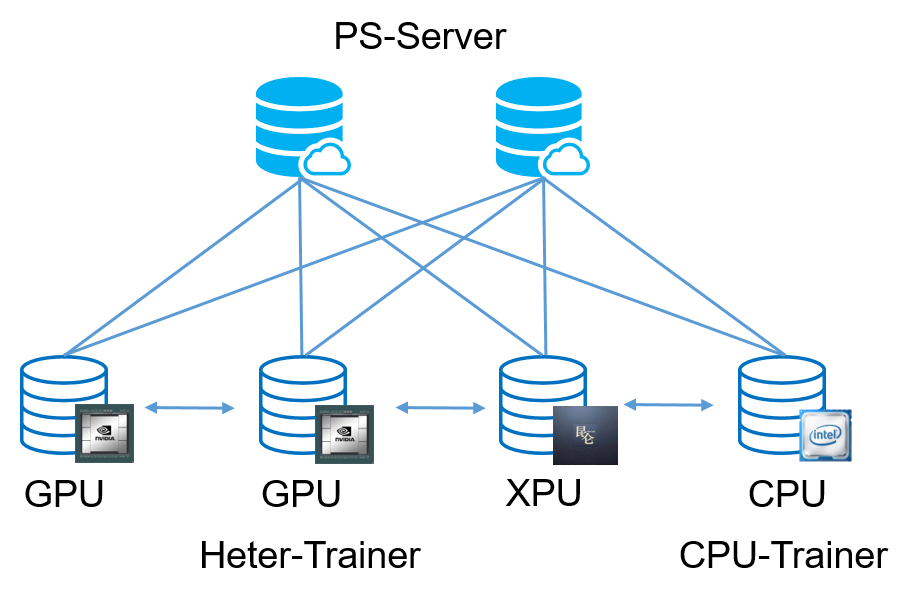
飞桨框架 2.0 版本基于工业实践,创新性地推出了大规模稀疏异构参数服务器功能。
眼看着就要到「双 11」就要到了,对于广大网购爱好者来说那绝对是不可错过的狂欢时刻!当今网购之所以如此火爆,不仅仅是营销策划的作用,智能化的搜索推荐技术也可以说是功不可没。它能把你日思夜想或者潜意识中动过购买念头的商品通通推送到你的面前,甚至会让人有一种冥冥自有天意、不买对不起上苍的感觉。而这背后往往都会有深度学习领域中个性化推荐模型发挥着威力。为了能够更准确的预知用户的内心需求,快速训练出效果良好的推荐模型并尽快部署上线,成为了各大网购业务相关企业的共同追求。
![]()
在搜索推荐领域中,通常推荐模型的网络并不复杂,但是由于对应的特征空间大,所以通常会使用算力要求不高但是规模非常庞大的 Embedding 和 FC 层来将用户及商品的高维稀疏特征向量转化为低维的稠密特征向量,导致这类模型的参数维度可以达到千亿甚至万亿级别,并且还伴随着大规模稀疏的特点。同时各个企业为了模型效果,往往会使用尽可能多的数据来训练模型,尤其是其中的点击数据,如果来自一些带有「选择困难症」的人,可能会非常的长,导致数据规模愈加庞大,甚至可以达到亿级。因此,相比 CV 和 NLP 领域而言,在搜索推荐场景中,单次 Batch 训练中前后向计算的时间远低于数据读取、拉取和更新参数等过程的时间,再加上庞大的数据和参数量,导致内存要求很高,甚至可以达到几十 T,而拥有这类特点的训练任务通常都被称为 IO 密集型训练任务。
单机训练肯定无法承受这样的任务,只有分布式训练才是解决问题的方法。简单来说,分布式训练就是使用多个硬件设备共同完成训练任务,可以分为 All-Reduce Collective 和 Parameter Server (参数服务器)两种训练架构。
