如何评价 ICCV 2019 的论文接收结果?有哪些亮点论文?
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
本文来自知乎问答,回答均已获作者授权,禁止二次转载
问题:如何评价 ICCV 2019 的论文接收结果?有哪些亮点论文?
https://www.zhihu.com/question/336194144
知乎高质量回答
一、作者:王云鹤
https://www.zhihu.com/question/336194144/answer/758560475
大半夜自问自答一下。自己组里投了两篇iccv都中了!不容易不容易。分别提出了一个无需训练数据的神经网络压缩算法,生成对抗网络(GAN)的剪枝算法,无论是内部还是审稿人,均给出了比较积极正向的评论。稍后我会尽快整理并敦促开源。:-P
------ 7月24日更新 ------
由于开源和挂arxiv需要走一个审批,先给大家安利一下Data-free learning和之前的几个工作:
1、Data-Free Learning of Student Networks. ICCV 2019. 这个我们很早就挂了arxiv,大家可以先看一下,很快就会开源的。
首次提出了在无数据情况下的网络蒸馏方法(DAFL),比之前的最好算法在MNIST上提升了6个百分点,并且使用resnet18在CIFAR-10和100上分别达到了92%和74%的准确率(无需训练数据)。
DAFL: Data-Free Learning of Student Networks
链接:https://arxiv.org/abs/1904.01186
2、Learning Versatile Filters for Efficient Convolutional Neural Networks. NIPS 2018.
即插即用的新型多用卷积核,在不同的任务(分类、检测、超分辨率)上均取得了比较好的效果。
链接:
http://papers.nips.cc/paper/7433-learning-versatile-filters-for-efficient-convolutional-neural-networks.pdf
3、LegoNet: Efficient Convolutional Neural Networks with Lego Filters. ICML 2019.
新型乐高卷积核,给未来的网络设计提一些新组件新思路。
链接:
http://proceedings.mlr.press/v97/yang19c/yang19c.pdf
以上三个工作,都会开源,都会开源,都会开源(划重点)。大家可以先关注一下这个github,https://github.com/huawei-noah,审批完成后都会开源到相应的页面上。
------ 7月26日更新 ------
大家关注的GAN压缩来了,欢迎大家讨论和后续试用:)
4、Co-Evolutionary Compression for Unpaired Image Translation. ICCV 2019.
https://arxiv.org/pdf/1907.10804.pdf
在这个工作里面,同时维护了两套种群,用来对cycleGAN里面的两个generator进行同步剪枝,并采用了discriminator aware loss来保持风格信息。保证translation任务完成的同时,将两个generators均压缩加速4倍以上,在一些ARM based机器上,也有约3倍左右的线上加速。开源代码整理好后,我再发一份详细的介绍~
-------------------------------------------------------------------------------------
此外更新一下我们组近一年的paper list,欢迎大家关注:
1. Yunhe Wang, Chang Xu, Chunjing Xu, Chao Xu, Dacheng Tao. Learning Versatile Filters for Efficient Convolutional Neural Networks, NeurIPS 2018.
2. Zhaohui Yang, Yunhe Wang, Hanting Chen, Chuanjian Liu, Boxin Shi, Chao Xu, Chunjing Xu, Chang Xu. LegoNet: Efficient Convolutional Neural Networks with Lego Filters. ICML 2019.
3. Mingjian Zhu, Kai Han, Chao Zhang, Jinlong Lin, Yunhe Wang. Low Resolution Visual Recognition via Deep Feature Distillation, ICASSP 2019.
4. Minjing Dong, Hanting Chen, Yunhe Wang, Chang Xu. Crafting Efficient Neural Graph of Large Entropy. IJCAI 2019.
5. Kai Han, Yunhe Wang, Han Shu, Chuanjian Liu, Chunjing Xu, Chang Xu. Attribute Aware Pooling for Pedestrian Attribute Recognition. IJCAI 2019.
6. Chuanjian Liu, Yunhe Wang, Kai Han, Chunjing Xu, Chang Xu. Learning Instance-wise Sparsity for Accelerating Deep Models. IJCAI 2019.
