【深度学习】UC Berkeley 讲座教授王强:Deep Learning 及 AlphaGo Zero
UC Berkeley 讲座教授王强:Deep Learning 及 AlphaGo Zero(上)
AI 科技评论按:北京时间 10 月 19 日凌晨,DeepMind 在 Nature 上发布论文《Mastering the game of Go without human knowledge》(不使用人类知识掌握围棋),在这篇论文中,DeepMind展示了他们更强大的新版本围棋程序“AlphaGo Zero”,掀起了人们对AI的大讨论。而在10月28日,Geoffrey Hinton发表最新的胶囊论文,彻底推翻了他三十年来所坚持的算法,又一次掀起学界大讨论。
究竟什么是人工智能?深度学习的发展历程如何?日前,AI科技评论邀请到UC Berkeley机器人与工程实验室讲座教授王强博士,他为大家深入浅出讲解了何为人工智能,深度学习的发展历程,如何从机器感知向机器认知演进,并解析了AlphaGo与AlphaGo Zero的原理、学习过程、区别等。
嘉宾简介:王强博士,本科毕业于西安交通大学计算机科学与技术专业,后获得卡内基梅隆大学软件工程专业硕士学位、机器人博士学位。美国货币监理署(OCC)审计专家库成员、IBM商业价值研究院院士及纽约Thomas J. Watson研究院主任研究员。IEEE高级会员,并担任了2008、2009、2013及未来2018年CVPR的论文评委,同时是PAMI和TIP两个全球顶级期刊的编委。王强博士在国际顶级期刊发表了90多篇论文,并多次在ICCV,CVPR等大会做论文分享。其主要研究领域图像理解、机器学习、智能交易、金融反欺诈及风险预测等。
以下为他的分享内容,本文为上篇,包括Hinton引导下的机器学习的发展过程,机器感知和机器认知、深度学习在AI上的应用、深度学习在未来的应用。

大家好,今天有幸到 AI 科技评论给大家分享关于 AlphaGo Zero 和 Deep Learning 的一些内容,这些内容其实比较科普,希望大家能够喜欢。
我在考虑这个问题之前,一直在纠结到底是说一些技术性的东西,还是科普性的东西。现在AI和deep learning这么火,我们怎么认识它的整个过程呢。这里我分了几部分内容,第一部分是我对深度学习的整体介绍,第二部分是关于深度学习的一些应用和未来的一些前瞻性分享。
可能时间会长一点,这次的分享要求大家具备一定的机器学习或深度学习基本知识,这样估计才能明白今天我所讲的一些内容。自我介绍我就不多去说了,我现在在一些大学做讲座和客座教授,也有带学生,同时也在金融行业做了很多工程上的应用。
Hinton引导下的机器学习发展过程
开始咱们的第一部分,在这之前我第一个问题想谈谈AI到底是什么。Geoffrey Hinton最近提出了胶囊计划,同时在10月19号DeepMind团队又发布了AlphaGo Zero,发布之后引起了大家思考,我们该怎么去考虑什么是 AI。
在这之前,我们先来说说Hinton的胶囊计划,大家都知道Hinton是深度学习之父,也是神经网络先驱,他对深度学习和神经网络的诸多核心算法和结构,包括对深度学习这个名称本身提供了很多贡献,而且是非常巨大的贡献。
首先,他提出了BP反向传播算法,能够系统解决一些多层的神经网络隐含层连接权的学习问题,并在数学中给出了完全的推导。大家也知道,BP算法一直带领着机器学习,特别是神经网络的发展,用BP算法来计算导数的时候,随着网络深度的增加,传播的梯度的幅度会急剧的减小,结果就造成了整体loss function的最初几层的权重的倒数变得也非常小。
大家可能对这方面有所了解。当我们在BP算法中使用梯度下降法时,最初几层权重的变化非常缓慢,以至于我们不能从一些比较有用的样本里进行有效学习,其他比较臭名昭著的就是梯度弥散问题。如果当神经网络的最后几层有足够数量神经元,可能单独这几层足以对有效的标签进行建模,那么我们最终建模的时候是在后面最深度的这部分,那么对所有层随机初始化的方法的训练,不管是第一层还是第n层,训练得到的整个网络的性能和训练得到的浅层网络的性能是比较相似的,但是梯度弥散影响了BP的发展。
这时候Hinton又出现了,他做了一件事,他提出了一个设想,就是RBM,大家对RBM可能非常了解,我在这里不会做太多说明。我只说它一些基本的原理,RBM是两层的结构,一个是显式结构,一个是隐藏结构,它是一个对称链接、无自反馈的随机神经网络,其实它也是一种特殊的马尔可夫随机场网络。在这里头,他会面临一些问题,RBM里网络和网络之间隐单元和可见单元是不连接的,但是两个隐单元和两个可见单元之间是连接的,而且每个可见层的节点和隐藏层的节点处于激活状态的值是1,未激活状态的值是0。那么0和1的节点表明一个什么问题呢,代表整个模型选取哪些节点来使用。当节点值为1的时候是可以被使用的,处于0的时候是不被使用的。节点的激活概率是由可见层和隐藏层节点的分布函数来进行计算的。
在这里会有一个问题,RBM的参数一共用了三个,第一个就是W,W为可见单元和隐藏单元之间边的权重。B和A是可见层和隐藏层的偏置,有了这个偏置之后,给它赋值能量,就可以得到联合概率。
在这个问题中,只要看到梯度下降时的最大化L(θ)的内容,然后对W进行求导,求导时只需要V和H。但是如果涉及到所有可见层和隐藏层的组合,此时计算量非常大。那么在面对这些问题的时候,大家会不会认为RBM在机器学习里是不可用的呢?
这时候Hinton又做了一个算法,这个算法是非常著名的CD算法,当K等于1的时候,所有内容的计算量大幅减少,那么CDK到底是怎么形成的,这时神经网络已经发展到第三个优化的过程,第一步是NN,第二步是ANN,到了第三步有了BP,到了第四步有了RBM,到第五步有了CD。有了CD的好处在哪里呢?可以通过显层得到隐藏层状态,然后再用隐藏层经重构可见的向量的显示层。在这里我不会对CD做比较详尽的解释,大家之后可以去看看整个过程。接下来,到了第六步的时候,Hinton又提出了一个叫深度置信网络,就是我们经常看到的DBN,在这里比较有意思的是建立了观察数据和标签之间的联合分布。
前面这些内容PPT里都没有,大家听听就可以了。我只是想告诉大家机器学习的发展过程是什么样的,在RBM之后还有关键的一个就是我们所说的ReLU激活单元。Hinton之后又提出防止过拟合的Dropout功能,Dropout指的是在深度学习网络训练过程中,按照一定概率把没用的东西从网络中丢弃掉。
其实大家都知道,在深度学习里最大的问题是费时,第二个问题是容易过拟合,深度学习在早期的突破对这些内容也产生了很大的影响,这时候Hinton提出了capsule计划,这个计划其实更多的是来挑战计算机视觉的一些问题。大家知道计算机视觉,包括图像理解和图像处理的时候,一般会用到CNN网络,那么CNN网络里最关键的一块在哪里?最关键就是能够保证网络在变化的过程中识别效率是很高的。其实Hinton提出来一个问题,在capsule计划中,虽然位置发生了变化,但内容没有变化,他其实提出了坐标的观念,建立物体的坐标。面对一个物体,用不同的坐标点表示出来,那么物体在变化的时候,只是位置和速率的变化。在这里capsule虽然没有经过太多的验证,但给我们做图像理解时提供了非常好的方式。
说到这么多,大家会想到一个最大的问题,既然capsule这么好,那么有多少人会去用呢?其实大家都知道BP是一个反向的思维过程,人的思维过程是正向的,其实这次是Hinton对他30年所坚持的算法的颠覆。在这里我会简单介绍capsule计划的一部分,更细致的内容大家可以去看看Hinton最新发表的论文。在这里提醒一下大家,在看那篇论文的时候,需要考虑同变性和不变性的一些处理方式。
重新认识AI
说到这些问题之后,还有一个比较有意思的事情,最近Hinton的capsule和AlphaGo Zero的出现,让我们重新来认识AI到底是一个什么样的东西。我在这里会跟大家提出一个想法,可能不是很成熟,这个观点当时是由我的导师在今年4月份提出来的。
首先AI是灵活的,这是非常关键的,他灵活的表现在哪里,就是神经网络和机器学习的出现。第二个问题,它是通用的,可以用在不同的应用场景里,接下来的PPT会讲到。然后第三个,他是自适应的,后面给大家讲AlphaGo Zero的时候,会说明它表现出怎样的自适应。还有最关键的原则,他是从第一个规则开始学习起来的。
其实人工智能的建立过程需要模仿人的成长过程,就像小朋友刚来到世界之后的学习过程。还有一个问题,AI的基础到底是什么?其实我在这里也提出这样的一个想法供大家来探讨,深度学习加上强化学习,再加无监督学习,AI所有的基础都是在这上面形成的。那么从应用的角度来说,AI它到底会用在哪里呢?AI由两部分组成,第一部分叫机器感知,第二部分叫机器认知,怎么让AI从机器感知向机器认知转化,我觉得这是个比较有意义的事情。
机器感知和机器认知

那么机器感知是什么概念?通俗来讲,比如说当机器发现一个人感冒的时候,它是智能体温计。它通过和人进行接触之后,发现你的体温是38度,你发烧了,那么机器会给反馈,告诉你发烧了。它是认识这个物体,然后再给反馈,这个状态是机器感知的过程。那么怎么变成机器认知,变成机器认知的时候它是什么样的状况?发现你感冒以后,如果你旁边有一个医疗机器人,那么他会帮你去敷一个冰毛巾来帮助降温,然后同时再去持续观察你体温的变化,来判断给你敷冰毛巾的动作会带来多大的价值,这就是我们所说的机器认知过程。
认知过程要比感知过程复杂,感知就是认识之后反馈一个比较完整的信息状态,认知就是获得你的信息,然后再把这个信息传递给动作,做出动作之后再对动作的价值做评价,然后持续改进动作。
那么在机器感知里头,大家可能经常看到像语音、图像识别、视频识别、手势、触摸这些过程,在机器认知这个领域,包括自然语言处理、attention、知识处理、决策、attention等内容。
