业界 | NovuMind异构智能核心技术引领智联网
机器之心发布
作者:Junko Yoshida
编译:Susan Hong
2017 年 10 月 17 日,EE Times(电子工程专辑)台湾网站中文编译了由国际电子行业权威期刊 EE Times 的主编 Junko Yoshida 采访、撰写的报道,讲述来自硅谷的创业企业 NovuMind(异构智能)在人工智能芯片以及智慧物联网领域的创新突破,并发表在 8 月 31 日 EE Times 网站上。
打造 AI 芯片的终极境界在于达到智慧物联网 (I²oT),即让小型的本地「终端」装置不仅能「看」也能「思考」且认知其所见所闻,而不至于占用数据中心的带宽。NovuMind 创始人吴韧博士提出的「专注于深度学习最基础卷积单元优化」的设计策略是一项革命性的创新,而这个新型芯片的使命就是「高效率地支持无处不在的人工智能」。
NovuMind 是百度前人工智能杰出科学家吴韧博士于 2015 年 8 月在美国加州硅谷成立的 AI 公司,主要为汽车、安防、医疗、金融等领域提供 ASIC 芯片(Application Specific Integrated Circuit),并提供训练模型的全栈式 AI 解决方案。目前团队共有 50 余人,包括在美国的 35 名以及北京的 15 名顶尖技术工程师。
相较于 Nvidia 的绘图处理器 (GPU) 或 Cadence 的数字信号处理器 (DSP) 等通用的深度学习芯片设计,吴韧强调,NovuMind 专注于开发「更有效进行推理 (interference)」的深度学习加速器芯片。
NovuMind 所设计的 AI 芯片仅使用尺寸极小 (3x3) 的卷积核。
在人工智能算法迅猛发展的时代,这种做法似乎有点反常。事实上,很多竞争者因为担心未来 AI 算法会有全新的计算方法,而将眼光放在去设计可编程的通用的芯片。
相形之下,NovuMind 更专注于「不太可能改变的神经网络的核心」这一设计理念。吴博士解释道,5x5 卷积可以通过堆叠较少计算的两个 3x3 过滤器来完成,7x7 可以通过堆叠三个来完成。「那为什么还要大费周章地使用其他过滤器?」
像 DSP 或 GPU 等架构的最大的问题,就是「处理器的利用率很低」。吴韧表示,「NovuMind 则通过使用独特的张量处理架构(tensor processing architecture)直接对三维张量进行处理,根本性地解决了这一效率问题。」
他表示,NovuMind 的设计想法是相当「主动积极的思考」方式,因为它专注于神经网路中的最小卷积组合;同时,新芯片的使命在于让更具功率效率的 AI 嵌入任何应用中。
NovuMind 的第一款 AI 芯片原型预计会在今年圣诞节前推出。吴博士表示,到明年 2 月份,他希望应用程序都准备就绪,并能够在该芯片上实现耗能不超过 5 瓦进行 15 万亿次运算(15 TOPS);而 NovuMind 的第二款芯片,耗能将不超过 1 瓦,计划在 2018 年中期面世。
NovuMind 的新芯片将支持 Tensorflow,Cafe 和 Torch 等主流深度学习框架。
NovuMind 的 AI 芯片的重点在于,不仅让一个小型的本地「终端」设备具有「看」的能力,而且还具备「思考」以及「识别」的能力,另外,这些都不需要通过数据中心的支持,不占用任何带宽。吴博士将之称为智能物联网(I²oT,Intelligent Internet of Things)。
过去几年,吴韧一向行事低调,而近来 NovuMind 的领先技术却让他受到业界和资本的高度关注。
