【“强化学习之父”萨顿】预测学习马上要火,AI将帮我们理解人类意识
编译自 KDnuggets
量子位 出品
地处加拿大埃德蒙顿的阿尔伯塔大学(UAlberta)可谓是强化学习重镇,这项技术的缔造者之一萨顿(Rich Sutton)在这里任教。

△ 萨顿
萨顿常被称为“强化学习之父”,他对强化学习的重要贡献包括时序差分学习和策略梯度方法。
如果你研究过强化学习,可能对他和巴尔托(Andrew Barto)合著的一本书很熟悉:《强化学习导论》(Reinforcement Learning, an introduction)。这本书被引用了2.5万多次,如今,第二版即将出版,全书草稿也已经在网上公开。

△ Reinforcement Learning, an introduction草稿 http://incompleteideas.net/book/bookdraft2017nov5.pdf
巴尔托是萨顿的博士论文导师,萨顿的博士论文《强化学习的时间学分分配》(Temporal Credit Assignment in Reinforcement Learning)中,引入了一种评价器结构和“时间信用分配”。他们把“显而易见”的强化学习理念,变成了一个以数学为基础的可行理论。
萨顿获得了斯坦福大学心理学学士学位(1978年)和硕士学位(1980),以及马萨诸塞大学安姆斯特分校计算机博士学位(1984)。
从1985年到1994年,Sutton担任GTE实验室的首席技术员。之后,他在麻省大学安姆斯特分校做了3年的高级研究员,然后又到AT&T香农实验室做了5年的首席技术员。2003年以来,他一直在阿尔伯塔大学计算机系担任教授兼iCORE主席,领强化学习和人工智能实验室。
2003年以来,萨顿在阿尔伯塔大学计算机系任教授、iCORE主席,领导着强化学习和人工智能实验室。今年6月,DeepMind在埃德蒙顿和阿尔伯塔大学联合设立首个海外研究院,萨顿也是这个研究院的领导者之一。
最近,机器学习和数据科学社区KDnuggets董事长,数据科学会议KDD和ACM SIGKDD的联合发起者Gregory Piatetsky专访了萨顿。
萨顿在专访中(再次)科普了强化学习、深度强化学习,并谈到了这项技术的潜力,以及接下来的发展方向:预测学习。
小编将专访内容搬运如下:
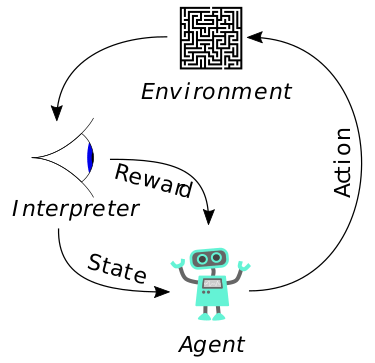
△ 典型的强化学习过程
我在上世纪80年代遇到了Rich Sutton,我和他当时都刚开始在波士顿地区的GTE实验室读博士。我研究智能数据库,他在强化学习部门,但是我们在GTE实验室的项目还远没有实际应用。我们经常下象棋,我们俩在这方面势均力敌,但在机器学习方面,Rich远远领先于我。
Q:强化学习的主要思想是什么?它与监督学习有何不同?
萨顿:在与世界的正常互动过程中,强化学习会通过试错法利用奖励来学习。因此,它跟自然学习过程非常相似,而与监督学习不同。
在监督学习中,学习只发生在一个特殊的训练阶段,这个阶段中会出现一个正常情况下不会出现的监督或教学信号。
例如,语音识别目前通过监督学习来完成,需要使用大量的语音数据集和正确的文本内容。这些文本内容就是一种监督信号,等系统开始工作、输入了新的语音时,就没有这个监督信号了。
而AI打游戏,通常就是通过强化学习来实现的,需要利用游戏的结果作为奖励。即使你玩了一个新游戏,也会看到自己是赢是输,并且可以用强化学习算法来提高你的游戏技术。
监督式游戏学习方法则需要借助一些“正确”的动作来实现,这些动作可以来自人类专家。这很方便,但在正常的游戏中是不可用的,而且会导致学习系统的技能局限在人类专家的技能范畴内。在强化学习中,你可以用较少的训练信息,这样做的优势是信息更充足,而且不受监督者的技能限制。
Q:你跟Andrew Barto合著的经典著作《强化学习导论》的第二版很快就要出版,具体什么时候?第二版的主要修订了哪些内容?你能跟我们讲讲新章节里关于强化学习与心理学之间有趣联系吗(第14章)?还有跟神经科学之间的有趣联系(第15章)?
萨顿:第二版的完整草稿目前已经可以在richsutton.com上看到。Andy Barto和我正在定稿:验证所有的参考文献,诸如此类。印刷版将于明年初发行。
从第一版发行以来的20年里,强化学习领域发生了很多事情。其中最重要的或许是强化学习思想对神经科学的巨大影响,现在,大脑奖励系统的标准理论是,它们是一种时间差异学习的实例(这是强化学习的基本学习方法之一)。
特别地,现在的理论认为,神经递质多巴胺的主要作用是携带时间差异误差,也称为奖励预测误差。这是一个巨大的发展,有许多来源、影响和测试,我们只能在书中进行概括。15和14章中介绍的这项发展和其他的发展概括了它们在心理学中的重要前提。
总的来说,第二版比第一版多了三分之二内容。函数逼近的内容从一章扩充到五章。还有关于心理学和神经科学的两个新章节。在强化学习的前沿也有一个新章节,有一节专门介绍它的社会影响。所有的东西都在这本书中不断更新和扩展。例如,新的应用程序章节涵盖了Atari游戏和AlphaGo Zero。
Q:什么是深度强化学习?它与强化学习有何不同?