深度学习在AI上的应用
下面我给大家谈谈深度学习在AI里的一些应用,这里会先谈当前深度学习已经成功应用的成果。

第一部分就是大家知道的语音识别,提到语音识别大家也知道中国的科大讯飞,到2010年之后,语音识别引入了监督学习的深度学习方法,大家也知道在传统的通过计算机来处理语音的过程中,语音需要进行分帧、加窗、提取特征,包括MFCC、PLP,还有一些机器神经网络的声学模型,此外通常会使用一些比较粗糙的特征,在后面有了监督学习之后,就提出了end to end的识别模式。其实大家都知道语音识别的话,首先需要对语音进行解压缩,要还原成一个没有任何压缩的文件。一般语音识别的架构就两部分,第一部分是训练,第二部分是解码,其实这里头有很多关于机器学习的一些算法,大家可以自己去看看资料,包括像一些经典的HTK、特征融合的内容等。
第二部分就是图像识别,现在最流行的就是人脸识别,总结为两类,一类是二维图像识别,一类是三维图像识别。其实大家很清楚,做图像识别或图像理解的一些工程师、研究人员等,用张量的形式进行操作来得到图像处理过程,这块我不做太多说明,我会在后边的研究分享里给大家带来一些图像识别的案例。在这里不得不提李飞飞的ImageNet,她建了一个庞大的图片库,工程师要对进入图片库的图片做标签化,比如说图片中是不是一只猫,这是一只什么样的猫,哪里是猫的头,哪里是猫的尾巴。
目前在最新的图像理解领域,结合我的研究方向,有三块可以考虑。首先考虑的就是用CNN加RNN的方式,通过CNN理解原始图像,把它变成语义分布的形式,然后用RNN把高级表示变成自然语言,这就是我们所说的图像理解过程。比如你看到一个人站在这里,他到底是站在树边还是站在汽车边,怎么来判断他处于哪个状态,就会产生一系列的序列化处理方式。
第三部分就是NLP,特别是像现在很火的机器翻译,它面临的一些比较大的问题在哪里?我不会说NLP现在的发展情况如何,我会提出它目前最大的一些难点,有兴趣的同学可以在上面做一些相关研究。
第一个难点是单词的边界界定,在口语中的时候,词与词通常是连贯的,比如说你去了吗?词和词之间是连贯的,要界定字词边界通常使用方法的是给上下文做一个最佳的组合。
第二个难点就是词的意思,即消除歧义。我在IBM 沃森工作的时间比较长,相比中文,沃森在做语言识别处理的时候比较好办。大家都知道一个英文单词有多个意思,但是英文的一句话只代表一个意思,但中文就比较难,中文一个字就是一个意思,但是多个字组成一句话的时候可能代表很多个意思,这里我就不举太多例子。很多NLP技术比如像沃森在北美那边用得很好,为什么到中国会比较难呢。沃森进入中国有九年的时间,包括我在IBM的时候,一部分的汉语学家和一部分科学家推动沃森进入中国这种具有庞大历史文化背景的国家,进来之后它就面临一个问题,词义消歧的问题比较大。
第三个问题是句法的模糊性,第四是有瑕疵的、不规范的输入,比如吗和嘛。
2014年之后,大家开始用深度学习的方式来进行自然语言处理,利用CNN+RNN的方式来帮助进一步的识别,还有机器翻译、语言识别都是用卷入神经网络加上递归神经网络去做。
第四部分大家很清楚,即多模态图像,第四部分现在运用得很成功。多模态图像是什么呢,说白了就是看图说话。用户拍了一张照片之后,我们会用image captioning技术来匹配合适的文字,方便以后的检索,省去用户手动配字。2015年开始,做了一些监督学习的算法。先做CNN的预训练,在这个基础上做一些微调,然后再通过RNN网络做一些supervised的训练。
第五部分是电子游戏,游戏方面大家都知道AlphaGo,AlphaGo的出现大大提升了强化学习的进程。
深度学习在未来的应用
在未来,机器学习会在哪些人工智能领域产生巨大的作用呢,现在是个开始,在下面这些领域都会有比较大的一些突破。我在这里也会给大家一个简单的介绍。
第一个是IR,即信息检索。信息检索中比较有名的大会是SIGIR,国际计算机协会的信息检索大会,IR更关注于效率和规模,Manning在2016年的时候提出用NLP加IR来提升了IR的正确率和召回率。
第二部分就是大家经常会看到的目前在各个APP上面用到的mobile UI,即移动用户界面和对话,包括聊天机器人、一些类似于Siri的个人助理、声控界面等,在这里也有很多人在做研究,我在伯克利的一个实验室正在做一套新的深度学习模型,基于自然语言检索生成的方式,包括循环神经网络、序列到系列的模型。这个形成过程比较有意思,我们在这里做了22个响应模型,包括机器检索的神经网络,机器生成的神经网络,机器知识库问答系统和机器模板系统,一共有这四个功能体系。
