论文地址:http://proceedings.mlr.press/v80/wu18d.html超参数优化(hyper-parameter optimization)组件:
多数开发者对模型压缩算法往往不甚了解,但超参数取值对最终结果往往有着巨大的影响,因此团队引入了超参数优化组件,采用了包括强化学习等算法以及AI Lab自研的AutoML自动超参数优化框架来根据具体性能需求,确定最优超参数取值组合。例如,对于通道剪枝算法,超参数优化组件可以自动地根据原始模型中各层的冗余程度,对各层采用不同的剪枝比例,在保证满足模型整体压缩倍数的前提下,实现压缩后模型识别精度的最大化。
开源在即,腾讯先用为敬
我们前面也提到过,腾讯AI Lab计划将PocketFlow开源。现在,这个框架已经用在了腾讯自己的移动端业务里。
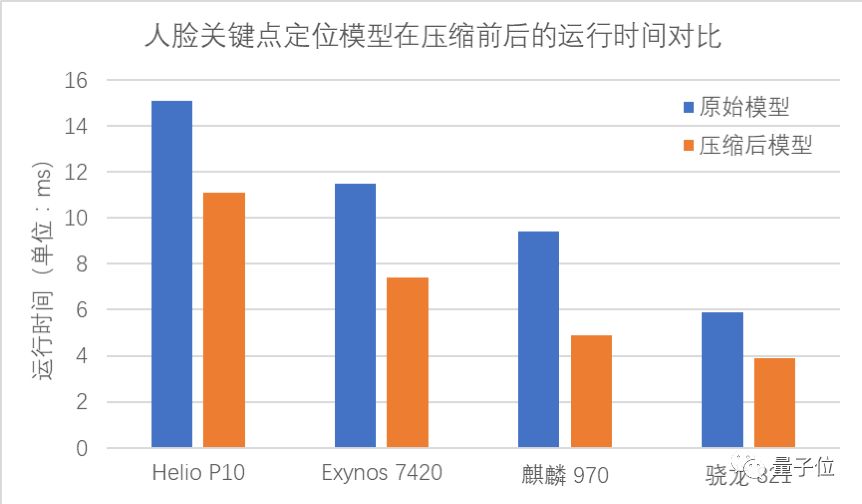
腾讯举了一个栗子:手机拍照App里的人脸关键点定位模型。他们用PocketFlow对这个模型进行了压缩,在保持定位精度不变的同时,降低了计算开销,在不同的移动处理器上取得了25%-50%不等的加速效果。
是不是有点期待?
— 完 —
加入社群
量子位AI社群28群开始招募啦,欢迎对AI感兴趣的同学,在量子位公众号(QbitAI)对话界面回复关键字“交流群”,获取入群方式;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进专业群请在量子位公众号(QbitAI)对话界面回复关键字“专业群”,获取入群方式。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
