干货分享 | 自然语言处理及词向量模型介绍(附PPT)
云脑科技机器学习训练营第二期,对自然语言处理及词向量模型进行了详细介绍,量子位作为合作媒体为大家带来本期干货分享~
本期讲师简介

樊向军
云脑科技核心算法工程师,清华大学学士,日本东京大学与美国华盛顿州立大学双硕士
第33届亚洲、国际物理奥赛双料金牌得主,在美国硅谷高通等公司有着多年超高性能计算仿真软件设计开发经验,获得高通Qualstar Diamond杰出贡献奖,目前作为云脑科技算法团队的主要成员进行金融、通信、能源大数据领域的核心人工智能算法研发与系统设计工作。
分享内容实录
自然语言处理Natural Language Processing是一个非常大的topic,在本节课程中,我们仅做非常概要性的介绍。下面这张图可以给你一个感觉,NLP技术能够做些什么。

NLP应用在自然语言处理中主要分为以下几类:第一是Classifying Words ,即需要去研究一下词是什么意思。第二是Classifying Documents,即整个文章有一些什么操作,怎么去分类。第三个比较难也比较热门的是Understand Documents,即理解文章是在讲什么。这些是NLP比较热门的几个方面。前半段我们讲介绍比较传统的NLP方法,后面会讲NLP和Deep Learning 的结合。
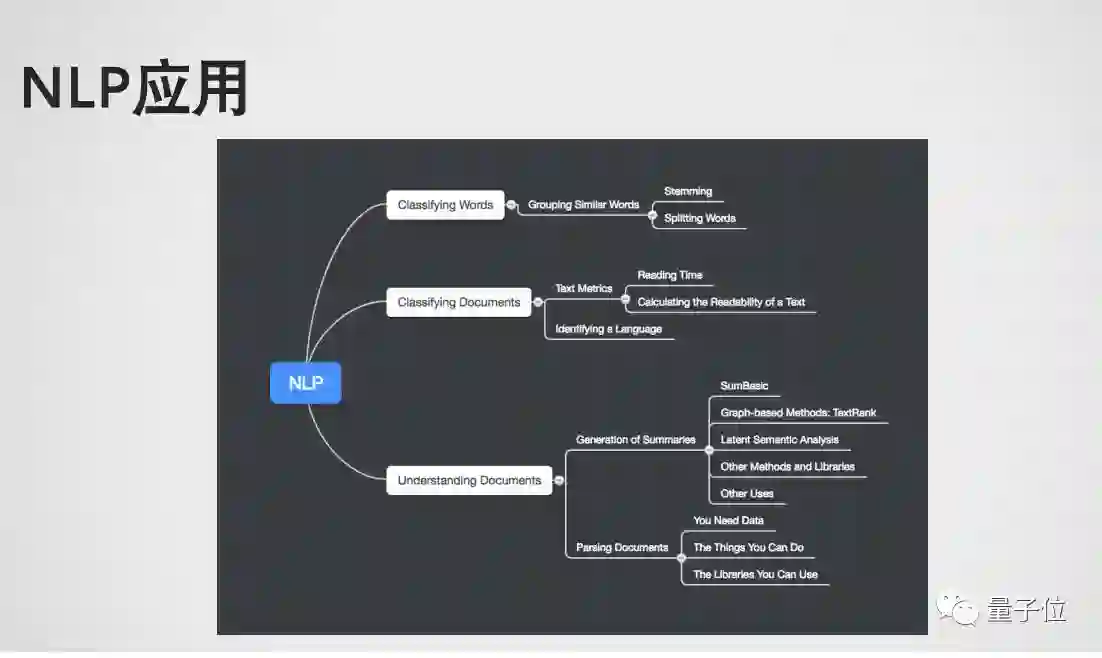
Classifying Words
也就是把每个词分类,词分为哪几类或者是能不能把它group起来?比如说维基百科上很多信息放在一起,或者你拿到一本字典、百科全书,再或者许多文章放在一起,怎么去分类这些字?NLP产生了许多分支去研究各种各样的里面的问题,比如: Stemming,找到一个词的词根,根据词根把相同的词尽量的放在一起。
另外一个是Splitting Words分词,根据里面的字母把词分成许多块,做字母级别的k-grams或者n-grams,再做分类。这两种方法比较偏重拉丁文、英文语系的文章,对词根或者字母进行分解,但是对中文不是很合适。

Classifying Documents
分类文本本身,词我们可以找词根或者分词,文本分类又提高了一个难度。它有一些应用,比如说我们想知道读一篇文章需要多久,最简单的办法是规定某一个人每分钟读多少词,统计一下这篇文章有多少词,做一下除法,就得到了时间。
这可能是最直截了当的方法,但是精度可能很差,因为每个人读的速度不一样,文章本身的难度也不一样等各种各样的原因。如果应用没有特别的要求,就可以这样简单的用一下,但如果某些应用或研究中希望得到一个高的精度,比如你的研究是有阅读障碍的人遇到各种各样的文本会怎么样,则希望会得到一个精度比较高的阅读时间的估计结果。NLP本身有许多研究,也产生了许多好的方法,在这里就不细讲了,有兴趣可以关注一下相关研究文献。
Identifying a Language
这也是比较有趣的应用,你输入给计算机一段语言,绝大部分要做翻译,比如说把日语翻译成中文,或者把中文翻译成日语,你需要选一下对应语言的选项才可以,那现在怎么让计算机自己去发现你的输入属于哪一种语言?这也是NLP的一个研究方向。
有一种方法是Words in a Vocabulary,先建一个词典,看你输入的属于哪一个词典里,当然这也是低效率,精度也不一定高的办法。还有一个方法是Frequencies of Groups of Letters,比如说中文,用中文的语言建立一个语言模型,然后再把新输入的东西带入你的模型作比较,得出是不是属于中文的结论。具体语言模型要怎么建立,后面会提到。

Understanding Documents