第三部分就是实用的私人助理,像Siri、GoogNow等,这些在未来也会有比较好的发展。有些人在上面做了跨域的迁移学习过程,包括一些艺术的生成、电影脚本的生成,这些技术在未来都会用到深度学习的内容。
前面是给大家带来的比较笼统的认识,即深度学习到底能做哪些事情,另外还有深度学习发展的过程。
王强教授的 Deep Learning 及 AlphaGo Zero(下) 分享总结将于明天推送,敬请期待!
视频:
UC Berkeley 讲座教授王强:Deep Learning 及 AlphaGo Zero(下)
AI 科技评论按:北京时间10月19日凌晨,DeepMind在Nature上发布论文《Mastering the game of Go without human knowledge》(不使用人类知识掌握围棋),在这篇论文中,DeepMind展示了他们更强大的新版本围棋程序“AlphaGo Zero”,掀起了人们对AI的大讨论。而在10月28日,Geoffrey Hinton发表最新的胶囊论文,彻底推翻了他三十年来所坚持的算法,又一次掀起学界大讨论。
究竟什么是人工智能?深度学习的发展历程如何?日前,AI科技评论邀请到UC Berkeley机器人与工程实验室讲座教授王强博士,他为大家深入浅出讲解了何为人工智能,深度学习的发展历程,如何从机器感知向机器认知演进,并解析了AlphaGo与AlphaGo Zero的原理、学习过程、区别等。
嘉宾简介:王强博士,本科毕业于西安交通大学计算机科学与技术专业,后获得卡内基梅隆大学软件工程专业硕士学位、机器人博士学位。美国货币监理署(OCC)审计专家库成员、IBM商业价值研究院院士及纽约Thomas J. Watson研究院主任研究员。IEEE高级会员,并担任了2008、2009、2013及未来2018年CVPR的论文评委,同时是PAMI和TIP两个全球顶级期刊的编委。王强博士在国际顶级期刊发表了90多篇论文,并多次在ICCV,CVPR等大会做论文分享。其主要研究领域图像理解、机器学习、智能交易、金融反欺诈及风险预测等。
以下为他的分享内容,本文为下篇,主要内容是对AlphaGo和AlphaGo Zero详细的解释说明。上篇请参见:UC Berkeley 机器人与工程实验室讲座教授王强:Deep Learning 及 AlphaGo Zero(上)。
今年9月19号,DeepMind在Nature上发表了一篇论文,这篇论文是在人工智能、深度学习上具有颠覆性的文章。
大家知道,原来有AlphaGo,现在又出了AlphaGo Zero,那么AlphaGo和AlphaGo Zero之间到底有什么样的区别。
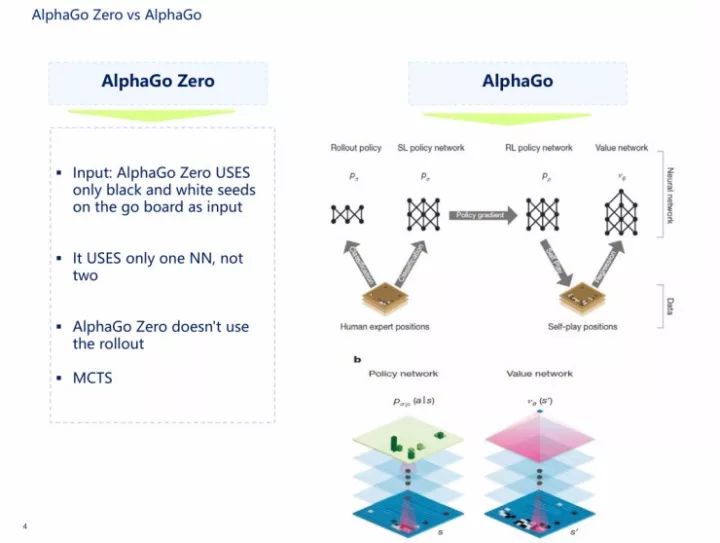
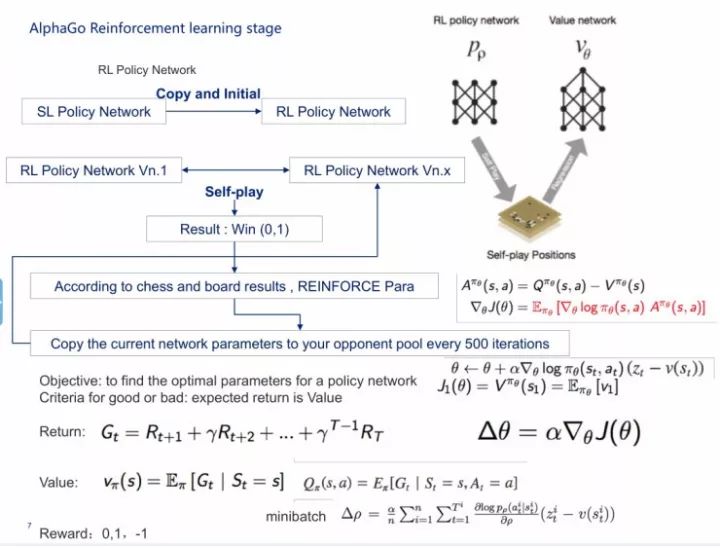
我先说AlphaGo,AlphaGo其实是由两个网络组成的,第一个是人类的经验,第二个是双手互搏、自学习。第一部分是监督策略网络,第二部分是强化策略网络,还有一个价值网络,再加上rollout网络,即快速走棋的网络,这四个网络再加上MCTS,就组成AlphaGo。
在AlphaGo里面输入了将近48种规则,但在AlphaGo Zero中,它的神经网络里面的输入只有黑子和白子,而且输入进的是一个网络,不是两套网络。这里所说的两套网络就是指价值网络和策略网络。AlphaGo和AlphaGo Zero的共同点是都用了MCTS。
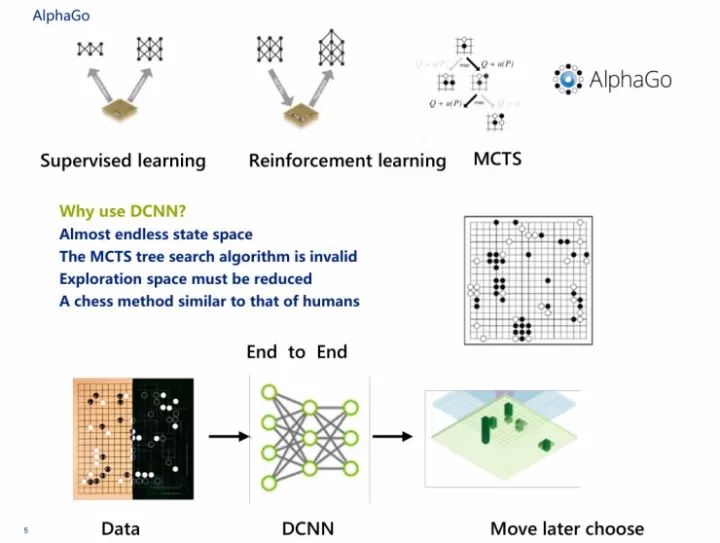
在这里会想到一个问题,为什么AlphaGo和AlphaGo Zero都会用到DCNN神经网络。
第一,大家都知道解决围棋问题是比较有意思的,围棋是19个格,19×19,361个落子的可能性,这时候落子可能存在的向量空间就是361乘以N,这个向量的状态空间几乎是无穷无尽的,大概计算量是10的171次方,用100万个GPU去运算100年也是算不完的。
第二,在这里MCTS的搜索方法是无效的。MCTS的搜索方式在这里我通俗地讲解下,随机拿一个苹果,和下一个苹果进行对比,发觉到哪个苹果比较大,我就会把小苹果扔掉,然后再拿这个大的和随机拿的下一个苹果去对比。对比到最后,我一定会挑出一个最大的苹果。
