面向现实世界场景,多语言大数据集PRESTO来了
机器之心编辑部
PRESTO–一个多语言数据集,用于解析现实的面向任务的对话。
虚拟助理正日益融入我们的日常生活。它们可以帮助我们完成很多事情:从设置闹钟到在地图导航,甚至可以帮助残疾人更容易地管理他们的家。随着我们使用这些助手,我们也越来越习惯于使用自然语言来完成那些我们曾经用手完成的任务。
构建强大虚拟助理所面临的最大挑战之一是确定用户想要什么,以及完成这些任务需要哪些信息。在自然语言处理(NLP)的相关文献中,这件事被定义为一个面向特定任务的对话解析任务,其中给定的对话需要由系统解析,以理解用户意图并执行操作来实现该意图。
基于定制化的数据集,如 MultiWOZ、TOP、SMCalFlow 等,学术界在处理面向特定任务的对话方面取得了一些进展。但这些数据集缺乏模型训练所需的典型语音场景,无法优化语言模型性能,仍然有很大的进步空间。由此产生的模型往往表现不佳,用户对互动功能的效果有一些失望。相关的语音场景涉及内容修改场景、不流畅的对话语序场景、不同语言混合使用场景,以及使用围绕用户环境的结构化上下文,其中可能涉及用户的笔记、智能家居、联系人列表等。
例如以下对话,该对话说明了用户需要修改其话语时的一个常见实例:

体现了用户修订的对话实例。
虚拟助理误解了用户的请求,并试图拨打不正确的联系人。因此,用户必须修改他们的话语以纠正助手的错误。为了正确地解析最后一句话,助理还需要解释用户特指的内容 — 在这种情况下,它需要知道用户在他们的手机中保存了一个联系人名单,它应该参考这个名单。
另一类对虚拟助理具有挑战性的困难场景是混合语言采场景,当用户在对助理讲话时从一种语言切换到另一种语言时,就会发生语言混合使用。例如下面的话语:

英语和德语文本混合使用的对话示意图。
在本例中,用户从英语切换到德语,其中「vier Uhr」在德语中的意思是「四点钟」。
为了推进解析这种现实存在的复杂语言文本的研究,近日,谷歌助手团队和哥伦比亚大学俞舟教授合作推出一个名为 PRESTO 的新数据集,这是一个用于解析现实任务对话的多语言数据集,其中包括大约 50 万人与虚拟助理之间的现实对话。
该数据集涵盖六种不同的语言,包括用户在使用助手时可能遇到的多种对话场景,包括用户定制改变、不流畅的对话语序场景、不同语言混合使用场景。数据集还包括结构化的上下文,例如用户的联系人列表。PRESTO 对各种场景进行了标注,使人们能够创建不同的测试集来分别分析这些语言场景的模型性能。

论文链接:https://arxiv.org/abs/2303.08954
研究者发现,这些场景中的一些更容易建模,只需很少的样本,而另一些场景则需要更多的训练数据。
数据集特征
涉及六种语言
我们数据集中的所有对话都是由语言对应的原生使用者提供,包括六种语言 —— 英语、法语、德语、印地语、日语和西班牙语。这与其他数据集,如 MTOP 和 MASSIVE 形成了鲜明对比。上述数据集仅将话语从英语翻译成其他语言,并不一定反映以非英语为母语的人的语言模式。
结构化上下文
用户在与虚拟助理交互时,通常会使用存储在设备中的信息,如笔记、联系人和列表。然而,助手通常无法访问此上下文,这可能导致在处理用户话语时出现解析错误。为了解决这个问题,PRESTO 包括三种类型的结构化上下文、注释、列表和联系人,以及用户话语及其解析。列表、笔记和联系人由每种语言的母语使用者在数据收集过程中编写。有了这样的上下文,研究者可以探索如何使用这些信息来提高解析面向任务的对话模型的性能。
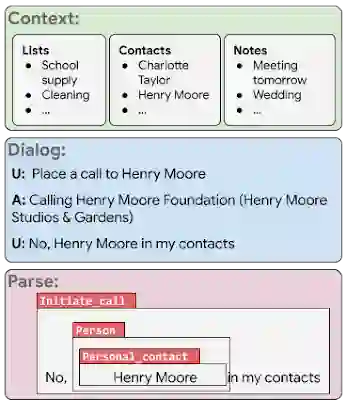
PRESTO 中的每个例子都包括:输入 —— 用户的虚拟状态(上下文)、一个或多个用户的对话,以及虚拟助理的回应(对话)。输出 —— 对话中最后一个用户话语的语义解析(parse)。
内容修改场景
用户在与虚拟助理交谈时,修改或纠正自己的话语是很常见的。这些修改发生的原因有很多 —— 助手可能在理解话语方面犯了错误,或者用户在发表话语时改变了他们的想法,例如图二。其他例子包括取消自己的请求(「不要添加任何东西。」)或在同一个语词中纠正自己(「添加面包 — 不,不,等等 — 在我的购物清单上添加小麦面包。」)。在 PRESTO 的所有例子中,大约有 27% 的例子有某种类型的用户修改,并且在数据集中有明确的标记。
语言混合使用场景
截至 2022 年,世界上大约有 43% 的人口是双语的。因此,许多用户在与虚拟助手交谈时都会转换语言。在建立 PRESTO 的过程中,研究者要求双语数据贡献者对语言混合使用的语料进行注释,这些语料约占数据集中所有语料的 14%。

