【ICML2020】北大本科生提出基于图到图翻译的分子逆合成预测框架
史晨策1, 徐民凯2, 郭宏裕3, 张铭1, 唐建4
1北京大学计算机科学技术系
2上海交通大学
3加拿大国家研究委员会
4魁北克学习算法研究院(Mila)
论文网址:https://arxiv.org/abs/2003.12725


摘要:
新药发现(Drug Discovery)领域中的一个基础问题是预测目标分子的合成路线,即逆合成预测(Retrosynthesis Prediction)。现有的方法大多将给定的目标分子(产物)与许多化学反应模版匹配,从而预测可能的反应物。然而,模版匹配耗费大量的算力,并且这些方法在新数据集上的泛化能力也欠佳。本文提出了一种名为G2Gs的不依赖化学反应模版的方法。G2Gs通过一系列图变换,将产物分子转换(或称为翻译)到反应物分子。G2Gs首先通过一个反应中心预测模块,将产物分子分解为多个合成子。然后它通过一个变分图翻译模块,将每个合成子转换到最终的反应物分子。实验结果表明,本文提出的方法的性能远优于那些不依赖反应模版的方法。并且,G2Gs的性能与基于模版的方法相近,但它不依赖任何领域知识,也有更好的可扩展性。
本文第一作者史晨策是北大计算机科学技术系2016级本科生,也是第一届图灵班学生,获得北京大学信息科学技术学院“十佳”优秀本科毕业论文奖,已被MILA唐建教授录为研究生。
一、 研究背景与动机
逆合成预测旨在预测可以合成给定化学产物的反应物分子集合,它是计算化学和新药发现领域中的一个基础任务。因为化学分子空间是离散且巨大的,这个问题非常具有挑战性。近几十年来,人们一直尝试用计算机技术来辅助这个任务。近年来,随着图表示学习技术的发展,基于机器学习算法来解决逆合成预测问题成为了机器学习领域的研究热点。
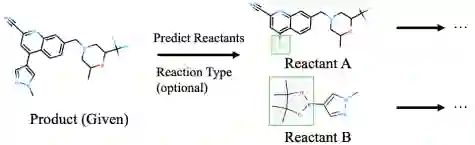
图1. 逆合成预测示意图
现有的关于逆合成分析的机器学习算法主要有两类:基于反应模版的方法和不依赖反应模版的方法。前者将目标分子与许多反应模版进行匹配,每个反应模版定义了一系列类似的化学反应的子图特征。虽然基于模版的方法有较好的可解释性,但是它们需要昂贵的子图匹配,并且一旦匹配失败,则模型不能给出任何的预测。
后者将逆合成预测当作是一个序列到序列(sequence-to-sequence)问题,它们将分子表示成字符串并利用机器翻译中的经典模型(如Transformer)将产物分子的字符串表示翻译到反应物分子的字符串表示。然而,分子的字符串表示往往不能有效地刻画分子中各原子之间的复杂关系,这类方法的预测结果也因此不尽如人意。
为了克服以上缺点,本文旨在设计一种不依赖反应模版的逆合成预测模型,同时它应将分子表示为图结构数据。本文的动机如下:(1)在化学反应中,只有一部分基团发生了变化,大部分基团则保持不变。现有的方法大多从头开始生成反应物,本文将尽可能利用那些保持不变的基团的信息。(2)有机反应的机理可由代表电子流动的箭头来表示,每个箭头表示一个键的断裂或形成,本文提出的模型将隐式地模拟此过程。基于以上观察,本文提出了G2Gs(Graph to Graphs)算法。
二、 G2Gs模型介绍
下面,本文将介绍G2Gs的模型结构。G2Gs是一个新颖的不依赖反应模版的方法,它将每个有机分子表示成一张分子图,并将逆合成预测看作是从产物图到反应物图的翻译过程。准确地说,本文首先使用一个图神经网络来估计分子中每个原子对间的反应活性,超过某一阈值且活性最高的原子对被识别为反应中心。然后G2Gs将反应中心断裂,从而将产物分子断裂成多个合成子。最后,基于这些合成子,G2Gs通过一系列图翻译来生成反应物。G2Gs的整体框架如图2所示。
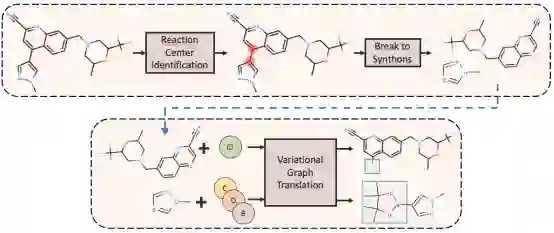
图2. G2Gs模型结构