就在两年前,百度在 2015 年 ImageNet 大规模视觉辨识挑战赛 (ILSVRC) 中被指违规,吴韧离开百度,随后否认了部分扭曲事实的国外媒体所报道的「作弊」说,商汤科技创始人汤晓欧也公开发表署名文章,声称「百度并没有作弊,吴韧工作令人钦佩」。
不过,在接受《EE Times》的专访时,吴韧并不愿意再多谈此事,仅表示「目前全力专注自己的技术,是非交给历史评说」。
目前,NovuMind 正积极研发终端装置深度学习加速器,在这场技术革命中 NovuMind 正大步向前迈进。2016 年 12 月获得 1,520 万美金的 A 轮资金,NovuMind 如今即将启动第二轮融资。吴韧在电话专访中解释:「这就是为什么我目前留在北京。」
三维张量操作是关键
正如吴韧所说,边缘计算中深度学习加速的核心在与如何最大化能效比同时减小延迟。许多移动设备的电池容量都非常有限,因此必须提高计算能效比;同时在无人机和自动驾驶等应用中,延迟必须越小越好,这样才能及时避免事故。
在这样的背景下,吴韧提到了两种现有的边缘计算深度学习加速方案——DSP,如 CEVA 和 Tensillica;以及 GPU,如 Nvidia 的 TX 系列。
他接着解释说,「DSP 最初是为了数字信号处理(如数字滤波器)设计的,使用的是一维乘加单元(MAC),可以说是一维操作。GPU(包括 Google 的 TPU)使用的是二维矩阵操作(GEMM)。」
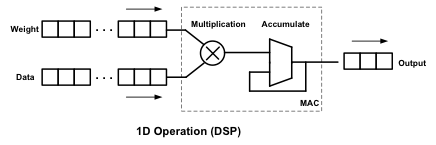
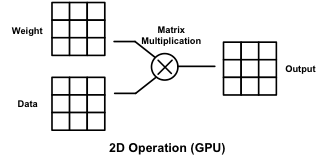
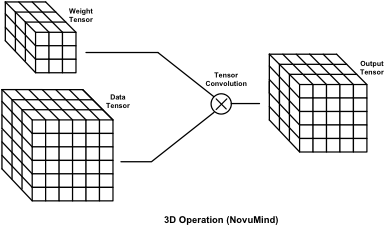
1D MAC、2D GEMM 和 3D Tensor 运作的比较(来源:NovuMind)
然而,目前的深度学习网络中的数据结构普遍是三维张量(Tensor)结构,而计算操作也是三维张量操作。吴韧进一步表示,「使用一维或者二维的运算单元去处理三维张量,必然会造成效率损失。这也是为什么虽然现在 GPU 和 DSP 都有很高的峰值性能,高达 1-2 TOPS,但是一旦跑真实的深度学习网络,实测效率就只有峰值效率的 20-30%。而且,内存存取没优化好,内存存取的时候计算单元就只能没事做,另外也有大量的能量都被浪费在了内存存取上面。」
NovuMind 如何解决这个问题呢?吴韧表示,NovuMind 使用的是与 DSP 和 GPU 都不同的架构——「独特的张量处理架构」,其芯片架构原生支持三维张量操作,因此可以大大提高深度学习加速器的芯片面积和能量的利用率。
目前 NovuMind 芯片架构在 FPGA 原型上执行主流深度学习网络时,实测效率可达峰值性能的 75%-90%。更关键的是,由于 NovuMind 的芯片架构直接支持三维张量操作,因此数据在内存中的组织形式非常高效,这样既可以节省内存带宽,又能大大减小内存访问时消耗的能量,从而极大地提高 NovuMind 人工智能加速芯片的能效比。吴韧强调,「比起传统的解决方案,我们的芯片架构优势巨大。」

NovuMind 创办人、CEO 吴韧
专注的力量
吴韧声称,NovuMind「基于三维张量运算」的设计,为其 AI 芯片带来了巨大优势。「由于它能直接在三维张量上进行处理,我们能避免三维张量运算展开到二维矩阵的中间步骤,因而能够节省大量的内存带宽与内存存取能量。」
但工程技术脱离不了权衡折衷。为了追求嵌入式 AI 所需的功率效率,NovuMind 的 AI 芯片又必须放弃什么呢?