刚刚我们有了词、有了文本,它们都是做分类,但文本具体是在讲什么呢?这又是一个一直想要解决,但没有非常好的、完全被解决的方向,很多人在这个方向上做各种各样的研究。现在有一些比较好的、可以实际应用的,比如document summary,之前英国有个学生写了对news做summary的系统,后来被谷歌收去了。所以像这种应用很多互联网公司已经有了很好的处理能力了,但还是希望有更好的算法进来。
关于summary,TextRank比较有意思,大家都知道谷歌最早的算法叫 PageRank,根据两个document之间的connection去links、去排序它语义的重要性。TextRank比它更拓展一点,不是简单的有关系或者没有关系,如果两个文本间部分有关系怎么办?它把两个文本间部分有关系部分copy进来,做一个语言模型。
第二个是Sentiment analysis 语义分析,简单的看一下这个文本是positive 还是 negative? 现在也很常用,比如说对亚马逊或者京东商品review,分析一下是好的还是坏的,好在哪里坏在哪里?或者是苹果app、安卓app或者是谷歌的app的评论,有多好多坏?好在哪里,差在哪里?这些都可以通过语义分析出来,帮助客户做更好的选择。
接下来是Parsing,也是很常用的,一个文本是有结构的,有章节,句子有主谓宾,有的段落的首句或者尾句是总结,那这种结构怎么去认识它。比如说股票公司的报告,上市公司的年报、财报,法律文件,合同等,这些报告你怎么去理解它?这些文本都比较结构化了,从人的角度都很好了解到,如第一章讲的是什么?合同的甲方乙方是谁?合同的成交价格是多少?这些人都可以快速的找到它,但对机器来说是不是有个比较好的办法去识别呢?而不是规定具体的哪一章节要讲什么。
有些公司试图把规范化化报告的描述,其实这些是很难完全做到的,其实有更好的办法:用NLP的方法找到关键点。
比如大家写code都需要有具体的格式,比如说缩进、每一行后面加分号等,这些都是规定好的,所以计算机很容易compare你的language把它变成机器语言,但真正的自然语言没有严格的语法,那怎么做Parsing也是需要做但也比较难的问题。
最后是Translate语言翻译,显而易见大家都看到了最近几年有很大的进步,应用也是越来越广。
NLP应用十分的广,这里主要是讲一下大概,如果大家对某个方向或应用感兴趣可以关注、阅读一些相关应用的研究结果。
比较常用的NLP Libraries: Apache OpenNLP,The Classical Language Toolkit (CLTK) ,FreeLing,Moses,NLTK,Pattern,Polyglot,Sentiment,SpaCy,CoreNLP,Parser
NLP与Deep Learning
之前讲的这些NLP都是和语言处理相关的。举几个例子,看看如何将NLP和Deep Learning 相结合?如何通过引入deep learning 把NLP做到更好的效果。
词分类
根据相似性词分类。这里例子是摘自斯坦福的讲义,如果大家对NLP感兴趣,建议看一下斯坦福的课程,里面讲了大量应用Deep Learning的例子,且都是更新比较快的。如果输入是一个青蛙,会输出一些和青蛙有关的词,比如toad等。如果你给他一个文本,它自己能够把它学出来。
语法的分析
词本身是有词性或是语法的,比如拉丁文、英文前缀后缀,如加un变反义,这都是根据词根来定。Deep learning的思路是:把每个词义变成一个vector,然后分成两个或多个vector,把它们combine起来,然后去学它的vector就可以了。对于句子做一些句法的分析,句子中有一些词,有主谓宾这种词要怎么认出来,这是做语义理解的一个基础,那怎么用Deep Learning 来做句法的分析?
语义的分析
传统的做法需要对语言本身做许多工程,需要做一些知识的积累,然后root放进来,然后用tree记录下来,最后来分析新进来的文本。Deep Learning的做法是把字和词变成一个向量,然后用neural network去学这个vector。
Question Answering也是有传统的做法,首先要做许多的feature engineering 把knowledge 先build起来,通过build起来的knowledge 再做一个分解。从deep learning角度来看,你Question Answering 需要的一些facts,需要的一些结果,需要的一些answer都会存在vector 里面,然后再通过vector再做问答的matching.
Translation谷歌、Facebook把之前传统的Translation方法都推翻了,使用Machine Learning 提高的很多的精度。这里有一个Neural Machine Translation的示意图,ML的做法都是把它变成了一个vector。

Vector
我们前面提到的应用都用vector 来做,下面我们主要讲vector是什么?怎么去用vector?怎么得到vector?
Word Embedding
简单的讲vector就是一个一维的数组,每一个词都变成一个vector。比如说先把一个词变到一个多维空间中,然后把所有的词都放在这个多维空间中。最大的好处是,这些词对计算机来说是categorical feature,像one-hot一样,两个词放在不同位置完全没有关系。如果用vector来表示,词与词之间的关系就可以用距离来表现。也就是说这些词对计算机来说本来是没有关系的,但通过vector转换之后,它们的距离代表了它们的关系,这也是比较好的帮助计算机去理解词之间关系的方法。
Word Embedding 实际上就是把词从词本身或从one-hot本身变成一个vector 的过程,Embedding就是你怎么去变换这个向量。
How Do We Represent the Meaning of a Word?
Meaning本身在字典的定义是:词背后的想法,或是某个人、文章、艺术品想要表达的想法。Meaning本身是个idea,它在大脑里面怎么存储的我们不知道,这个idea怎么让计算机系统去理解它,比较好的办法是把它变成一个vector。
词本身如果不做向量的变化,那计算机看起来是什么?如果两个词不一样,那就是一个分类的feature, 那我们就直接做one-hot,就是在出现的位置记为1,其他位置记为0,这样做显然是可以的,但是维度是十分大的,尤其是英文。比如说,你搜索电视大小其实和电视容量是一个意思,那计算机怎么知道电视大小和电视容量是同一个意思?包括你要查hotel和motel,其实是一个意思,如果用one-hot它们将在两个维度上,完全没有关系。如果把它变到一个比one-hot低维的,但每个位置上都是有浮点数的vector,而且这些浮点数的数值是有意义的,比如说两个词的浮点数值大小非常靠近,那这两个词就比较靠近,那这样学出来的vector 也是非常有意义的。

How to Represent Word as Vector?
怎么去学vector?每一个词都做一个one-hot encoding,变成一个很长的vector。通过Neural network,首先input vector然后通过 Hidden Layer加工,再marking到另一个词上面,再进行训练。如果这两个词是相近的就是1,如果不相近就是0。如果能准备到这样的数据,让神经网络去学,所有的词都表征为向量之后,那这两个向量距离之间就比较接近,因为和train数据是有关系的。如果进去是一个词,让它比较和另一个词的距离,这时需要有一个label才可以去train,那怎么样得到这个label呢?