来自 PRESTO 的印地语 - 英语、西班牙语 - 英语和德语 - 英语编码混合语料的例子。
非流畅的对话语序场景
由于人们和虚拟助手的对话中存在很多口语表达,类似重复的短语或填充词这样的断续语在用户的话语中是无处不在的。像 DISFL-QA 这样的数据集注意到现有的 NLP 文献中存在这样的场景,开始致力于跨域这种鸿沟。在本文的工作中,研究者考虑了六种语言下的对话。其中,英语、日语和法语中带有填充词或重复的语料的例子。

主要发现
研究者对上述每一种场景都进行了有针对性的实验,他们使用 PRESTO 数据集训练出一些基于 mT5 的模型,并使用介于预测解析和人工注释解析之间的一种精确匹配方法来对模型进行评估。下面展示了对内容修改场景、非流程的对话语序场景和语言混合使用场景这三种场景中,在不同的训练数据数量下的性能结果。
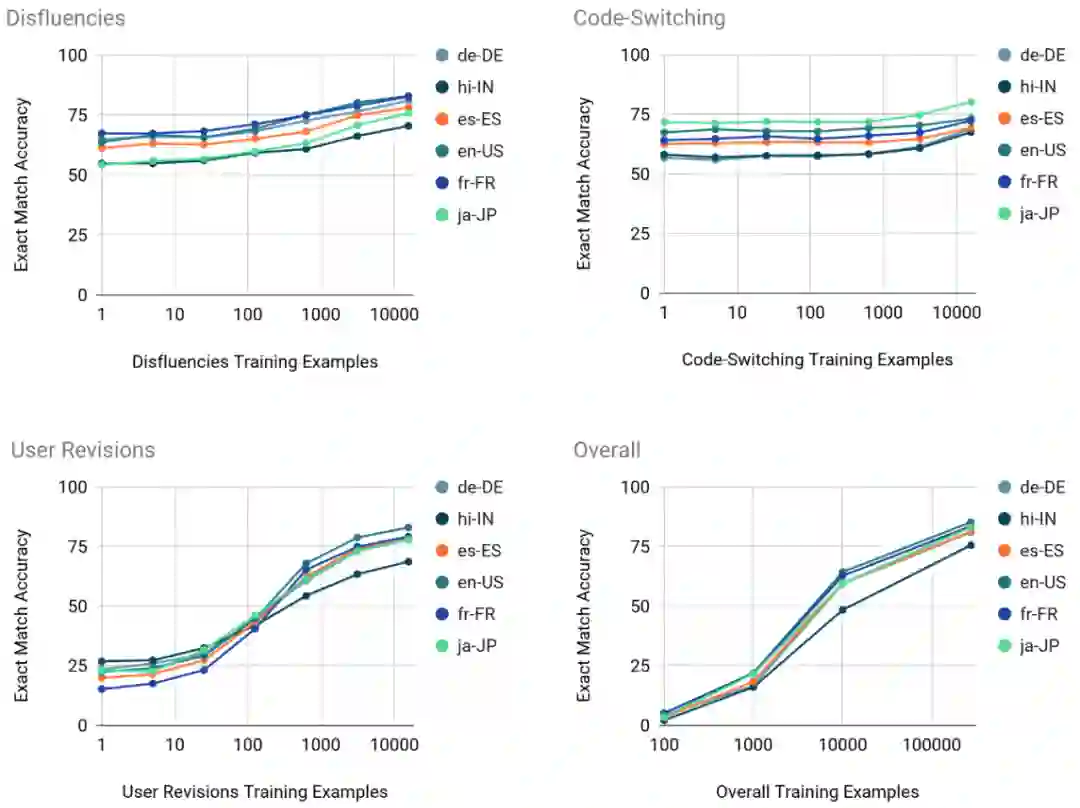
随着训练数据量的增加,对各种语言场景和完整测试集进行 K-shot 的结果。
可以发现,对目标场景进行零样本学习得到的性能较差,这说明在数据集中使用目标场景中设计的文本来提高性能是有必要的。模型在非流程的对话语序场景和语言混合使用场景下的表现比用户判读要好得多(精确匹配准确度相差 40 多分)。
结论
在该工作中,作者介绍了 PRESTO,一个用于解析面向对话任务的多语言数据集。该数据集涵盖了用户与虚拟助理的日常对话中的各种真实痛点,这些痛点是当前 NLP 社区中现有数据集所缺乏的。
PRESTO 包括大约 50 万个由英语、法语、德语、印地语、日语和西班牙语六种语言的母语使用者贡献的话语。研究者创建了专门的测试集来评估每一种场景 —— 内容修改场景、非流程的对话语序场景和语言混合使用场景以及结构化的上下文。实验的结果表明,当目标场景不包含在训练集中时,零样本的表现较差,这表明需要使用此类语句来提高性能。
同时研究者注意到,内容修改场景、非流程的对话语序场景更容易通过增加更多的数据来完成建模,而语言混合使用场景下即使有更多的样本,也依然难以建模。
随着这个数据集的发布,研究者预期能带来新一轮的探索热潮,他们希望研究界能在用户每天日常聊天场景下进行研究,并且能取得进展。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com


