机器学习在IT运维中的应用
现如今,人工智能和机器学习已经渗透进了每个领域,它从根本上改变和影响了这些领域的业务模式、技术架构以及方法论。同样在 IT 运维与 Devops 中也是如此。作为 IT 运维团队,我们真正关注的是机器学习如何提供实时事件的管理能力,从而帮助较大规模的企业提高服务质量。这其中的关键点就在于在用户发现问题之前提早探测异常,进而减少生产事故与中断带来的负面影响。
那么在 IT 运维中,机器学习是什么?
在 wiki 中机器学习的定义如下:
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.
也就是说,随着任务的不断执行,经验的积累会带来计算机性能的提升。
而在 IT 运维的语境中,这段话又可表述为:随着运维事件(运维数据)的不断产生,处理结果的积累会带来企业服务质量的提升。
我们期望在这个过程中可以建立一种行为模型,一方面它可以依据经验数据识别事件,将事件归类、归因。另一方面它又可以动态改变事件发生的条件,反过来影响事件发生的概率。例如监督式机器学习可以记录用户给定的告警及告警集群的活动,并相应地动态调整告警规则。这不同于传统管理工具的方式,你需要在一开始就对它们进行一定的配置,建立静态的规则,并期望它们留意你预先就知道会发生的事件。而机器学习则可以存在反馈机制,它能利用数据不断创建和更新行为模型,而不是使用静态的行为去寻找特定的结果。
并且,机器学习还可以在不指明具体方向的情况下自行探索,它可以发现事件隐含的特性,并依据此将相关的事件聚类,总结出特征向量。这种无监督的机器学习方式可以发现事件与事件、事件与运维结果之间的隐性关联。例如,它可以用于分析事件流和日志信息,从而找出异常的消息簇。之后,这些异常可以与某项运维结果或者事件相联系,从而分析出潜在的原因与症结。
在运维中应用机器学习的前提是具有运维数据、应用场景、特征工程、预测模型。
在运维过程中,会产生海量的运维数据,这其中有些可用于描述应用或者系统的运行状态、有些可用于标签、有些可用于进行经验反馈。这些巨量的、多维度的数据是机器学习建立行为模型的基础。运维数据从来源和用途上可分为机器数据、传输数据、代理数据和人为数据。
由应用或者 IT 系统自身产生,包括日志信息、监控数据等。这类数据的量最大、维度最广,它可以全面的描述应用、系统或集群的运行状况。
在不同系统之间通过网络传输的数据,可能包含系统或者业务数据。
由一些工具主动产生的数据,比如代码分析、系统测试数据等。这类数据一般是通过特定的方式产生,本身就带有一定的特征和标签性。
人产生的数据,比如系统操作、提的工单、QQ& 微信中的信息等。这类数据可以作为经验判断和标签的依据。
