旷视南京研究院魏秀参:细粒度图像分析综述
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
本文主题是细粒度级别图像分析领域的现状与展望,讲述者是旷视科技南京研究院负责人魏秀参博士。极市曾有幸邀请到魏博士进行细粒度图像识别的线上分享,分享视频与详情链接请戳:干货|魏秀参:针对细粒度图像任务的深度卷积特征选择与融合
本文来源:旷视MEGVII
主要内容包含 5 个方面:
1)简单介绍细粒度图像分析领域;
2)细粒度图像检索现状;
3)细粒度图像识别现状;
4)细粒度图像分析相关的其他计算机视觉任务;
5)细粒度图像分析发展展望。
介绍
在传统计算机视觉研究中,图像分析通常是针对诸如“狗”“车”和“鸟”等传统意义类别上的分类、检索。而在许多实际应用中,图像对象往往来自某一传统类别下较细粒度级别的不同子类类别,如不同种类的“狗”——哈士奇、阿拉斯加、比熊等;或不同种类的“车”——奥迪、宝马、奔驰等。
细粒度级别图像分析是针对此类问题的一项计算机视觉领域热门研究课题,其目标是对上述细粒度级别图像中的物体子类进行定位、识别及检索等若干视觉分析任务的研究,具有真实场景下广泛的应用价值。然而因细粒度级别子类别间较小的类间差异和较大的类内差异,使其区别于传统图像分析问题成为更具挑战的研究课题。
现实世界中有非常普遍的细粒度图像分析任务。比如美国大自然保护协会曾在kaggle举办的、针对捕鱼业中海船上若干种鱼类的细粒度分类,甚至还有根据鲸鱼尾部进行个体级别的更加细粒度的识别任务。此外,还有针对植物树叶的细粒度识别, 城市管理场景中对过往车辆的细粒度分析, 新零售场景中商品识别的细粒度识别和检索等等。
解决细粒度图像分析的一个关键是找到细粒度物体的Keypoints,利用这些关键部位的不同,进行针对性的细粒度分析,如检索、识别等。目前,细粒度图像分析领域的经典基准数据集包括:
鸟类数据集CUB200-2011,11788张图像,200个细粒度分类
狗类数据集Stanford Dogs,20580张图像,120个细粒度分类
花类数据集Oxford Flowers,8189张图像,102个细粒度分类
飞机数据集Aircrafts,10200张图像,100个细粒度分类
汽车数据集Stanford Cars,16185张图像,196个细粒度分类
细粒度图像分析一直是一个火热的计算机视觉研究方向。每年计算机视觉顶级会议如CVPR、ICCV、ECCV、IJCAI以及顶级期刊如TPAMI、IJCV、TIP等都有大量相关论文出现。此外,围绕这一方向还频繁举办相关Workshop和挑战赛,比如Workshop on Fine-Grained Visual Categorization、The Nature Conservancy Fisheries Monitoring、iFood Classification Challenge等。在细粒度图像分析领域,一些国际顶尖的研究机构,如斯坦福大学、加州伯克利、牛津大学皆是细粒度研究的科研重镇。
细粒度图像分析一般有两个核心任务,一是细粒度图像检索,二是细粒度图像识别。下面将分别进行重点介绍。
细粒度图像分析之图像检索
传统图像检索与细粒度图像检索
一般来说,图像检索包含了以文字搜图、以图搜图这两个搜索场景。这里着重讨论以图搜图,它也被称为Content Based Image Retrieval(CBIR)。
