机器之心 & ArXiv Weekly Radiostation
参与:杜伟、楚航、罗若天
本周的重要论文有 DeepMind 联合哈佛大学等机构造出 3D 模拟小老鼠来探索神经网络,以及伯克利提出的数据增强加持的强化学习方法实现了多环境下的 SOTA结果。
DeepEEP Neuroethology of A Virtual Rodent
Training with Quantization Noise for Extreme Model Compression
Lite Transformer With Long-short Range Attention
Decoupling Representation and classifier for long-tailed recognition
Bayesian Deep Learning and a Probabilistic Perspective of Generalization
MakeItTalk: Speaker-Aware Talking Head Animation
Reinforcement Learning with Augmented Data
ArXiv Weekly Radiostation:NLP、CV、ML更多精选论文(附音频)
论文 1:DeepEEP Neuroethology of A Virtual Rodent
摘要:
人工神经网络算是目前最为先进的人工智能,这是一类由多层神经元互联组件构成的机器学习算法,而「神经元」最早就是来自大脑结构的启发。尽管人工神经网络中的神经元肯定不同于实际人脑中的工作方式,但越来越多的研究者认为,将二者放在一起研究不仅可以帮助我们理解神经科学,还有助于打造出更加智能的 AI。
DeepMind 和哈佛大学的研究者就在这一思路上进行了探索。
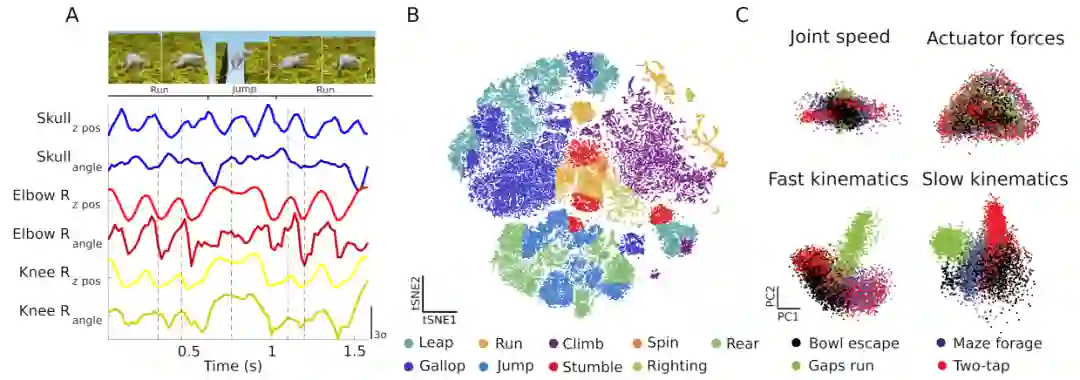
他们提出的是一种小鼠的 3D 模型,这一模型可在模拟环境中接受神经网络的控制
。同时,他们用神经科学技术来分析小鼠的大脑生物活动,由此来理解神经网络如何控制小鼠的行为。
![]()
![]()
虚拟小鼠分别执行跳过空隙、迷宫觅食、逃离丘陵和前爪精确击球四项任务。
![]()
推荐:
该论文目前已被 ICLR 2020 大会接收为 Spotlight 论文。
论文 2:Training with Quantization Noise for Extreme Model Compression
摘要:
剪枝和蒸馏是模型压缩中常用的两种方法,通过减少网络权重的数量来删减参数。还有一种方法就是「量化」,不同的是,它是通过减少每个权重的比特数来压缩原始网络。标量量化(scalar quantization)等流行的后处理量化方法是让训练网络的浮点权重以一个低精度表征去表示,比如说定宽整数。这些后处理量化方法的好处在于压缩效率很高,并且能够加速支持硬件上的推理。但缺点在于,这些近似值造成的误差会在前向传播的计算过程中不断累积,最终导致性能显著下降。
现在,
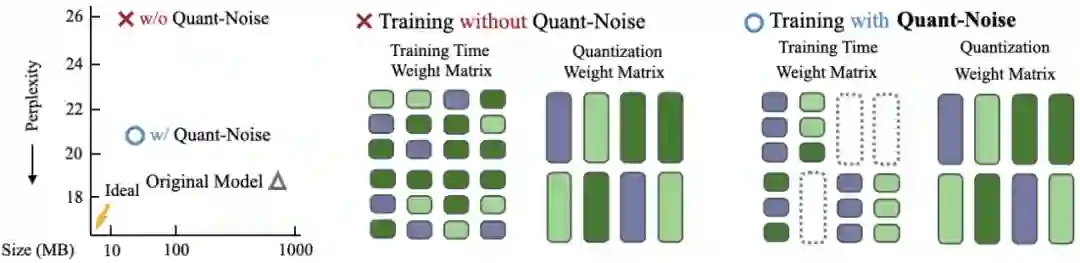
来自 Facebook 的研究者提出了一种新的模型量化压缩技术 Quant-Noise,可对模型进行极致压缩,同时在实际应用部署时保持高性能
。在这项研究中,研究者提出了一种仅量化权重子集而非整个网络的压缩方案。在每次前向传播时仅量化网络的随机部分,对大多数权重使用无偏梯度进行更新。
![]()
利用/未利用 Quant-Noise 训练的两种情况。
![]()
研究者在训练过程中将量化噪声应用于权重子集,从而改善了量化模型的性能。
![]()
在未利用 Quant-Noise 训练、利用 Quant-Noise 微调以及利用 Quant-Noise 训练三种不同的设置下,Adaptive Input 架构的困惑度和 RoBERTa 的准确率变化情况。可以看出,直接利用 Quant-Noise 训练可以实现最低的困惑度和最高的准确率。
推荐:
该方法可以在训练过程中采用更简单的量化方案,这对于具有可训练参数的量化模块来说是非常有用的,比如乘积量化(Product Quantizer,PQ)算法。
论文 3:Lite Transformer With Long-short Range Attention
摘要:
虽然推出还不到 3 年,Transformer 已成为自然语言处理(NLP)领域里不可或缺的一环。然而这样流行的算法却需求极高的算力才能实现足够的性能,这对于受到算力和电池严格限制的移动端来说有些力不从心。
在本文中,
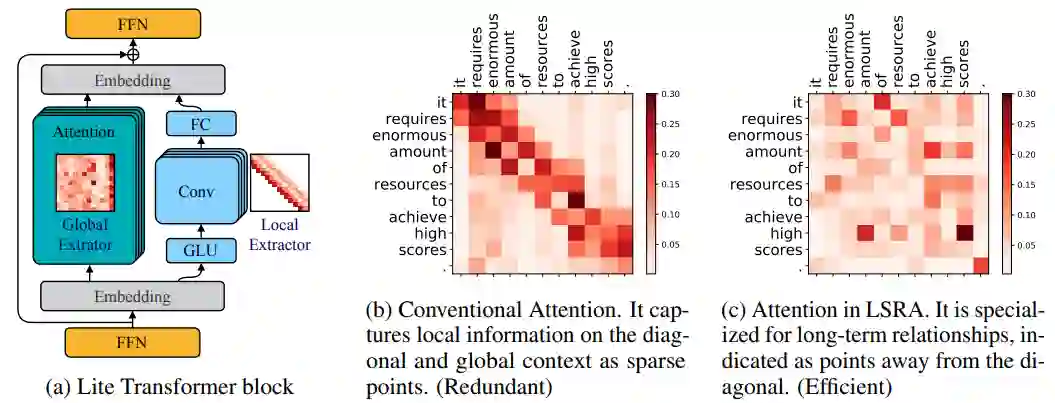
来自 MIT 与上海交大的研究人员提出了一种高效的移动端 NLP 体系结构 Lite Transformer,向在边缘设备上部署移动级 NLP 应用迈进了一大
步
。该研究是由 MIT 电气工程和计算机科学系助理教授韩松领导的。
![]()
Lite Transformer 架构 (a) 和注意力权重的可视化,传统的注意力 (b) 过于强调局部关系建模。
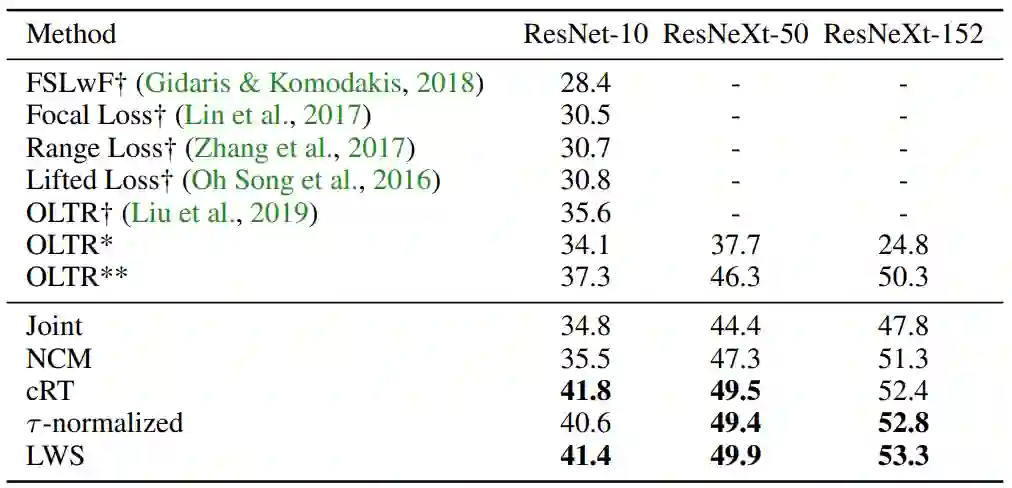
论文 4:Decoupling Representation and classifier for long-tailed recognition
摘要:
针对长尾分布的图像识别任务,目前的研究和实践提出了大致几种解决思路,比如分类损失权重重分配(loss re-weighting)、数据集重采样、尾部少量样本过采样、头部过多样本欠采样,或者迁移学习。
来自新加坡国立大学与 Facebook AI 的研究者提出了一个新颖的解决角度:在学习分类任务的过程中,将通常默认为联合起来学习的类别特征表征与分类器解耦(decoupling),寻求合适的表征来最小化长尾样本分类的负面影响
。
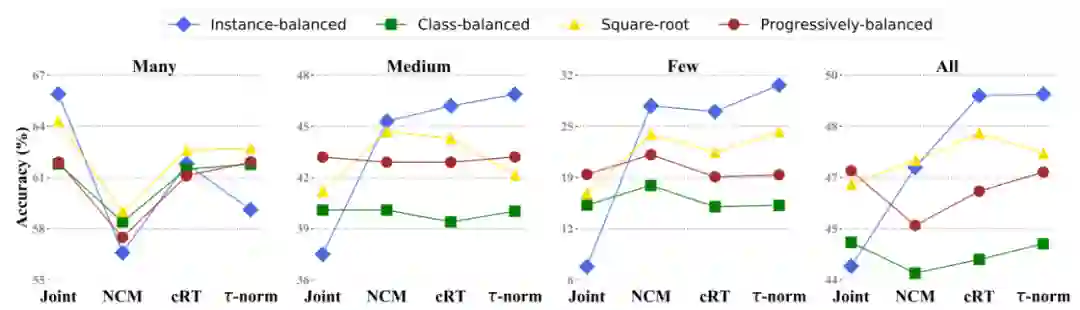
该研究系统性地探究了不同的样本均衡策略对长尾型数据分类的影响,并进行了详实的实验,结果表明:a) 当学习到高质量的类别表征时,数据不均衡很可能不会成为问题;b) 在学得上述表征后,即便应用最简单的样本均衡采样方式,也一样有可能在仅调整分类器的情况下学习到非常鲁棒的长尾样本分类模型。该研究将表征学习和分类器学习分离开来,分别进行了延伸探究。
![]()