第三是我们希望走棋的时候的探索空间必须要缩小,要看这个子落下之后另一个子有几种可能性,不要说别人下了一个子之后还有360个空间,那这360个空间里头都有可能性。DeepMind比较厉害的地方是做了一个随机过程,而不是说在三百多个里选哪个是最好的,这个用计算机是算不出来的。
第四个问题,它必须要做一种类似于人类下棋的方法。那么刚才有朋友问到什么是端到端,端到端在AlphaGo里边表现得非常明确。我把数据扔给神经网络,然后神经网络马上给出我一个状态,这个状态有两个,包括目前状态和目前状态的价值,这非常有效,表示棋子落在哪里,以及赢的概率到底有多大。
在这里我先给大家讲一下AlphaGo的原理。一般的棋盘比如围棋、象棋等,我们第一步先做一件事,把棋盘的状态向量标记成s,围棋的棋盘是19*19,它一共有361个交叉点,每个交叉点有三个状态,1表示黑子,-1表示白子,0表示没有子,考虑到每个位置还可能有落子的时间等信息,我们可以用361乘以N维的向量表示棋盘的状态。
我们把棋盘的状态向量变成s,从0开始,s0表示的棋盘里的所有状态,没有任何子,s1落的是第一个子,s2是第二个子,第二步加入落子的状态a,在当前的状态s下,我们暂时不考虑无法落子的情况。下第一个子的时候,可供下一步落子的空间是361个,我们把下一步落子的行动也用361维的向量表示,变成a。第三步我们来设计一个围棋的人工智能程序,给定s状态,然后寻找最好的策略a,让程序按照这个策略去走。有四个条件,先是棋盘的状态s,寻找下棋最好的策略a,然后让程序按照这个策略a走棋,获得棋盘上最大的地盘,这是围棋人工智能程序的基本原理和思路。
DeepMind以及我们之前在沃森那边做的,主要流程如下:
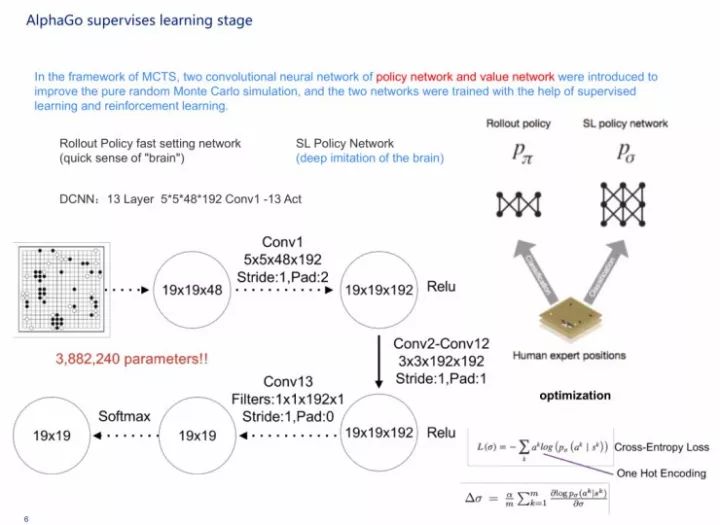
第一步先找一个训练样本,然后在观察棋局的时候,发现在每一个状态s里都会有落子a,那么这时候就会有一个天然的训练样本。
第二步,我们做一个网络,拿了一个3000万的样本,我们把s看成一个19×19的二维图像,然后乘以N,N指的是48种围棋的各种下赢的特征,落子向量a不断训练网络,这样就得到了一个模拟人下围棋的神经网络。
第三步我们设计一个策略函数和一个概率分布,我们拿到一个模拟人类棋手的策略函数跟某个棋局的状态s,可计算出人类选手可能在棋盘落子的概率分布,每一步选择概率最高的落子,对方对子后重新再算一遍,多次进行迭代,那就是一个和人类相似的围棋程序,这是最开始的设计思维和方式,策略函数和概率分布。
其实DeepMind还不是很满意,他们设计好这个神经网络之后,可以和六段左右过招,互有胜负,但还是下不过之前从沃森中做出来的一个电脑程序。这时候,DeepMind把他们的函数与从沃森中衍生出来的程序的函数算法结合在一块,对原来的算法重新做了一个完整详细的修正。
DeepMind最初对围棋一概不知,先假设所有落子的分值,这个大家一定要记住,在做任何科学研究的时候,当你发现你一无所知的时候,一定先要设定一个值,这个值千万不能是零。然后第二部分就简单了,就像扔骰子一样,从361种方法里随机选一个走法,落第一个子a0,那么棋盘状态就由s0变为s1,对方再走一步,这时候棋盘状态就变成s2,这两个人一直走到状态sN,N也许是360,也许是361,最后一定能分出胜负,计算机赢的时候把R值记为1。
从s0、a0开始再模拟一次,接下来如PPT中卷积所示,做激活函数。在下到10万盘次之后,这时候AlphaGo得到了非常完整的落子方案,比如说第一个子落在哪里赢的可能性比较大。
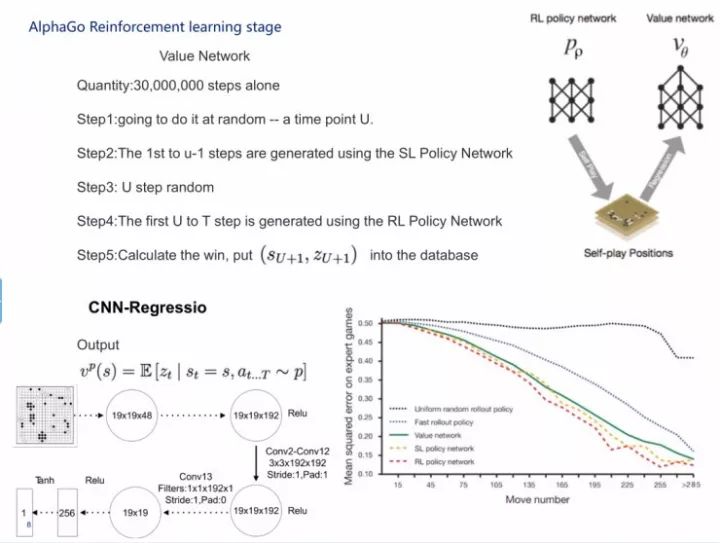
MCTS在这里起的作用是什么呢?MCTS能保证计算机可以连续思考对策,在比较的过程中发现最好的落子方式。在这之后,DeepMind发现用MCTS还不是非常好,他们就开始设计了一个比较有意思的东西,就是评价函数,我在这里就不太多讲评价函数。
AlphaGo的监督学习过程其实由两个网络组成,一个是从其他人中获得的学习经验,先是做了一个softmax,即快速落子,它的神经网络比较窄,第二部分是深度监督式神经网络。