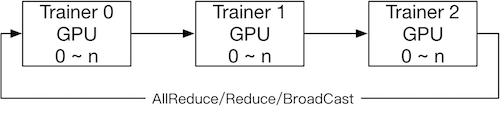
在 Collective 架构中,集群中存在多个地位平等的 Trainer(也可以叫 Worker)。在数据并行的方式下,每个 Trainer 上都保存一份完整的模型网络结构和模型参数,在前向和反向计算过程中,每个 Trainer 使用自己划分的数据(shard)进行计算,得到对应的梯度;然后 Trainer 之间通过 All-Reduce 等通信方式同步梯度到所有 Trainer,最后每个 Trainer 使用同步后的梯度独立完成参数更新。
![]()
由于推荐搜索领域模型的 Embedding 层规模庞大以及训练数据样本长度不固定等原因,导致容易出现显存不足和卡间同步时间耗费等问题,所以 Collective 架构很少被用于搜索推荐领域。
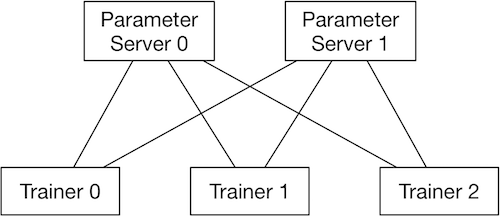
再来看看参数服务器架构。与 Collective 相比,参数服务器架构中除了 Trainer 之外还有一个角色叫 Server。在执行前向与反向计算过程中,Server 负责从各个 Trainer 收集汇总梯度,然后使用这些梯度信息计算更新参数,并向各个 Trainer 分发更新后的参数信息。
![]()
但是在应对 IO 密集型任务时,传统参数服务器模式会出现以下问题:
![]()
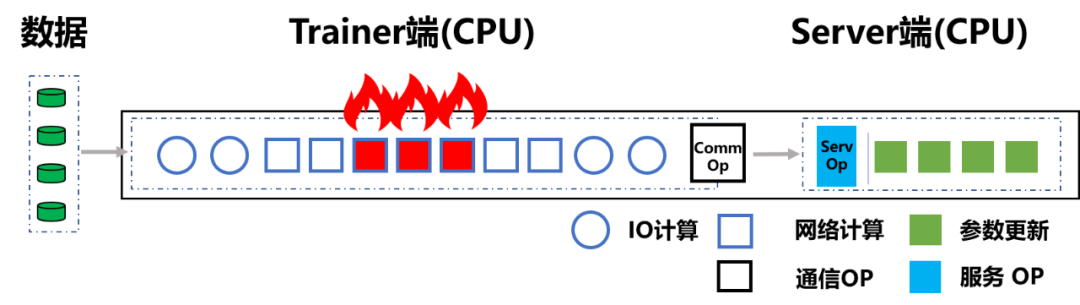
图 3:传统参数服务器架构(CPU 机器)遇到算力瓶颈
资源利用率低:IO 密集型任务主要还是数据读取和模型读取 (IO) 的性能对训练速度更具决定性。在这方面使用 GPU 的集群如同「杀鸡用牛刀」,并不会对整体的训练速度产生多少帮助,而且硬件资源得不到充分利用。而如果加大 Batchsize 提高单次前向后向计算占比,也会受到单机 IO 吞吐能力的制约,而且由于模型高度稀疏,模型效果也会受到影响。
