更轻量的 pQRNN:基于投影,实现快速并行的 NLP 处理

文 / Prabhu Kaliamoorthi,Google Research 软件工程师
深度神经网络在过去十年中从根本上改变了自然语言处理 (NLP),主要途径是其在使用专用硬件的数据中心上的应用。然而,保护用户隐私、消除网络延迟、实现离线功能以及降低运营成本等需求激发了 NLP 模型在设备端而非数据中心上部署的研究的飞速发展。不过,移动设备的内存和处理能力有限,这就要求在它上面运行的模型必须小巧高效,同时不牺牲质量。
去年,我们发布了名为 PRADO 的神经网络模型,当时在许多文本分类问题上都表现出 SOTA 的性能,并且所用模型的参数不到 200K。大多数模型的每个 token 使用固定数量的参数,而 PRADO 模型使用的网络结构只需要很少的参数即可学习对任务最相关或最实用的 token。
PRADO
https://www.aclweb.org/anthology/D19-1506.pdf
今天,我们将介绍的是 pQRNN,这一全新的模型扩展以最小模型尺寸推进了 NLP 的 SOTA 性能。pQRNN 的新颖之处在于它能够将简单的投影操作与准 RNN 编码器相结合,实现快速并行处理。我们的结果表明 pQRNN 模型能够以较少的参数数量在文本分类任务上实现 BERT 级效果。
准 RNN
https://arxiv.org/abs/1611.01576
PRADO 的工作原理
一年前开发时,PRADO 利用了 NLP 领域特定的文本分割知识来缩减模型大小并提高性能。通常,NLP 模型的文本输入首先会被处理为适合神经网络的形式。方法是将文本分割成碎片 (token),与预定义通用字典(所有可能 token 的列表)中的值对应。然后,神经网络使用可训练的参数向量(包括嵌入向量表)唯一地标识每个片段。但是,文本的分割方式会对模型的性能、大小和延迟产生重大影响。下图显示了 NLP 社区使用的各种方法及其优缺点。
通用字典
https://blog.floydhub.com/tokenization-nlp/
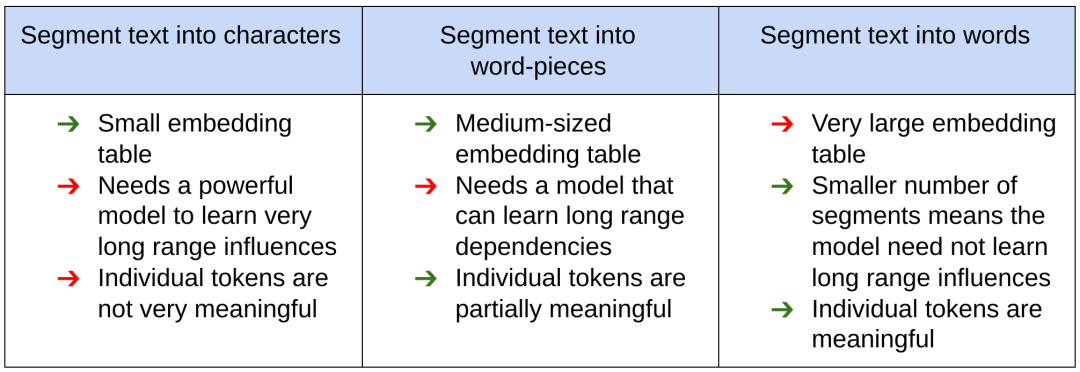
由于文本段的数量是模型性能和压缩的重要参数,这就提出了一个问题,也就是 NLP 模型是否需要有能力明显区分每一个可能的文本段。为了回答这个问题,我们来看一下 NLP 任务的内在复杂性。
只有少数 NLP 任务(如语言模型和机器翻译)需要知道文本段之间的细微差异,也因此需要能够唯一识别所有可能的文本段。相比之下,大多数其他任务可以通过知道这些片段的一小部分子集来解决。此外,这个与任务相关的片段子集可不太常见,因为片段的绝大部分显然专用于冠词,比如 a、 an、 the 等,对于很多任务来说,这些冠词并不重要。因此,让网络为给定任务确定最相关的片段,可以获得更好的性能。此外,网络不需要唯一识别这些片段,而只需要识别文本段的簇。例如,情感分类器只需要知道与文本中的情感高度相关的片段簇。
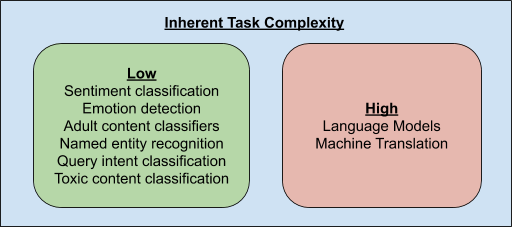
基于以上分析,PRADO 被设计为从单词而非单词片段或字符中学习文本段的簇,能够在低复杂度的 NLP 任务中取得良好性能。由于单词粒度更有意义,而与大多数任务最相关的单词却相当少,因此学习相关单词簇的简化子集所需的模型参数也相应少很多。
改进 PRADO
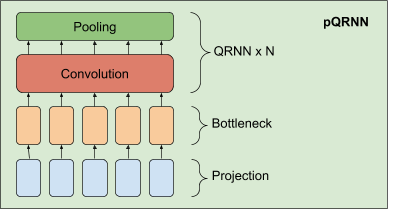
在 PRADO 成功的基础上,我们开发了一种改进的 NLP 模型,称为 pQRNN。此模型由三个基本模块组成,一个是将文本中的 token 转换为三元向量序列的投影算子,一个密集的瓶颈层 (Bottleneck Layer) 和一些堆叠的 QRNN 编码器。