到了做强化学习的时候,它会把原来通过机器学习过来的监督神经网络copy到强化神经网络里,然后进行初始化,让强化神经网络作为对手和另一个强化神经网络进行互相学习,来选择一个最优的结果。具体细节如PPT所示,500次做一次迭代,在这里会用到一些梯度下降的方式。
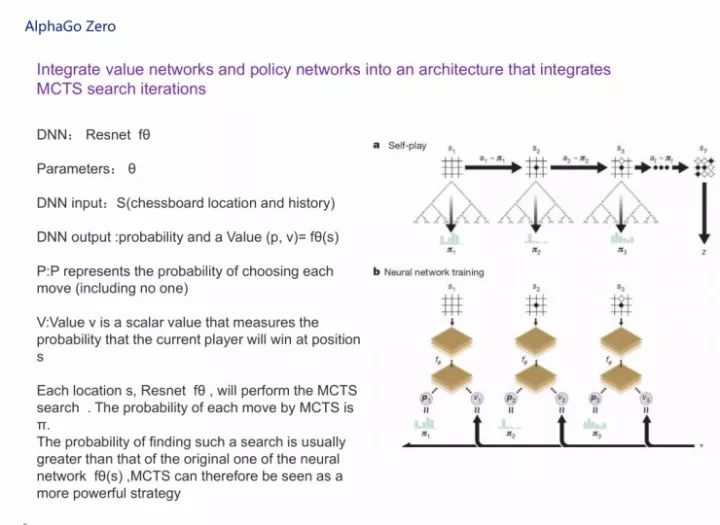
前面是我们看到的AlphaGo,接下来看AlphaGo Zero,它对原来的过程做了完整的简化,集成了价值网络和策略网络,放到一个架构里头,即将MCTS和两个神经网络放在一块。这两个神经网络其实用了一个比较有意思的神经网络,叫Resnet,Resnet的深度大家也知道,曾经做到过151层,我在这里就不讲得特别详细了。如PPT所示,它的参数是θ,深度神经网络的输入是s,输出落子概率(p, v)。
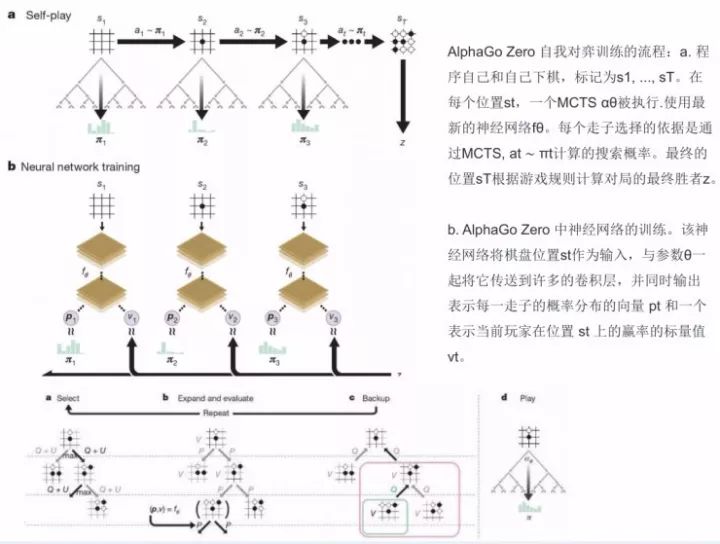
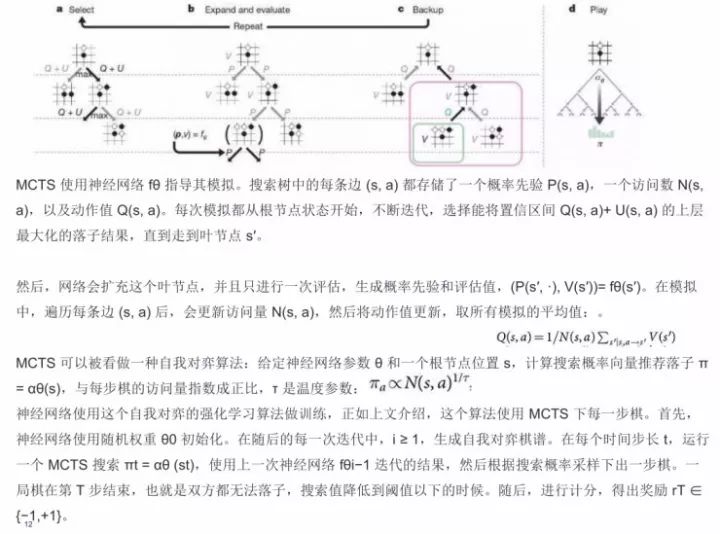
在这里我给大家大概说说AlphaGo Zero自我对弈训练的流程。
第一步是程序自己和自己下棋,标记为s1, ..., sT。在每个位置st,一个MCTS αθ被执行。每个走子选择的依据是通过MCTS(选择最好的θ参数)、at ∼ πt计算的搜索概率。最终的位置sT根据游戏规则计算对局的最终胜者z。
第二步是AlphaGo Zero中神经网络的训练。该神经网络将棋盘位置st作为输入,与参数θ一起将它传送到许多的卷积层,并同时输出表示每一走子的概率分布的向量pt和一个表示当前玩家在位置st上的赢率的标量值vt。同时MCTS 使用神经网络 fθ 指导其模拟。
搜索树中的每条边 (s, a) 都存储了一个概率先验 P(s, a)(概率先验是在CNN里非常关键的问题)、一个访问数 N(s, a)以及动作值 Q(s, a)。每次模拟都从根节点状态开始,不断迭代,选择能将置信区间 Q(s, a)+ U(s, a) 的上层最大化的落子结果,直到走到叶节点s′。 然后,网络会扩充这个叶节点,并且再进行一次评估,生成概率先验和评估值。在模拟中,遍历每条边(s, a) 后,会更新访问量N(s, a),然后将动作值更新,取得所有模拟的平均值。
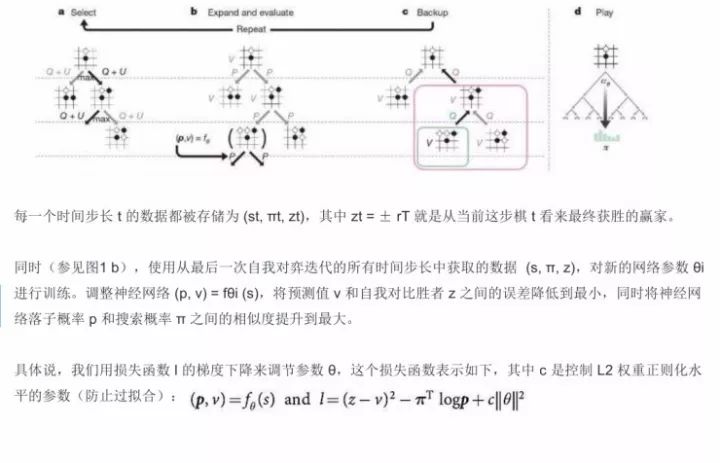
此外还要做时间步长的计算,还有L2 权重正则化水平参数(防止过拟合)的覆盖,包括用损失函数的梯度下降来进行调节。
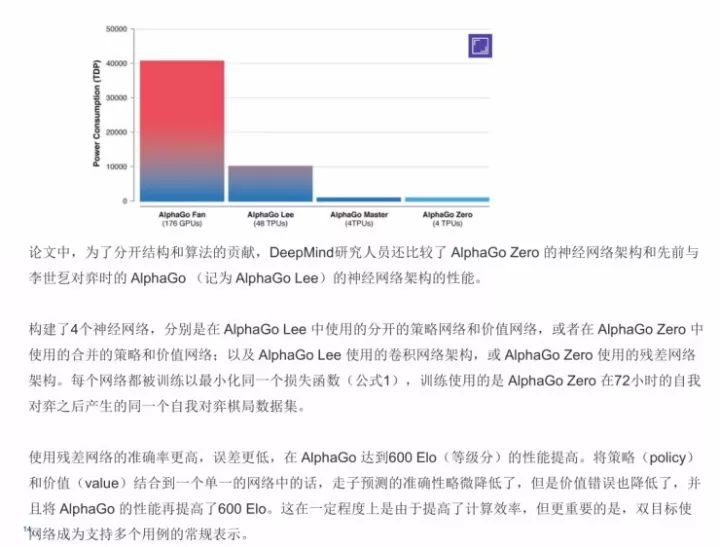
在这里还有一件非常好玩的事情,他们用了张量处理单元(TPU),同时还做了一系列的说明,在训练网络时完全用了分布式的训练方式,用了176个GPU,48个TPU,其实AlphaGo Zero比较厉害的地方的是只用了四个TPU去做。DeepMind还比较了AlphaGo Zero的神经网络架构和AlphaGo的神经网络架构的性能,在性能上我就不多说了。
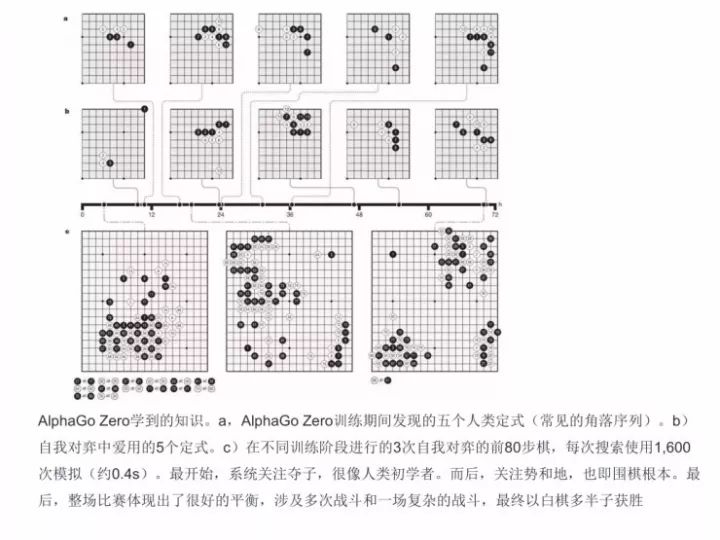
AlphaGo Zero比较厉害的地方在哪里呢?一是它发现了五个人类的定式(常见的角落的序列),二是自我对弈中爱用的5个定式,三是在不同训练阶段进行的3次自我对弈的前80步棋,每次搜索使用1,600 次模拟(约0.4s)。
最开始,系统关注夺子,很像人类初学者,这是非常厉害的,白板+非监督学习方式完全模拟到人类初学者。后面,关注势和地,这是围棋的根本。最后,整场比赛体现出了很好的平衡,涉及多次战斗和一场复杂的战斗,最终以白棋多半子获胜。其实这种方式是在不停的参数优化过程中做出的一系列工作。

接下来大概说说AlphaGo和AlphaGo Zero的一些比较。
第一,神经网络权值完全随机初始化。不利用任何人类专家的经验或数据,神经网络的权值完全从随机初始化开始,进行随机策略选择,使用强化学习进行自我博弈和提升。
第二,无需先验知识。不再需要人为手工设计特征,而是仅利用棋盘上的黑白棋子的摆放情况,作为原始输入数据,将其输入到神经网络中,以此得到结果。
第三,神经网络结构的复杂性降低。原先两个结构独立的策略网络和价值网络合为一体,合并成一个神经网络。在该神经网络中,从输入层到中间层是完全共享的,到最后的输出层部分被分离成了策略函数输出和价值函数输出。
第四,舍弃快速走子网络。不再使用快速走子网络进行随机模拟,而是完全将神经网络得到的结果替换随机模拟,从而在提升学习速率的同时,增强了神经网络估值的准确性。
