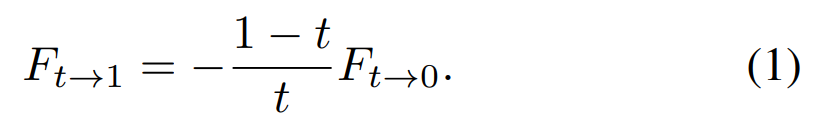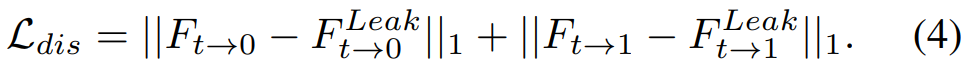在视频处理中,视频帧插值技术已经得到了广泛的应用。然而,传统的基于流的视频帧插值算法并不完美,有时不仅速度较慢,还会产生较多的伪影。针对这些问题,在本文中,来自旷视科技和北京大学的研究者进行了改进,提出了一种高效的实时中间流估计算法,不仅运行速度实现了数倍甚至数十倍的提升,而且伪影也较以往方法少得多。
视频帧插值(VFI)是当前视频处理中的一种常见方法,广泛用于提高帧速率和增强视觉质量,它支持各种应用,例如慢动作合成、视频压缩和用于动态视频去模糊的训练数据生成。此外,在实时速度下,高分辨率视频(如 720p、1080p)上,视频帧插值算法还有许多潜在的应用。
由于现实世界中存在复杂、大量的非线性运动和光照变化,因此视频帧插值方面还有一些挑战性问题存在。基于流的视频帧插值算法最近提供了解决这些挑战的框架,并且取得了出色的结果。根据如何 warp 输入帧,基于流的视频帧插值算法可以分为前向 warp 和后向 warp 方法,但这些方法基本上都有过于复杂沉重和缺少对近似中间流的直接监督等缺点。
大多数现有方法首先估算双向光流,然后将它们线性组合成近似中间流,从而会导致运动边界周围出现伪影。在一篇论文中,旷视科技和北京大学的研究者为视频帧插值(VFI)提出了一种实时中间流估计算法(real-time intermediate flow estimation, RIFE)。
![]()
研究者设计了一个名为 IFNet 的中间流模型,该模型可以直接估计从多到少的中间流。然后根据估计的中间流对输入帧进行 warp,并采用融合过程来计算最终结果。基于该研究提出的 leakage distillation 技术,RIFE 能够进行端到端训练并获得出色的性能。实验表明,RIFE 比现有基于流的视频帧插值方法要快得多,并且在多个基准上达到 SOTA。
对于这种实时中间流估计算法,网友对其效果大加赞赏,并表示:「这种算法同样适用于游戏,很快老旧的 PS2 也能玩 4K 游戏了。」
![]()
![]()
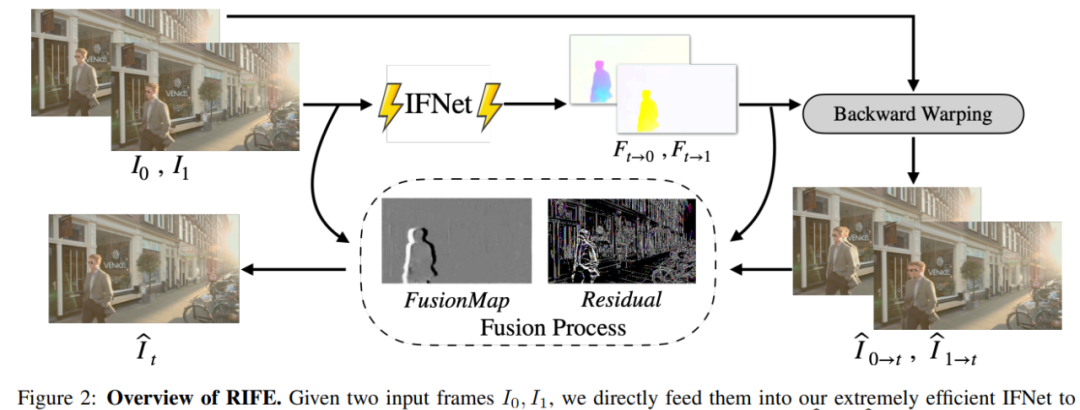
RIFE 包含两个主要组件,分别是利用 IFNet 进行高效的中间流估计和使用 FusionNet 时 warp 帧的融合过程。RIFE 的整体结构如下图 2 所示:
![]()
具体而言,给定一对连续的 RGB 帧 I_0 和 I_1,研究者的目标是在时间 t∈ (0, 1) 时合成中间帧 ^I_t。首先,通过将输入帧馈入 IFNet,该算法直接估计中间流 F_t→0,然后使用线性运动假设近似 F_t→1:
![]()
其次,研究者通过输入帧的后向 warp(backword warping)可以得到两个粗略结果 ^I_0→t 和 ^I_1→t 。此外,为了消除 warp 帧中的伪影,研究者利用一种类似于 FusionNet 的编码器 - 解码器架构将输入帧、近似流和 warp 帧馈入融合过程,以生成插值帧。