该研究在几个公开的长尾分类数据集上重新修改了头部类别和尾部类别的分类决策边界,并且搭配不同的采样策略进行交叉训练实验。以上是训练出的不同分类器之间的对比结果。
![]()
在 Places-LT、Imagenet-LT 和 iNaturalist2018 三个公开标准数据集上,该研究提出的策略也获得了同比更高的分类准确率,实现了新的 SOTA 结果。
推荐:
将表征学习和分类器学习分开,寻找合适的表征来最小化长尾样本分类的负面影响,这提供了长尾型分类的新思路。论文已被 ICLR 2020 接收。
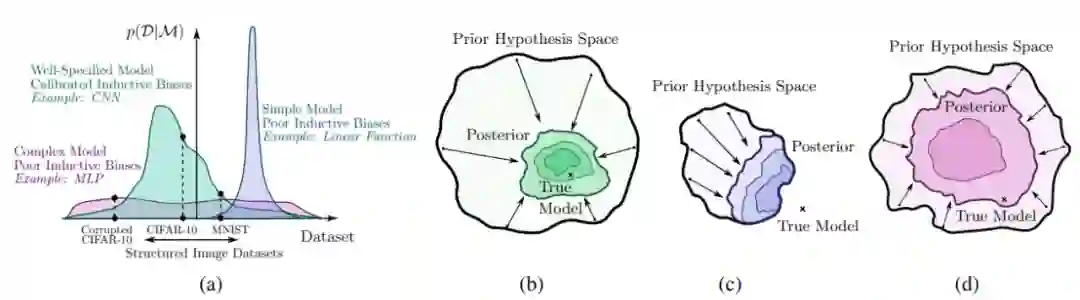
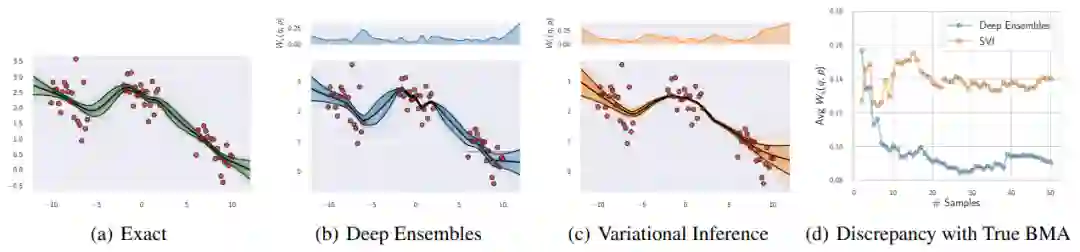
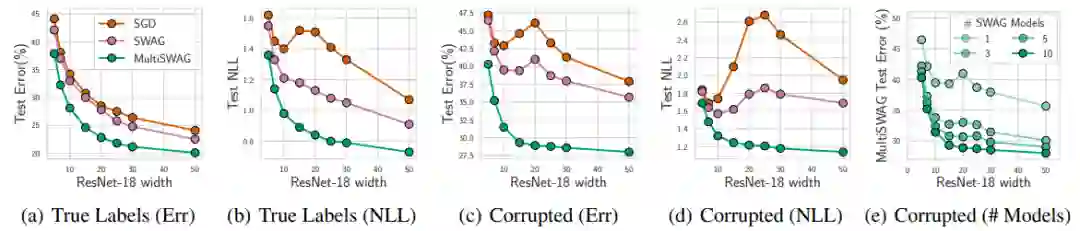
论文 5:Bayesian Deep Learning and a Probabilistic Perspective of Generalization
摘要:
贝叶斯方法的一个关键区别性特征在于边缘化,而不在于使用单一设置(single setting)的权重。贝叶斯边缘化尤其可以提升现代深度神经网络的准确率和校准。在这篇论文中,
来自纽约大学的两位研究者表示,深度集成可以为近似贝叶斯边缘化提供一种有效机制,并且他们提出的相关方法在开销不大的情况下通过在吸引域(basins of attraction)内的边缘化进一步提升了预测分布
。
此外,研究者还探究了神经网络权重上模糊分布所隐含的函数先验(prior over function),并从概率性的角度解释此类模型的泛化性能。从这个角度来看,研究者解释了对神经网络泛化来说神秘且独特的结果,例如利用随机标签拟合图像的能力,并展示了这些结果可以通过高斯过程来复现。此外,他们还表示,贝叶斯模型一般可以减轻双下降(double descent),从而能够提升单调性能且增强灵活性。最后研究者从贝叶斯的视角解释了预测分布校准的回火问题。
![]()
![]()
![]()
推荐:
本篇论文第一版提交于 2020 年 2 月,这是修改后的第二版。论文已被 ICML 2020 接收。
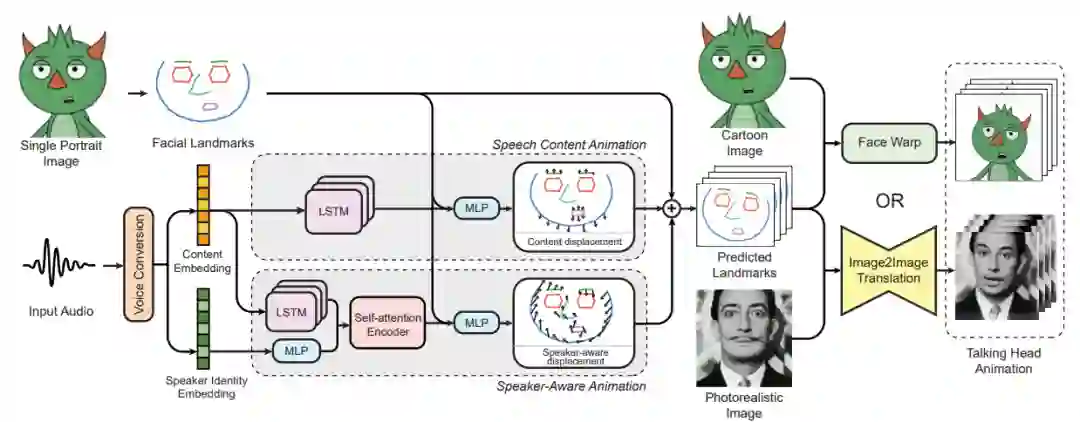
论文 6:MakeItTalk: Speaker-Aware Talking Head Animation
摘要:
今天我们来看 Adobe 的一项研究,
该研究提出了一种叫做 MakeItTalk 的新模型,不仅能让真人头像说话,还可以把卡通、油画、素描、日漫中的人像动态化
。
该研究提出了一种新方法,可以基于单张人脸图像和语音生成惊艳的说话状态头部动画。之前的方法往往学习音频和原始像素之间的直接映射来创建说话人面部,而该方法将输入音频信号中的内容和说话人信息分离开来。音频内容稳健地控制嘴唇及周围面部区域的运动,说话人信息则决定人脸表情的细节和说话人的头部动态。
该方法的另一个重要组件是预测能够反映说话人动态的人脸特征点
。基于该中间表征,该方法能够合成包含完整运动的说话人面部逼真视频。此方法还可使艺术作品、素描、2D 卡通人物、日漫、随手涂鸦转化为会说话的动态视频。
![]()
本研究中 MakeItTalk 方法的 Pipeline。
![]()