传统CBIR的通用流程是:先对输入图像进行特征提取,得到特征向量,进而将若干这样的特征向量组合成一个数据集。当进行到图像检索的过程后,同样,先对Query图像进行特征提取,然后将这个向量与之前收集到的数据集中的图像进行最邻近匹配,这样便可以从数据集中找到与Query图像相似的图像。
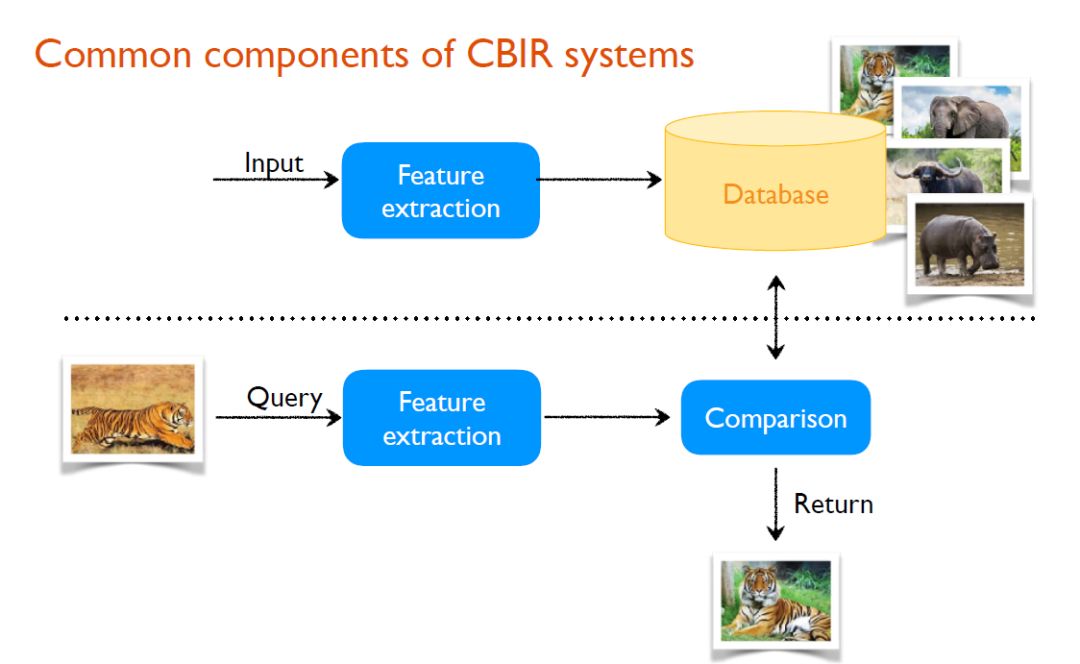
尽管图像检索这个领域到目前为止已有长足进步,但是它们大多都针对的是通用物体,比如在一些变化不会特别大的刚体之间搜索,如不同角度、光照下拍摄的埃菲尔铁塔、一些建筑物等等。
如果将这些系统用于更精细的场景,那么上述方法便显得力不从心了,如给定一只鸟的照片,让系统在两百多只各类鸟中找出同类的鸟。下图展示了细粒度图像检索与传统图像检索之间的差别。

显然,细粒度图像检索面对的问题比传统图像检索更加复杂,检索对象所处的环境背景变化、姿态变化以及scale变化都更为明显。因此,研究人员需要寻求新的方法来完成细粒度图像检索任务。
细粒度图像检索之SCDA
对于传统图像检索来说,只要让系统对图像的特征值进行对比,便可以得出结果,其中不存在任何的监督信息。然而对于细粒度图像检索而言,研究人员第一步需要通过无监督的方法将输入图像中的主要信息定位出来,从而防止背景或图像中噪声区域的干扰。
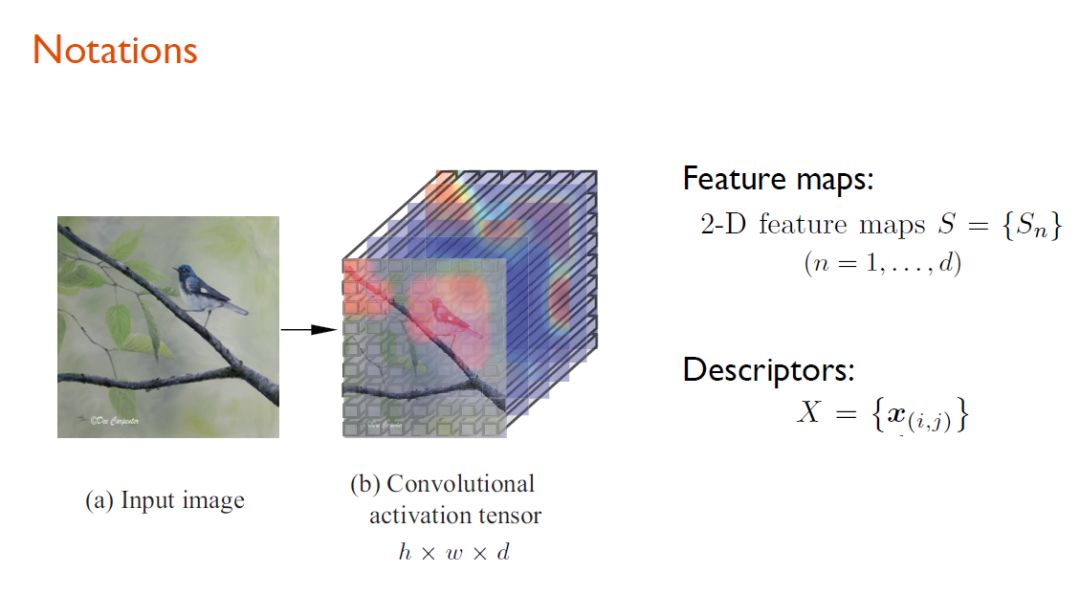
在深入到具体模型之前,先介绍涉及到的重要Notation。
当输入图像进入预训练的CNN模型之后,可以得到一个卷积激活tensor。需要说明的是,这里使用的预训练的分类模型,只见过图像级别的标注,没有见过诸如边界框这样关于位置的标注信息。
特征图(Feature map):在得到卷积激活tensor之后,每一个 h×w 的map就是一个特征图,这也被称为一个通道(channel)。
