【牛津DeepMind】从Word2Vec到BERT:上下文嵌入(Contextual Embedding)最新综述论文
【导读】词嵌入表示向量是自然语言处理的重要组成部分。最近来自牛津大学和DeepMind等撰写了关于上下文嵌入表示的综述论文,详述了当前预训练模型的代表性工作等。

地址:
https://www.zhuanzhi.ai/paper/74bd42517a67f1258516cb5086cf3524
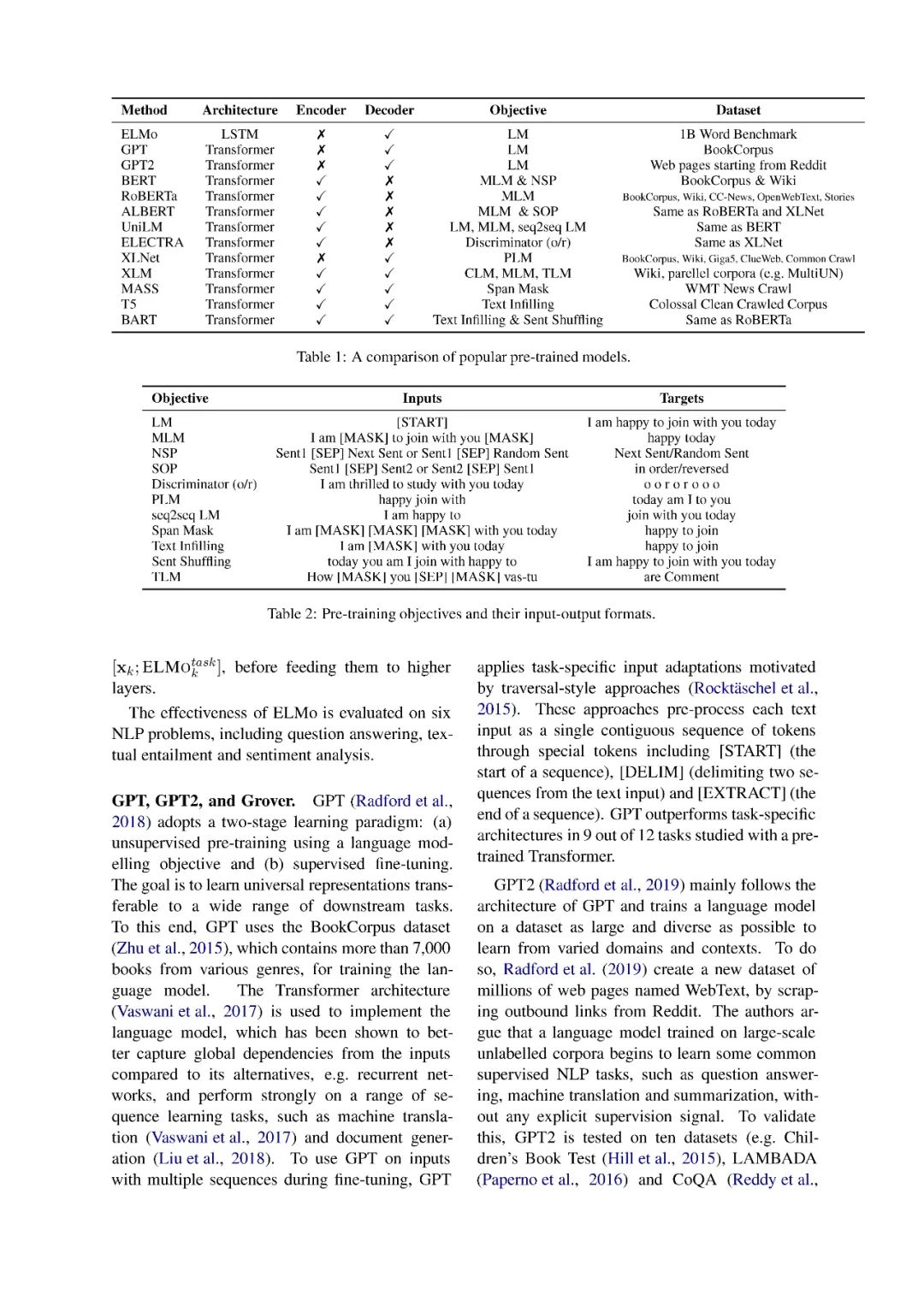
上下文嵌入,如ELMo和BERT,超越了像Word2Vec这样的全局单词表示,在广泛的自然语言处理任务中取得了突破性的性能。上下文嵌入根据上下文为每个单词分配一个表示,从而捕获不同上下文中单词的用法,并对跨语言传输的知识进行编码。在这项综述中,我们回顾了现有的上下文嵌入模型、跨语言的多语言预训练、上下文嵌入在下游任务中的应用、模型压缩和模型分析。
在大型语料库无监督训练的分布式词表示(Turian et al., 2010; Mikolov et al., 2013; Pennington et al., 2014)在现代自然语言处理系统中得到了广泛的应用。但是,这些方法只获得每个单词的一个全局表示,而忽略了它们的上下文。与传统的单词表示不同,上下文嵌入超越了单词级语义,因为每个标记都与作为整个输入序列的函数的表示相关联。这些与上下文相关的表示可以在不同的上下文中捕捉到词汇的许多句法和语义特征。