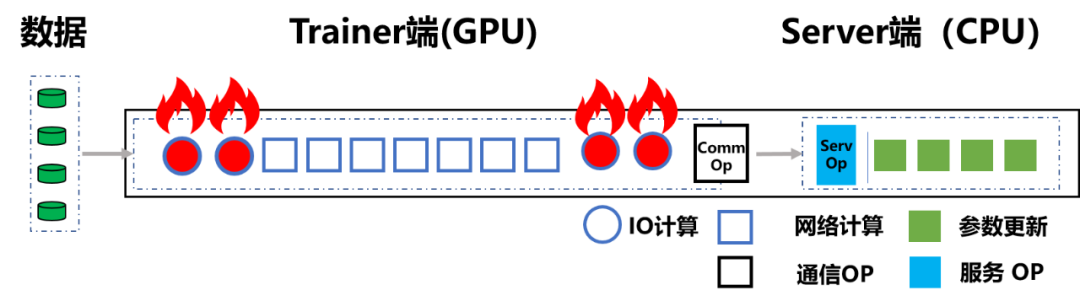
网络带宽不足:由于一台 GPU 机器可以顶替多台 CPU 机器,必然会导致整个集群网卡数量降低。这样在将数据和模型下载到 Trainer 阶段就很容易出现带宽瓶颈。尤其是当 Server 和 Trainer 都在一台设备时,一旦每个 Trainer 划分的训练数据过大,训练准备阶段就会变得极为耗时,整个训练过程直接输在了起跑线上。
![]()
图 4:传统参数服务器架构(GPU 机器)遇到 IO 瓶颈
那么有没有可以高效调整机器配比,快速支持新硬件的接入,使用 GPU 等高算力的同时还不用担心 IO 瓶颈的方法呢?
上面的要求好像很多,其实核心问题就在于硬件的配置,传统的参数服务器对硬件的统一性要求太严格,而现实是单一「兵种」是无法应对大部分「战场」的。如果能同时使用不同的硬件同时参与到训练中,让它们各司其职,发挥各自优势,很多问题就可以迎刃而解了!
为了应对上述问题,飞桨框架 2.0 版本基于工业实践,创新性地推出了大规模稀疏异构参数服务器功能
,一举解除了传统参数服务器模式必须严格使用同一种硬件型号 Trainer 节点的枷锁,使训练任务对硬件型号不敏感,即可以同时使用不同的硬件进行混合异构训练,如 CPU、AI 专用芯片(如百度昆仑 XPU)以及不同型号的 GPU 如 V100、P40、K40 等。同时还可以解决大规模稀疏特征模型训练场景下,IO 占比过高导致的芯片资源利用率过低的问题。通过异构参数服务器训练架构,用户可以在硬件异构集群中部署分布式训练任务,例如云服务器集群,实现对不同算力的芯片高效利用,为用户提供更高吞吐、更低资源消耗的训练能力。
![]()
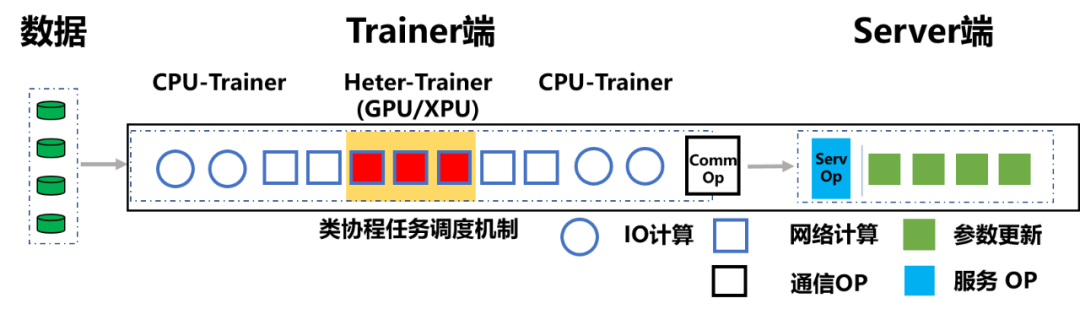