场景也就是所谓的任务。机器学习的核心就是用一个预测模型(线性回归、逻辑回归、SVD、决策树等)和一堆原始数据(运维数据)来得到一些预测结果。而这个预测结果就是任务的预测值。以下我列了几个在运维领域适用于机器学习的场景。
在 IT 运维中产生的成千上万的事件充满了噪音和冗余,单纯靠人工方式根本无法处理。机器学习可以自动化这个流程,类似于电子邮箱中的垃圾邮件过滤机制。利用机器学习,可以大幅度降低事件的噪音,只甄选真实的事件向用户告警。
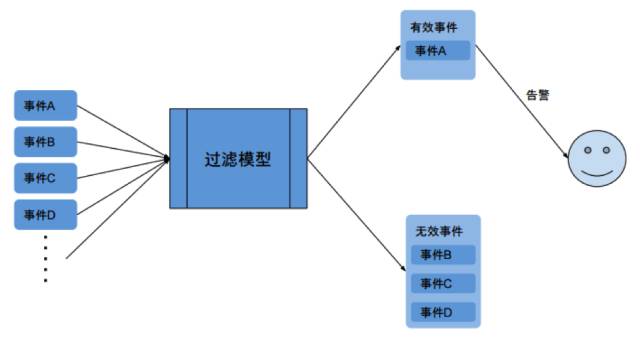
机器学习可以按照预先定义的模型,提取事件的特征,归类到不同的事件场景 (situation) 中,便于运维人员理解与处理。
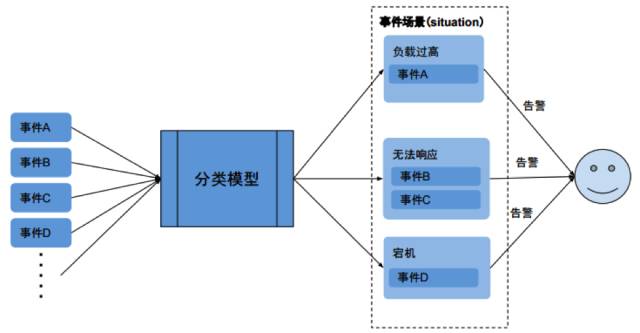
机器学习将事件归类到事件场景后,可以分析事件之间的关联、按照因果逻辑生成事件告警。这样运维人员看到的事件告警是经过处理的、具有逻辑关系和意义的结果信息。
对于以往发生的事件与告警,机器学习可以自动学习事件场景与处理策略。当类似事件再次发生时,机器学习可以将事件归类,并自动生成处理步骤,提供给运维人员。
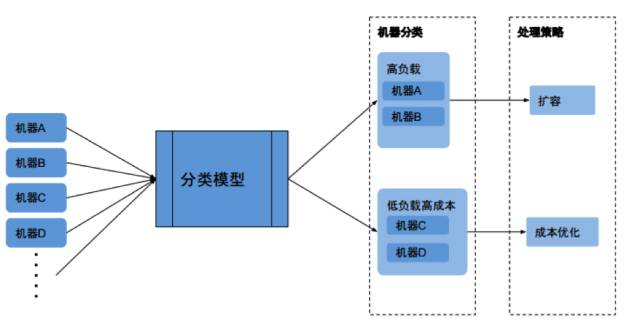
机器学习可以按照预先定义的模型,根据机器数据自动分类机器。这样运维人员可以针对不同的分类,做相应的分析与优化。
在机器学习中,一个预测模型的好坏往往取决于特征工程。坊间常说:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。由此可见特征工程在实际的机器学习中的重要性。从某些层面上来说,所使用的特征越好,得到的效果就越好。在有些时候,我们甚至可以使用一些不是最优的模型来训练数据,如果特征选择得好的话,依然会得到不错的结果。
而在运维中,如何选择特征是个领域和工程问题。
我们一般可以遵循以下流程来构建特征:
任务的确定:根据具体业务确定要解决的问题
数据的选择:收集数据,整合数据
数据的预处理:数据格式化、清洗、采样
特征的构造:利用领域知识和工程化方法构造和选择特征
计算模型:通过模型计算得到模型在该特征上所提升的准确率
上线测试:通过在线测试的效果来判断特征是否有效
在有了运维数据和应用场景(确定业务问题)后,如何建立一个预测模型能尽量的拟合数据,从而使得目标函数最优化则成为了解决运维问题的关键。
一般情况下预测模型可以分成两个子集:回归和分类。
它研究的是因变量和自变量之间的关系,以便做出关于连续变量的预测,如天气预报的最高温度的预测。在技术运维中,我们可以通过建立回归模型来预测下一个点的监控值,并通过设置动态阈值的方法来对异常数据进行检测。
