




长按识别二维码享更多精彩
↑ 点击上方蓝字关注我们,和小伙伴一起聊技术!
几个星期前,我们开始编写深入研究JavaScript工作原理的系列文章。通过阅读这些文章,你可以了解到JavaScript的构建块及其交互原理,从而能够编写出更好的代码(前排提示:文中所有标蓝部分均可阅读原文获取详情)。
本系列的第一篇文章简单介绍了引擎、运行时间和堆栈的调用。第二篇文章研究了谷歌V8 JavaScript引擎的内部机制,并介绍了一些编写JavaScript代码的技巧。
而这第三篇文章将讨论另一个很重要的主题——内存管理。随着编程语言变得越来越成熟越来越复杂,开发人员很容易忽视这一问题。同时,本文还将提供一些处理JavaScript内存泄漏的技巧,既能确保SessionStack不会出现内存泄漏,也不会增加web应用程序的内存占用。
概述
像C这样的编程语言都会有低级别的内存管理原语,例如malloc()和free()。开发人员使用这些原语能够显式地对内存进行分配和释放。
而JavaScript会在对象(对象、字符串等)创建时为它们分配内存,在对象不再使用时,“自动”释放内存。这个过程我们称之为垃圾收集。这种看似很“自动化”的资源释放机制其实是混乱的根源,因为这给JavaScript(以及其他高级语言)开发人员带来了一种错觉,认为自己可以不用管理内存。这种想法是错误的。
即使是使用高级语言,开发人员也应该了解一些内存管理方面的知识(或者至少懂得一些基础知识)。因为在自动内存管理(比如垃圾收集器的bug或实现限制等)出现问题的时候,开发人员必须能够理解并正确地解决这些问题(或者找到一个合适的解决方案,以最低的代价来修改代码)。
内存的生命周期
无论使用哪种编程语言,内存的生命周期都是一样的:
这里简单介绍一下内存生命周期中的每一个阶段:
分配内存——内存由操作系统分配,并允许程序使用它。在低级语言(例如C)中,开发人员必须显式地执行这一操作。而在高级语言中,系统会自动为你分配内存。
使用内存——在这一步中,程序将使用先前分配的内存。在代码中使用已分配过内存的变量时,就会发生内存读写操作。
释放内存——释放所有不再使用的内存,使之成为自由内存,并可以被重利用。与分配内存操作一样,这一操作在低级语言中也是需要显式地执行。
要快速了解调用栈和内存堆的相关概念,你可以阅读本系列的第一篇文章。
内存是什么?
在介绍JavaScript中的内存之前,我们先来简单讨论一下什么是内存,以及它是如何工作的。
在硬件层面上,计算机存储器由大量的触发器组成。每个触发器包含了一些晶体管,并且能够存储一个比特(bit,又称“位”)。单个触发器由唯一的标识符来寻址,这样我们就能够读取和覆盖它们。因此,从概念上讲,可以把整个计算机内存看作是可以读写的一个巨大数组。
因为我们并不擅长用比特来思考和计算,所以要把它们组织成更大的群体,这样才可以用来表示数字。8个比特称为1个字节(byte)。除了字节之外,还有字(word,有时是16位,有时是32位)。
很多东西都存储在内存中:
程序使用的所有变量和其他数据。
程序的代码,包括操作系统的代码。
编译器和操作系统会为你处理大部分的内存管理工作,但你还是需要了解一下底层到底发生了什么。
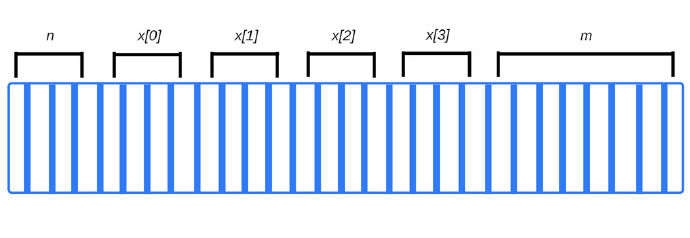
编译代码时,编译器会检查原始数据类型并提前计算所需的内存,然后将所需的数量分配给调用堆栈空间中的程序。为这些变量分配的空间称为栈空间,因为当函数被调用时,它们的内存就会被添加到现有内存中。当调用终止时,它们将会在LIFO命令(后进先出)中被移除。例如,看一下这个声明:
int n; // 4个字节
int x[4]; // 4个元素的数组,每个元素4个字节
double m; // 8个字节
编译器能够立即知道所需的内存:4 + 4×4 + 8 = 28字节
这段代码展示了整型和双精度浮点型变量所占内存的大小。但是大约20年前,整型变量通常占2个字节,而双精度浮点型变量占4个字节。你的代码不应该依赖于当前基本数据类型的大小。
编译器会插入与操作系统交互的代码,并同时在栈上申请要存储的变量所需的字节数。
在上面这个例子中,编译器知道每个变量准确的内存地址。事实上,当我们写入变量n时,它就会被翻译成类似“内存地址4127963”这样的内部信息。
注意,如果尝试访问x[4],那就会访问到与m相关的数据。这是因为在数组中访问一个不存在的元素(它比数组中最后一个实际分配的元素x[3]还要大4个字节),最终可能会读取(或重写) 到m的位,这肯定会对程序的其余部分产生不可预知的结果。
当一个函数调用其他函数时,每个函数都会得到自己的栈块。它保存了所有的局部变量,同时还有一个程序计数器,用于记录程序执行的位置。当函数执行完成时,它的内存块就可用于其他地方了。
动态分配
不幸的是,如果在编译时不知道变量需要多少内存,那情况就有点复杂了。假设要进行如下的操作:
int n = readInput(); // reads input from the user
...