深度描述子(Descriptor):在得到卷积激活tensor之后,可以得到 h×w 个 d 维的向量,这里把这样的一个 d 维的向量称为深度描述子(Descriptor)。它描述的是原图中对应的小patch的信息。
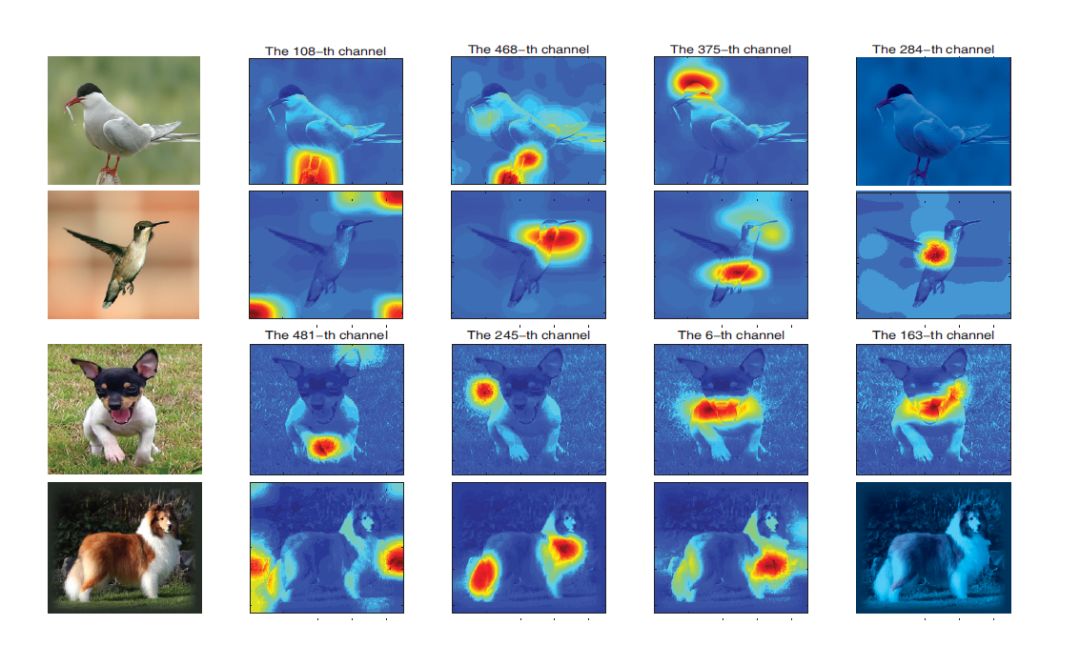
在对每一个channel进行可视化研究的过程中,研究人员发现了两个现象:
(1)对于不同鸟类而言,同一channel的激活情况可能大不一样。之所以会出现这一现象,其原因或许与深度学习的分布式表征本质有关。
(2)对于同一鸟类而言,不同channel所激活的部位大不相同,有的激活部位与鸟有关,有的则无关。
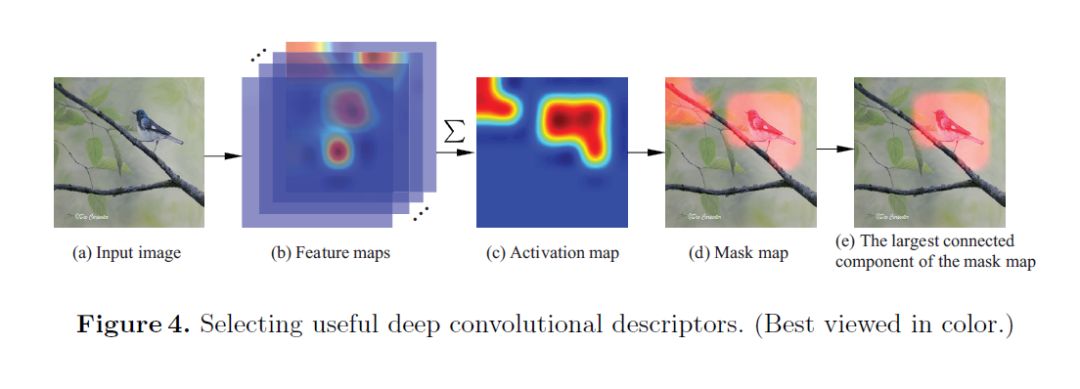
因此从上面的观察能看到,使用全部channel或许会引入噪声,而仅使用某个channel来定位主要物体也是不理想的。于是,研究人员决定把得到的所有特征图从深度方向进行加和,从而得到一个2D的激活图。需要说明的是,这里进行的加和操作依据了如下假设,即如果主要物体出现在了图中,那绝大多数channel都应该在主要物体出现的位置产生激活。因此,如果加和的部分大于其均值,那么系统便会判定这里可能是目标物体出现的空间。
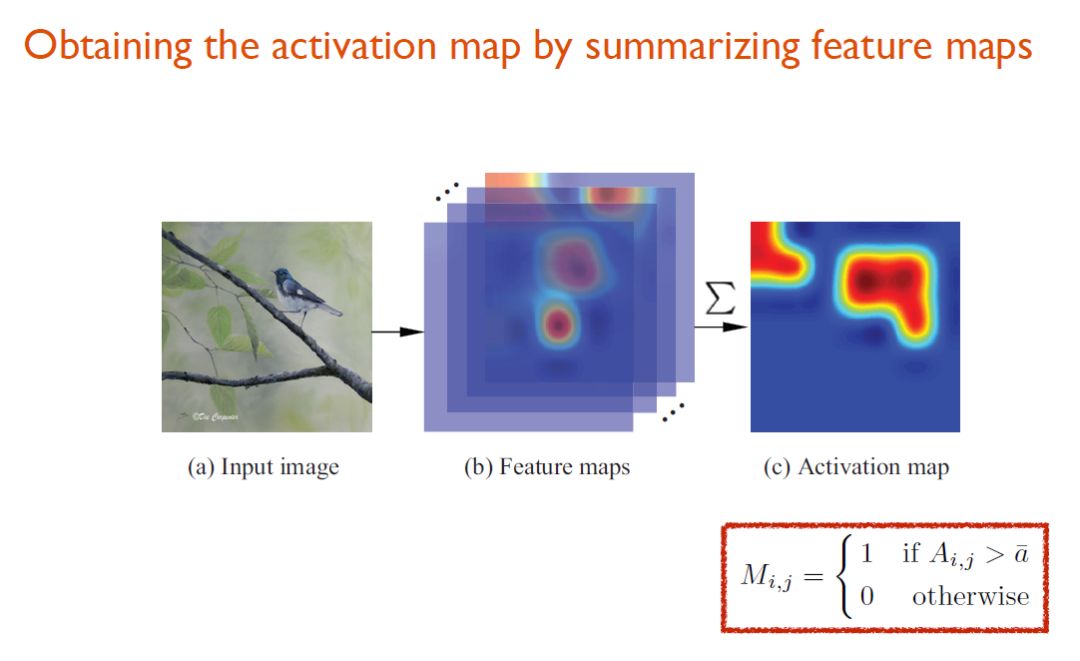
依据这种无监督定位的方法,系统已经可以初步将目标物体从背景中分离出来。不足的是有一些背景或噪声信息也被标记了出来。对此,研究者利用了flood-fill的算法保留主体的定位结果,而较小区域的噪声或背景则被摒弃。
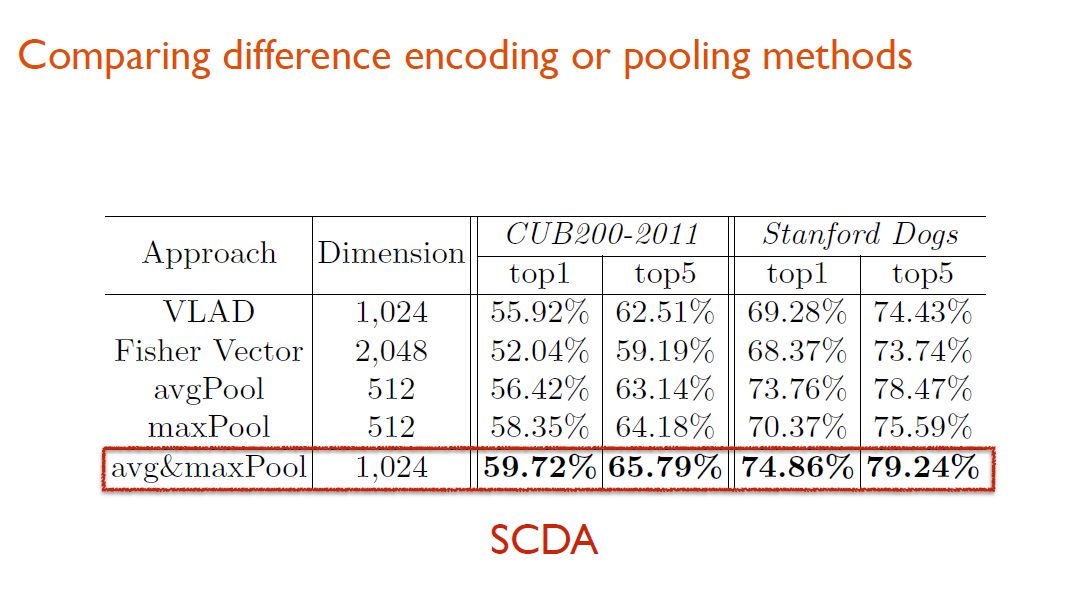
之后,研究人员基于无监督定位的结果,保留了有效的深度描述子,同时去除背景或噪声区域深度描述子的干扰,接着对保留下来的描述子进行了融合。在进行融合操作时,研究人员尝试了下图中的三种方法。

通过将这三种方法在两个benchmark数据集(CUB200-2011、Stanford Dogs)上进行对比实验,研究人员发现,将avgPool和maxPool进行级联可以获得最佳性能。这种经过级联筛选以后得到的特征被称为SCDA。
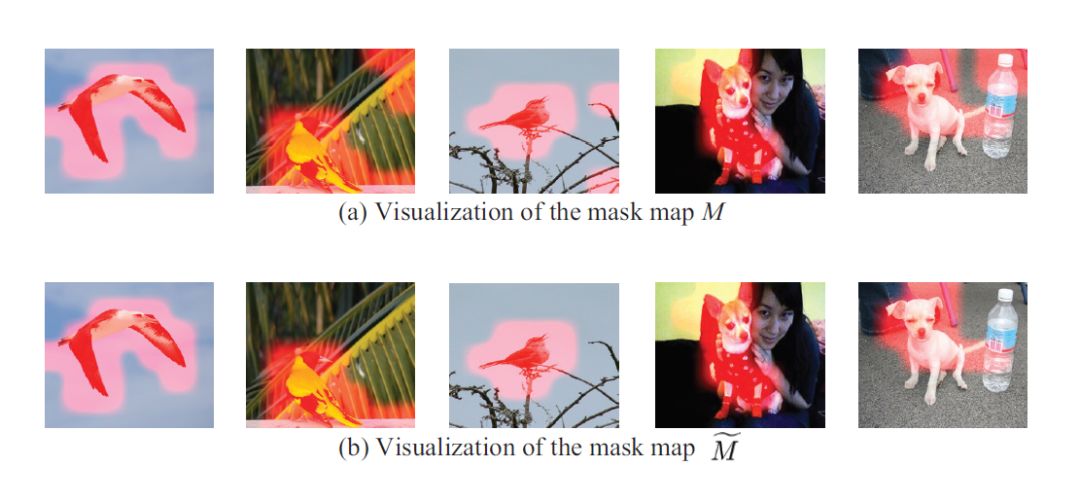
从结果来看,系统现在基本上可以准确地定位物体。
SCDA算法整体流程图
以下是一些定性比较结果,通过将算法无监督定位的结果与ground truth相比,可以发现,二者基本重合,模型的效果比较理想。

红色虚线为ground truth结果,黄色为SCDA算法标注结果
此外,研究人员还对SCDA方法进行了加强。

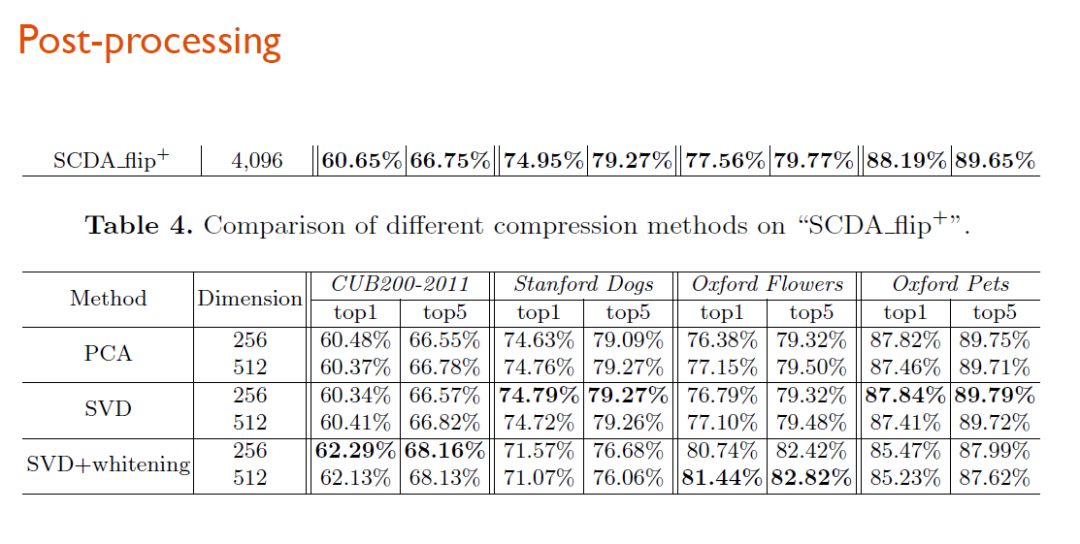
最终测试结果显示,SCDA方法与其强化方法SCDA+、SCDA_flip+在性能上都超越了现有的所有模型。
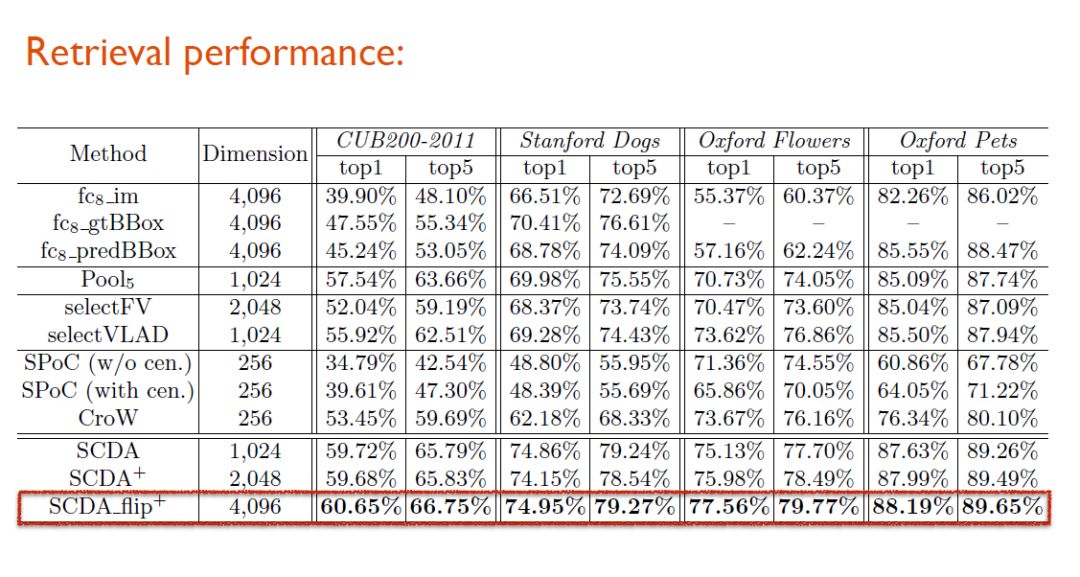
当研究人员使用3种后处理方法(PCA、SVD、SVD+whitening)对SCDA_flip+进行进一步加强(256维),它甚至可以拿到比4096维更高的性能表现。
细粒度图像检索之DDT
在上述提到的SCDA方法中,对于每张图而言,都有一个自适应的threshold来对每张图中的物体进行定位。而在真正进行物体定位的时候,人们拿到的往往可能是一批图像,而不是单张。所以我们自然的会希望借助整个图像集合的信息,也就是图像与图像之间的协同信息来做好物体定位。这便对应到了计算机视觉领域的另一个基础研究课题——物体协同定位 Object Co-Localization。在物体协同定位中,我们唯一依靠的信息是“这个集合中的图像都有某个共同物体”,对于“共同物体”到底是什么,甚至都不需要知道。