预测得到的卡通形象和动画和真实人脸动画。MakeItTalk 合成的不仅是面部神情,还有不同的头部姿态。
![]()
推荐:
通过对该方法的定量和定性评估,结果表明与之前的 SOTA 方法相比,该方法能够生成的说话状态头部动画质量更高。
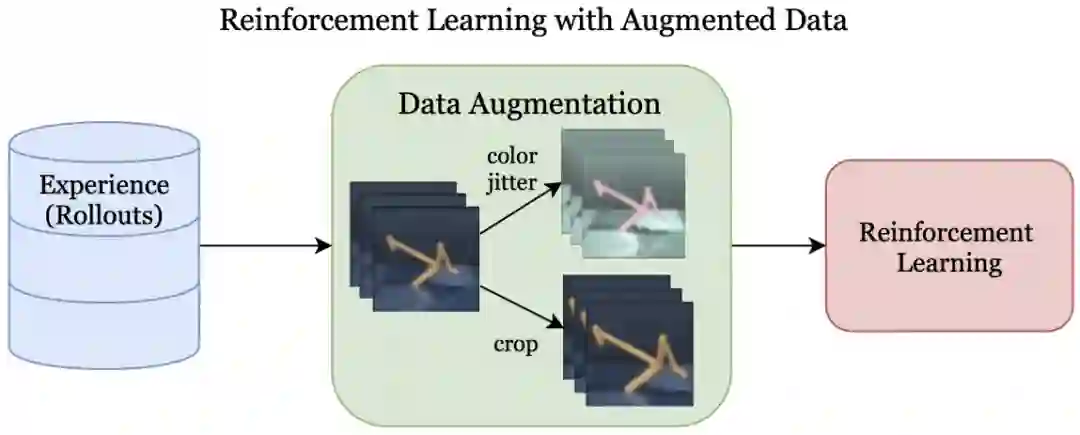
论文 7:Reinforcement Learning with Augmented Data
摘要:
在本文中,
来自加州大学伯克利分校的研究者提出了利用增强数据来进行强化学习(Reinforcement Learning with Augmented Data,简称为 RAD),这是一种可以增强任何 RL 算法的即插即用模块
。他们发现,从数据效率、泛化性和墙上时钟速度三方面来看,随机修剪、色彩抖动和随机卷积等数据增强方法在常用基准上能够使简单 RL 算法的性能媲美甚至超越当前 SOTA 方法。
在 DeepMind 控制套件上,研究者证实就数据效率和性能两方面而言,RAD 在 15 个环境中均实现了当前 SOTA 效果,并且 RAD 可以显著提升几个 OpenAI ProcGen 基准上的测试时泛化性。最后自定义的数据增强模块可以实现较类似 RL 方法更快的墙上时钟速度。
![]()
Reinforcement Learning with Augmented Data(RAD)架构。
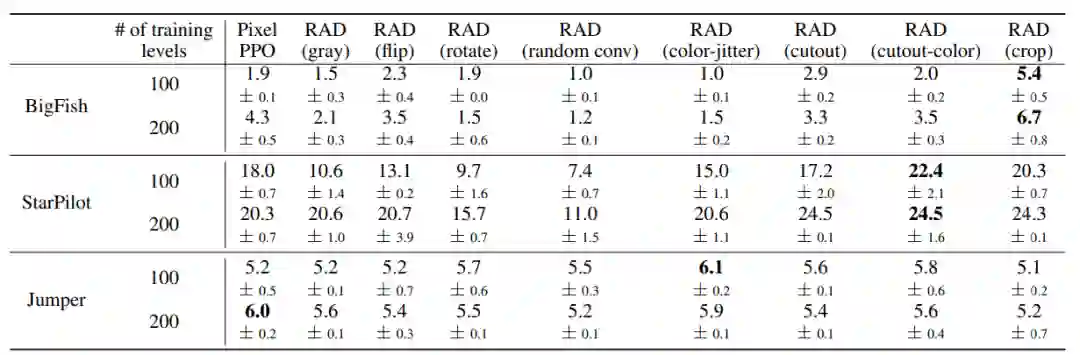
![]()
![]()
RAD 与不同数据增强方法在 3 个 OpenAI ProcGen 环境(BigFish、StarPilot 和 Jumper)中的泛化结果对比。
推荐:
在 DeepMind 控制套件上,RAD 在 15 个环境中均实现了当前 SOTA 效果。
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
1. Empower Entity Set Expansion via Language Model Probing. (from Yunyi Zhang, Jiaming Shen, Jingbo Shang, Jiawei Han)
2. DomBERT: Domain-oriented Language Model for Aspect-based Sentiment Analysis. (from Hu Xu, Bing Liu, Lei Shu, Philip S. Yu)
3. Stay Hungry, Stay Focused: Generating Informative and Specific Questions in Information-Seeking Conversations. (from Peng Qi, Yuhao Zhang, Christopher D. Manningg)
4. Interpretable Multimodal Routing for Human Multimodal Language. (from Yao-Hung Hubert Tsai, Martin Q. Ma, Muqiao Yang, Ruslan Salakhutdinov, Louis-Philippe Morency)
