如何排查 Kubernetes 的内存增长问题?


作者 | 阿文
责编 | 郭芮
出品 | CSDN(ID:CSDNnews)
kubectl exec -it pod -n xxx /bin/bash
-
RSS是 Resident Set Size(常驻内存大小)的缩写,用于表示进程使用了多少内存(RAM中的物理内存),RSS不包含已经被换出的内存。 RSS包含了它所链接的动态库并且被加载到物理内存中的内存。 RSS还包含栈内存和堆内存。 -
VSZ是 Virtual Memory Size(虚拟内存大小)的缩写。 它包含了进程所能访问的所有内存,包含了被换出的内存,被分配但是还没有被使用的内存,以及动态库中的内存。

-
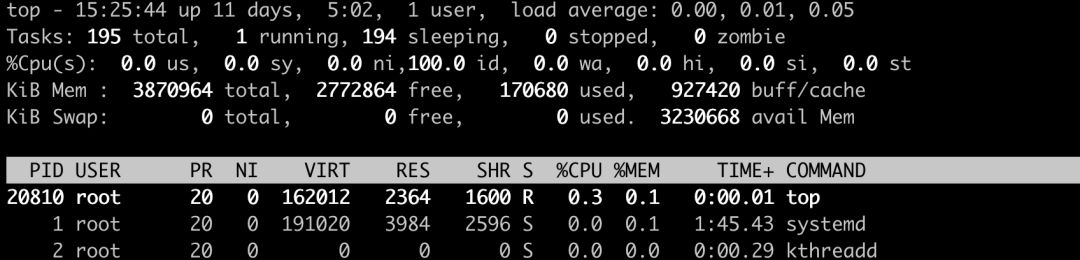
虚拟内存通常并不会全部分配给物理内存; -
共享内存 SHR 并不一定是共享,例如程序的代码段、非共享的动态链接库,也都算在 SHR 里。当然,SHR 也包括了进程间真正共享的内存。所以在计算多个进程的内存使用时,不要把所有进程的 SHR 直接相加得出结果。
cat /proc/7/status
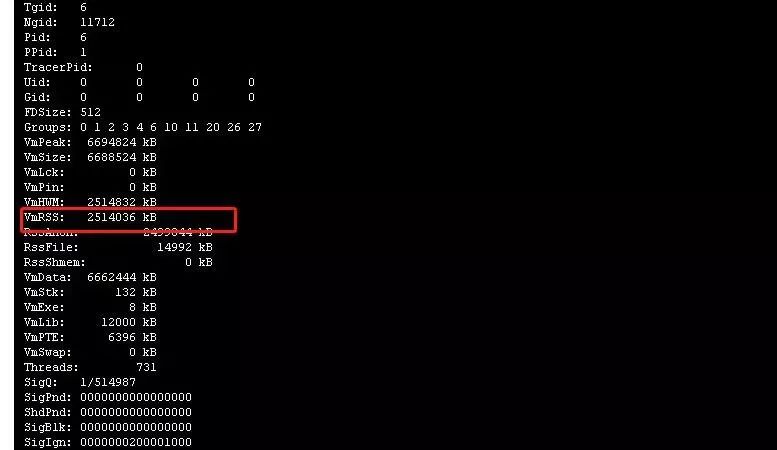
kubectl top pod
查看 pod 的内存占用 确实发现该 pod 占用 17 G ,说明并不是容器内进程内存泄露导致的问题,那这就奇怪了,是什么原因导致占用这么多内存呢?
[root@8e3715641c31 /]# dd if=/dev/zero of=my_new_file count=1024000 bs=3024
1024000+0 records in
1024000+0 records out
3096576000 bytes (3.1 GB, 2.9 GiB) copied, 28.7933 s, 108 MB/s
[root@8e3715641c31 /]# free -h
total used free shared buff/cache available
Mem: 3.7Gi 281Mi 347Mi 193Mi 3.1Gi 3.0Gi
Swap: 0B 0B 0B
DESCRIPTION
free displays the total amount of free and used physical and swap memory in the system, as well as the buffers and caches used by the kernel. The information is gathered by parsing /proc/meminfo. The displayed columns are:
total Total installed memory (MemTotal and SwapTotal in /proc/meminfo)
used Used memory (calculated as total - free - buffers - cache)
free Unused memory (MemFree and SwapFree in /proc/meminfo)
shared Memory used (mostly) by tmpfs (Shmem in /proc/meminfo)
buffers
Memory used by kernel buffers (Buffers in /proc/meminfo)
cache Memory used by the page cache and slabs (Cached and SReclaimable in /proc/meminfo)
buff/cache
Sum of buffers and cache
available
Estimation of how much memory is available for starting new applications, without swapping. Unlike the data provided by the cache or free fields, this field takes into account page cache and also that not all
reclaimable memory slabs will be reclaimed due to items being in use (MemAvailable in /proc/meminfo, available on kernels 3.14, emulated on kernels 2.6.27+, otherwise the same as free)
-
Buffers 是内核缓冲区用到的内存,对应的是 /proc/meminfo 中的 Buffers 值。 -
Cache 是内核页缓存和 Slab 用到的内存,对应的是 /proc/meminfo 中的 Cached 与 SReclaimable 之和。
-
Buffers 是对原始磁盘块的临时存储,也就是用来缓存磁盘的数据,通常不会特别大(20MB左右)。这样,内核就可以把分散的写集中起来,统-优化磁盘的写入,比如可以把多次小的写合并成单次大的写等等。 -
Cached是从磁盘读取文件的页缓存,也就是用来缓存从文件读取的数据。这样,下次访问这些文件数据时,就可以直接从内存中快速获取,而不需要再次访问缓慢的磁盘。 -
SReclaimable 是Slab的一部分。Slab 包括两部分,其中的可回收部分,用SReclaimable记录;而不可回收部分,用SUnreclaim记录。
kubectl logs -f pod-name -n namespace-name
sync; echo 3 > /proc/sys/vm/drop_caches //表示清空所有缓存(pagecache、dentries 和 inodes)
sync; echo 1 > /proc/sys/vm/drop_caches
sync; echo 2 > /proc/sys/vm/drop_caches
resources:
requests:
cpu: "200m"
memory: "128Mi"
limits:
cpu: "500m"
memory: "512Mi"
-
JVM 初始分配的内存由-Xms 指定,默认是物理内存的 1/64; -
JVM 最大分配的内存由-Xmx 指定,默认是物理内存的 1/4; -
默认空余堆内存小于 40% 时,JVM 就会增大堆直到-Xmx 的最大限制;空余堆内存大于 70% 时,JVM 会减少堆直到 -Xms 的最小限制; -
因此服务器一般设置-Xms、-Xmx 相等以避免在每次 GC 后调整堆的大小。对象的堆内存由称为垃圾回收器的自动内存管理系统回收。
-
JVM 使用-XX:PermSize 设置非堆内存初始值,默认是物理内存的 1/64; -
由 XX:MaxPermSize 设置最大非堆内存的大小,默认是物理内存的 1/4; -
-Xmn2G:设置年轻代大小为 2G; -
-XX:SurvivorRatio,设置年轻代中 Eden 区与 Survivor 区的比值。

登录查看更多
相关内容

Arxiv
7+阅读 · 2020年3月12日



相关VIP内容
相关资讯
相关论文
Arxiv
7+阅读 · 2020年3月12日