推荐系统工程化落地技术点汇总
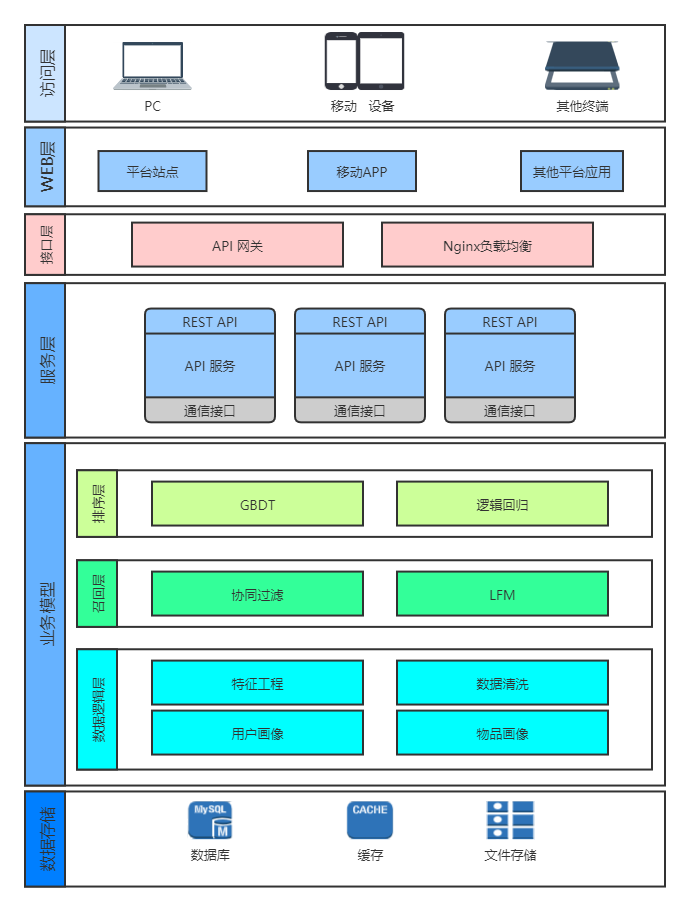
这张图是上个月给51CTO和第四范式做公开课的时候PPT中的一个图,这张图也是目前企业中将推荐系统落地的常见方式。我们从这张图中可以看到,实际上,一个推荐系统的落地从大的层面上我们可以将其分为6个部分。从下向上看,分别是数据存储、业务模型、服务层、接口层、web层和访问层。
很多研究推荐系统的初学者一般都会将重点放在业务模型这一块。不得不说,业务模型的确是推荐系统的核心,因为在整个推荐系统工程化的过程中,都离不开业务模型。但事实上,业务模型往往只占整个推荐系统的50%比重甚至还会更低,而更重要的就是如何让一个推荐系统能够更好地流转。
推荐系统的整套体系实际上是一个非常完整的体系,它包括了数据的采集、存储,以及数据如何喂到模型里,模型又如何对其进行加工,加工之后又将结果怎么样保存,最后怎么将结果提供给用户,在提供给用户这个步骤中,我们还需要考虑用户量的问题,因为用户量变大,那么就意味着接口的负载压力增强,就需要去采用一系列的负载均衡的手段来增加整体的并发量,从而将接口中的数据提供出去。在接口中的数据提供出去之后,我们还需要考虑,这个数据在客户端是如何拼装的,当然,这一个部分往往有单独的人来做,作为一名推荐算法工程师来讲也许并不需要考虑。
总的而言,我们可以将推荐系统这一系列的知识点划分成3个层面,即算法和模型层面、数据层面和接口层面。
算法和模型层面
算法和模型层面是推荐系统的核心,也是评价推荐系统好坏的最关键的点。下图是我总结的在推荐系统中常用的算法和模型。
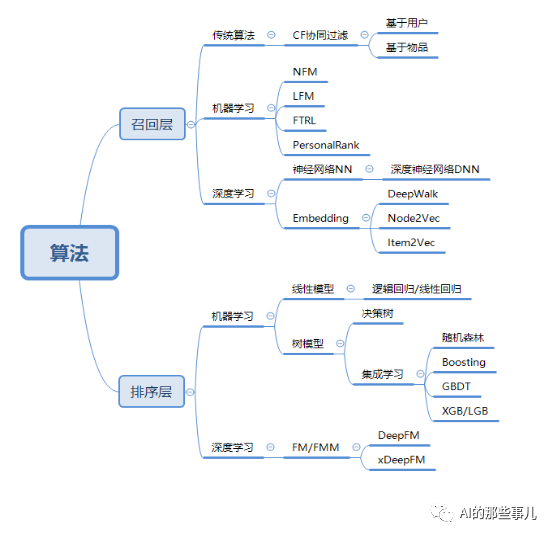
所以,对于推荐系统的工程化来讲,并不在于你用的模型有多么高大上,而最重要的是学会因地制宜,知道什么样的算法适用于什么场景。举例来说,目前我们要做一个新闻推荐,有1000个候选新闻集合,有1万个用户,并且我们只有点赞、阅读等简单的特征,且没有太多的用户基本信息。那么这个时候,显然不能用太复杂的模型,因为很多复杂一点的模型需要用到用户的画像和内容画像,而目前的情况下是做不到的,这个时候我们就可以考虑用协同过滤来做,但是协同过滤我们知道,既包含了基于user的协同过滤,又包含了基于item的协同过滤,该如何选,这就是我们在实际工程化时需要考虑的问题。