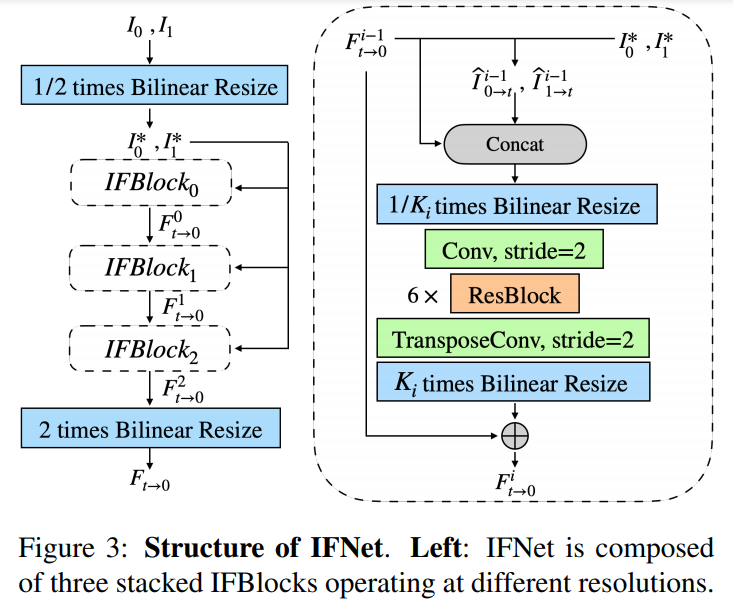
IFNet 的结构如下图 3 所示。IFNet 的作用是在给定两个连续输入帧 I_0 和 I_1 的情况下直接且高效地预测出 F_t→0。
![]()
在下图 4 中,研究者提供了 IFNet 的视觉效果,并与预训练 LiteFlowNet 生成的线性组合双向光流进行了比较。结果表明,IFNet 生成了清晰的运动边界,而线性组合流出现了像素重叠和模糊的运动边界。
![]()
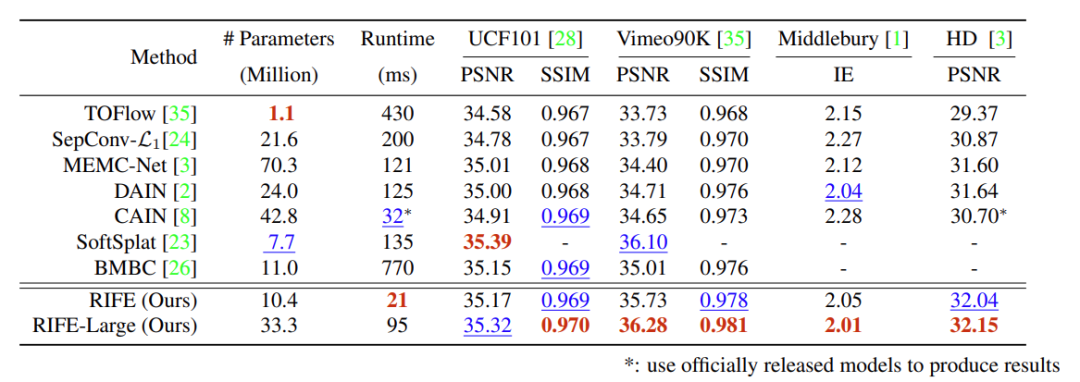
如下表 1 所示,研究者将 IFNet 与当前的 SOTA 光流估计网络的运行时进行了比较。目前基于流的模型通过需要运行两次才能得到双向流,而本研究中间流估计过程的运行速度较以往方法缩短了 6 至 30 倍。因此 IFNet 为开发实时流 VFI 算法提供了可能。
![]()
融合过程包含一个语境提取器和一个具有类 U-Net 的编码器 - 解码器架构的 FusionNet。其中,语境提取器和 FusionNet 中的编码器部分具有相似的架构,都包含 4 个步幅为 2 的 ResNet 块。FusionNet 中的解码器部分具有 4 个转置卷积层。研究者使用 sigmoid 函数来限制 FusionNet 的输出。
IFNet 的 leakage distillation
由于无法获取中间图像并缺少监督,中间流难以进行直接近似。为了解决这个问题,研究者在 IFNet 中添加了一个 leakage distillation 损失,其目的是为了预测出一个能够获取中间帧的 overpowered 教师网络。这个 leakage distillation 损失的定义如下:
![]()
如以往研究一样,IFNet 利用迭代更新流程生成了最终流估计,并且研究者将 leakage distillation 损失运用到了整个预测序列中。
在实验部分,研究者选取了以下基准用于方法的评估,包括 Middlebury、UCF101、Vimeo90K 和 HD。研究者在 Vimeo90K 训练集上训练本文提出的模型,然后在上述基准中测试它们。
如下表 2 所示,研究者使用英伟达 TITAN X GPU,按照 640 × 480 的输入分辨率,在多个基准和运行速度的情况下对性能进行了测试。结果显示,基础模型 RIFE 的运行速度快于所有对比方法。此外,RIFE-Large 在多个基准上比之前的 SOTA 方法 SoftSplat 快 30%。
![]()
表 2:在 UCF101、Vimeo90K、Middlebury OTHER 数据集和 HD 基准上的定量对比。红色和蓝色数字分别指的是最佳和次佳的性能。