第五,神经网络引入Resnet。神经网络采用基于残差网络结构的模块进行搭建,用了更深的神经网络进行特征表征提取。从而能在更加复杂的棋盘局面中进行学习。
第六,硬件资源需求更少。AlphaGo Zero只需4块TPU便能完成训练任务。
第七,学习时间更短。AlphaGo Zero仅用3天的时间便能达到AlphaGo Lee的水平,21天后达到AlphaGo Master的水平。
今天讲这么多,大家在听我讲这个科普类的东西时,可能会需要有一些比较好的基础知识,包括MCTS、CNN、DNN、RNN、Relu、白板学习、Resnet、BP、RBM等,我希望大家对我讲的这些神经网络有一个比较详细的了解。
第一是了解它的基本网络架构,第二是去了解优点和缺点在哪里。第三个是它的应用,是用在语言处理还是图像上,用的时候它有哪些贡献。到了第四步的时候,当你了解这些深度学习的过程之后,你可以考虑在工程上应用这些算法,再建立你的数据模型和算法。到第五步可以开始用MATLAB或Python去做复现,然后最后再去看深度学习算法对自己所做的工作有什么样的回报。

然后特别是做一些微调的工作,这时候你很有可能就能发表论文了。在这种情况下,我给大家提供一个比较好的思维方式,如果大家去用深度学习,怎么能保证从目前简单的AI的应用工作变成复杂的应用工作。其实,这是从机器感知到机器认知的转变过程。
机器感知在这里要做一个总结,机器感知是指从环境中获取目标观测信息,这是第一步。到了机器认知就比较有意思了,是将当前的状态映射到相应操作,比如说旁边的车要发动了,可能会撞到你,这时候你戴的手表可能会智能提醒你,看你的动作是否有改变,从而判断提醒是否有效,再进一步提高报警级别。
其实在机器认知的过程中,可能会用到大批量的深度学习和NLP技术、图像理解技术、语音识别技术,多模态图像识别技术,在这些领域去做一些组合的时候,可能对大家的研究比较有意义。
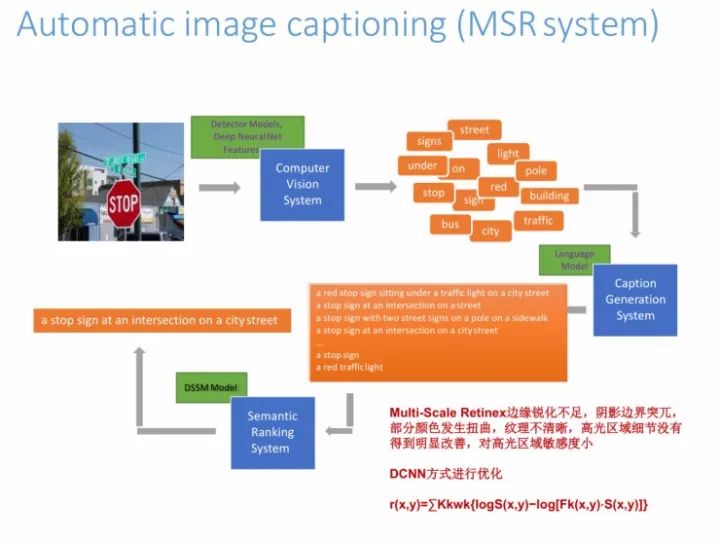
说说我们最近做的一些工作,这是一个MSR系统,我们在用DCNN的方法做优化,用image captioning来做这个系统的时候会面临一些问题。在这里用Multi-Scale Retinex技术会存在一些问题,比如边缘锐化不足,阴影边界突兀比较大, 部分颜色发生扭曲等。我们试过了很多方法,也做了很多参数的优化处理,发现效果都不是很好,Hinton出了capsule之后,我们立马开始去对物体坐标性的点进行描述处理,而不用BP的反向处理方式,现在我们正在做一些算法的猜想证明。

最后的结果如下:我们在训练图片的时候,它越来越能够认识到人在做什么事。图中是人和机器所看到的,机器会认为这个人在准备食物,但其实人会认为她在做更实际的东西,会把所有的图片都认出来,我们现在已经做到跟人的匹配率达到97.8%,也是通过反复Resnet学习去做出来的。
下面是在COCO上的结果。
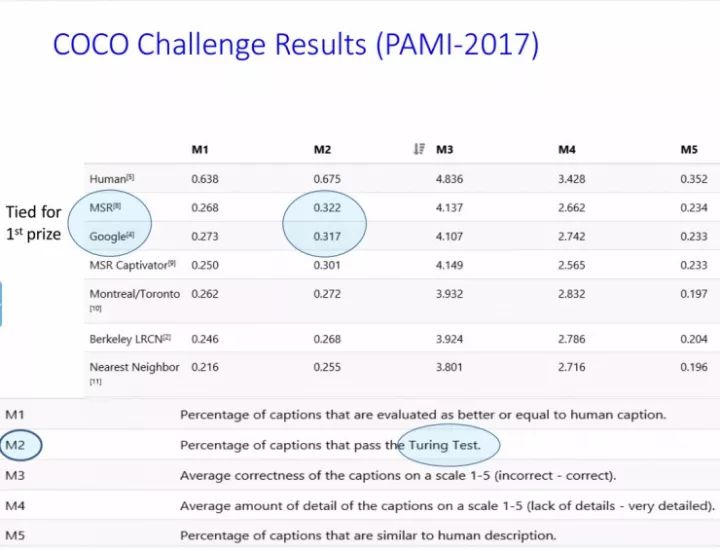
今天公开课就结束了,我希望大家去看下AlphaGo Zero最新的论文,然后去看看Hinton的胶囊计划,如果大家在这里有什么想法可以和我来探讨。还有一个论坛大家可以进来去看一下,地址是mooc.ai,大家可以看这里边有什么需要去讨论的东西。
视频:

人工智能赛博物理操作系统
AI-CPS OS
“人工智能赛博物理操作系统”(新一代技术+商业操作系统“AI-CPS OS”:云计算+大数据+物联网+区块链+人工智能)分支用来的今天,企业领导者必须了解如何将“技术”全面渗入整个公司、产品等“商业”场景中,利用AI-CPS OS形成数字化+智能化力量,实现行业的重新布局、企业的重新构建和自我的焕然新生。
AI-CPS OS的真正价值并不来自构成技术或功能,而是要以一种传递独特竞争优势的方式将自动化+信息化、智造+产品+服务和数据+分析一体化,这种整合方式能够释放新的业务和运营模式。如果不能实现跨功能的更大规模融合,没有颠覆现状的意愿,这些将不可能实现。
领导者无法依靠某种单一战略方法来应对多维度的数字化变革。面对新一代技术+商业操作系统AI-CPS OS颠覆性的数字化+智能化力量,领导者必须在行业、企业与个人这三个层面都保持领先地位:
重新行业布局:你的世界观要怎样改变才算足够?你必须对行业典范进行怎样的反思?