如之前所述,在传统参数服务器模式下,前向及反向步骤在 Trainer 端完成,参数更新在 Server 端完成。而
在异构参数服务器架构中
,原先那样粗粒度的任务分工显然不再适用,只有让不同硬件参加到训练任务中,并在自己最擅长的领域工作,才能各显神通。因此飞桨的研发人员在传统的 CPU-Trainer 之外,又部署了一类 Heter-Trainer,并在 Heter-Trainer 上配置有 Service。这样 CPU-Trainer 便将 Heter-Trainer 视为特殊的 Server,从而对 Heter-Trainer 的异构算力不敏感,使 Heter-Trainer 可以混部各类不同型号芯片(例如 GPU 或 XPU 等)。
为了让 CPU-Trainer 和 Heter-Trainer 完成不同类型的任务,飞桨将整个计算任务做了进一步的拆分。CPU-Trainer 继续负责数据读取、参数的读取和更新、参数的网络传输等 IO 任务,甚至在小 BatchSize 训练时,使用 CPU 处理更快的网络层计算;而对于复杂网络的计算,则 CPU-Trainer 会交给 Heter-Trainer 处理。总之,所有 CPU 相对 GPU 或 XPU 更擅长处理的操作都放在 CPU 中,其它的放在 GPU 或 XPU 中。
![]()
值得注意的是,异构参数服务器架构并不只是简单的将计算任务拆分。拆分后,异构硬件间的通信代价高的问题也需要解决。为了解决这个问题,飞桨的整个传输通信过程得到了优化。该过程将不会完全依赖于硬件自身的吞吐,而是引入类协程任务调度机制,该机制采用了异步等待和多 Queue 流水线等方式对任务进行灵活调度,避免传输队列阻塞,对任务进行灵活调度,并且还优化了 Heter-Trainer 的吞吐机制,高效的避免传输队列阻塞。
此外,异构参数服务器训练架构在各个硬件设备上还引入了异构存储机制,将模型训练所用到的参数,按照一定层级分别存储到 SSD、内存和显存中,并且支持参数在 SSD、内存、显存之间的快速拷贝,使模型规模不再受限于内存或显存的规格,可以进一步支持更大参数规模的模型训练。
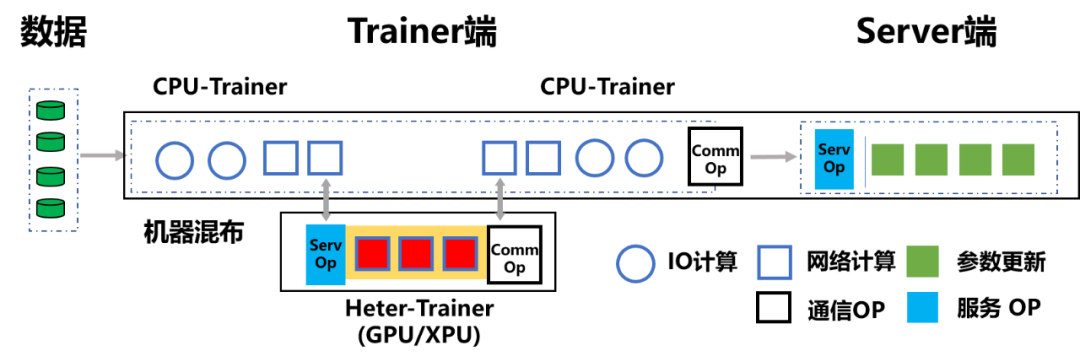
如果用户希望将现有 GPU 机器上的传统参数服务器架构改造为异构参数服务器架构,则用户可以通过飞桨从机器上划分出部分 CPU 资源形成 CPU-Trainer,然后再将原有的 GPU-Trainer 改造为 Heter-Trainer。但是通常在此场景下, CPU-Trainer 所能处理的数据,仅需要使用少量 GPU 资源组成的 Heter-Trainer 处理,便足以完成训练计算任务,从而可以节省大量的 GPU 资源。
而对于将 CPU 机器上的传统参数服务器架构改造为异构参数服务器架构的需求,飞桨可以支持用户根据任务所需的实际算力灵活引入异构硬件(GPU 或 XPU)成为 Heter-Trainer,这样不仅可以保障资源的利用率,而且可以利用用户手中的旧型号硬件机器,大大节约用户的成本。这一特点也使异构参数服务器架构非常适合部署在云上异构集群场景中。
![]()
图 7:传统参数服务器架构的异构改造(外挂硬件,CPU 机器为例)
飞桨的异构参数服务器架构不仅可以支持 CPU 机器、GPU 机器和 XPU 机器的混合模式,而且支持全部 CPU-Trainer 或 GPU-Trainer 的那样的传统参数服务器的硬件组合,甚至在 GPU 单类型机器的集群内采用 Heter 模式,可以达到训练提速的效果。
异构参数服务器兼顾了传统参数服务器架构的大规模稀疏及异步优势,充分利用了 GPU 等 AI 芯片带来的算力上的提升,在模型训练速度上显著提升。
使用 4 台 GPU 机器作 Trainer 的 Collective 架构(Collective-GPU)。
使用 4 台 CPU 机器作 Trainer 的非异构参数服务器架构(PS-CPU)。
使用 4 台 GPU 机器作 Trainer 的非异构参数服务器架构(PS-GPU)。
使用 4 台 CPU 机器和若干 GPU 机器作 Trainer 的异构参数服务器架构(PS-Heter)。
其中 CPU 机器型号为 Intel(R) Xeon(R) Gold 6148,GPU 机器型号为 Intel(R) Xeon(R) Gold 6148+Tesla V100 32G。
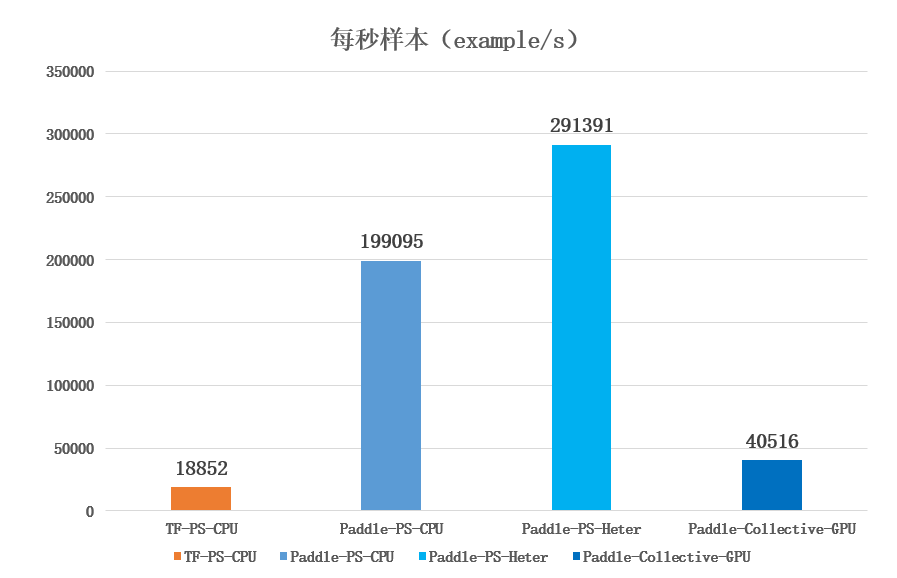
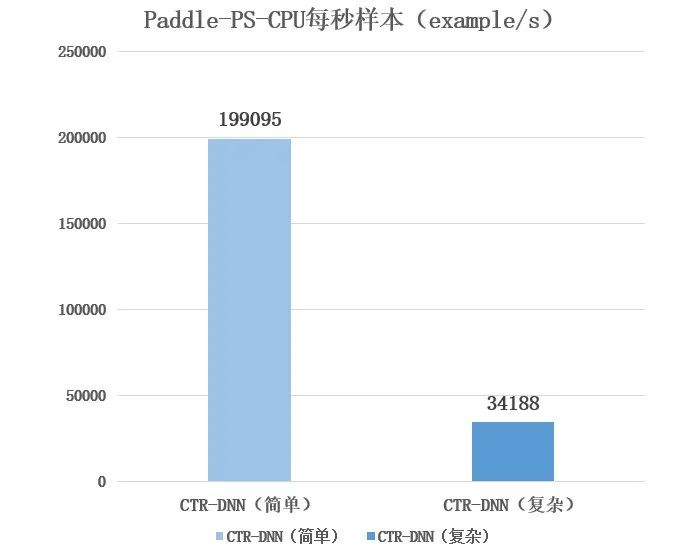
首先我们在简单的 CTR-DNN 模型(FC 层维度分别为「400->400->400->2」)和 Criteo 数据集进行测试,模拟简单 IO 密集型训练任务。如下图所示,我们可以看到对于简单模型,飞桨异构参数服务器架构(PS-Heter,4 CPU+1GPU)性能表现优于其它训练架构。
![]()
当我们扩大 FC 层维度(FC 层维度分别为「4096->2048->1024->2」),模拟复杂网络时的 IO 密集型训练任务,如下图所示,可以看到 PS-CPU 架构的性能下降显著。
![]()
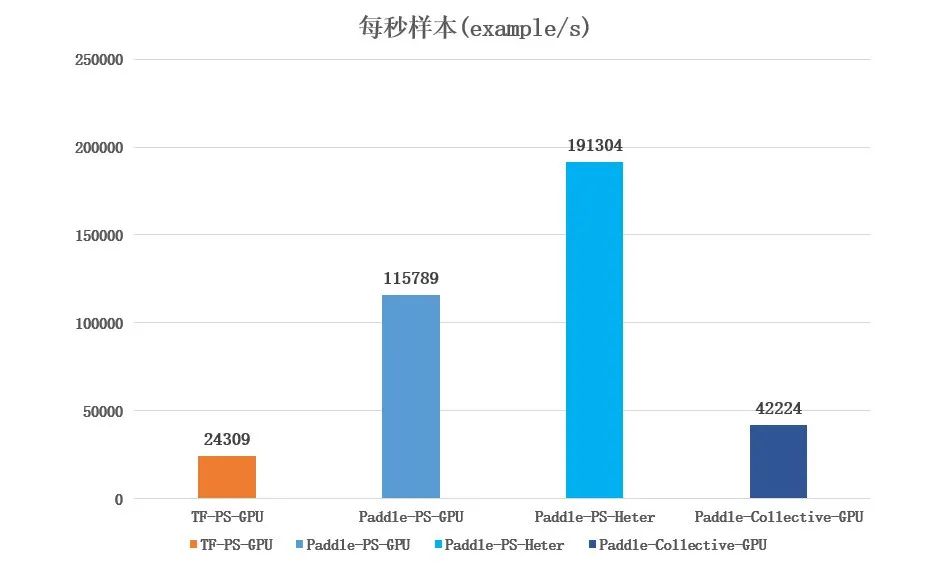
然后改为使用 GPU 的架构进行测试,且统一使用 4 台 GPU 机器,可以看到常用于复杂网络计算的 Collective-GPU 架构的表现一般,都远不如 PS-GPU 和 PS-Heter(4CPU+4GPU)架构,而其中 PS-Heter 性能依然保持着优异的性能。
![]()
此外,在一些真实业务模型上使用单台 GPU / 昆仑芯片机器 + 10 台 CPU 机器,可以完成千万数据千亿参数点击率模型的分钟级训练。