5. Politeness Transfer: A Tag and Generate Approach. (from Aman Madaan, Amrith Setlur, Tanmay Parekh, Barnabas Poczos, Graham Neubig, Yiming Yang, Ruslan Salakhutdinov, Alan W Black, Shrimai Prabhumoye)
6. Recipes for building an open-domain chatbot. (from Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Kurt Shuster, Eric M. Smith, Y-Lan Boureau, Jason Weston)
7. Detecting Domain Polarity-Changes of Words in a Sentiment Lexicon. (from Shuai Wang, Guangyi Lv, Sahisnu Mazumder, Bing Liu)
8. Unnatural Language Processing: Bridging the Gap Between Synthetic and Natural Language Data. (from Alana Marzoev, Samuel Madden, M. Frans Kaashoek, Michael Cafarella, Jacob Andreas)
9. Knowledge Graph Empowered Entity Description Generation. (from Liying Cheng, Yan Zhang, Dekun Wu, Zhanming Jie, Lidong Bing, Wei Lu, Luo Si)
10. Self-Attention with Cross-Lingual Position Representation. (from Liang Ding, Longyue Wang, Dacheng Tao)
1. Pyramid Attention Networks for Image Restoration. (from Yiqun Mei, Yuchen Fan, Yulun Zhang, Jiahui Yu, Yuqian Zhou, Ding Liu, Yun Fu, Thomas S. Huang, Honghui Shi)
2. Stitcher: Feedback-driven Data Provider for Object Detection. (from Yukang Chen, Peizhen Zhang, Zeming Li, Yanwei Li, Xiangyu Zhang, Gaofeng Meng, Shiming Xiang, Jian Sun, Jiaya Jia)