萨顿:深度强化学习是深度学习和强化学习的结合。这两种学习方式在很大程度上是正交问题,二者结合得很好。
简而言之,强化学习需要通过数据逼近函数的方法来部署其所有的组件——值函数、策略、世界模型、状态更新——而深度学习是最近开发的函数逼近器中最新、最成功一个。
我们的教科书主要介绍线性函数逼近器,并给出一般情况下的方程。我们在应用一章和一节中介绍了神经网络,但要充分了解深度强化学习,就必须用Goodfellow、Bengio、和Courville的《深度学习》来补充我们的书。
Q:强化学习在游戏中取得了巨大的成功,例如AlphaGo Zero。你预计强化学习还将在哪些方面有优异表现?
萨顿:当然,我相信,从某种意义上讲,强化学习是人工智能的未来。有人认为,智能系统必须能够在不接受持续监督的情况下自主学习,而强化学习正是其中的最佳代表。一个AI必须能够自己判断对错,只有这样才能扩展到大量的知识和一般技能。
Q:Yann LeCun评论说,AlphaGo Zero的成功很难推广到其他领域,因为它每天都玩数百万局游戏,但是你不能在现实世界里跑得更快。强化学习在哪些方面目前还没有成功(例如,当反馈稀疏时)?如何能够解决?
萨顿:Yann应该会认同这个观点:关键是要从普通的无监督数据中学习。我和Yann也都会认同这样一个观点:在短期内,这将通过专注于“预测学习”来实现。
预测学习可能很快就会成为一个流行词。它的意思是预测将要发生的事情,然后根据实际情况进行学习。因为你从发生的事情中学习,没有一个监督员告诉你应该预测什么。但因为你通过等待发现了结果,你就有了一个监督信号。预测学习是无监督的监督式学习。预测学习可能会在应用中取得重大进展。
唯一的问题是,你希望把预测学习看成是监督学习还是强化学习的产物?强化学习的学生知道强化学习有一个主要的子问题,称为“预测问题”,如何有效地解决这个问题正是大部分算法工作的重点。事实上,第一篇讨论时间差异学习的论文题目是《学会用时间差异的方法来预测》。
Q:20世纪80年代,当研究强化学习时,你认为它会取得这样的成功吗?
萨顿:20世纪80年代,强化学习根本没有流行。它本质上并不是一个科学或工程的概念。但却是一个显而易见的想法。对心理学家来说很明显,对普通人来说也很明显。所以我认为,这显然是一件值得研究的事情,最终会得到认可。
Q:强化学习的下一个研究方向是什么?你现在在做什么?
萨顿:除了预测学习之外,我想说的是,当我们有用训练过的世界模型来做规划的系统时,下一个重大进步就会到来。
我们目前拥有优秀的规划算法,但只有当有模型提供给它们时才行,就像所有游戏系统中所看到的那样,模型是由游戏规则(和自我对局)提供的。但我们在现实世界中并没有跟游戏规则类似的东西。我们需要物理定律,没错,但我们也需要知道很多其他的事情,从如何走路和观察到别人如何回应我们所做的事情。
我们在第八章的Dyna系统中描述了一个完整的规划和学习系统,但却局限为几种方式。第17章阐述了可能克服这种局限的方法。我将从那里入手。
Q:强化学习可能是通用人工智能(AGI)发展的核心。你的观点是什么——在可预见的未来,研究人员会开发AGI吗?如过会,这将会对人类产生巨大的好处,还是像埃隆·马斯克(Elon Musk)警告的那样,会对人类构成威胁?
萨顿:我认为人工智能是试图通过制造与人类思想类似的东西来理解人类的思想。正如费曼所说,“我无法创造的东西,我就不理解它”。在我看来,会发生的重大事件是我们即将第一次真正理解意识。这种认识本身将产生巨大的影响。
这将是我们这个时代最伟大的科学成就,其实任何时候都是如此。它也将是有史以来人文学科最伟大的成就——深刻地理解我们自己。如果这样来看待,那就不会把它看成是一件坏事。虽然是挑战,但并不是坏事。我们将揭示哪些东西是真实的。那些不想让它成为现实的人会把我们的工作看成是坏事,就像科学抛弃了灵魂的概念一样,那些珍视这些想法的人认为是坏的。
毫无疑问,当我们更深入地了解大脑如何运作时,我们今天所珍视的一些观点也会面临同样的挑战。
Q:当你远离电脑和智能手机的时候,你喜欢做什么?你最近读过什么书?你喜欢什么书?
萨顿:我是自然的爱好者,也喜欢哲学、经济学和科学的思辨思想。我最近读了尼尔·斯蒂芬森的《Seveneves》、尤瓦尔·赫拉利的《人类简史》,以及G.爱德华·格里芬的《美联储传》。
☞ 【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞ 【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞ 【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞ 【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞ 【TFGAN】谷歌开源 TFGAN,让训练和评估 GAN 变得更加简单
☞ 【NIPS 2017】清华大学人工智能创新团队在AI对抗性攻防竞赛中获得冠军
☞ 【英伟达NIPS论文AI脑洞大开】用GAN让晴天下大雨,小猫变狮子,黑夜转白天
☞ 【BicycleGAN】NIPS 2017论文图像转换多样化,大幅提升pix2pix生成图像效果