7. Hanting Chen, Yunhe Wang, Chang Xu, Zhaohui Yang, Chuanjian Liu, Boxin Shi, Chunjing Xu, Chao Xu, Qi Tian. Data-Free Learning of Student Networks, ICCV 2019.
8. Han Shu, Yunhe Wang, Xu Jia, Kai Han, Hanting Chen, Chunjing Xu, Qi Tian, Chang Xu. Co-Evolutionary Compression for Unpaired Image Translation, ICCV 2019.
------ 2019/9/5更新开源地址 ------
Data-Free Learning of Student Networks, ICCV 2019.
开源地址:https://github.com/huawei-noah/DAFL
------ 2019/9/10更新开源地址 -----
Co-Evolutionary Compression for Unpaired Image Translation, ICCV 2019.
开源地址:
https://github.com/huawei-noah/GAN-pruning
Learning Versatile Filters for Efficient Convolutional Neural Networks
开源地址:
https://github.com/huawei-noah/Versatile-Filters
LegoNet: Efficient Convolutional Neural Networks with Lego Filters
开源地址:
https://github.com/huawei-noah/LegoNet
二、作者:量子位
https://www.zhihu.com/question/336194144/answer/876628418
人在ICCV 2019,刚从韩国首尔离开。
说两篇有意思的论文吧,来自一个中国小哥,都是关于“衣服”的研究。
一篇教人穿衣服,另一篇给人换衣服。
比脱衣服的研究难多了,而且颇具商业价值。【doge
第一篇教人穿衣服:FiNet模型
这篇论文题目为Compatible and Diverse Fashion Image Inpainting,还被接收为Oral论文(接受率仅4.6%),研究方向是时装搭配。

