田奇:华为计算机视觉研究计划与进展
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

本文转载自:AI掘金志

2020 年 8 月 7 日,第五届全球人工智能与机器人峰会(CCF-GAIR 2020)在深圳正式开幕。
CCF-GAIR 2020 峰会由中国计算机学会(CCF)主办,雷锋网、香港中文大学(深圳)联合承办,鹏城实验室、深圳市人工智能与机器人研究院协办。
作为中国最具影响力和前瞻性的前沿科技活动之一,CCF-GAIR 大会已经度过了四次精彩而又辉煌的历程。在大会第二天的「视觉智能•城市物联」专场上,华为云人工智能领域首席科学家、IEEE Fellow田奇教授登台发表精彩演讲,分享了华为在人工智能领域的理解与实践。
田奇介绍了华为在人工智能领域的十大愿景,华为为了实现这个战略目标,从中梳理出深耕基础研究、打造全栈方案、投资开放生态和人才培养、解决方案增强、内部效率提升五大方向,以此打造无所不及的AI,构建万物互联的智能世界。
华为计算机视觉基础研究以数据高效和能耗高效为核心,覆盖从2D视觉到3D视觉的技术和应用,主要包含底层视觉、语义理解、三维视觉、数据生成、视觉计算、视觉多模态等方面。在此方向上,华为将基础研究进一步聚焦到数据、模型和知识三大挑战:
1、数据上,如何从海量的数据中挖掘有用的信息。田奇以生成数据训练和不同模态数据对齐这两个应用场景为例,介绍了华为如何使用知识蒸馏与自动数据扩增结合的方法让AI模型高效地挖掘数据中的有用信息。
2、模型上,怎样设计高效的视觉模型。田奇认为在深度学习年代,视觉模型主要包含神经网络模型设计和神经网络模型加速两个场景。具体地,田奇介绍了华为如何通过局部连接思路解决网络冗余问题、如何加入边正则化思想来解决局部连接带来的不稳定性等等。
3、知识上,如何定义视觉预训练模型、如何通过虚拟环境学习知识、如何表达并存储知识。为了实现华为打造通用视觉模型的目标,田奇认为推理预测是从视觉感知到认知的关键步骤。虽然预训练方法目前在视觉领域的应用还不成熟,但是近期自监督学习的成果为视觉通用模型的发展注入了新活力,这也将成为常识学习的必经之路。
基于三大挑战,田奇提出华为视觉六大研究计划:数据冰山计划、数据魔方计划、模型摸高计划、模型瘦身计划、万物预视计划、虚实合一计划,来帮助每一位AI开发者。
以下是田奇博士的大会演讲全文,雷锋网AI掘金志作了不改变原意的整理与编辑:
注: 关注公众号「AI掘金志」,对话框回复“视觉智能”,获取CCF-GAIR大会视觉专场部分嘉宾演讲PPT。
田奇:尊敬的各位嘉宾、各位老师、各位朋友,大家下午好!我是田奇,现任华为云人工智能领域首席科学家。非常感谢大会的邀请,很荣幸能在这里为大家介绍华为计算机视觉计划。
首先,我会简单介绍一下华为人工智能的研究背景和在计算机视觉领域的基础研究。然后,我会从模型、数据和知识三个核心点出发,来重点介绍华为视觉六大研究计划。最后,我会介绍一下华为云人工智能在人才培养方面的理念。
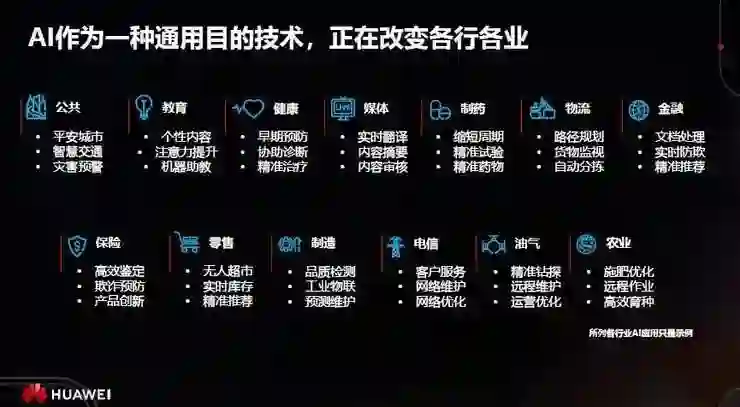
近年来,AI的发展如火如荼,正在改变各行各业。华为预计:到2025年左右,97%的大企业都会上云,其中77%的企业云服务都会涉及到AI。
因此,在云上,AI是一个关键的竞争点。如果把大企业的智能化升级比作一个赛道,那么AI、IoT、5G就是提高发展速度和商业高度的重要引擎。

以前我们的董事长徐直军阐述过华为在人工智能领域的十大愿景,这里我简单介绍几点。
过去,长达数年的分析时间,未来会是分钟级的训练耗时;
过去,需要天量的资源消耗,未来将是高性能的计算;
过去,计算主要集中在云端,未来主要是云端+终端;
过去,是大量的人工标注,未来将是自动标注、半自动标注的舞台;
过去,专业人员才能用AI,未来是面向普通人的一站式开发平台。
基于这样的愿景,华为的AI发展战略就是打造无所不及的AI,构建万物互联的智能世界。