(Peters et al., 2018; Devlin et al., 2018; Yang et al., 2019; Raffel et al., 2019)的研究表明,在大规模未标记的语料库上预训练的上下文嵌入,在文本分类、问题回答和文本摘要等一系列自然语言处理任务上取得了最先进的表现。进一步的分析(Liu et al., 2019a; Hewitt and Liang, 2019; Hewitt and Manning, 2019; Tenney et al., 2019a)证明了上下文嵌入能够学习跨语言的有用且可迁移的表示。
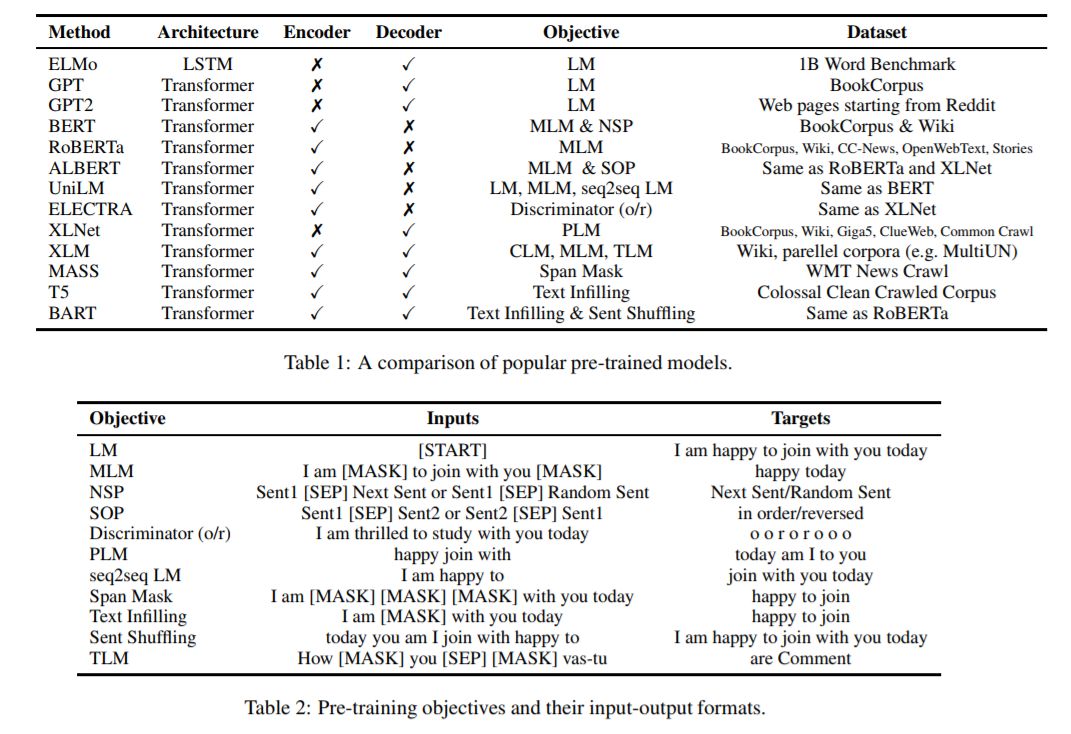
综述论文的其余部分组织如下。在第2节中,我们定义了上下文嵌入的概念。在第3节中,我们将介绍获取上下文嵌入的现有方法。第四部分介绍了多语言语料库中下文嵌入的预处理方法。在第5节中,我们描述了在下游任务中应用预训练的上下文嵌入的方法。在第6节中,我们详细介绍了模型压缩方法。在第7节中,我们调查了旨在识别通过语境嵌入学到的语言知识的分析。在第8节中,我们通过强调未来研究的一些挑战来结束综述。












专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“CE” 就可以获取《从Word2Vec到BERT:上下文嵌入(Contextual Embedding)最新综述论文》专知下载链接