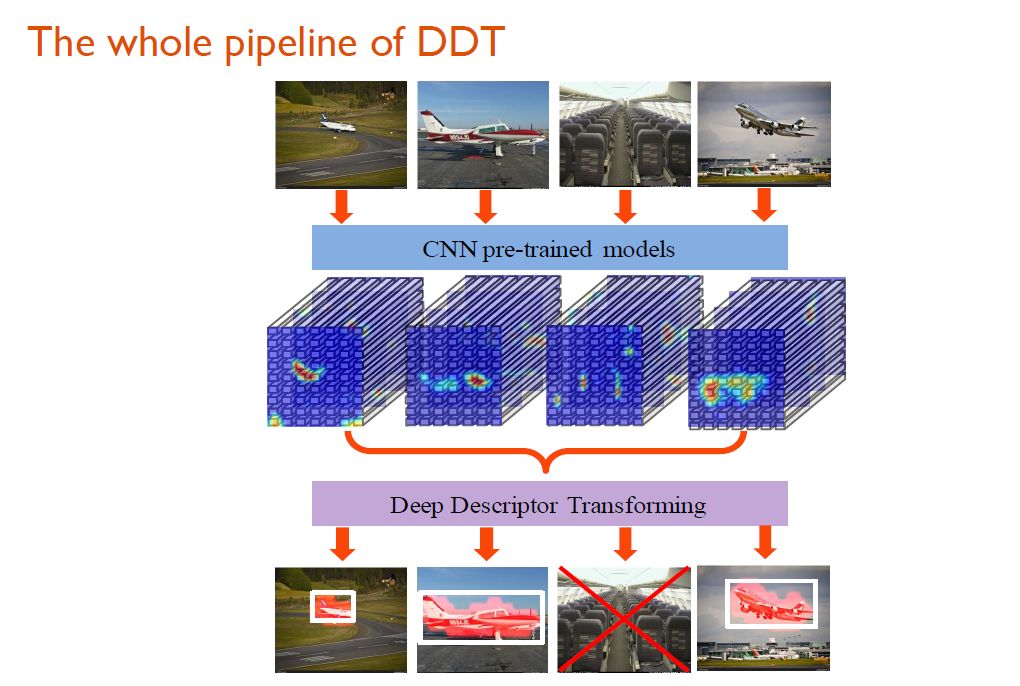
在协同定位的场景下,人们期望借助整个图像集合中所有图像之间关系的信息,由此做好物体的定位。研究人员提出了一个DDT(Deep Descriptor Transforming)方法。与SCDA方法类似,在DDT方法中,属于同样语义的图像一开始会被送入一个预训练的CNN分类网络,得到对应的一些tensors。
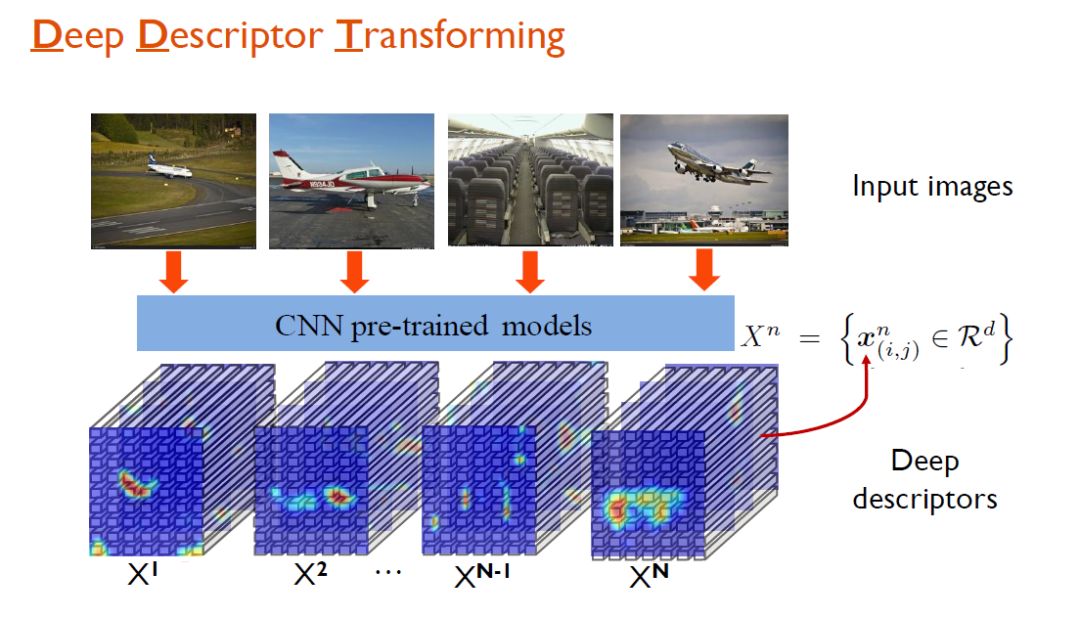
对于这些tensors,研究人员需要衡量的是其中每一个描述子的相关程度。其实我们需要的仅仅是一个映射函数:将深度描述子从自身空间映射到一个新空间。在新空间中可方便衡量深度描述子的相关程度。如果结果呈现正相关,那表示这些描述子具有跨图像的物体描述效果,如果负相关,那么说明这些描述子只和某一张图像相关,不具备通用的描述效果。显然,在DDT的方法中,threshold天然为一个定值:0。
为了实现这一映射目标,研究人员使用了PCA矩阵分解技术,即通过一组正交变换,将一组可能存在相关性的变量转换成一组线性不相关的变量。
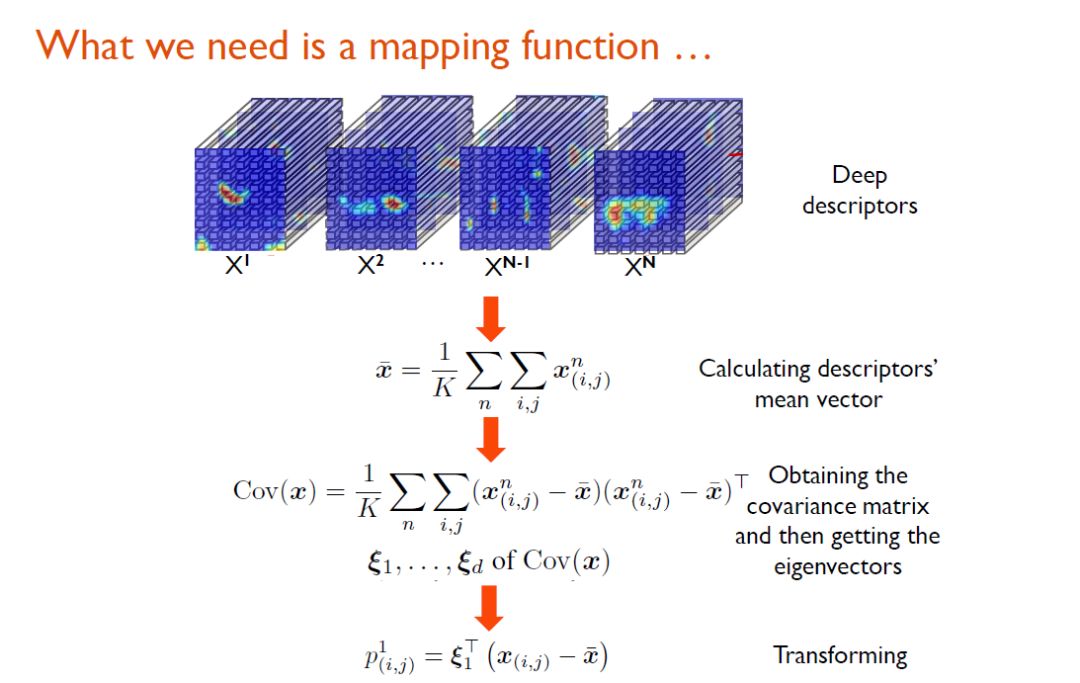
需要注意的是,这里仅仅需要PCA的第一维,将这一维当作映射函数。通过这种方法,每一个d维的深度描述子就可以转化到一个新空间,这个新空间的维度仅仅为1。在该空间中,我们就可以用映射后得到的score衡量描述子之间的相关程度了。