华为将从以下五个方向进行研究或者投资。
第一:深耕基础研究,在计算机视觉、自然语言处理、决策推理等领域,构筑数据高效、能耗高效、安全可信、自动自治的机器学习的基础能力。
第二:打造全栈方案,面向云、边、端等全场景,全栈的解决方案,提供充裕的、经济的算力资源。
第三:投资开放生态和人才培养,将面向全球,持续与学术界、产业界和行业伙伴进行广泛的合作。
第四:把AI的思维和技术引入现有的产品和服务,实现更大的价值、更强的竞争力。
第五:提升内部的运营效率。

华为云Cloud&AI的定位就是围绕鲲鹏、昇腾和华为云构建生态,打造黑土地,成为数字世界的底座。为了实现这个目标,华为云提出了一云两翼双引擎+开放的生态目标。

就像这架飞机一样,双引擎是基于鲲鹏和昇腾构建的基础芯片架构;两翼是计算以及数据存储和机器视觉;一云是华为云,提供安全可靠的混合云,成为生态伙伴的黑土地,为世界提供普惠的算力。开放的生态是指硬件开放、软件开源,使能我们的合作伙伴。
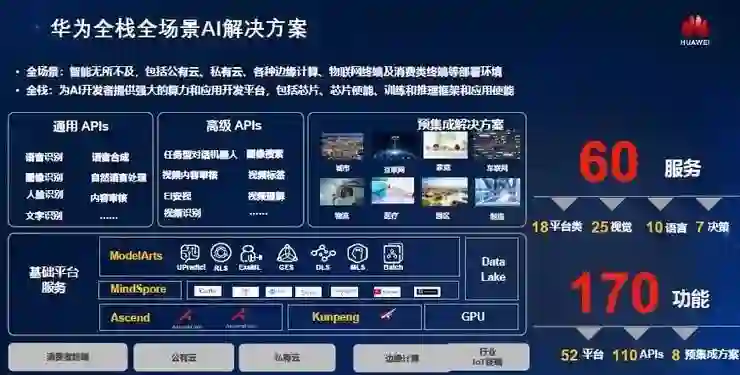
华为云主要面向八大行业使能AI技术。到2019年底,我们已经提供了60种服务、170多种功能,所涉及的行业包括:城市、互联网、家庭、车联网、物流、金融、园区、制造等等。
以上是对华为AI的简单介绍,下面将介绍我们在计算机视觉领域的一些基础研究。
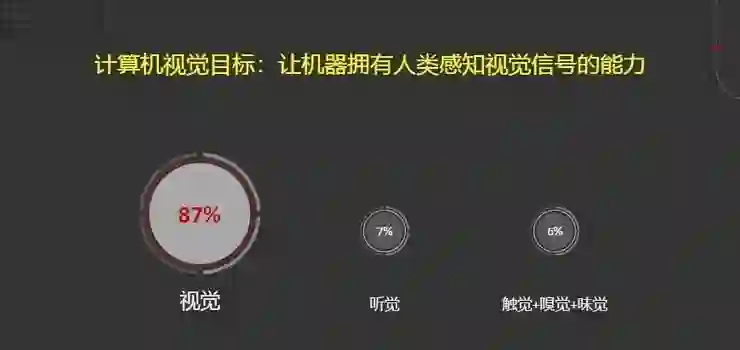
众所周知,人类对外部世界的感知80%以上来自于视觉信号。近年来,随着视觉终端设备的不断普及,如何让机器像人类一样拥有感知视觉信号的能力是计算机视觉的终极目标。

计算机视觉已在智能汽车、智能手机、无人机、智能眼镜等诸多行业得到了广泛应用。
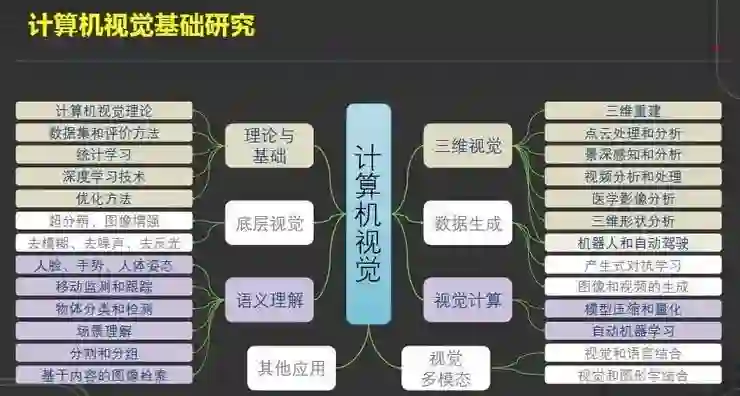
总的来说,视觉研究可以分以下几个部分:
首先是基础理论,例如统计学习、优化方法、深度学习技术等;
接下来考虑底层视觉,如超分辨、图象增强、去模糊、去噪声、去反光等等;
再到中高层的语义理解,包括场景理解、物体分类与检测、人脸、手势、人体姿态的识别、分割和分组等等。
除了二维视觉以外,三维视觉的研究也有着极其重要的地位,包括三维重建、点云处理和分析、景深感知分析等等。
同时,在人工智能时代,数据生成的方法研究也是一项有价值的任务。在一些工业场景中,视觉计算借助海量算力来做一些神经网络架构搜索的研究,以及模型压缩与量化。
最后是视觉与其他模态的结合,比如视觉与语言的结合,视觉与图形学结合,这都是计算机视觉领域的一些基础性的研究课题。
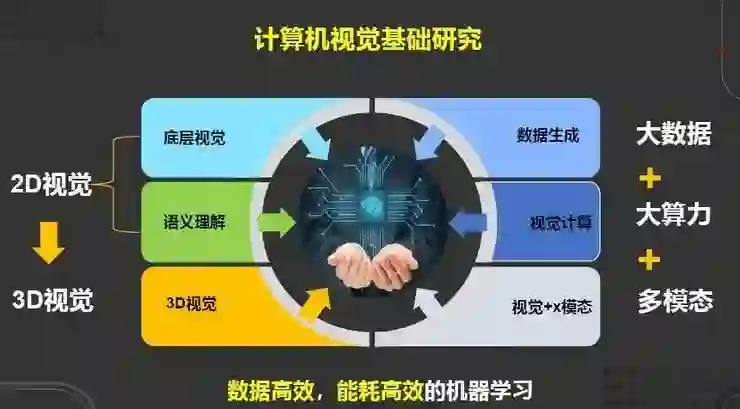
华为的基础研究就是围绕底层视觉、语义理解、三维视觉、数据生成、视觉计算、视觉+多模态等方面,构建数据高效、能耗高效的机器学习能力。