3. Leveraging Photometric Consistency over Time for Sparsely Supervised Hand-Object Reconstruction. (from Yana Hasson, Bugra Tekin, Federica Bogo, Ivan Laptev, Marc Pollefeys, Cordelia Schmid)
4. Consistent Video Depth Estimation. (from Xuan Luo, Jia-Bin Huang, Richard Szeliski, Kevin Matzen, Johannes Kopfi)
5. DFUC2020: Analysis Towards Diabetic Foot Ulcer Detection. (from Bill Cassidy, Neil D. Reeves, Pappachan Joseph, David Gillespie, Claire O'Shea, Satyan Rajbhandari, Arun G. Maiya, Eibe Frank, Andrew Boulton, David Armstrong, Bijan Najafi, Justina Wu, Moi Hoon Yap)
6. The 4th AI City Challenge. (from Milind Naphade, Shuo Wang, David Anastasiu, Zheng Tang, Ming-Ching Chang, Xiaodong Yang, Liang Zheng, Anuj Sharma, Rama Chellappa, Pranamesh Chakraborty)
7. Gabriella: An Online System for Real-Time Activity Detection in Untrimmed Surveillance Videos. (from Mamshad Nayeem Rizve, Ugur Demir, Praveen Tirupattur, Aayush Jung Rana, Kevin Duarte, Ishan Dave, Yogesh Singh Rawat, Mubarak Shah)
8. Fashionpedia: Ontology, Segmentation, and an Attribute Localization Dataset. (from Menglin Jia, Mengyun Shi, Mikhail Sirotenko, Yin Cui, Claire Cardie, Bharath Hariharan, Hartwig Adam, Serge Belongie)
9. Multi-Scale Boosted Dehazing Network with Dense Feature Fusion. (from Hang Dong, Jinshan Pan, Lei Xiang, Zhe Hu, Xinyi Zhang, Fei Wang, Ming-Hsuan Yang)
10. Deep Multimodal Neural Architecture Search. (from Zhou Yu, Yuhao Cui, Jun Yu, Meng Wang, Dacheng Tao, Qi Tian)