研究者还在 Vimeo90K 测试集中选取了一段大幅动作的视频剪辑,提供了视觉方面的对比,如下图 5 所示。其中 SepConv-L1 和 DAIN 会产生伪影(ghosting artifact),CAIN 会导致铁铲的部分缺失,总体来说本文方法的生成结果最为可靠。
![]()
图 5:在 Vimeo90K 测试集上的定性对比结果。
![]()
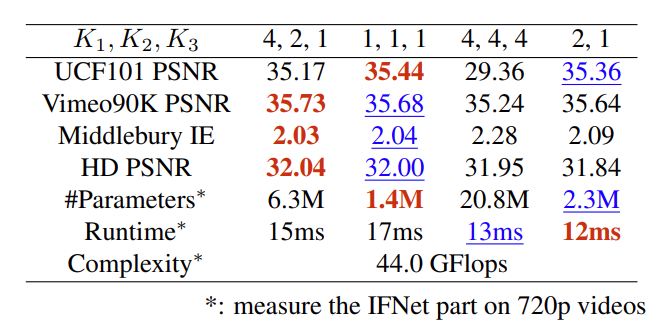
表 4:在 IFBlock 上不同的比例设置。IFNet 采用的是 (4, 2, 1) 设置, (1, 1, 1) 的组合只能在 UCF101 这种分辨率有限(256 × 256)的数据集上获得更好的性能。
![]()
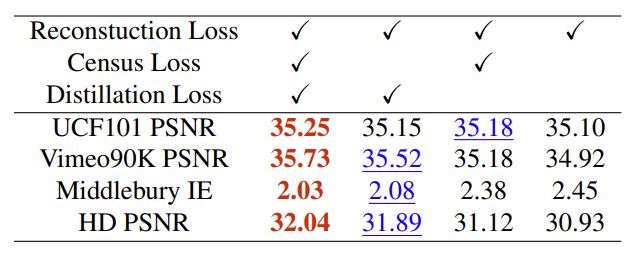
表 5:不同损失函数的设置。去掉 leakage distillation 损失函数会导致性能的大幅下降,特别是在高分辨率基准上。
![]()
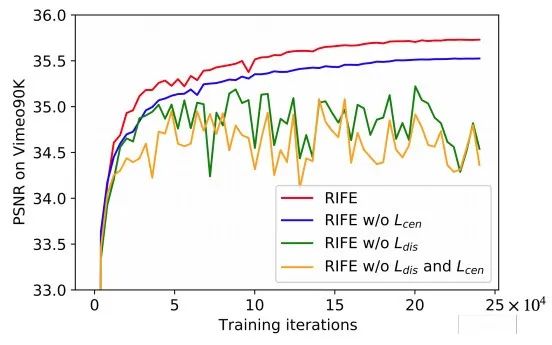
图 7:在 Vimeo90K 测试集上,每 5 个训练时(epoch)对本文所提出的模型进行评估。
为了评估本文模型在多帧生成方面的能力,研究者分别提供了 Vimeo90K 测试集中大幅动作的 2×、4× 和 8× 结果,如下图 6 所示。可以看出来,RIFE 能够生成平滑而连续的运动。
![]()
Amazon SageMaker实战教程(视频回顾)
Amazon SageMaker 是一项完全托管的服务,可以帮助机器学习开发者和数据科学家快速构建、训练和部署模型。Amazon SageMaker 完全消除了机器学习过程中各个步骤的繁重工作,让开发高质量模型变得更加轻松。
10月15日-10月22日,机器之心联合AWS举办3次线上分享,全程回顾如下,复制链接到浏览器即可观看。
另外,我们准备了Amazon SageMaker 1000元服务抵扣券,帮助开发者体验各项功能。点击阅读原文,即可领取。
![]()
第一讲:Amazon SageMaker Studio详解
主要介绍相关组件,如studio、autopilot等,并通过在线演示展示这些核心组件对AI模型开发效率的提升。
-
视频回顾地址:
https://app6ca5octe2206.h5.xiaoeknow.com/v1/course/alive/l_5f715443e4b005221d8ea8e3
第二讲:使用Amazon SageMaker 构建一个情感分析「机器人」
主要介绍情感分析任务背景、进行基于Bert的情感分析模型训练、利用AWS数字资产盘活解决方案进行基于容器的模型部署。
第三讲:DGL图神经网络及其在Amazon SageMaker上的实践
主要介绍图神经网络、DGL在图神经网络中的作用、图神经网络和DGL在欺诈检测中的应用和使用Amazon SageMaker部署和管理图神经网络模型的实时推断。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com