研究到了这个程度,只是简单地将输入图像中缺失的时尚单品补全已经不够用了。
想要突出还要注重整体搭配的协调性与真实性。
在这个过程中,最棘手的一个问题是,如何在耦合形状和外观时,妥善处理衣服的边界。
这也是同类模型效果不如人意,且无法商业化的关键点之一。
这个论文中,作者提出了一个名为FiNet的模型,基于两阶段的变分自编码器的生成网络,在满足多样性和兼容性的条件下,来填充图像中缺失的时尚商品。
核心思路是,分别用形状生成网络和外观生成网络,来依次生成缺失衣服的形状和外观。
从而使FiNet可以在目标区域中修复出具有不同形状和外观的服装。
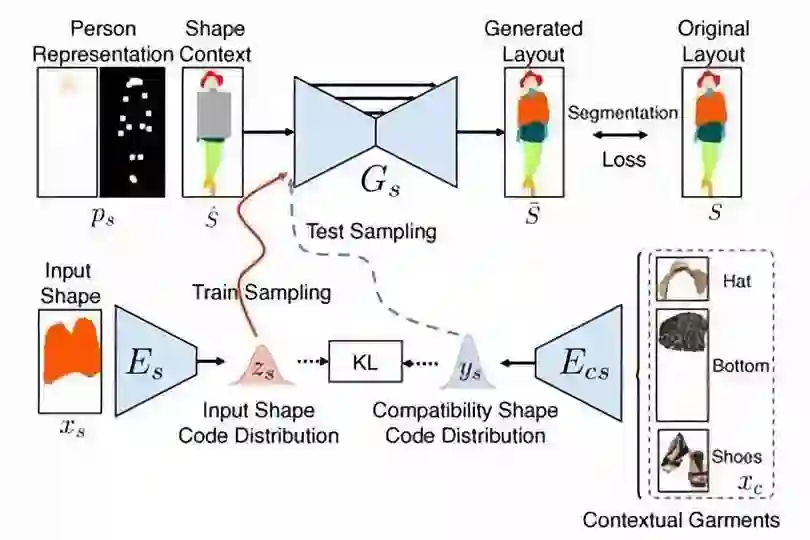
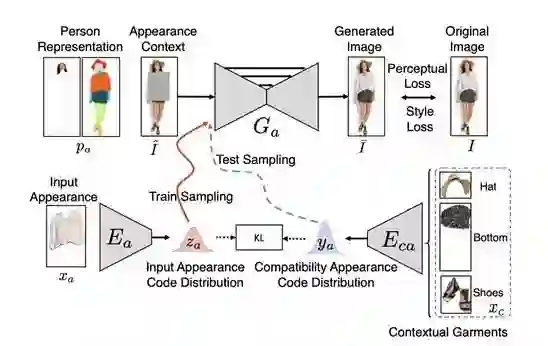
为了保证兼容性,作者也在其中集成了一个兼容性模块,将兼容性信息编码到网络中,来保证让生成衣服的形状和外观都是和其他衣服是兼容搭配的。
如此研究,应用场景也颇为广泛。
从用户的角度来说,在不知道穿什么衣服出门的时候,可以让计算机模型自动生成搭配的潮流服装。
而商家,则是可以将这一技术,应用到时装设计和新时尚商品推荐等应用中,来更好的实现商业购买转化,进一步激发用户的消费力。
那效果如何呢?在论文中,作者给出的效果是这样的:

直观来看,与Pix2Pix+noise、BicyleGAN、VUNET、ClothNet等方法相比,效果比较好。
从实际应用的角度来分析,FiNet模型的结果,也相对更接近落地一些。
论文地址:
FiNet:Compatible and Diverse Fashion Image Inpainting
链接:https://arxiv.org/abs/1902.01096v2
第二篇:给人换衣服,ClothFlow模型
这篇论文名为ClothFlow: A Flow-Based Model for Clothed Person Generation,研究主题也是衣服生成。
但与FiNet模型比起来,这篇论文的实现方式与应用方向都有很大不同。
ClothFlow是一个基于外观流的衣服生成模型。
主要用于将一个图片中的服装渲染到另外一张图片上,其想要实现的效果是这样的:

具体的实现方式,是使用一个级联的特征金字塔网络,估算源服装区域和目标服装区域的几何变换,然后通过多个基于编码器-解码器的生成网络来实现“衣服迁移”。
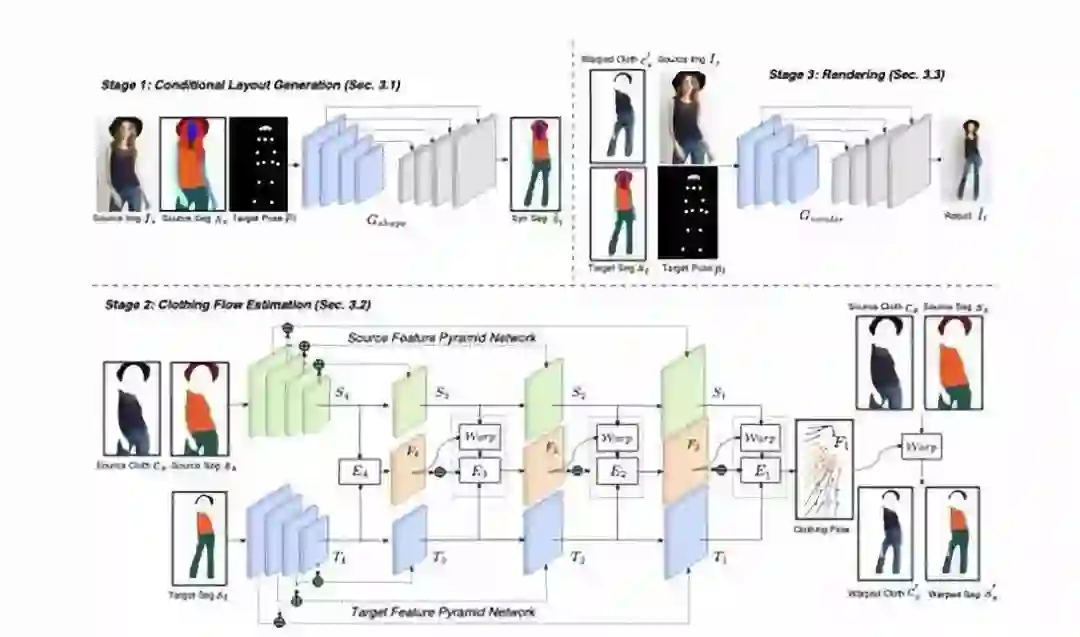
在论文中,作者也多次提到了这一研究的应用场景——虚拟试衣等服装相关应用。
尤其是在直播场景中,有不少的想象空间。
这一技术成熟后,主播可以虚拟换装,省去买衣服的成本和换衣服的时间。
而且, 用户也可以根据自己的喜好给主播选穿什么样的衣服。
论文地址:
ClothFlow: A Flow-Based Model for Clothed Person Generation
http://openaccess.thecvf.com/content_ICCV_2019/papers/Han_ClothFlow_A_Flow-Based_Model_for_Clothed_Person_Generation_ICCV_2019_paper.pdf
三、作者:Weiran Huang
https://www.zhihu.com/question/336194144/answer/794404398
宣传一波我们在今年 ICCV 的一个小样本学习的工作《Few-Shot Learning with Global Class Representations》(项目地址)。
项目地址:
https://tiangeluo.github.io/GlobalRepresentation.html
论文地址:
https://www.weiranhuang.com/publications/GlobalRepresentation-ICCV19.pdf
图像识别是计算机对图片进行理解和处理的第一步。
常见应用场景:手机相册自动分类,识别拍摄物体以便进行后续处理等
近年来,在深度网络的帮助下,计算机已经在图像识别上取得了超越人类的效果
存在的问题:
现有的图像识别技术集中于大规模的物体识别,因为深度网络需要大量训练数据
现实世界中,有很多场景没有这么多的标注数据,获取标注数据的成本也非常大,例如在医疗领域、安全领域、终端用户手动标注等
在没有大量训练数据的条件下,如何让深度神经网络也能够像人类一样,把过往的经验迁移到新的类别上

相比之下,借助于之前丰富的知识积累,人类只需看一次就能轻松识别出新的类别。受到人类这种利用少量样本即可识别新类能力的启发,研究者们开始研究小样本学习问题。在小样本学习问题中,我们假设有一组基类,以及一组新类。每个基类具有足够的训练样本,而每个新类只有少量标记样本。小样本学习的目的是通过从基类转移知识来学习识别具有少量标注样本的新类别。我们提出一种基于全局类别表征的小样本学习方法,可以应用于:
1、标准小样本学习问题:给定一个大规模的训练集作为基类,可以类比于人类的知识积累,对于从未见过的新类(与基类不重叠),借助每类少数几个训练样本,需要准确识别新类的测试样本。
2、广义小样本学习问题:相比与小样本学习,广义小样本学习中测试样本不仅包含新类,还包含了基类。