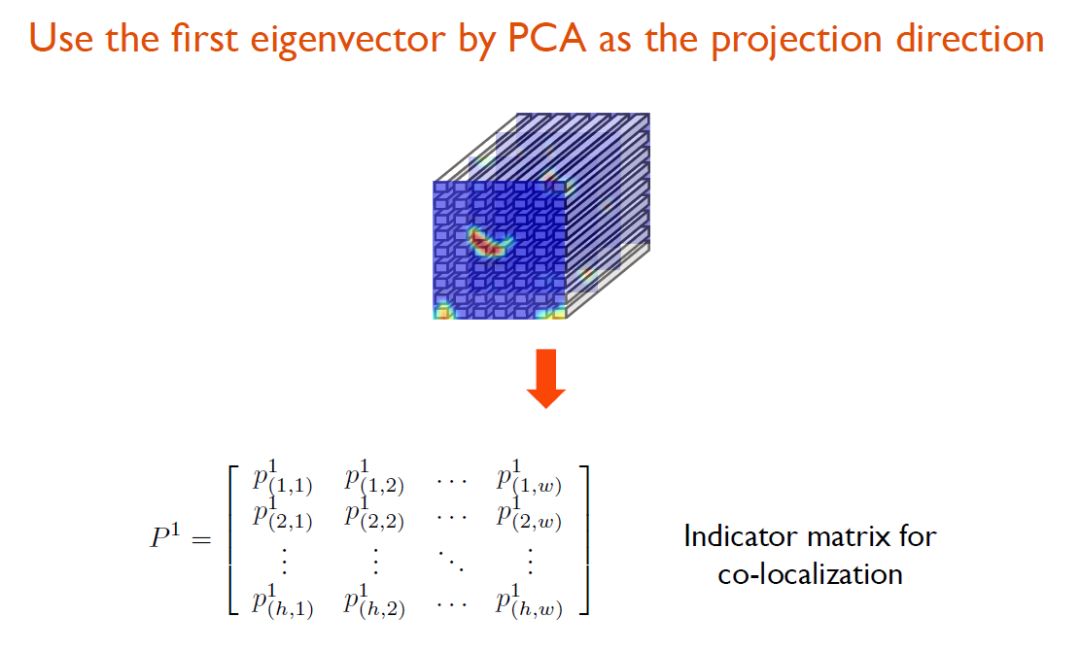
因此,在DDT方法下,系统可以根据多张图片的协同信息,将物体定位出来。另外,由于PCA本身具有去噪的效果,所以它可以很好的剔除掉不相关的噪声图片。以下图为例,飞机内部虽然与飞机本身的语义相关,但在图像上该它并没有出现飞机的任何外貌特征,所以对应于这张图的indicator matrix全为负值,即表示这张图属于噪声信息,需要被剔除掉。
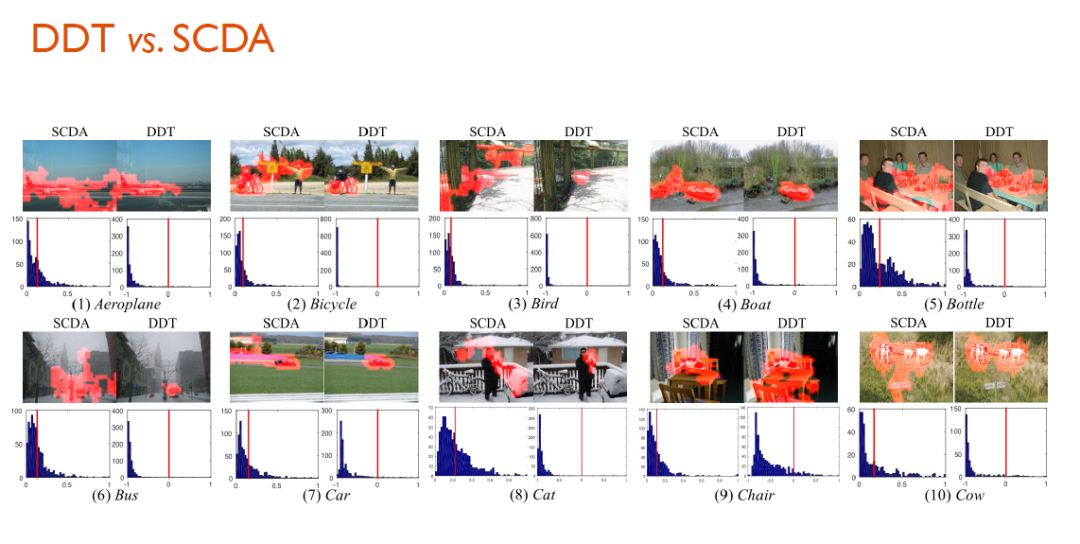
DDT与SCDA性能对比
根据下方对比图可以发现,由于SCDA只是从单张图像拿到信息并进行无监督物体定位,因此它有可能将我们不关心的类也标注出来。而对DDT方法而言,由于它是从多张图片中协同获取信息,所以它能够精确的定位出我们关心的物体位置。
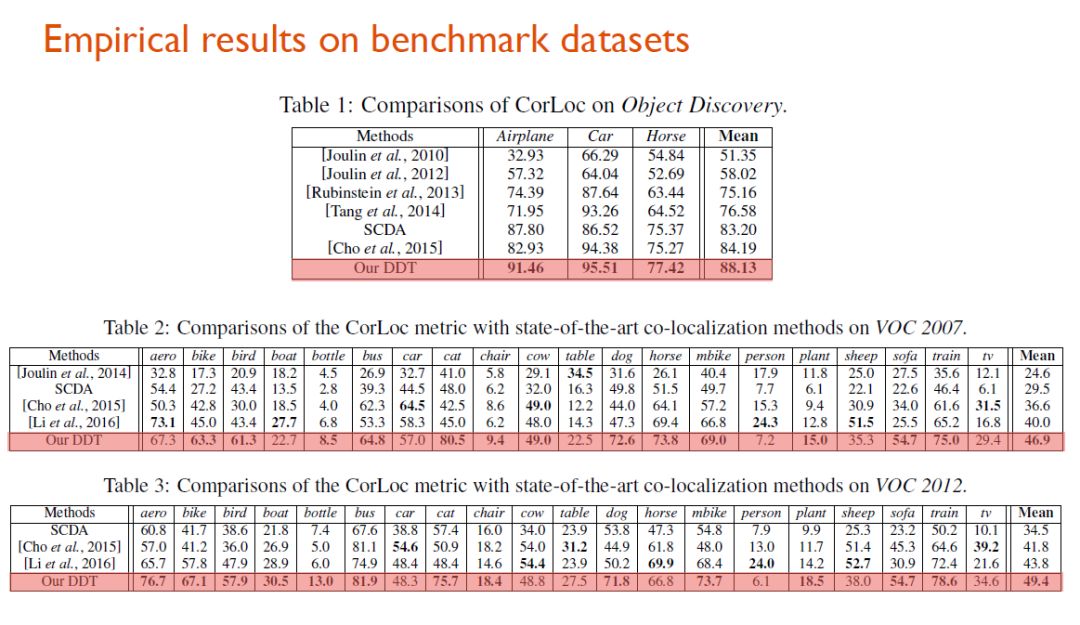
研究人员将两个模型在4个数据集上进行了效果对比。

前三个数据集的测试结果显示,DDT方法显著超越之前的所有方法。
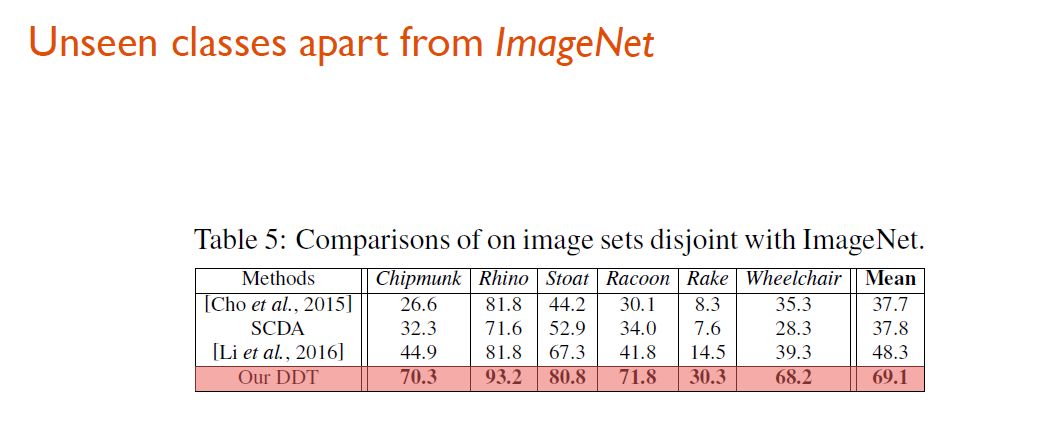
对于ImageNet而言,比较特殊,因为DDT模型使用了基于ImageNet预训练的CNN模型,所以为了观察模型的泛化能力,就必须选择不包含在ImageNet那1000类中的物体类作为测试集。于是研究人员选择了6个不属于ImageNet的类来测试DDT的协同定位效果。结果显示,在面对这些未见过的类别时,DDT算法显著好于其它所有算法。
下图展示了可视化的结果。

细粒度图像分析之图像识别
Mask-CNN细粒度图像识别基本思想