1. Image Augmentation Is All You Need: Regularizing Deep Reinforcement Learning from Pixels. (from Ilya Kostrikov, Denis Yarats, Rob Fergus)
2. Energy-based models for atomic-resolution protein conformations. (from Yilun Du, Joshua Meier, Jerry Ma, Rob Fergus, Alexander Rives)
3. Visual Grounding of Learned Physical Models. (from Yunzhu Li, Toru Lin, Kexin Yi, Daniel Bear, Daniel L. K. Yamins, Jiajun Wu, Joshua B. Tenenbaum, Antonio Torralba)
4. Towards Feature Space Adversarial Attack. (from Qiuling Xu, Guanhong Tao, Siyuan Cheng, Lin Tan, Xiangyu Zhang)
5. Non-Exhaustive, Overlapping Co-Clustering: An Extended Analysis. (from Joyce Jiyoung Whang, Inderjit S. Dhillon)
6. An Explainable Deep Learning-based Prognostic Model for Rotating Machinery. (from Namkyoung Lee, Michael H. Azarian, Michael G. Pecht)
7. Reinforcement Learning with Augmented Data. (from Michael Laskin, Kimin Lee, Adam Stooke, Lerrel Pinto, Pieter Abbeel, Aravind Srinivas)
8. Explainable Unsupervised Change-point Detection via Graph Neural Networks. (from Ruohong Zhang, Yu Hao, Donghan Yu, Wei-Cheng Chang, Guokun Lai, Yiming Yang)
9. Plan-Space State Embeddings for Improved Reinforcement Learning. (from Max Pflueger, Gaurav S. Sukhatme)
10. Privacy in Deep Learning: A Survey. (from Fatemehsadat Mirshghallah, Mohammadkazem Taram, Praneeth Vepakomma, Abhishek Singh, Ramesh Raskar, Hadi Esmaeilzadeh)
![]()