华为对底层视觉的研究涉及诸多方面,这些技术有着广泛应用场景,比如,为了提升手机端的图片质量,我们对照片进行超分辨和去噪处理,并提出了一系列有针对性的算法以面对从Raw域到sRGB域去噪,来提高照片的清晰度。
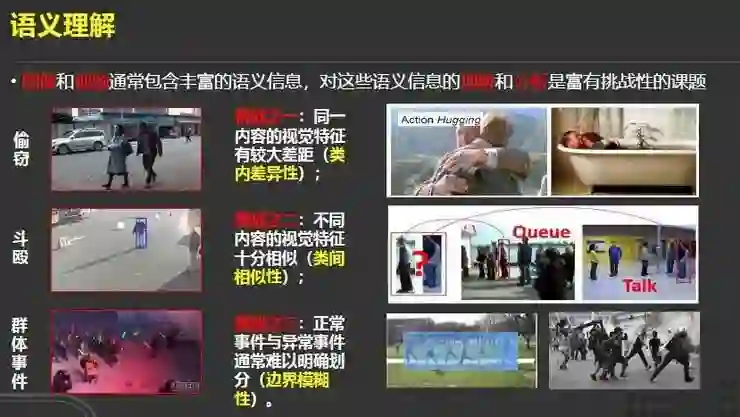
在语义理解方面,由于图像视频包括丰富的语义信息,如何有效理解并分析它们是一项富有挑战性的课题。以下举几个例子来说明:
挑战之一:同一内容的视觉特征的差异性。比如说拥抱这个动作,虽然是内容相同,但视觉表征可能非常不同,我们称其为类内差异性。
挑战之二:不同内容的视觉特征十分相似,我们称其为类间相似性。比如上图的两个男子,从图像上看,他们的视觉特征非常相似。但是放到场景中,一个是在排队,一个是在对话,这直观地解释了不同类间具有很高的类间相似性。
挑战之三:如何区分正常事件与异常事件。比如一群人在晨跑和一群人在斗殴,这往往会造成边界模糊。
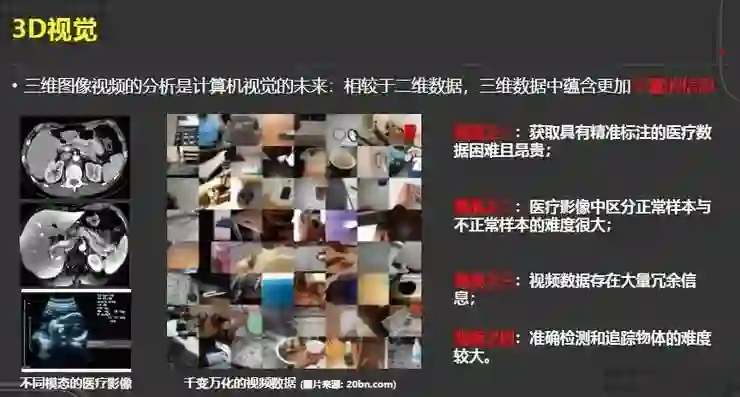
对于3D视觉而言,虽然三维数据比二维数据携带着更丰富的信息,但与之而来的是诸多挑战。
比如在医学领域,获取具有精准标注的医疗数据,往往需要专家的协助,这是困难并且昂贵的;同时,因为一些医疗影像通常是在一些很细微的地方有差异,所以区分正常样本和异常样本的难度非常大;此外,视频数据也存在大量的冗余,如何去除冗余并提取有效信息也很具挑战性。
最后,准确检测和追踪物体也极具挑战并值得进一步探索。
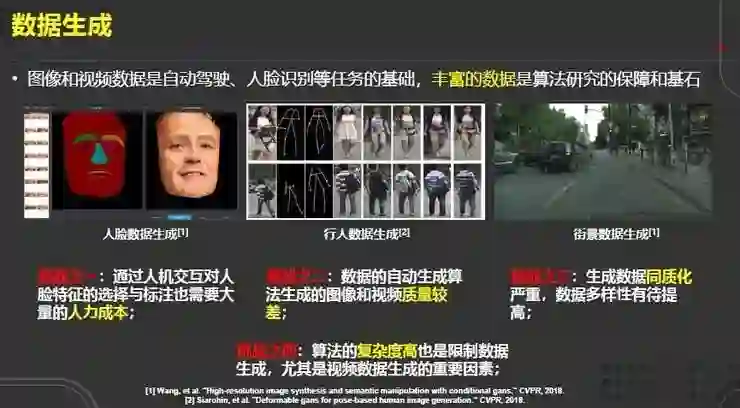
数据生成同样是一个热门研究方向。我们认为数据是视觉算法研究的保障和基石,在深度学习时代,大多数场景数据的收集越来越昂贵,所以数据生成具有直接的应用价值。
比如在安防企业中基于姿态的行人数据生成;在无人驾驶中街景数据的生成以及人脸数据的生成等。但目前该领域仍存在一些挑战:
挑战之一:通过人机交互对人脸特征的选择与标注需要大量的人力成本;
挑战之二:如何生成高质量的图像以及视频数据仍是巨大挑战;
挑战之三:生成数据同质化严重,数据多样性有待提高;
挑战之四:算法复杂度也制约着数据生成的性能,特别是视频数据生成这类对算力有着较高要求的任务。
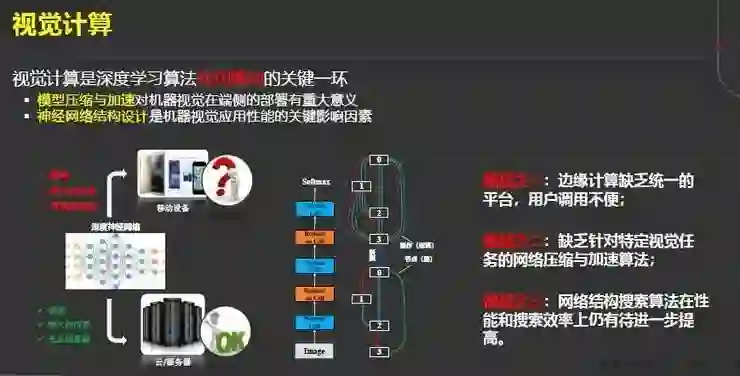
下一个基础研究是视觉计算,我们认为视觉计算是深度学习算法应用落地的关键一环。
它主要集中在两个方面:一个是模型的压缩与加速,这对机器视觉在端侧的部署具有重大的意义;另一个就是神经网络架构设计。
但是视觉计算目前仍然面临一些挑战。第一,边缘计算缺乏统一的平台,用户调用不便;第二,缺乏针对其它特定视觉任务的网络压缩与加速的算法;第三,网络结构搜索在性能和搜索的效率上都有待进一步提高。
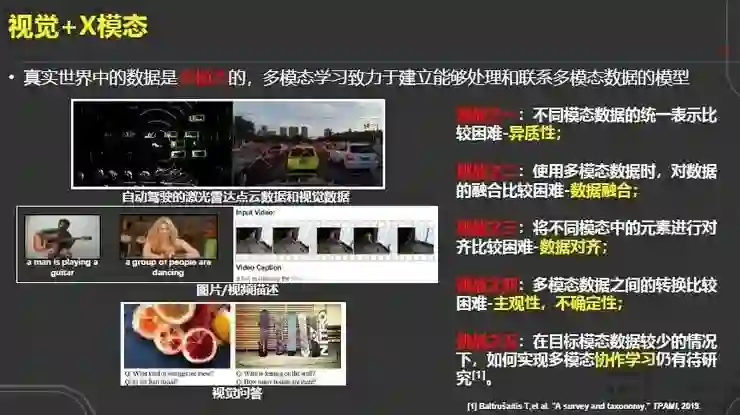
最后一个研究领域是视觉与多模态。真实世界的数据是多模态的,比如在自动驾驶中,除了摄像头的输入,还有激光雷达的点云数据;在图片、视频的描述中,从图片、视频到文字的映射等。
它们存在的挑战,包括数据融合的问题、数据对齐的问题、数据异质性的问题、主观性和不确定性的问题、还有协作方面的问题,都有待研究。
以上是华为计算机视觉基础研究的一些方向,下面介绍一下我们从这些基础研究中,进一步提出的华为视觉研究计划。