// create an array with "n" elements
在编译时,编译器不知道数组需要使用多少内存,因为这是由用户提供的值决定的。
因此,不能为栈上的变量分配空间。相反,程序需要在运行时明确地向操作系统请求适当大小的空间。这个内存是在堆空间上分配。静态内存和动态内存分配的区别,请见下面这个表格:
要完全理解动态内存分配的原理,我们需要多研究研究指针,这可能有点偏离本文的主题了。
在JavaScript中分配内存
现在将解释第一步:如何在JavaScript中分配内存。
JavaScript把开发人员从内存分配的责任中解救了出来:JavaScript能自己完成这项工作,同时进行赋值。
var n = 374; // allocates memory for a number
var s = 'sessionstack'; // allocates memory for a string
var o = {
a: 1,
b: null
}; // allocates memory for an object and its contained values
var a = [1, null, 'str']; // (like object) allocates memory for the
// array and its contained values
function f(a) {
return a + 3;
} // allocates a function (which is a callable object)
// function expressions also allocate an object
someElement.addEventListener('click', function() {
someElement.style.backgroundColor = 'blue';
}, false);
某些函数调用也会导致对象的内存分配:
var d = new Date(); // allocates a Date object
var e = document.createElement('div'); // allocates a DOM element
分配新的值或对象:
var s1 = 'sessionstack';
var s2 = s1.substr(0, 3); // s2 is a new string
// Since strings are immutable,
// JavaScript may decide to not allocate memory,
// but just store the [0, 3] range.
var a1 = ['str1', 'str2'];
var a2 = ['str3', 'str4'];
var a3 = a1.concat(a2);
// new array with 4 elements being
// the concatenation of a1 and a2 elements
在JavaScript中使用内存
在JavaScript中使用分配的内存就意味着对内存进行读写,而这可以通过读写一个变量的值或者对象的属性,或者将参数传递给函数来实现。
当内存不再需要时进行释放
大多数的内存管理问题都出现在这个阶段。
最困难的工作在于计算出何时不再需要已分配的内存,这通常要求开发人员来决定在程序中哪些地方不再需要内存,并将其释放。
高级语言中嵌入了一种称为垃圾收集器的软件,它的工作是跟踪内存的分配和使用,以便在任何情况下找到一块不再需要的已分配内存,并自动将其释放。
不幸的是,这个过程只是进行粗略估计,因为很难知道某块内存是否真的需要 (不能通过算法来解决)。
垃圾收集器大多数的工作是收集无法访问的内存,例如,所有指向这块内存的变量都超出了作用域。但是,这些收集到的内存空间并不完整。因为在任何时候都可能存在这么一块内存:有一个变量指向了它,但它却永远不会被访问到。
垃圾收集
由于很难判断某块内存是否真的有用,因此,垃圾收集器想了一个办法来解决这个问题。本节将主要介绍垃圾收集的算法及其局限性。
内存引用
垃圾收集算法主要依赖的是引用。
在内存管理中,如果一个对象可以访问另一个对象,则称它在引用另一个对象(可以是隐式的或显式的)。例如,一个JavaScript对象引用它的原型(隐式引用)和它的属性值(显式引用)。
在这种情况下,“对象”这个概念就扩展到了比常规JavaScript对象更广泛的领域,并且还包含了函数作用域(或全局范围)。
引用计数垃圾收集算法
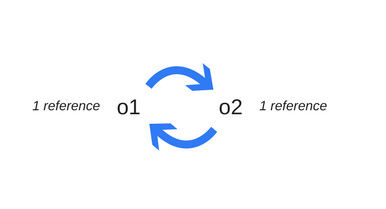
这是最简单的垃圾收集算法。如果没有指针指向一个对象,那这个对象就被认为是“可收集的垃圾”。
看下面的代码:
var o1 = {
o2: {
x: 1
}
};
// 2 objects are created.
// 'o2' is referenced by 'o1' object as one of its properties.
// None can be garbage-collected
var o3 = o1; // the 'o3' variable is the second thing that
// has a reference to the object pointed by 'o1'.
o1 = 1; // now, the object that was originally in 'o1' has a
// single reference, embodied by the 'o3' variable
var o4 = o3.o2; // reference to 'o2' property of the object.
// This object has now 2 references: one as
// a property.
// The other as the 'o4' variable
o3 = '374'; // The object that was originally in 'o1' has now zero
// references to it.
// It can be garbage-collected.
// However, what was its 'o2' property is still
// referenced by the 'o4' variable, so it cannot be
// freed.
o4 = null; // what was the 'o2' property of the object originally in
// 'o1' has zero references to it.
// It can be garbage collected.
循环会产生问题
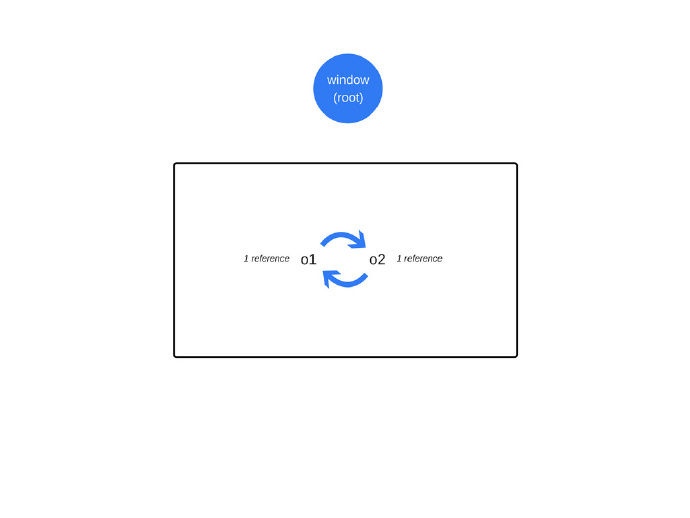
当涉及到循环时,会有一个限制。在下面的示例中,创建了两个对象,两个对象互相调用,从而创建了一个循环。在函数调用之后将超出作用域,因此它们实际上是无用的,可以被释放。然而,引用计数算法认为,由于每个对象至少被引用一次,所以它们都不能被垃圾收集。
function f() {
var o1 = {};
var o2 = {};
o1.p = o2; // o1 references o2
o2.p = o1; // o2 references o1. This creates a cycle.
}
f();
标记-清除(Mark-and-sweep)算法
该算法能够判断出某个对象是否可以访问,从而知道该对象是否有用。
该算法由以下步骤组成:
垃圾收集器构建一个“根”列表,用于保存引用的全局变量。在JavaScript中,“window”对象是一个可作为根节点的全局变量。
所有根节点都会被检查并标记为活动的(也就是说不是垃圾)。子节点都是递归检查的,所有可以从根节点中得到的都不被认为是垃圾。
所有未标记为活动的内存碎片都被视为垃圾。收集器现在可以释放这些内存并将其还给操作系统。
这个算法比上一个算法要好,因为“一个对象没有被引用”就意味着这个对象无法访问。
截止到2012年,所有的现代浏览器都有一个“标记-清除”垃圾收集器。在过去的几年里,JavaScript在垃圾收集(生成、增量、并发、并行的垃圾收集)领域所做的所有改进都是对该算法实现的改进(标记和清除),而不是对垃圾收集算法本身的改进。
在这篇文章中,你可以更详细地阅读到有关跟踪垃圾收集的详细信息,同时还包括了标记-清除算法及其优化。
循环不再是问题
在上面的第一个例子中,函数调用返回后,那两个对象就不再被全局对象可访问的东西所引用。因此,垃圾收集器会认为它们不可访问。
尽管对象之间存在引用,但它们对于根节点来说是不可达的。
垃圾收集器的反直观行为
尽管垃圾收集器很方便,但它们有一套自己的折衷方案,其中之一就是非决定论,换句话说,GC是不可预测的,你无法真正判断何时进行垃圾收集。这意味着在某些情况下,程序会使用更多的内存,这实际上是必需的。在对速度特别敏感的应用程序中,可能会很明显的感受到短时间的停顿。如果没有分配内存,则大多数GC将处于空闲状态。看看以下场景:
分配一大块内存。
大多数元素(或者所有元素)都被标记为不可访问(假设引用指向一个不再需要的缓存)。
没有继续分配内存。
在此场景中,大多数GC将不再继续收集。换句话说,即使是不可用的引用,收集器也不会夺走这些引用。虽然这些并不是严重的内存泄漏,但仍然会出现高于平时内存使用的情况。
内存泄漏是什么?