与回归模型不同,分类的任务是分配离散的类标签给特定的观察对象作为预测的结果。回到上面的例子:在天气预报中的分类问题可能是对晴天、雨天或者雪天的预测。
分类任务可被分成两个主要的子类别:监督学习和无监督学习。
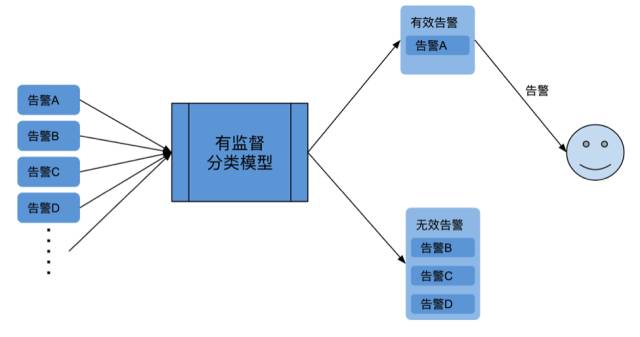
在监督学习中,用于构建分类模型的数据的类标签是已知的。例如,一个垃圾邮件过滤的数据集,它里面将包含垃圾邮件以及非垃圾邮件。在有监督的学习问题中,我们已经知道了训练集中的邮件要么是垃圾邮件,要么是非垃圾邮件。我们将会使用这些信息来训练我们的模型,以对新的邮件进行分类。在运维的场景中,我们可以通过建立有监督的分类模型,来消除告警噪音。
而与此相反,无监督学习任务处理未标记的实例,并且这些类必须从非结构化数据集中推断出来。通常情况下,无监督学习采用聚类技术,使用基于一定的相似性(或距离)的度量方式来将无标记的样本进行分组。例如在技术运维中,我们可以对机器进行聚类,便于运维人员找出它们彼此之间的关联,做相应的分析与优化。
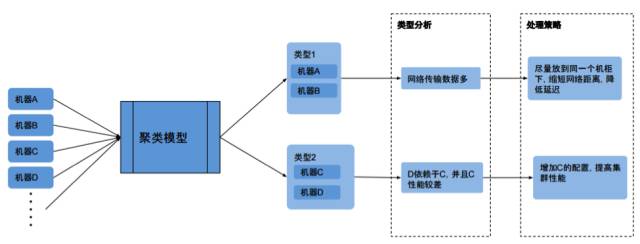
传统的运维方式基本都是依赖人工和静态规则,它们无法适应于动态复杂变化的场景。而人工智能可以让运维具备机器学习和算法的能力,从而在动态变化场景的复杂条件下,能够做出高效准确的决策判断。我们需要具有从“基于专家经验”到“基于机器学习”的观念转变,让 Ops AI 化(这个 AI 指的是 Algorithmic IT),从而推动运维朝着高效的方向发展。
随着大数据技术的发展以及数据产品的应用和推广,尤其是在工业和互联网领域,企业使用机器学习来提升收入或是降低成本的方式愈加有效。这其中,预防欺诈、定位电子广告的目标客户、内容推荐、建造更好的汽车、瞄准更好的潜在市场、优化媒体改善医疗保障服务等都证明大数据机器学习的多功能性和广泛的适用性。
大家都知道,机器学习技术不仅包含高深的理论算法模型以及对数据的合理利用,同时也离不开全面的工程技术支持。因此,QCon 2017 上海站特设会前两天的深度培训——综合介绍业界先进的机器学习算法模型及应用实践,以及飞速发展的大数据实时计算技术。我们邀请的国内一线互联网技术专家们,也将通过各自在不同领域的实践分享,向大家展示如何利用【机器学习实践】和【大数据实时计算】技术的融合来引领业务发展的,并引领大家走上成为机器学习工程师之路。
深度培训在 QCon 大会前 2 天,10 月 15 日 -16 日在上海宝华万豪酒店举办,培训包括 10 小时的授课和 2 个小时的提问交流,沉浸式学习热门技术,深度培训机器学习和大数据实时计算知识。

学习席位有限,点击 「 阅读原文 」即可进入大会官网,了解更多信息,点击官网“立即报名”按钮即可获取学习席位,开启成为机器学习工程之路。