那么除了召回之外,排序层其实也是这个道理,从最简单的逻辑回归,到GBDT+LR,再到深度学习的排序模型,实际上每种模型的存在都有其存在的道理。例如我们用LR模型,一般是因为它相对比较简单,不需要太多特征,其本质是做一个点击率的预估。当我们有了更多特征的时候,我们就要考虑到特征如何筛选,如何进行特征的组合,那么这个时候,我们可以使用GBDT+LR来做这个排序,当然,如果用户量和内容量特别大的情况下,我们还可以考虑使用深度学习模型来做排序。
所以说,在推荐系统领域中模型和算法有很多,但是用哪个,如何用才是最关键的问题。
数据层面
除了上面的模型和算法层面之外,数据层面也是在推荐系统工程化中需要特别注意的地方。任何模型的输入都离不开数据的处理,输入数据决定了模型所达到的上限,下图是我总结的推荐系统数据层面常用的几个点。
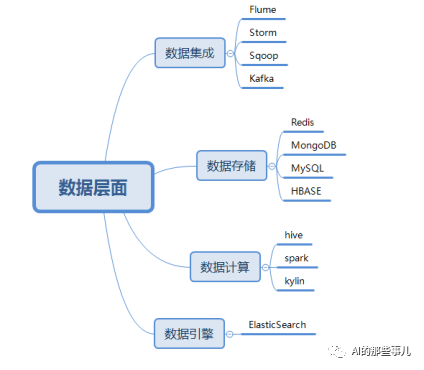
数据集成即通过各种各样的工具将数据收集过来,以便对数据进行分析和处理。在数据集成这个层面中,Flume、Storm、Sqoop和Kafka是四个常用的工具。一般情况下,我们用Flume来做日志数据的参加、聚合和传输系统,然后配合Kafka做分布式的消息队列,从而进行数据的实时传输。
而数据存储中的数据指用户和平台所产生的数据。用户所产生的数据一般包括两类:用户的浏览日志数据和用户的行为数据,平台所产生的数据包括用户的基本信息、待推荐列表等。这些数据都需要用数据库来存储,在存储的过程中,会根据用途不同而采用不同的数据库进行存储。
例如,我们对于用户的行为数据,可以使用MongoDB或者HBase这类的数据库进行数据存储;用户信息相关的内容,由于其结构化比较严重,所以一般可以使用MySQL这种结构化数据库进行存储;而我们要向外推送的推荐列表,由于要保持其推荐的速度和实时性,这个时候我们需要用一些基于内存的数据库进行存储,这个时候Redis就是我们的首选。但是从另外一方面来讲,Redis实际上问题在于,一旦断电其内容就会丢失,那么这个时候我们就需要想办法将redis中的数据进行落地,在这里,比较常见的方式就是使用Pika来做数据的持久化。
除了上面的集成和存储之外,在推荐系统的工程化中,对于数据的计算,数据引擎的处理都有比较常见的工程化体系,这些都是一个推荐系统工程师需要掌握的内容。
接口层面
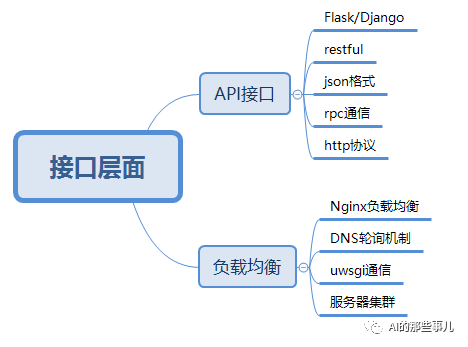
最后,我们再来说说接口层面。实际上,接口层面在很多公司也是推荐系统工程师需要掌握的内容。在这里主要需要掌握的点是API接口和负载均衡。
API接口
对于API接口,重点掌握API接口的开发和发布。
开发:用代码将内容进行封装,再形成一个个可以对外调用的方法或函数。
发布:指将我们所封装好的方法或函数通过API接口的方式发布出去,使得其他开发人员可以利用API接口来获得数据,在推荐系统中的数据一般指给用户的推荐列表。
因为我们开发一般都是基于Python语言,所以在这里我们只列举了Python中常用的两个框架,即Flask框架和Django框架;而RESTful是网络应用程序的设计风格和开发方式,基于HTTP协议,可以使用XML格式或JSON格式定义,目前大多数厂商都使用RESTful配合JSON格式的数据进行接口开放,而JSON(JavaScript Object Notation)是一种轻量级的数据交换格式。简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言,易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。
而上述所有的通信,都是基于HTTP协议进行通信的。RPC通信技术实际上是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。这种协议在人工智能框架中比较常见,其中最常见的有Google所开源的TensorFlow框架中基于RPC所衍生出来的gRPC协议。
负载均衡
负载均衡(Load Balance)指将负载(工作任务)平衡、分摊到多个操作单元上进行运行。一个大型的商业推荐系统的稳定运行离不开负载均衡,负载均衡不仅能够保证接口的稳定性,还能够提高接口的吞吐量,从而直接提高接口的并发承载能力。因此,负载均衡也是在推荐系统工程化中必须掌握的一类技术。