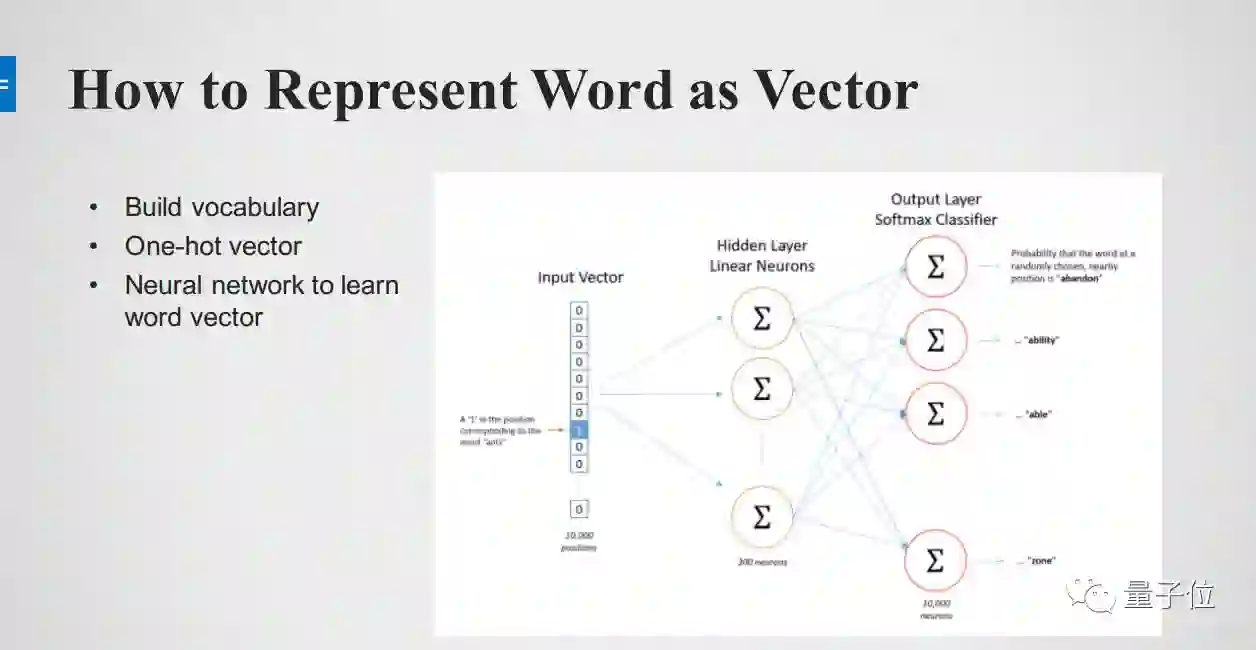
Skip-Gram Model
下面举一个Skip-Gram Model的例子,它的主要思想是:如果你能够拿到一些文本,可能是维基百科、百度百科的文章,很自然的有一些词就会出现在另一些词的附近,那我们在做Skip-Gram的过程实际就是在create 一个train data的过程,我们把文本拿来,把中间词作为x,两边的词作为label或是topic words,这两个词如果同时出现在附近,可以记为1,如果没有记为0。
这样的就可以得到一个train sample,这样的train sample都是一个pairs,这样就可以把文本变成很多个train sample,再返回刚才的模型,能很好的把Hidden Layer学出来。学到Hidden Layer之后这就一个embedding了,通过word Paris建立语言模型,然后每一个词再回来,本身还是一个one-hot encoding,再经过Hidden Layer weight matrix,会变成一些的word vector。
回溯总结一下,vector就是把词本身变成一个向量,怎么得到这个向量?刚才举到了用神经网络,Skip-Gram 建立train 数据,然后学到这个数据,然后Embedding实际上就是Hidden Layer weight matrix,通过Embedding就得到了向量。这是一个比较直接的,事实证明也是一个比较有效的办法。

Negative Sampling
刚刚有讲到每个词用one-hot encoding,然后用weight matrix与它相乘,假设我们想要得到的vector的size是300,输入字典的维度是10000,可以看到weight matrix 有300*10000个parameter,只有一个FC Layer就非常大了,所以不仅是weight matrix 这么大,每一次迭代都要把matrix更新一遍,这样整个学习过程的效率是十分低的。
比如说在10000个词中有很多和它是词义相近的,但绝大部分和它是没有关系的,数学的角度是正交的,所以它不需要每次都进行更新。所以Negative Sampling的核心:大量减少更新的内容,而且可以大量的减少训练损失,实际测量下来的结果也是非常好的。当然还要做一个词频,高频的词需要放到训练的过程当中去,低频的就不需要做了。
总结一下Word2Vec 是怎样一个流程:
Collect text data
Process text
Skip-Gram to generate word pair
Training embedding
Word2Vec
Vector Space Visualization
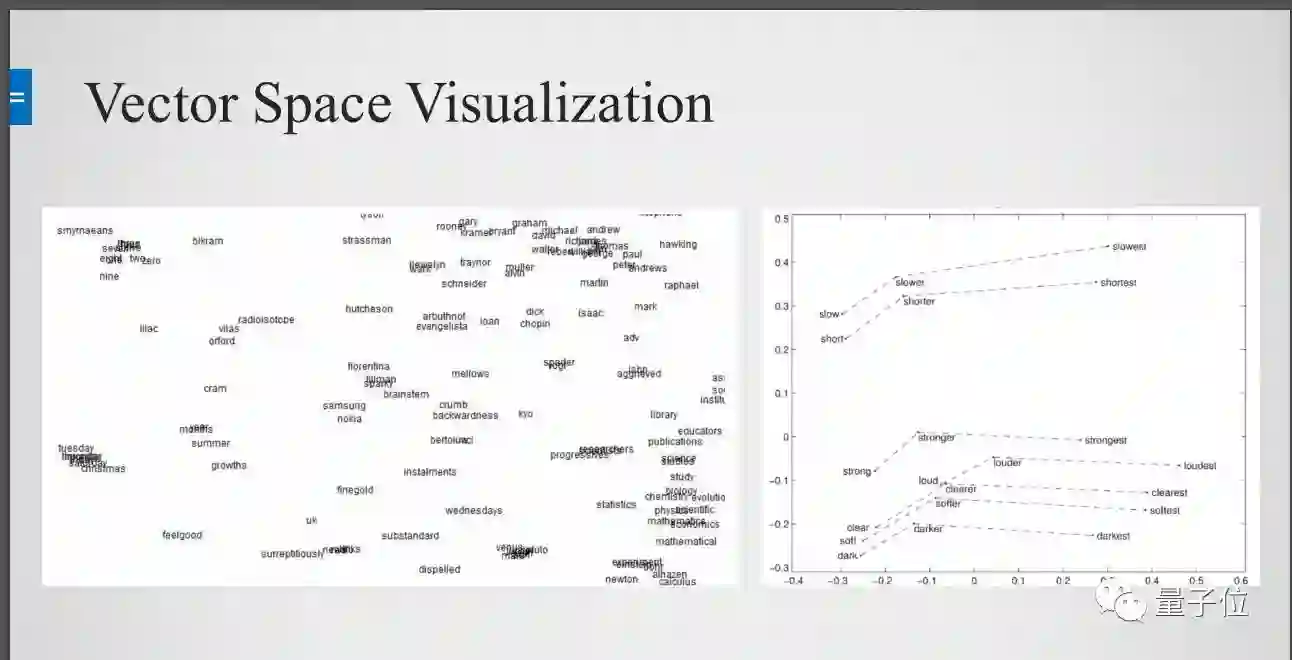
把它们全都变成vector之后下一步需要做什么?下一步最简单的做法就是把它们画出来。
当然之前例子中说到把每一个词变到300维,300维是人的肉眼是看不出来的,大家的物理世界只有3维,需要一些降维的方法,降维之后可以看到本来一些词是没有关系的,最后自动的group到一起。
比如说左上角12345678910的英语都到一起了,左下角和时间相关的都在一起了,右下角语文数学化学高考科目都到一起了,这是个比较有意思的事情,明显的看到这个学习的过程是比较有意义的,意思相近的词都在一起了。
还有一个点,word vector不仅仅是把词进行分类,而且词和词之间的距离也是有很强的关系。
比如说英语里面有基本级、比较级、最高级,如果看成一个向量,一个的比较级减去最高级和另外一个比较级减去另外一个最高级,下面的向量还是一样的。它不仅把词之间的分类学会了,词之间的关系也学会了。还有就是男人对应国王,女人对应什么?是皇后。这个也能学出来。所以Word2Vec的fundamental idea不是很难,但效果也是非常好的。
相关学习资源
以上就是此次课程的相关内容,在量子位微信公众号(QbitAI)对话界面回复“171202”,可获得完整版PPT。
上期课程回顾:干货分享 | 详解特征工程与推荐系统及其实践
P.S.云脑科技对人才如饥似渴,如有兴趣请移步http://cloudbrain.ltd/join.html ,简历发送至 job@cloudbrain.ai ,据说邮件主题添加注明“来源量子位”,通过率会更高噢~
— 完 —
活动报名

加入社群
量子位AI社群11群开始招募啦,欢迎对AI感兴趣的同学,加小助手微信qbitbot4入群;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进群请加小助手微信号qbitbot4,并务必备注相应群的关键词~通过审核后我们将邀请进群。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态