我们认为计算机视觉实际上面临三大挑战:从数据到模型、到知识。 从数据来讲,举个例子,每分钟上传到YouTube的视频数据已经超过500小时,如何从这些海量的数据中挖掘有用的信息,这是第一个挑战。
从模型来讲,人类能够识别的物体类别已经超过2万类,计算机如何借助于深度神经网络来构建识别高效的视觉识别模型,这是第二个挑战。
从知识来讲,在计算机视觉里面如何表达并存储知识,这是第三个挑战。
因此我们提出的第一个研究方向:如何从海量的数据中挖掘有效的信息?有两个主要应用场景,一是如何利用生成数据训练模型;第二是如何对齐不同模态的数据。

深度学习主要是监督学习的范式,需要大量人工标注的数据,而人工标注的成本越来越高,比如无人驾驶,数据标注成本可能成百上千万,因此华为也花了很大的人力物力来研究数据生成技术。
我们把数据生成技术主要分为三类:第一类是数据扩增;第二类是利用生成对抗网络GAN来合成更多的数据;第三种方法是利用计算机图形学技术来生成虚拟场景,从而生成我们所需要的虚拟数据。
在这三方面,华为在ICLR20、CVPR2018和CVPR2019都有一些相关论文发表,数据生成主要应用的领域在智慧城市、智能驾驶方面。

在这里,介绍一个我们最新的工作。我们提出知识蒸馏与自动数据扩增结合的方法,在不使用额外数据的情况下,可以达到业界领先精度:在ImageNet-1000 Top-1准确率为85.8%。之 前几年都是谷歌最强,它在ImageNet-1000上最高精度是85.5%。

数据的第二方面是多模态学习。例如无人驾驶有图像、GPS、激光雷达信息。相对于单模态,多模态具有天然的互补性,因此是场景理解的主要手段。
当然也面临很多挑战,比如多模态的信息表示、融合、对齐、协同学习等等。我们认为多模态学习是未来机器视觉的主流方式,在自动驾驶、智能多媒体方面有着广泛应用前景。
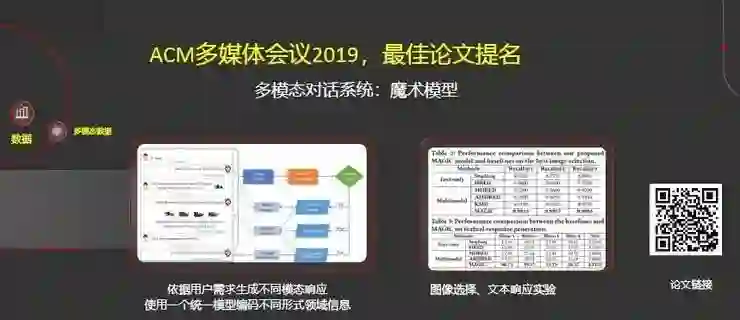
在多模态学习方面,介绍一个我们在2019年的ACM多媒体会议上获得最佳论文提名的工作,该工作主要是面对电商(服装)设计了一个人机对话系统。
具体而言,系统会依据用户需求生成不同的模态响应,使用一个统一模型以编码不同形式领域信息。最后在图像选择、文本响应都取得了很好的结果,右边的二维码是相关论文的链接。
第二个研究方向是:怎样设计高效的视觉识别模型?同样有两个应用场景,第一个是在深度学习时代,如何设计神经网络模型。第二是如何加速神经网络的计算。
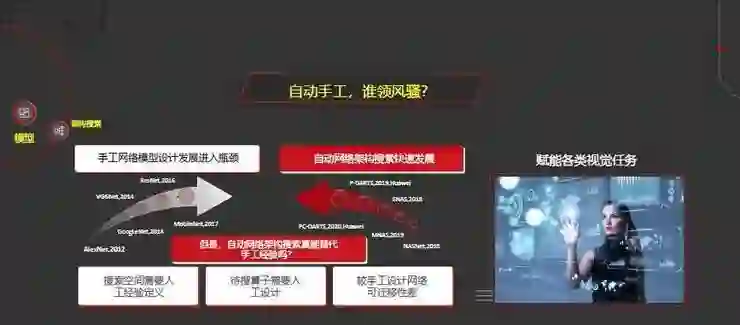
在神经网络设计方面有很多优秀的模型诞生,从2012年的AlexNet到VGGNet、GoogleNet、MobileNet,然而,手工网络模型设计进入瓶颈期。
2018年以来,自动网络架构搜索进入快速发展的阶段,包括今年华为的PC-DARTS在业界都取得了很好的效果。但是自动网络架构搜索真能替代手工经验吗?
主要面临以下几个挑战:第一是搜索空间需要人工经验定义;第二是待搜的算子也是人工设计的;第三是它相比手工设计的网络可迁移性比较差,抗攻击能力也比较差。