重新构建企业:你的企业需要做出什么样的变化?你准备如何重新定义你的公司?
重新打造自己:你需要成为怎样的人?要重塑自己并在数字化+智能化时代保有领先地位,你必须如何去做?
AI-CPS OS是数字化智能化创新平台,设计思路是将大数据、物联网、区块链和人工智能等无缝整合在云端,可以帮助企业将创新成果融入自身业务体系,实现各个前沿技术在云端的优势协同。AI-CPS OS形成的数字化+智能化力量与行业、企业及个人三个层面的交叉,形成了领导力模式,使数字化融入到领导者所在企业与领导方式的核心位置:
精细:这种力量能够使人在更加真实、细致的层面观察与感知现实世界和数字化世界正在发生的一切,进而理解和更加精细地进行产品个性化控制、微观业务场景事件和结果控制。
智能:模型随着时间(数据)的变化而变化,整个系统就具备了智能(自学习)的能力。
高效:企业需要建立实时或者准实时的数据采集传输、模型预测和响应决策能力,这样智能就从批量性、阶段性的行为变成一个可以实时触达的行为。
不确定性:数字化变更颠覆和改变了领导者曾经仰仗的思维方式、结构和实践经验,其结果就是形成了复合不确定性这种颠覆性力量。主要的不确定性蕴含于三个领域:技术、文化、制度。
边界模糊:数字世界与现实世界的不断融合成CPS不仅让人们所知行业的核心产品、经济学定理和可能性都产生了变化,还模糊了不同行业间的界限。这种效应正在向生态系统、企业、客户、产品快速蔓延。
AI-CPS OS形成的数字化+智能化力量通过三个方式激发经济增长:
创造虚拟劳动力,承担需要适应性和敏捷性的复杂任务,即“智能自动化”,以区别于传统的自动化解决方案;
对现有劳动力和实物资产进行有利的补充和提升,提高资本效率;
人工智能的普及,将推动多行业的相关创新,开辟崭新的经济增长空间。
给决策制定者和商业领袖的建议:
超越自动化,开启新创新模式:利用具有自主学习和自我控制能力的动态机器智能,为企业创造新商机;
迎接新一代信息技术,迎接人工智能:无缝整合人类智慧与机器智能,重新
评估未来的知识和技能类型;
制定道德规范:切实为人工智能生态系统制定道德准则,并在智能机器的开
发过程中确定更加明晰的标准和最佳实践;
重视再分配效应:对人工智能可能带来的冲击做好准备,制定战略帮助面临
较高失业风险的人群;
开发数字化+智能化企业所需新能力:员工团队需要积极掌握判断、沟通及想象力和创造力等人类所特有的重要能力。对于中国企业来说,创造兼具包容性和多样性的文化也非常重要。
子曰:“君子和而不同,小人同而不和。” 《论语·子路》云计算、大数据、物联网、区块链和 人工智能,像君子一般融合,一起体现科技就是生产力。
如果说上一次哥伦布地理大发现,拓展的是人类的物理空间。那么这一次地理大发现,拓展的就是人们的数字空间。在数学空间,建立新的商业文明,从而发现新的创富模式,为人类社会带来新的财富空间。云计算,大数据、物联网和区块链,是进入这个数字空间的船,而人工智能就是那船上的帆,哥伦布之帆!
新一代技术+商业的人工智能赛博物理操作系统AI-CPS OS作为新一轮产业变革的核心驱动力,将进一步释放历次科技革命和产业变革积蓄的巨大能量,并创造新的强大引擎。重构生产、分配、交换、消费等经济活动各环节,形成从宏观到微观各领域的智能化新需求,催生新技术、新产品、新产业、新业态、新模式。引发经济结构重大变革,深刻改变人类生产生活方式和思维模式,实现社会生产力的整体跃升。
产业智能官 AI-CPS
用“人工智能赛博物理操作系统”(新一代技术+商业操作系统“AI-CPS OS”:云计算+大数据+物联网+区块链+人工智能),在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的认知计算和机器智能;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。


长按上方二维码关注微信公众号: AI-CPS,更多信息回复:
新技术:“云计算”、“大数据”、“物联网”、“区块链”、“人工智能”;新产业:“智能制造”、“智能农业”、“智能金融”、“智能零售”、“智能城市”、“智能驾驶”;新模式:“财富空间”、“特色小镇”、“赛博物理”、“供应链金融”。
点击“阅读原文”,访问AI-CPS OS官网
本文系“产业智能官”(公众号ID:AI-CPS)收集整理,转载请注明出处!
版权声明:由产业智能官(公众号ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源。部分文章推送时未能与原作者取得联系。若涉及版权问题,烦请原作者联系我们,与您共同协商解决。联系、投稿邮箱:erp_vip@hotmail.com