从本质上说,内存泄漏可以定义为:不再被应用程序所需要的内存,出于某种原因,它不会返回到操作系统或空闲内存池中。
编程语言支持不同的内存管理方法。然而,某一块内存是否被使用实际上无法判断。换句话说,只有开发人员才知道这块内存是否可以还给操作系统。
某些编程语言为开发人员提供了帮助,另一些则期望开发人员能清楚地了解内存何时不再被使用。维基百科上有一些有关人工和自动内存管理的很不错的文章。
四种常见的内存泄漏
1.全局变量
JavaScript以一种非常有趣的方式来处理未声明的变量: 对于未声明的变量,会在全局范围中创建一个新的变量来对其进行引用。对浏览器来说,全局对象是window。例如:
function foo(arg) {
bar = "some text";
}
等价于:
function foo(arg) {
window.bar = "some text";
}
如果bar在foo函数的作用域内对一个变量进行引用,却忘记使用var来声明它,那么将创建一个意想不到的全局变量。
在这个例子中,遗漏一个简单的字符串不会造成太大的危害,但这肯定会很糟。
创建一个意料之外的全局变量的另一种方法是使用this:
function foo() {
this.var1 = "potential accidental global";
}
// Foo called on its own, this points to the global object (window)
// rather than being undefined.
foo();
要防止这些错误发生,可以在JavaScript文件的开头添加’use strict’。这就启用了更严格的JavaScript解析模式,以防止意外的全局变量。你可以在这里了解更多到有关这种JavaScript执行的模式。
尽管我们讨论的是未知的全局变量,但仍然有很多代码充斥着显式的全局变量。根据定义,这些是不可收集的(除非被指定为空或重新分配)。用于临时存储和处理大量信息的全局变量特别令人担忧。如果你必须使用一个全局变量来存储大量数据,那么请确保将其指定为null,或者在完成后将其重新赋值。
2. 被遗忘的定时器和回调
在JavaScript中,setInterval的使用很常见。
大多数提供了观察器和采用回调工具的库,都会在自身实例变得不可访问时,自动将指向回调的引用置为不可访问。然而,对于setInterval来说,这样的代码很常见:
var serverData = loadData();
setInterval(function() {
var renderer = document.getElementById('renderer');
if(renderer) {
renderer.innerHTML = JSON.stringify(serverData);
}
}, 5000); //This will be executed every ~5 seconds.
这个例子描述了该定时器在运行时具体发生了什么:定时器引用了那些不再需要的节点或数据。
renderer表示的对象可能会在未来的某个时间点被删除,从而导致内部处理程序中的一整块代码都变得不再需要。但是,由于定时器仍然是活动的,所以,处理程序不能被收集,并且其依赖项也无法被收集。这意味着,存储着大量数据的serverData也不能被收集。
对观察器来说,当变量不再需要的时候,需要显示地删除它们(或者是无法访问的关联对象)。
过去的某些浏览器(IE 6)不能很好地管理循环引用,但这一点却尤为重要。现在,一旦被监视对象变得不可访问,即使监听器没有被显式删除,大多数浏览器也能对其进行收集。然而,我们还是应该在对象被处理之前显式地删除这些观察者。例如:
var element = document.getElementById('launch-button');
var counter = 0;
function onClick(event) {
counter++;
element.innerHtml = 'text ' + counter;
}
element.addEventListener('click', onClick);
// Do stuff
element.removeEventListener('click', onClick);
element.parentNode.removeChild(element);
// Now when element goes out of scope,
// both element and onClick will be collected even in old browsers // that don't handle cycles well.
现代浏览器(包括Internet Explorer和Microsoft Edge)使用了先进的垃圾收集算法来检测这些循环并能够正确处理它们。换句话说,在将节点置为不可访问之前,无需严格调用removeEventListener。
一些框架或库,比如JQuery,会在处置节点之前自动删除监听器(在使用它们特定的API的时候)。这是由库内部的机制实现的,能够确保不发生内存泄漏,即使在有问题的浏览器下运行也能这样,比如……IE 6。
3.闭包
JavaScript开发中有一个关键点,即闭包:一个能够访问外部(封闭)函数变量的内部函数。由于JavaScript运行时的实现细节存在问题,下面这个代码会产生内存泄漏:
var theThing = null;
var replaceThing = function () {
var originalThing = theThing;
var unused = function () {
if (originalThing) // a reference to 'originalThing'
console.log("hi");
};
theThing = {
longStr: new Array(1000000).join('*'),
someMethod: function () {
console.log("message");
}
};
};
setInterval(replaceThing, 1000);
这段代码做了一件事:每次调用replaceThing的时候,theThing都会得到一个包含一个大数组和一个新闭包(someMethod)的新对象。同时,变量unused指向一个引用了originalThing的闭包。是不是很混乱,嘿嘿?重要的是,一旦具有相同父作用域的多个闭包的作用域被创建,则这个作用域就可以被共享。
在这种情况下,为闭包someMethod而创建的作用域可以被unused共享的。unused内部存在一个对originalThing的引用。即使unused从未使用过,someMethod也可以在replaceThing的作用域之外(例如在全局范围内)通过theThing来被调用。由于someMethod共享了unused闭包的作用域,那么unused引用包含的originalThing会迫使它保持活动状态(两个闭包之间的整个共享作用域)。这阻止了它被收集。
当这段代码重复运行时,可以观察到内存使用在稳定增长,当GC运行后,内存使用也不会变小。从本质上说,在运行过程中创建了一个闭包链表(它的根是以变量theThing的形式存在),并且每个闭包的作用域都间接引用了了一个大数组,这造成了相当大的内存泄漏。
这个问题是Meteor小组发现的,他们写了一篇不错的文章详细地描述了这个问题。
4. 脱离DOM的引用
有时,将DOM节点存储在数据结构中可能会很有用。假设你希望快速地更新表中的几行内容,那么你可以在一个字典或数组中保存每个DOM行的引用。这样,同一个DOM元素就存在两个引用:一个在DOM树中,另一个则在字典中。如果在将来的某个时候你决定删除这些行,那么你需要将这两个引用都设置为不可访问。
var elements = {
button: document.getElementById('button'),
image: document.getElementById('image')
};
function doStuff() {
elements.image.src = 'http://example.com/image_name.png';
}
function removeImage() {
// The image is a direct child of the body element.
document.body.removeChild(document.getElementById('image'));
// At this point, we still have a reference to #button in the
//global elements object. In other words, the button element is
//still in memory and cannot be collected by the GC.
}
当涉及到DOM树的内部或叶节点时,还需要额外注意一个问题。假设你在JavaScript代码中有一个指向某个表(<td>标记)的特定单元格的引用。有一天,你决定从DOM中删除这个表,但要保留对该单元格的引用。人们可能会认为GC会收集所有的东西,除了单元格。但事实上,这种情况并不会发生。单元格是该表的子节点,而子节点则会引用父节点。也就是说,JavaScript代码中引用整个表的单元格会使得整个表留在内存中。在保存对DOM元素的引用时,要仔细考虑这个问题。
在SessionStack,我们编写代码的时候一直遵循着这些最佳实践,并对处理内存分配十分谨慎,因为:
一旦将SessionStack集成到你web应用程序中,它就会开始记录所有的内容,包括:所有DOM的更改、用户交互、JavaScript异常、堆栈跟踪、失败的网络请求、调试消息等等。通过使用SessionStack,你可以将web应用程序中的问题作为视频进行回放,并查看发生在用户身上的所有内容。所有这些都必须在对web应用程序性能没有影响的情况下进行。
由于用户可以重新加载页面或浏览web应用,所以你必须正确处理所有的监视器、拦截器、变量分配等等,这样,才不会出现任何形式的内存泄漏,也不会增加所集成的web应用的内存占用。
我们有一个免费的试用体验,你可以试一试。
参考资源
http://www-bcf.usc.edu/~dkempe/CS104/08-29.pdf
https://blog.meteor.com/an-interesting-kind-of-javascript-memory-leak-8b47d2e7f156
http://www.nodesimplified.com/2017/08/javascript-memory-management-and.html
原文:How JavaScript works: memory management + how to handle 4 common memory leaks
作者:Alexander Zlatkov
译者:雁惊寒
长按识别二维码享更多精彩