在这里介绍一下我们在ICLR2020提出的一个目前业界搜索速度最快的自动网络架构搜索技术PC-DARTS,它主要包含两个思想:一是采用局部连接的思想,随机地选择1/K的通道进行连接,可以解决冗余的问题;另一个是提出了边正则化的思想以保证网络稳定。
图片展示了这是Darts系列方法首次在ImageNet上完成的搜索,相较于之前的模型,搜索的效果更好,速度更快。右边二维码是相关论文链接。
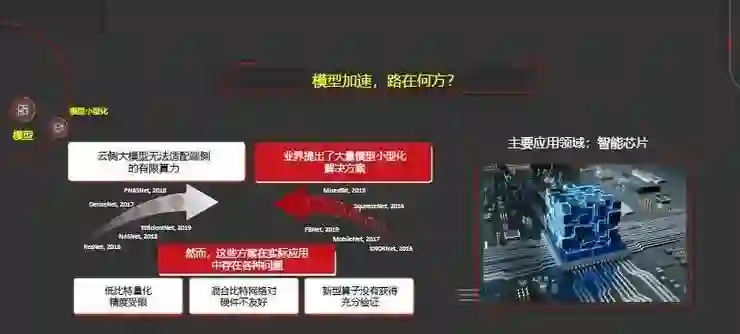
模型的另外一个研究方向是模型加速以及小型化。
对于早期的ResNet、DenseNet到最新的EfficientNet,由于云侧大模型无法适配端侧的有限算力,所以自2016年以来,业界提出了众多模型小型化的解决方案。
然而这些方法在实际应用中存在各种问题。比如,低比特量化精度受限;在实现的时候,如果用混合比特来表示响应和权重,这种混合比特的网络实现对硬件并不友好;此外,新型的算子也并没有得到一些充分的验证。

在CVPR2020,我们作了一个口头报告。该报告介绍了一个新型算子加速卷积网络,该算子的核心思想是在CNN中采用加法计算替代乘法运算。
从原理上讲,我们是用曼哈顿距离取代夹角距离。该方法用加法代替乘法运算,同时用8比特的整数计算,对硬件实现更加友好,功耗更低。
在ImageNet数据集上的结果表明,加法网络达到了基本媲美乘法网络的效果。虽然精度大概损失1%到2%,但其在功耗上具有显著优势。此外,二维码展示了开源代码以及论文链接。
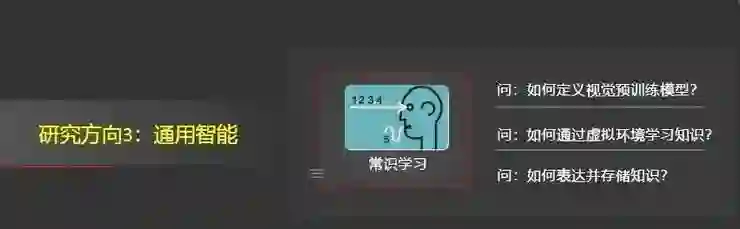
第三个研究方向是通用智能,我们称其为知识抽取。可简要概括为两个场景,第一个是如何定义通用的视觉模型,打造我们的视觉预训练模型;第二是如何通过虚拟环境来学习、表达和存储知识。

我们的目标是构建一个通用视觉模型,类似于自然语言处理领域存在的预训练模型BERT、GPT-3,可以为下游的任务提供高效的初始化,满足系统所需要的泛化性和鲁棒性。
就监督学习和强化学习而言,监督学习需要海量的样本,模型无法泛化到不同的任务;而强化学习需要海量的试错,同样缺少可重复性、可复用性以及系统需要的鲁棒性。
虽然强化学习在一些游戏中,例如围棋、星际争霸等取得很好的效果,但是在一些简单的任务比如搭积木,效果就比较差。所以我们认为要学会推理预测,才能实现从视觉感知到认知。
从当下研究主流来看,自监督学习是成为常识学习的必经之路,但是目前的自监督学习缺乏有效的预训练任务,其在视觉领域的应用还不成熟。

上图展示了我们在CVPR2019通过自监督学习来学习完成拼图游戏。具体而言,拼图游戏把一个图像分成3×3的9个小块,再把它的位置随机打乱,通过自监督学习来恢复图像原始的构成。
该任务能改进自监督学习性能,使网络能够处理任意拼图布局,从而更好地学习空间上下文提供的语义信息。我们把它在ImageNet上学习的结果迁移到别的地方,同样也取得了很好的结果。左下角二维码是我们的开源代码链接。
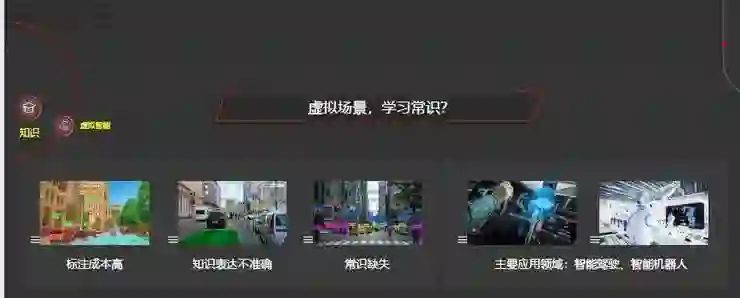
最后一个研究方向是构造虚拟场景来学习常识?因为深度学习需要大量的数据标注,这存在诸多问题:首先是标注成本特别高;其次是数据标注存在一个致命的问题,即知识表达不准确。
比如在无人驾驶场景中,我们有许多像素级分割的标注,但是并不知道这样的标注对无人驾驶的识别任务是最有效的,这一点难以证明。
第三是基于数据标注,必然导致常识的缺失,而人类对外部世界的认识很多依赖于常识。

我们在CVPR2019上提出用计算机图形学的技术生成虚拟场景,从虚拟场景中学习模型控制无感知的机械臂。
具体而言,我们只需要一个摄像头和一台计算机即可以控制没有装备其它感知设备的机械臂以完成复杂的搬运动作。因为这是从虚拟的环境中搜集的数据,因此标注的代价几乎为零。
此外,利用域迁移算法,所以几乎没有性能损失。如果融合强化学习,还能实现其它的多种任务,右边二维码是相关的代码和论文。

基于以上对数据、模型和知识方面的总结,我们提出了华为的视觉研究计划,希望能够助力每一位AI开发者。
我们的计划包括六个子计划,与数据相关的是数据冰山计划、数据魔方计划;与模型相关的是模型摸高计划、模型瘦身计划;与知识抽取相关的则是万物预视计划,也就是我们的通用预训练模型计划,此外还有虚实合一计划。
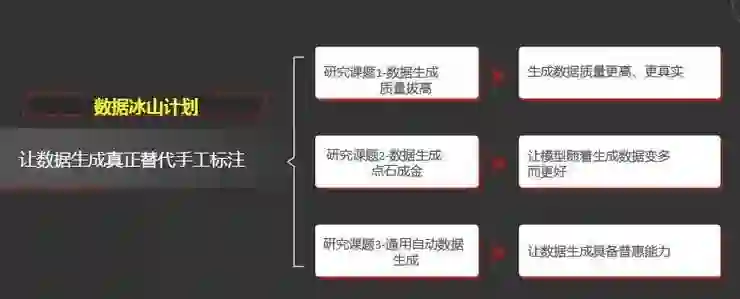
关于数据冰山计划,我们希望用数据生成方法真正代替手工标注。我们共有三个研究子课题,第一个子课题是希望数据的生成质量更高。
第二个研究课题是数据生成的点石成金计划,我们希望生成的数据能够自动挑选高质量的数据,让模型随着生成数据的变多而真正的变好。
第三个课题是通用自动数据生成,我们希望根据不同的任务自动生成它所需的数据,让数据生成具备普惠的能力。

第二个数据计划是魔方计划,关注多模态数据量化、对齐、融合策略的研究,构建下一代的智能视觉。
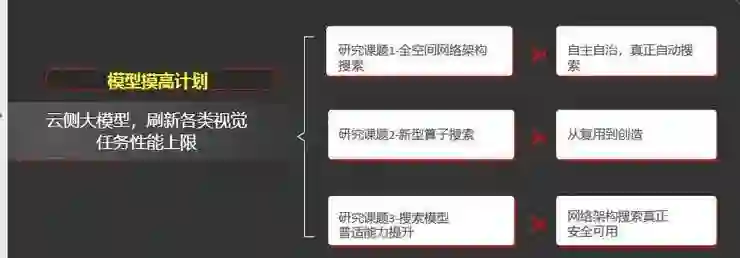
模型摸高计划考虑云侧大模型,刷新各类视觉任务性能上限。这包含了三个子课题:第一个是全空间网络架构搜索,希望不受算子、搜索网络的限制,真正实现自主自治,真正自动搜索。
第二个是新型算子搜索,希望设计与芯片相关的算子,让算子从复用到创造。
第三个是搜索模型的普适能力提升,之前提到搜索设计的模型与手工设计的模型相比普适性较差,我们希望将来的网络搜索能够真正的安全可用。
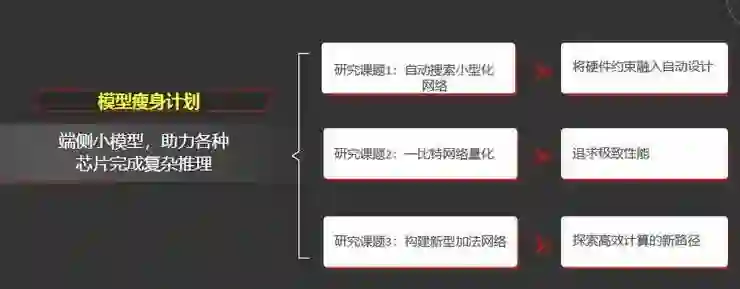
模型瘦身计划则针对端侧小模型,助力各种芯片完成复杂推理。其同样包含三个子课题:第一个小课题是自动搜索小型化,将硬件的约束融入自动设计,比如说功耗、时延的约束等。
第二个小课题研究低比特网络量化,尤其是一比特网络量化,追求极致的性能。
第三是构建新型的加法网络,探索高效计算的新途径。