为了能让广大用户快速上手异构参数服务器训练架构,飞桨在操作方面做的也比较简单,不仅配有成熟的脚本么,并且仅需要补充简单的几行代码,就可以将传统参数服务器训练架构修改为异构参数服务器架构。
本示例需要运行在 Linux 环境下,Python 版本不低于 2.7,且飞桨开源框架版本为最新分支版本(Develop 版本)。具体操作步骤如下所示:
执行脚本 sh download_data.sh,系统会从国内源的服务器上下载 Criteo 数据集,并解压到指定文件夹。
全量训练数据放置于./train_data_full/;
全量测试数据放置于./test_data_full/;
用于快速验证的训练数据与测试数据放置于./train_data / 与./test_data/
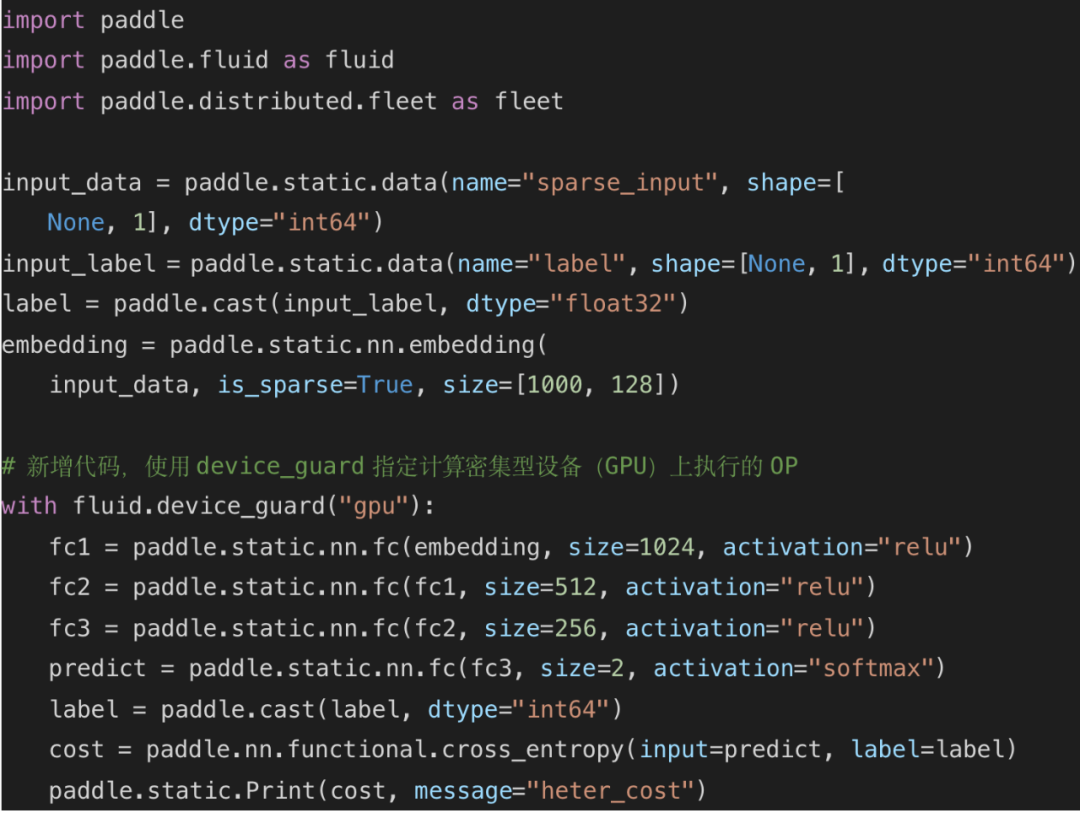
2. 构建一个三层的 CTR-DNN 网络,并将其中需要算力的网络层配置给 GPU 处理。
![]()
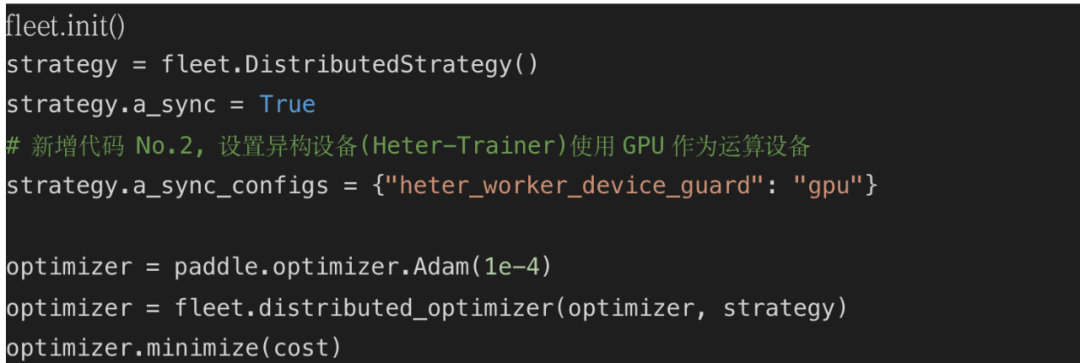
3. 调用 Paddle 分布式 Fleet API,添加运行策略,设置异构设备 (Heter-Trainer) 使用 GPU 作为运算设备,然后完成反向组网。
![]()
1) 启动 Server 与 Heter-Trainer。
![]()
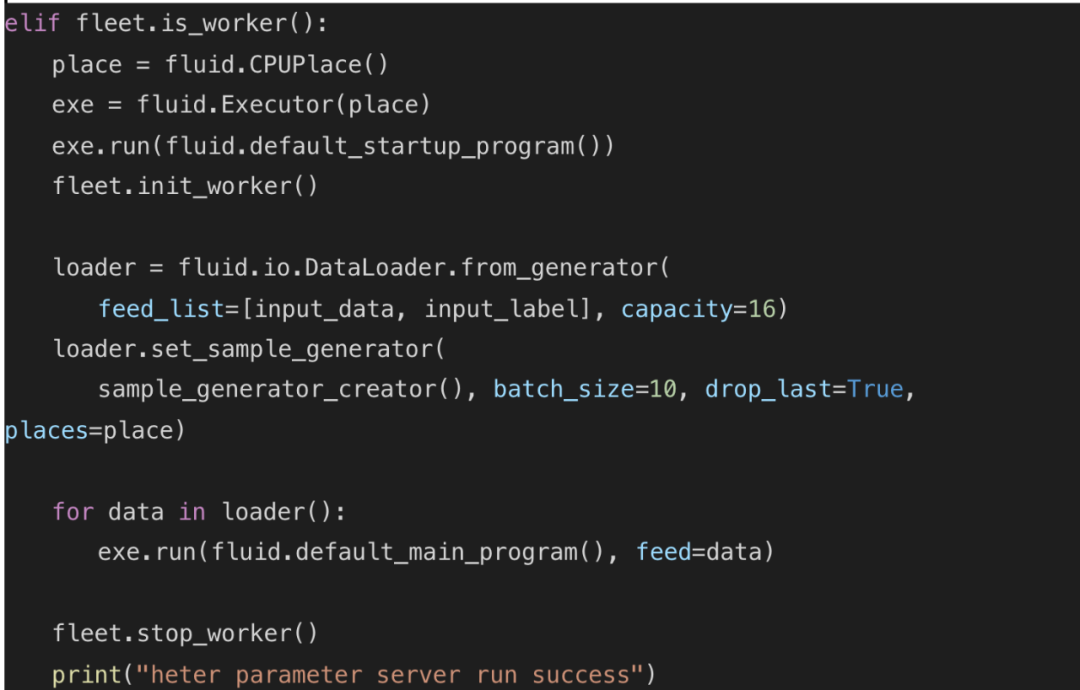
2) 启动 CPU-Trainer,执行数据 IO 及总体训练流程控制。
![]()
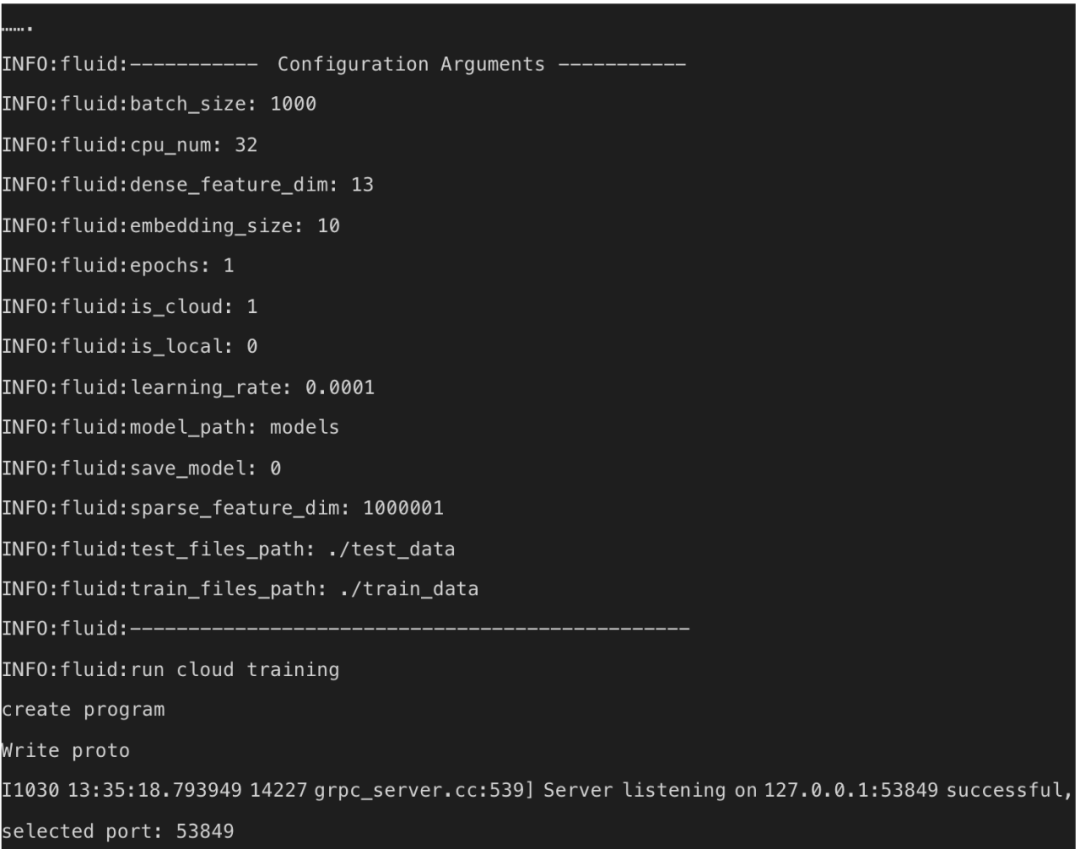
飞桨对分布式训练的启动代码进行了易用性封装,使用 fleetrun 命令即可快速启动分布式训练:
![]()
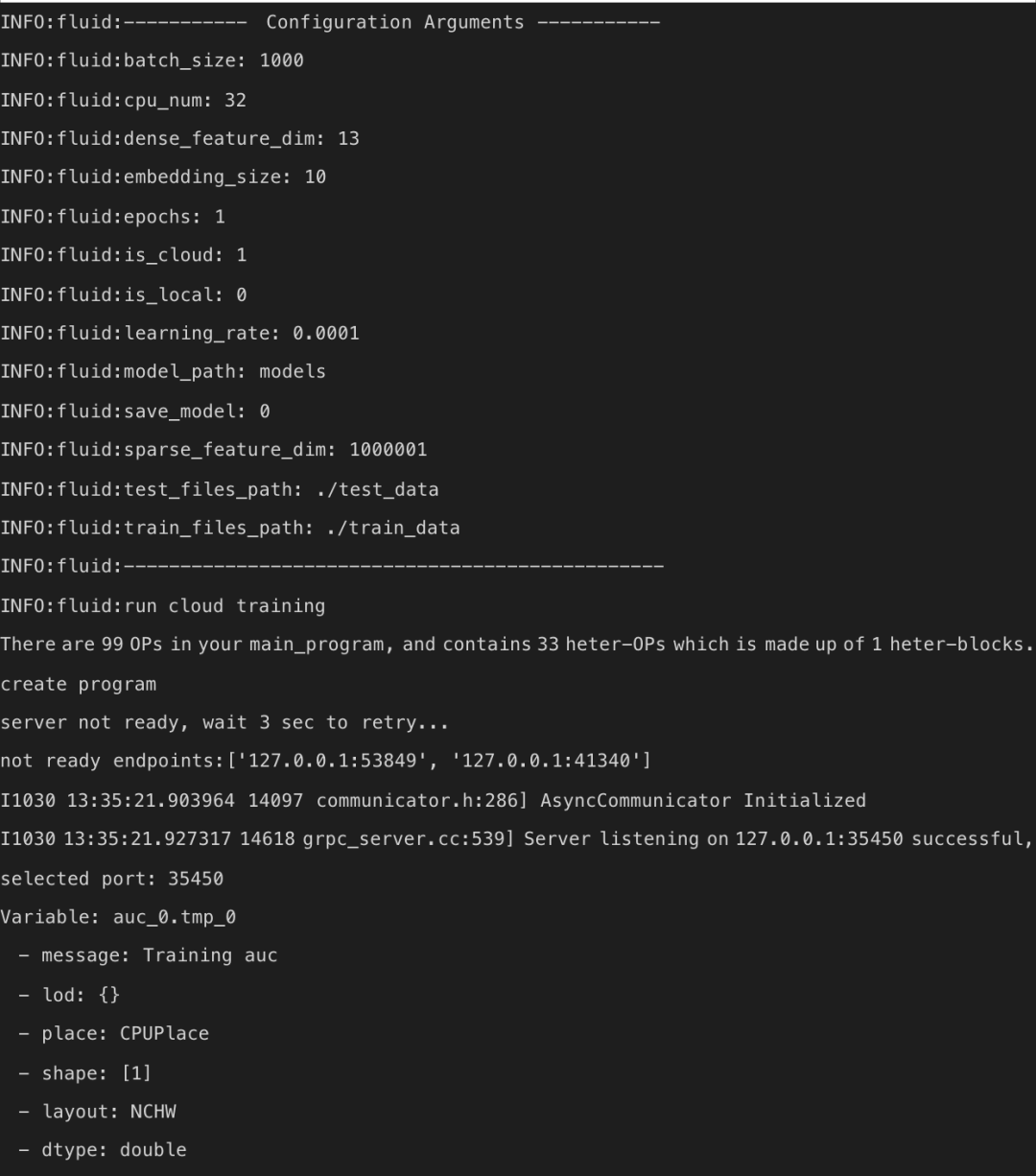
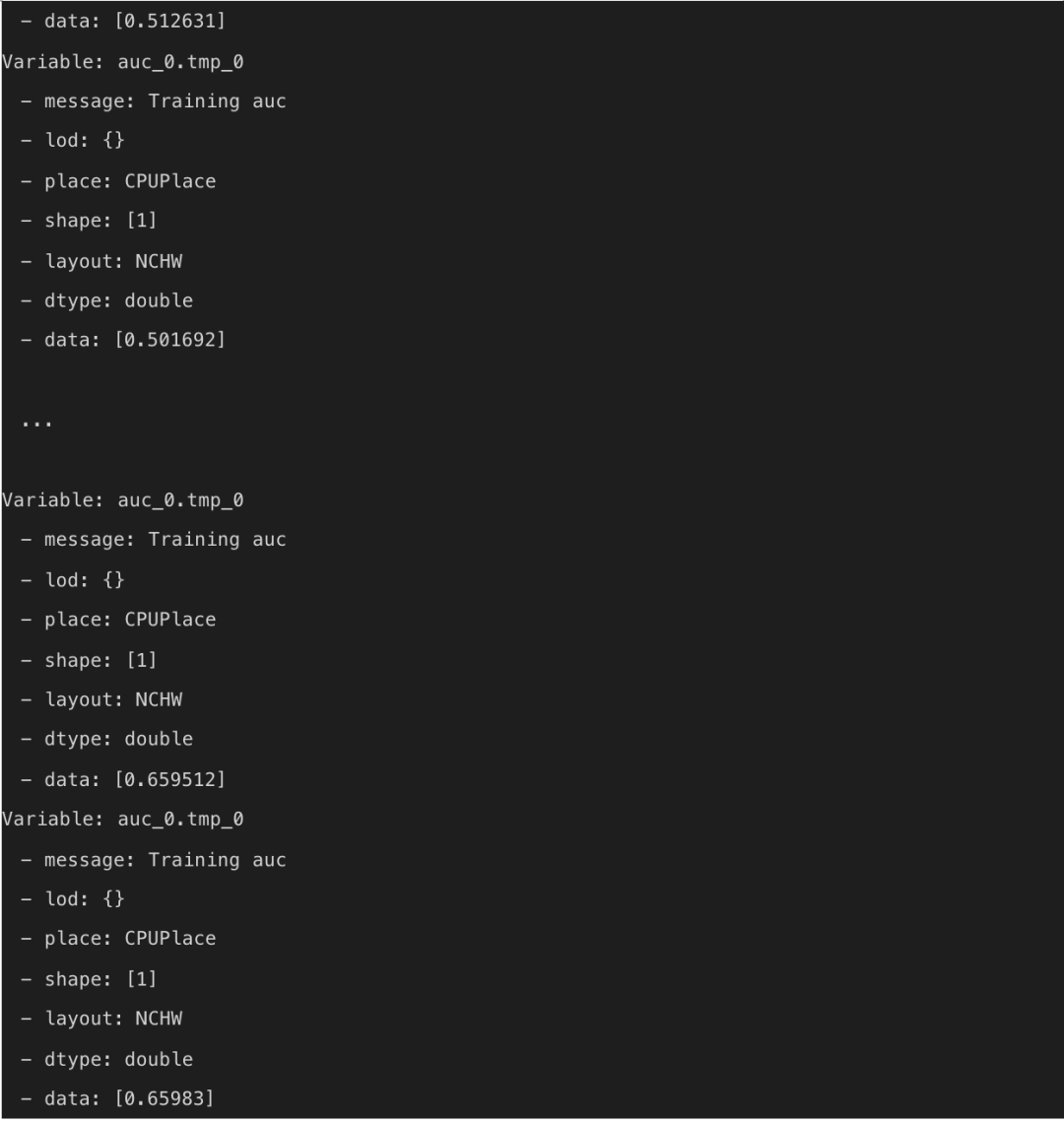
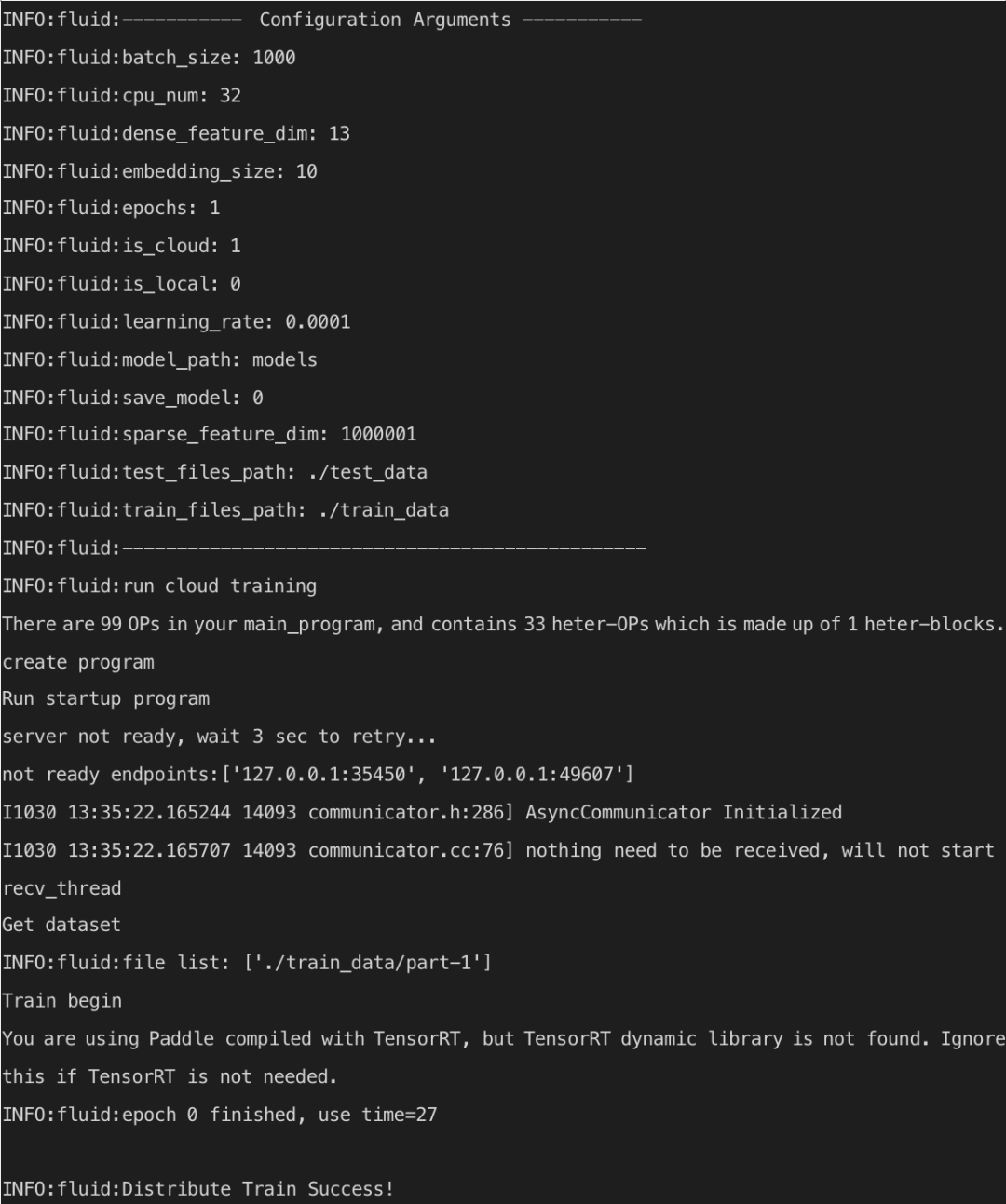
当训练结束后可以看到任务成功的显示信息,如下所示。
![]()
![]()
![]()
![]()
由百度深度学习工程师精心打造的 4 节系列直播课,11 月 9 日、10 日、12 日、13 日每天晚上 19 点
,让你快速:
了解深度学习框架的前沿进展,理解动态图的开发模式及其优势;
掌握用更少,更简洁的代码完成深度学习的经典任务;
通过图片相似度案例掌握产业应用广泛的经典双塔网络结构;
通过机器翻译案例掌握自然语言处理领域的经典 LSTM 网络结构。
掌握深度学习先人一步,扫描海报上的二维码,并回复:【
直播
】,即可加入交流群与更多深度学习大佬交流~
![]()
如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
https://www.paddlepaddle.org.cn/
飞桨 (PaddlePaddle) 以百度多年的深度学习技术研究和业务应用为基础,是中国首个开源开放、技术领先、功能完备的产业级深度学习平台,包括飞桨开源平台和飞桨企业版。飞桨开源平台包含核心框架、基础模型库、端到端开发套件与工具组件,持续开源核心能力,为产业、学术、科研创新提供基础底座。飞桨企业版基于飞桨开源平台,针对企业级需求增强了相应特性,包含零门槛 AI 开发平台 EasyDL 和全功能 AI 开发平台 BML。EasyDL 主要面向中小企业,提供零门槛、预置丰富网络和模型、便捷高效的开发平台;BML 是为大型企业提供的功能全面、可灵活定制和被深度集成的开发平台。
本文为机器之心发布,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com