pQRNN 中投影层的实现与 PRADO 中的相同,可帮助模型学习最相关的 token,而无需一组固定的参数来定义。它首先对文本中的 token 进行记录,然后使用简单的映射函数将其转换为三元特征向量。这样就得到了具有平衡对称分布的三元向量序列,唯一地表示了文本。这种表示无法直接投入使用,因为它没有提供解决目标任务所需的信息,而且网络也无法控制这种表示。我们将其与密集瓶颈层结合,使网络学习与当前任务相关的每个单词的表示。瓶颈层产生的表示仍然没有考虑单词的上下文。我们使用双向 QRNN 编码器堆栈来学习上下文表示,得到一个能够从文本输入中学习上下文表示而无需任何预处理的网络。
性能
我们在 civil_comments 数据集上评估了 pQRNN,并将其与同一任务上的 BERT 模型进行了对比。仅仅因为模型大小与参数数量的正比关系,pQRNN 就比 BERT 小得多。除此之外,pQRNN 还经过量化,进一步将模型大小缩减至原来的四分之一。BERT 的公开预训练版本在任务上表现不佳,因此,为了取得最佳结果,比较的是在几种不同的相关多语言数据源上预训练的 BERT 版本。
civil_comments
https://tensorflow.google.cn/datasets/catalog/civil_comments量化
https://arxiv.org/abs/1712.05877
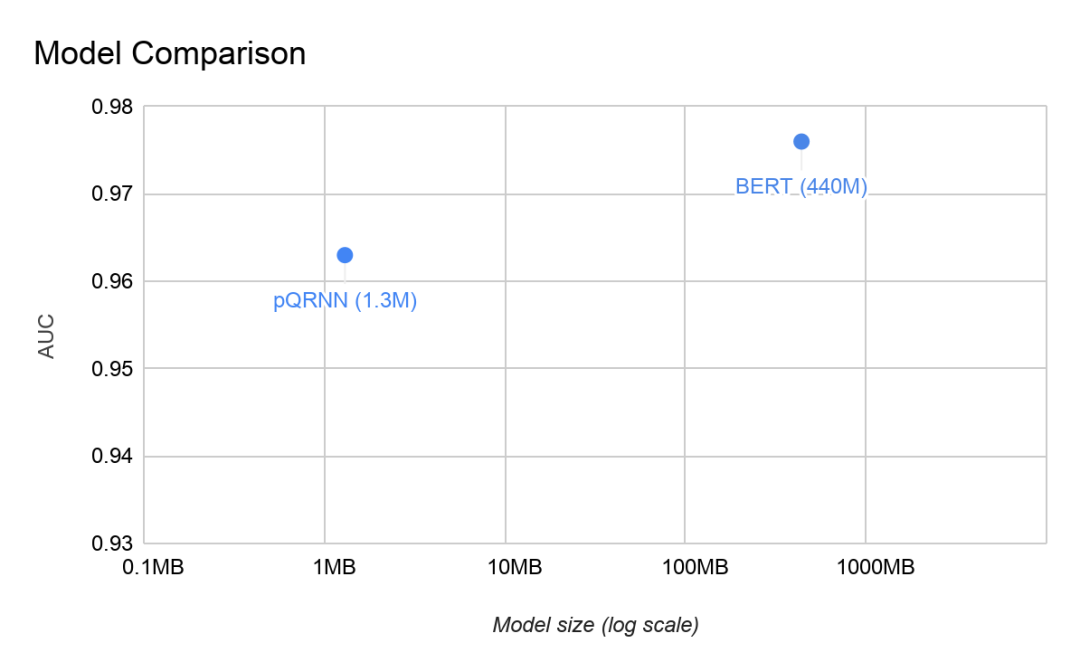
我们捕获了两个模型的曲线下面积 (AUC):在没有任何形式的预训练,只在监督数据上进行训练的情况下,使用 130 万个量化(8 位)参数,pQRNN 的 AUC 为 0.963。在几种不同的数据源上进行预训练,并在监督数据上进行微调,使用 1.1 亿个浮点参数,BERT 模型的 AUC 为 0.976
结论
我们用上一代模型 PRADO 展示了如何将其用作下一代最 SOTA 轻量级文本分类模型的基础。我们推出了 pQRNN 模型,并表明这种新的架构几乎可以达到 BERT 级性能,而使用的参数数量仅为原来的三百分之一,并且只在监督数据上进行训练。为了进一步推动这一领域的研究,我们现已开源 PRADO 模型,鼓励社区将其用作新模型架构的起点。
开源 PRADO 模型
https://github.com/tensorflow/models/tree/master/research/sequence_projection
致谢
我们感谢 Yicheng Fan、Márius Šajgalík、Peter Young 和 Arun Kandoor 对开源工作的贡献和对模型改进的帮助。我们还要感谢 Amarnag Subramanya、Ashwini Venkatesh、Benoit Jacob、Catherine Wah、Dana Movshovitz-Attias、Dang Hien、Dmitry Kalenichenko、Edgar Gonzàlez i Pellicer、Edward Li, Erik Vee、Evgeny Livshits、Gaurav Nemade、Jeffrey Soren、Jeongwoo Ko、Julia Proskurnia、Rushin Shah、Shirin Badiezadegan、Sidharth KV、Victor Cărbune 和 Learn2Compress 团队的支持。我们要感谢 Andrew Tomkins 和 Patrick Mcgregor 对研究项目的赞助。
更多 AI 相关阅读:






