谷歌提出新方法:基于单目视频的无监督深度学习结构化

更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
感知场景的深度是自主机器人的一项重要任务:准确估计物体离机器人的距离的能力对于躲避障碍、安全规划和导航至关重要。虽然可以从传感器数据(例如 LIDAR)中获得(和学习)深度,但是也可以用无监督的方式从单目相机中学习场景深度,这取决于机器人的运动以及由此产生的场景的不同视图。这种方式还学习了“自运动(egomotion)”(机器人或摄像机在两帧之间的运动),同时提供了机器人自身的定位。
虽然这种方法具有较长的历史(运动结构和多视图几何学),但是新的基于学习的技术,具体来说是通过深层神经网络对场景深度和自运动的无监督学习,已经推进了该领域技术的发展。其中包括 Zhou 等人的工作(Unsupervised Learning of Depth and Ego-Motion from Video),以及我们之前在训练中对场景的 3D 点云进行对齐的研究(Depth Prediction Without the Sensors: Leveraging Structure for Unsupervised Learning from Monocular Videos)。
尽管目前已经有这些成果,学习预测场景深度和自运动仍然是一个持续的挑战,尤其是在处理高动态的场景和估计运动物体的深度情况下。由于以往对无监督单目学习的研究没有对运动对象进行建模,因此会导致对对象深度的连续错误估计,常常会将其深度映射到无穷大。
在我们发表在 AAAI-2019 的论文 Depth Prediction Without the Sensors: Leveraging Structure for Unsupervised Learning from Monocular Videos (无传感器深度预测:利用结构信息完成基于单目视频的无监督学习)中,我们提出了一种新的方法,它能够对运动对象进行建模,并且给出高质量的场景深度估计结果。
与其它单目视频的无监督学习方法相比,我们的方法能够恢复运动物体的正确场景深度。在本文中,我们还提出了一种 无缝的在线优化技术,可以进一步提高质量,并应用于跨数据集的迁移。此外,为了鼓励大家提出更好的机载机器人学习方法,我们开源了论文的 TensorFlow 代码 (https://github.com/tensorflow/models/tree/master/research/struct2depth) 。

图 1 之前的工作(中间行)不能正确估计运动目标,而把他们的深度映射为无限远(热度图中深蓝色部分)。而我们的方法则提供了更好的深度估计。
我们方法的一个关键思想是在学习框架中引入结构信息。也就是说,我们不是直接依靠 神经网络来学习场景深度,而是将单目场景看作由移动物体(包括机器人本身)组成的 3D 场景。我们将各个运动建模为场景中的独立变换——旋转和平移,然后将其用于建模 3D 几何并估计所有物体的运动。此外,知道哪些对象有潜在可能会移动(例如,汽车、人、自行车等)能够帮助我们学习它们单独的运动矢量,即使它们可能是静态的。通过将场景分解为 3D 和单独的对象,可以更好地学习场景中的深度和自运动,尤其是在高度动态的场景中。
我们在 KITTI 和 CITYSCAPE 城市驾驶数据集上测试了该方法。我们发现它的表现优于目前最先进的方法,并且与使用立体成对视频作为监督的方法的表现接近。重要的是,我们能够正确地恢复与自运动车辆速度相同的汽车的场景深度。这在以前是相当具有挑战性的,在这种情况下,移动车辆(单目输入)呈现静态,表现出与静止的地平线相同的行为,导致算法将其推断为无限深度。虽然立体视频输入可以 解决 这一问题,但是我们首次提出了能够从单目输入中进行正确推断的方法。

图 2 之前用单目视频作为输入的工作不能提取运动物体,并且错误地将它们映射到无限深度。
此外,由于在我们的方法中对象是单独处理的,所以该算法能够为每个对象提供单独的运动矢量,即对它运动方向的估计:

图 3 动态场景下深度估计结果与独立车辆的移动矢量估计示例
除了上述结果,这项研究还证明了进一步探索无监督学习方法所具有的潜力,因为单目输入比立体或 LIDAR 传感器更便宜,更容易部署。如下图所示,在 KITTI 和 Cityscapes 数据集中,监控传感器(无论是立体还是 LIDAR)都有丢失值,并且有时可能由于时间延迟无法与相机输入对准。

图 4 KITTI 数据集单目视频深度预测(中间行),与 Lidar 传感器的真实值对比,后者没有覆盖全部场景,并且有丢失值和噪声值。真实深度值在训练中没有使用。
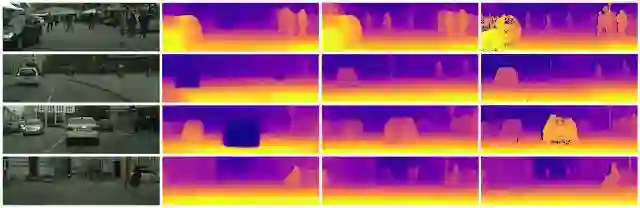
图 5 Cityscapes 数据集的深度预测结果。从左到右分别是:图像、基线、我们的方法和立体视频提供的真实值。请注意立体真实值中的丢失值。而且我们的算法能在没有任何真实值深度信息的监督的情况下达到这样的效果。
我们的结果还提供了最先进的自运动估计,这对于自主机器人来说至关重要,因为它提供了机器人在场景中移动时的定位。下面的视频(由于微信限制,此处动图无法上传,可以查阅原文看原图)给出了我们方法的结果,我们对推断的自运动中获得的速度和转角进行了可视化。虽然深度和自运动的输出是标量,我们可以看到,当减速或停止时,它能够估计它的相对速度。

图 6 深度和自运动预测。从速度和转角指示中可以看出车辆转弯和红灯停下时的估计值。
学习算法的一个重要特征是移动到未知环境时的适应性。在该工作中,我们进一步介绍了在线优化方法,该方法在收集新数据的同时继续进行在线学习。以下是在 Cityscape 上训练,然后在 KITTI 上进行在线优化之后,估计深度质量提升的示例。

7 在线优化效果示意图。在 Cityscapes 数据集上进行训练,而在 KITTI 数据集上进行测试。图像显示了训练模型和经过在线优化的训练模型给出的深度预测。经过在线优化的模型能够更好地描绘场景中目标的轮廓。
我们进一步在与训练集有很大不同的数据集上测试,即在由 Fetch 机器人 收集的室内数据集上测试,而训练是在室外城市驾驶 Cityscape 数据集上进行的。这些数据集之间存在很大的差异。即使如此,我们发现在线学习技术能够获得比基线更好的深度估计。

图 8 在线自适应的结果:当模型从 Cityscapes(室外驾驶数据集)迁移到由 Fetch 机器人收集的室内数据。最底行显示了应用在线优化后深度预测结果的提升。
综上所述,这项工作致力于从单目相机中进行场景深度和自运动的无监督学习,并解决高度动态场景中的问题。结果显示,该方法获得了高质量的场景深度和自运动预测结果,与立体视频有类似的表现。并且我们提出了在学习过程中结合结构的思想。
更值得注意的是,我们提出的仅从单目视频中无监督学习场景深度和自运动预测与在线适应结合寓示了一个强大的想法,因为它不仅能够以无监督的方式从简单的视频中学习,而且还可以非常容易地迁移到其他数据集上。
查看英文原文:
http://ai.googleblog.com/2018/11/a-structured-approach-to-unsupervised.html

如果你喜欢这篇文章,或希望看到更多类似优质报道,记得给我留言和点赞哦!