首先要了解负载均衡的各种机制,其中最常用的就是DNS轮询机制,因此,掌握DNS轮询机制是掌握负载均衡的关键。另外,在Web服务器端,负载均衡一般是使用Nginx来实现的,Nginx作为负载均衡服务,可以支持作为 HTTP代理服务对外进行服务。Nginx采用C语言进行编写,不论是系统资源开销还是CPU使用效率都比 Perlbal 要好很多。另外,Nginx可以和几乎所有的Web API进行兼容,其特点是占有内存少、并发能力强,事实上Nginx的并发能力在同类型的网页服务器中表现较好,中国大陆使用Nginx网站用户有:百度、京东、新浪、网易、腾讯、淘宝等。
uWSGI是一个Web服务器,它实现了WSGI协议、uwsgi、HTTP等协议,并且可以与Nignx进行无缝衔接。Nginx中HttpUwsgiModule的作用是与uWSGI服务器进行交换。而uwsgi也可以与Python的Flask等框架无缝衔接,因此,我们在进行负载均衡和接口发布时,常用的一个组合就是Fkask+uWSGI+Nginx。
在负载均衡阶段,除了上面的几种框架之外,我们还需要了解Linux的基本配置及服务器集群的基础搭建。一个优秀的推荐系统功能不可能是单机工作的,因此,这里需要大量的服务器进行相互配合和协同工作,我们把这些服务器的集合一般称之为服务器集群,而目前服务器集群大多是以Linux系统作为其主要的操作系统,因此,对于Linux服务器的基本配置和操作一定要熟练,只有这样,我们才能搭建出一套优雅的工程化推荐系统。
帮忙推广
最近黄鸿波大佬组织了一次面向企业工程化落地的推荐系统培训,在此友情宣传一波,有需要的同学可以接着往下阅读。下图是做的培训大纲:
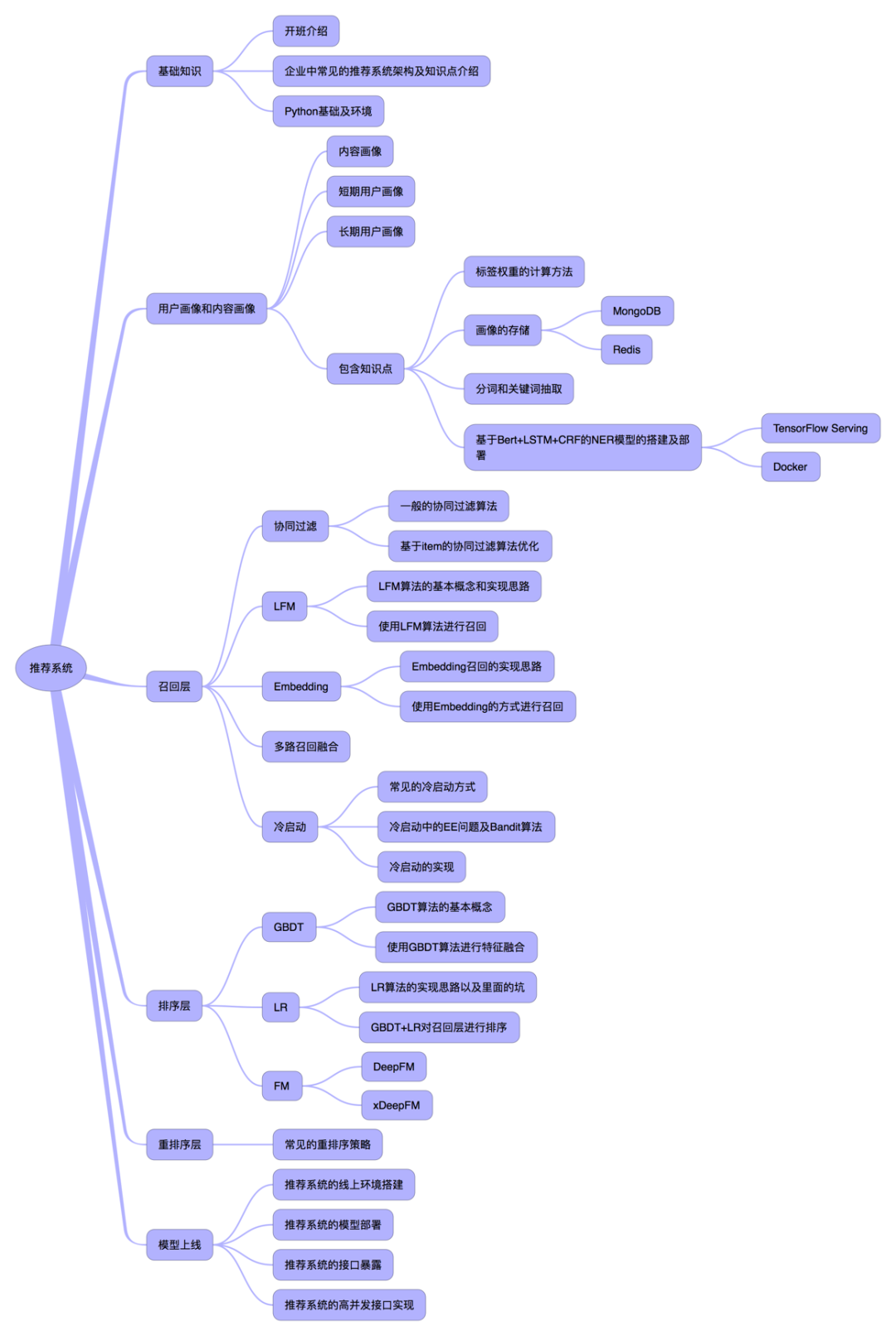
而在费用方面,由于是自己来做,大部分的同学都是学生,所以价格也计划做的很低。具体如下:
1、原始价格为2499元。2人组队报名,可以享受特惠价1999元;
2、所有报名成功的人,均可获得一本他写的推荐系统技术实战书籍一本(如果顺利,预计2021年出版)
感兴趣的同学可以扫描下方的二维码,加群向大佬咨询。