吴韧表示:「NovuMind 的芯片为几种最重要的拓扑结构做优化,如 VGG、RESNET 网路所定义的层级,以及另一小部份我们认为重要且相关的其他网络层。」
「我们的芯片能非常高效地计算这些经过优化的网络层。当然,我们的芯片也可以处理其他类型的层,但计算效率会略有下降。」吴韧说,「NovuMind 的 AI 芯片目前的通用性不足,但我很有信心,因为我们有很强的 AI 团队,同时公司的超级计算机能提供强大的运算力支持训练,这样我们即使只使用这些经过优化的层也能搭建非常好的深度学习模型以满足绝大多数应用的需要。」
NovuMind 为什么深信 3x3 卷积核是必经之路?吴韧说:「这还要归功于原始的 VGG 网络的论文及其作者。」
VGG 是指英国牛津大学 (Oxford University) 工程科学系视觉几何小组 (Visual Geometry Group;VGG)。VGG 研究人员在 2015 年撰写了题为「大规模图像识别的超深度卷积网络」(Very Deep Convolutional Networks for Large-Scale Image Recognition) 的论文。
VGG 的这篇论文说服了吴韧将其芯片架构映射到硬件。他随即惊讶地发现 VGG 的架构非常适合硬件实现。「算法设计者能够提出如此优越且对硬件设计非常友好的算法,这是极其罕见的情况之一。」他认为,我们目前看到其他实际有用的网络拓扑都是以 VGG 的成果为基础的,包括大行其道的 ResNet,而 ResNet 中的相关层也是 Novumind 芯片优化的重点目标,目前来看,优化取得了非常好的效果。
吴韧并补充说:「由于 3x3 卷积是一个重要的组成部份,我们的设计当然将会尽可能地确保使其具有最高效率。」
延迟比较
吴韧表示,相较于 DSP 和 GPU,NovuMind 的架构在延迟方面表现出色。
他观察到,「DSP 是专为数据流处理而设计的,延迟表现不错。」另一方面,「GPU 通常需要对数据块做批量处理(batch processing),因而延迟较差——在 8-64 批次(batch)大小时约延迟 50-300 毫秒 (ms),」使其难以满足即时的需求。
他解释说,NovuMind 架构也使用了基于数据流的处理方式 (延迟< 3ms)。「我们可以想像,当一辆自动驾驶车以每小时 65 英哩 (mph) 的速度行驶而必须立刻刹车时,NovuMind 架构比 GPU 的延迟优势相当于刹车距离减少 4.5-30 英尺(相当于 1.5-9 米)。」他说:「这将会对自动驾驶车带来重大影响。」

DSP, GPU 与 NovuMind 架构比较
开发蓝图
吴博士提到,NovuMind 第一款芯片将基于 28 纳米技术。第二款芯片,预期 2018 年中旬推出,将会运用 16 纳米技术。
那么 NovuMind 的 AI 芯片可以怎么用呢?吴博士提出了几种应用场景,一个是包含 NovuMind 芯片的微型 USB 设备,从而使其连接到设备,如连接的摄像机,成为 AI 驱动的系统;第二,由于 NovuMind 的 AI 芯片具有高达每秒 15 万亿次操作的能力,可以让 AI 芯片用于「自动驾驶车」;此外,第三个应用场景是在云端使用 AI 芯片加速深度学习运算。
吴博士观察到,GPU 的高耗电、高发热和对机架空间的极高要求,限制了其在数据中心中的应用。虽然 NovuMind 的 AI 芯片是为「本地」设备而设计,但是可以将它以 PCIe 插卡的形式放在服务器内,对数据中心的关键应用进行加速,如语音识别等。
在自动驾驶方面,吴博士则认为,「今天在自动驾驶汽车中的一个集中式的计算单元将会比任何人想象的复杂得多」。实际上,他预计会有多个 AI 芯片对采集到的数据进行预处理,然后再将其提供给一个可以做出决策的中央单元。他解释说,NovuMind 的 AI 芯片将成为自动驾驶车内许多 AI 芯片之一。
目前,吴博士表示,公司的 AI 芯片原型已经可以组成系统并运行大规模多视频流多目标的人脸识别算法。凭借其强劲的处理能力,这款芯片真正量产后可以同时从 10 万路摄像头中识别数百万的目标人群。「更重要的是,我们可以在摄像头终端就做到这一点而不用连接到云端数据中心,因此就没有额外的网络带宽和存储空间开销。」他解释说。
为传感器增添「直觉」
在被问及深度学习的未来时,吴博士说,「掌握了大量数据和大量的计算能力,我们已经能够训练神经网络去做许多复杂的事情。」这是 AI 技术今天所在的地方。
但是,吴博士解释说,NovuMind 希望能够为传感器加上「直觉」。就像人类和动物都配备了五种感官一样,机器应该也能够有一定的「本能」来帮助他们做出反应,这是 AI 应用真正落地的方向。
「对于实现机器的普遍的智慧,推理能力和长期记忆,我们还有很长的路要走。」
原文地址:x-Baidu Scientist Blazes AI Shortcut
作者简介
吉田俊子(Junko Yoshida),EE Times 主编、首席国际特派记者,报道领域覆盖全球电子业,特别关注中国电子业发展。吉田俊子拥有近 30 年的报道经验,关注新一代消费电子产品的新兴技术和商业模式,目前致力于中国半导体制造业,专注于撰写和报道晶圆厂和无晶圆厂制造商。此外,她的报道领域还涉及汽车、物联网、无线/网络等。
本文为机器之心发布,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