最后两个计划跟知识相关,第一个是万物预视计划,主要目标是定义预训练任务以构建通用的视觉模型。

第二个是虚实合一计划,其主要目标是解决数据标注瓶颈的问题,希望在虚拟的场景下不通过数据标注,直接训练智能行为本身。
该领域早期的研究并不多,如何定义知识,如何构筑虚拟世界,如何模拟用户行为,如何在虚拟的场景中保证智能体的安全,比如说在虚拟的场景中做无人驾驶的训练,相信这是真正通向通用人工智能的一个有益的方向。
我们的视觉研究计划欢迎全球的AI研究者加入我们,这是基于昇腾AI计算平台,加速计算机视觉基础研究。
最后介绍一下我们的研究进展,以及华为云AI培养人才的理念。华为云AI希望打造一支世界一流的AI研究团队,主要从开放、创新、培养六个字践行,我们需要打造的是一个具有华为特色的人工智能军团。

众所周知,在计算机视觉领域有三大顶会:CVPR、ECCV和ICCV。CVPR一年一次,ECCV和ICCV每两年一次。CVPR在本领域的会议中排名第一,在所有的计算机和非计算机学科中排名第10,具有广泛的影响力。
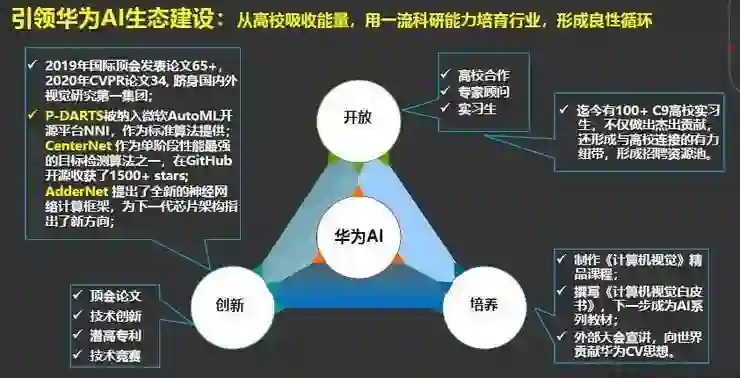
我们希望在各种顶会中取得更好的成绩,2019年我们的视觉团队在国际顶会发表论文60多篇,今年的CVPR有34篇论文,基础研究的论文发表已经跻身国际国内第一集团。
我们大量的工作也是通过我们的实习生和高校老师联合完成的,比如说P-DARTS,去年这项工作已经被纳入微软的开源平台,作为标准算法进行提供。
第二个是CenterNet,也是单阶段性能最强的目标检测算法之一,在GitHub开源收获了很高的评价。还有一个是AdderNet提出了全新的神经网络计算架构,为下一代芯片架构指出了新方向。
第二方面是开放,我们希望与顶级的高校老师合作,华为的视觉团队过去1-2年中有100多位C9高校和其它的高校的实习生,他们不仅做出了杰出的贡献,而且也形成了与高校之间有力的纽带。
第三是从培养的角度出发,视觉团队制作了计算机视觉精品课程,同时也撰写了计算机视觉白皮书,希望下一步成为AI系列教材,最后对内外部宣讲。

最后把我们半年来的视觉领域的进展与各位分享一下,我们的目标是希望在各项视觉基础任务中打造性能最强的计算模型,积极投入D+M生态建设。
在全监督学习方面,把全空间、网络架构搜索和数据扩增技术结合,在ImageNet达到85.8%的精度,打破谷歌三年的垄断。
另外,在自研的数据增强技术方面,在MS-COCO这样一个业界具有挑战的测试集,目前不管是单模型还是多模型,我们都达到业界第一,其中多模型达到58.8%的检测精度,也打破了微软多年的垄断。
在多模态学习方面,目前在自动驾驶数据集Nuscenes Challenge上取得业界第一的检测精度,击败来自全球92支队伍并大幅度领先第二名达3.1%。
最后,在弱监督方面,我们在2020年的图象识别竞赛WebVision达到业界第一的精度。在无监督方面,我们在无标签ImageNet-1000数据集上达到了业界领先的75.5%的精度,大大超过了Facebook保持的71.1%的精度。
未来希望我们的无监督学习能逼近甚至超越监督学习的极限。
以上就是华为视觉计划的一些介绍和进展,谢谢大家。
下载1:动手学深度学习
在CVer公众号后台回复:动手学深度学习,即可下载547页《动手学深度学习》电子书和源码。该书是面向中文读者的能运行、可讨论的深度学习教科书,它将文字、公式、图像、代码和运行结果结合在一起。本书将全面介绍深度学习从模型构造到模型训练,以及它们在计算机视觉和自然语言处理中的应用。

下载2:CVPR / ECCV 2020开源代码
在CVer公众号后台回复:CVPR2020,即可下载CVPR 2020代码开源的论文合集
在CVer公众号后台回复:ECCV2020,即可下载ECCV 2020代码开源的论文合集
重磅!CVer-论文写作与投稿交流群成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满2000+人,旨在交流顶会(CVPR/ICCV/ECCV/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI等)、SCI、EI等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!