传统小样本学习的方法,通常只使用基类数据进行学习。由于基类和新类之间存在严重的样本不均衡问题,导致容易过拟合到基类数据,这一点在广义小样本问题中尤为突出。通过在训练阶段引入新类的数据,我们同时对基类和新类学习全局类别表征,并利用样本生成策略解决类别不均衡问题,有效防止训练模型在基类数据中出现过拟合的现象,从而提高了模型泛化到新类的能力。
解决方案
我们的思路是将每个类(包括基类和新类)表示为特征空间中的一个高维向量(称为类别表征),然后将测试图片到各个类的表征的距离进行比较,来对测试图片进行分类。我们同时使用基类与新类的 “所有训练样本” 来学习这种类别表征,因此称这种表征为全局类别表征。
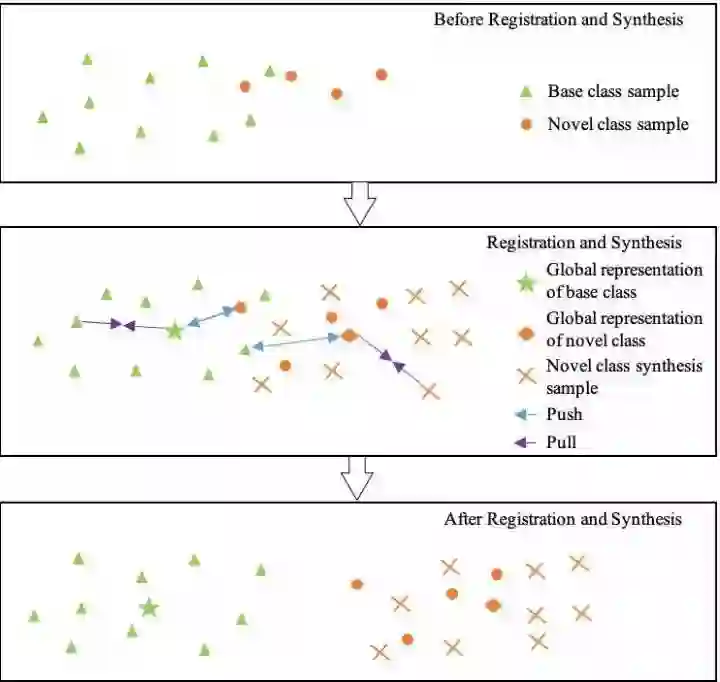
上图给出了一个直观的几何解释:第一个框是尚未进行 “样本生成” 和 “注册” 的初始状态,其中每个点代表一个样本在特征空间中的位置,绿色三角形的点代表某个基类的样本,橙色的圆点代表某个新类的样本。为了能够将两类分开,我们需要对特征空间做变换,使得绿色和橙色的点能够分开(如第三个框所示)。第二个框表示了对特征空间做变换的过程:首先我们先对新类数据进行样本生成(生成的样本用橙色的叉表示),然后将绿色和橙色两类的样本分别往各自的全局类别表征 “拉近”,同时把不同类的样本互相 “推开”。这个过程被称作 “注册”。
下图是我们训练框架的示意图(点开看大图):
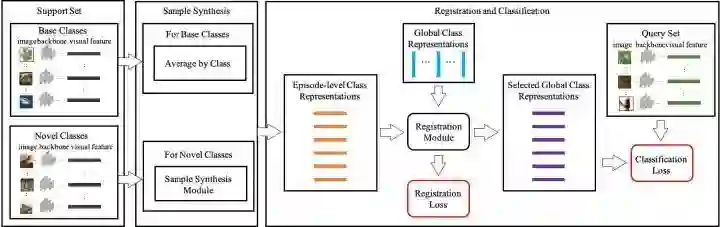
训练方法:
输入基类图片池和新类图片池,我们分阶段进行训练(episodic training)。初始状态时,我们把各个类别所有训练样本的特征向量的平均值作为对应全局类别表征。在每个训练阶段(training episode),我们先选取若干个类作为本轮训练的数据。将样本通过特征提取网络提取图像特征,然后对于每个基类,我们使用该类样本的特征向量的平均值作为该类的阶段性类别表征;对于每个新类,由于样本量小,我们首先使用数据增强手段进行样本生成,然后将其作为该新类的阶段性类别表征。之后将得到的阶段性类别表征送入注册模块和全局类别表征进行配准,得到对应的全局类别表征以及注册误差。随后通过将每个问询集中的样本与配准后的全局表征进行比较,用最近邻的方法预测样本的标签,然后与真实标签对比,得到分类误差。把注册误差和分类误差相加得到总体误差,然后用来训练我们的模型(需要更新的是特征提取网络,全局类别表征和注册模块)。
测试方法:
将测试图片提取图片特征向量后,与配准后的全局类别表征进行比较,用最近邻的方法预测样本的标签。测试方法与训练过程中对问询数据进行预测的方法一致。
具体的实现细节,可以参看论文原文。
原文 链接:
https://www.weiranhuang.com/publications/GlobalRepresentation-ICCV19.pdf
部分实验效果
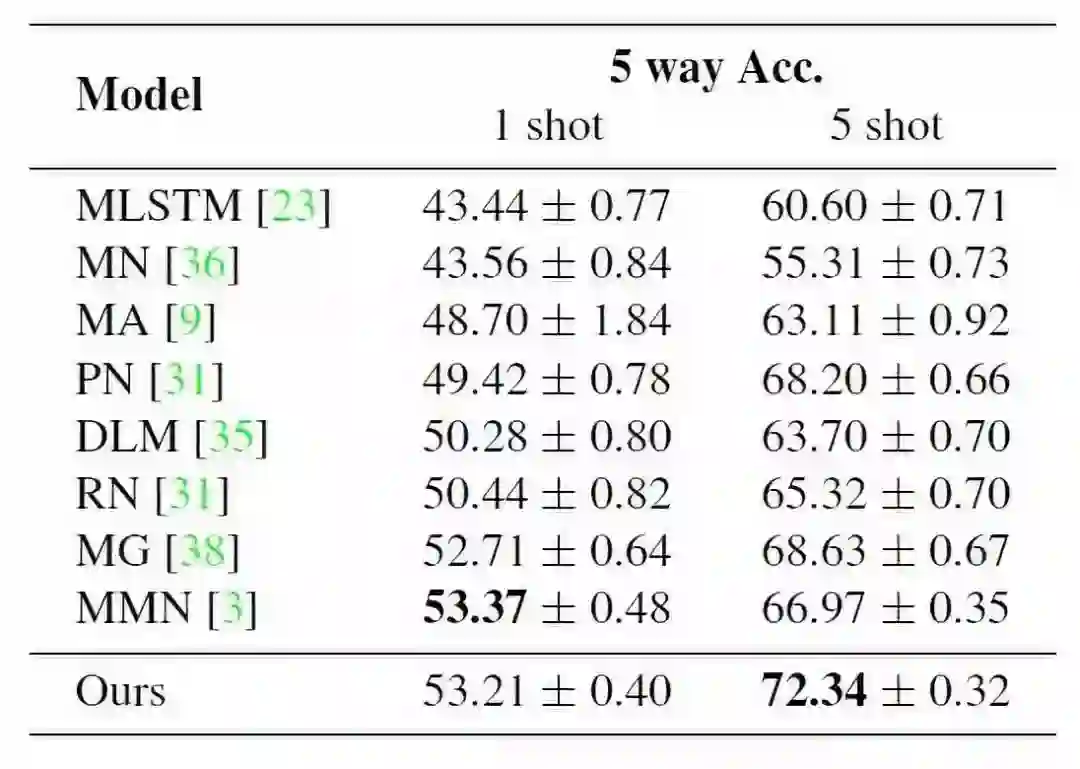
1、标准小样本学习
我们从 miniImageNet 中取 64 类用作 training,16 类用作 validation,20 类用作 testing。待分类的测试图片只从新类中选取。1 shot 表示在训练集中每个新类有 1 个样本,5 shot 表示每个新类有 5 个样本。每次预测需要从 5 个候选类中选择一个作为给定图片的分类。下表给出了我们的方法和其他小样本学习方法的对比结果。从表中可以看出,我们的方法具有很好的表现。
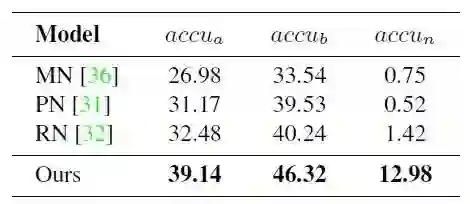
2、 广义小样本学习
我们仍然在 miniImageNet 上进行实验,具体设定和小样本学习的设定相同。唯一的区别在于测试样本同时从基类和新类抽取。每个新类包含 5 个训练样本。衡量指标有三个:

下表给出了我们的方法和其他方法的对比实验结果,从表中可以看出,我们的方法显著超过了对比算法。
总结:
我们提出的方法同时使用了基类数据和新类的小样本数据来学习类别表征,可以防止训练的模型在基类上过拟合。
相比于之前学习阶段性类别表征的方法,我们提出的全局类别表征直接与所有基类和新类训练样本进行比较,可能更具可分辨性。
我们的方法能同时有效处理标准小样本学习和广义小样本学习。
传送门:
Weiran Huang:基于全局类别表征的小样本学习
链接:
https://zhuanlan.zhihu.com/p/78743300
最后再推荐下我们关于 ICCV 2019 论文、代码等汇总的开源GitHub项目:
https://github.com/extreme-assistant/iccv2019
-End-
*延伸阅读
CV细分方向交流群
添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入目标检测、目标跟踪、人脸、工业检测、医学影像、三维&SLAM、图像分割等极市技术交流群(已经添加小助手的好友直接私信),更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台
觉得有用麻烦给个在看啦~