G2Gs的第一个模块是反应中心鉴别模块。一个原子对(i,j)被称为是一个反应中心若:(1)产物中原子i和原子j之间有边。(2)反应物中原子i和原子j之间没有边。因为数据集中每个化学反应的产物和反应物中的原子都是一一对应的,我们可以很容易地通过比较产物和反应物来获得每个化学反应的反应中心。给定目标分子,G2Gs首先利用图神经网络来获得分子的低维表示,并利用边的嵌入表示来估计每个原子对的反应活性。然后G2Gs将反应活性最高的原子对作为反应中心,将其断裂,从而将目标分子分割成多个合成子。该模块将一对多的图翻译任务转换成了多个一对一的翻译任务,从而降低了问题的难度。
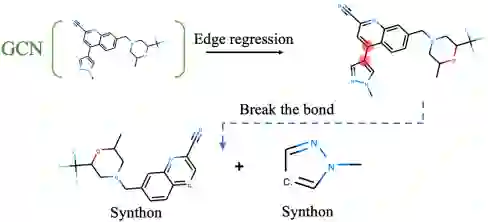
图3:反应中心鉴别模块
G2Gs的第二个模块是变分图翻译模块,其目的是将每个合成子翻译到最终的反应物。G2Gs将该过程看作是马尔可夫决策过程,它将当前子图视为当前的状态,并依次决定要采取何种动作,例如添加一个原子或一条边。值得一提的是,两个同样的合成子可能会被翻译成不同的反应物,为了鼓励模型生成多样的预测,本文在该模块中加入了一个隐变量来刻画这种不确定性。具体地说,该模块的每个决策包含四个动作:选取第一个点,选取第二个点,选取两个点之间边的类型,判断翻译过程是否中止。该模块框架图如下:
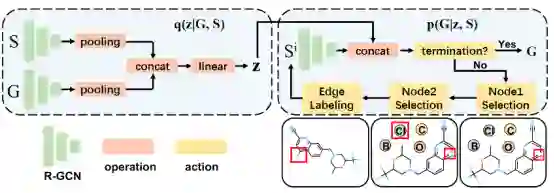
图4:变分图翻译模块
三、 实验分析
为了验证G2Gs的性能,本文在标准数据集USPTO-50K上进行了实验,它包含5万个原子对应的化学反应。本文采用top-k字符串精确匹配作为评估指标,即将预测的反应物的字符串表示与Ground Truth的字符串表示进行比较。本文在反应类型已知和反应类型未知两种情形下比较了各模型的性能,实验结果如下表所示。
表1.反应类型已知情况下各模型的性能对比
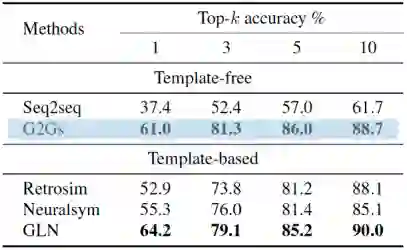
表2. 反应类型未知情况下各模型的性能对比
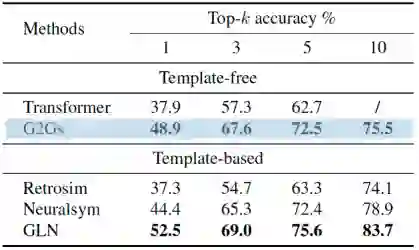
结果表明,和不依赖模版的方法相比,G2Gs总是大幅优于这些基准模型。和基于模版的方法相比,本文的G2Gs接近或者优于当前最好的模型GLN的性能。
为了让读者对G2Gs有更直观的理解,本文给出了几组预测的可视化。图5展示了G2Gs预测准确的几个样例。这些反应所蕴含的反应模版如图5底部所示。图6展示了模型预测错误的一个案例。然而,这并不意味着本文的模型在这个案例上没能成功地预测一个可行的合成路线。这是因为一个分子往往可以通过多种方式合成,而数据集中的标签并不一定是唯一的方案。为了验证这个猜想,本文使用了一个前向反应预测模型。这个模型把G2Gs的预测结果(反应物)当作输入,并预测该反应的产物。如图6底部所示,该模型预测的结果正是逆合成任务的输入,这表明,G2Gs提供的合成路线的确可能是正确的。
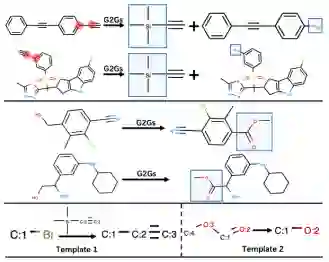
图5: 几个预测正确的案例。
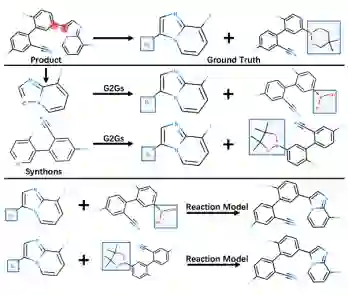
图6:一个预测错误的案例
四、 总结与展望
本文将逆合成预测任务看作是一个图到图的翻译任务并提出了一种不依赖反应模版的方法。另外,我们设计了一种变分图翻译模块,它可以有效地刻画预测过程中的不确定性,并生成多样的图翻译结果。本文通过实验证明了提出的方法的优良性能。本文的方法不需要任何领域知识并且在大数据集上的扩展性非常好,这使它在真实应用场景中非常有前景。未来,作者计划将G2Gs扩展到可支持端到端训练的形式,并且将其应用到多步逆合成预测任务上。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“G2GS” 可以获取《【ICML2020】北大本科生提出基于图到图翻译的分子逆合成预测框架》专知下载链接索引