细粒度图像识别也可以被称为细粒度图像分类。在进行细粒度分类时,研究人员借用了做图像检索时的思想,即“定位主要物体,去掉无效描述子(describetor)”。后续实验可证实,基于深度描述子筛选的思想不仅有利于细粒度图像检索,对细粒度图像识别同样大有裨益。
具体而言,研究人员通过对分析对象添加keypoints,进而生成keyparts,从而生成有关ground truth的边界框。

然后,研究人员用生成的边界框来训练一个分割网络,学习针对物体的mask。
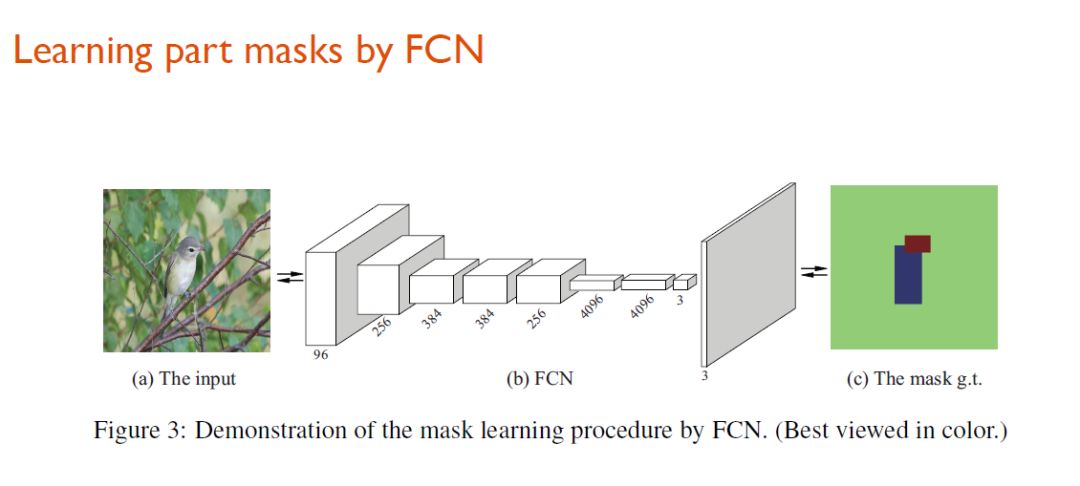
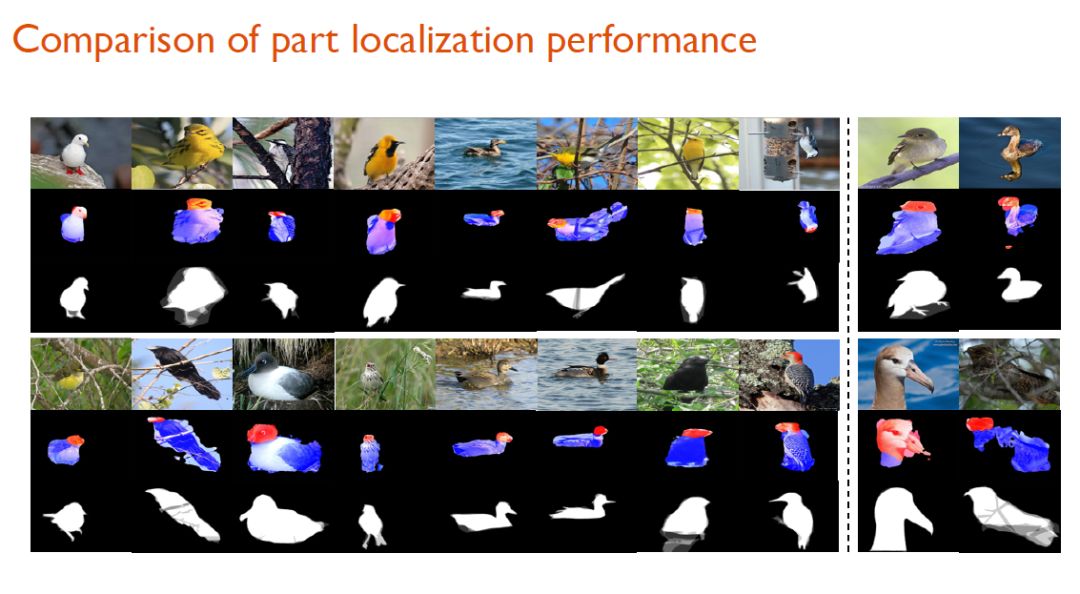
keypart定位效果示意
进一步,研究人员根据习得的mask,生成了对应物体整体、头部、身体的三个网络。他们在这些网络的最后一层卷积tensor上进行对应的深度描述子筛选与融合。最后,通过将融合的结果进行级联,研究人员便可以让模型做最后的细粒度识别任务。

这种细粒度识别方法也超越了当时同类的所有模型。
有关细粒度图像分析的真实应用
应用1:RNN-HA车辆细粒度识别模型
对于车辆的细粒度识别而言,难度较大。因为往往同类车辆之间的差异十分微小,比如对于下图的两辆奥迪A6来说,其外貌完全一样,不同之处可能仅仅在于其之上的年检标志,或者是车内某些小装饰。
面对这个难题,研究人员从人类识别的认知逻辑出发,尝试找到突破口。他们发现当人类在进行车辆细粒度识别时,经历了两个过程:判断车型→同种车型精细对比。
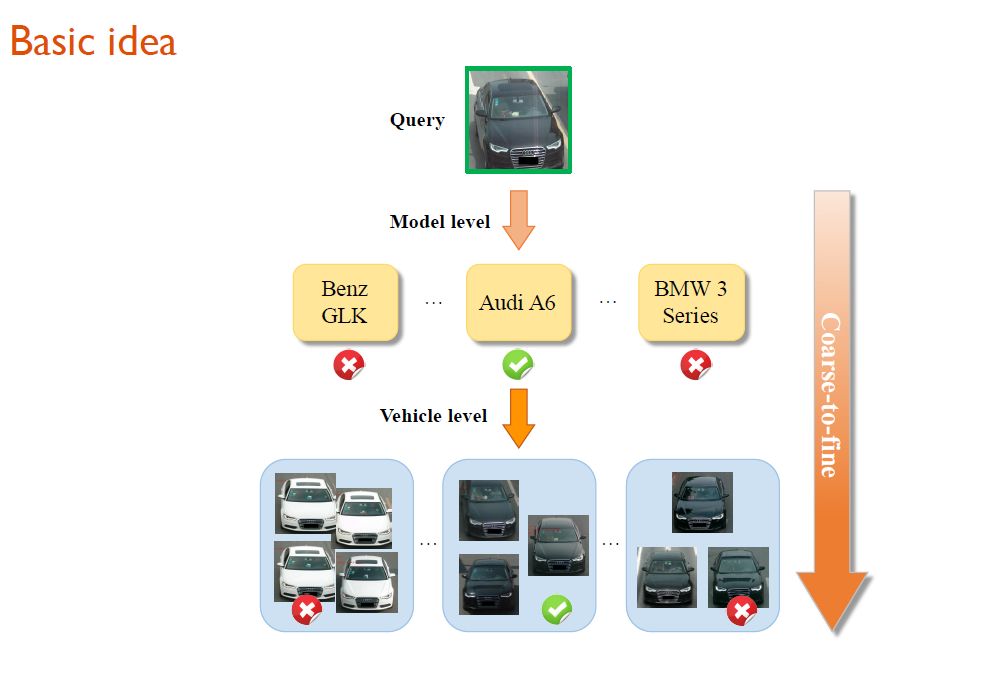
在这个思路的启发下,研究人员设计了RNN-HA模型。
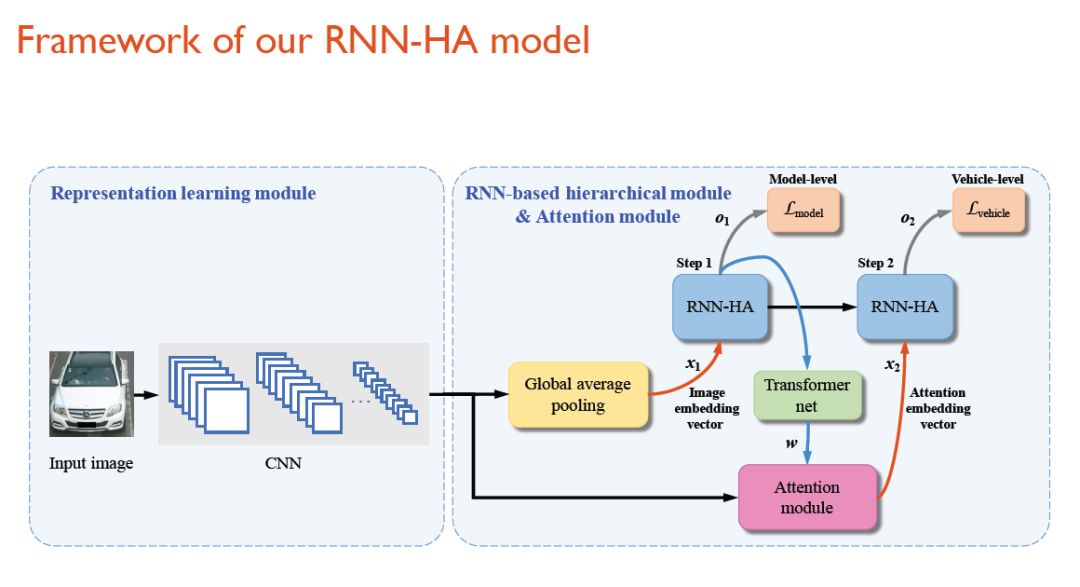
在上述模型中可以看到,获取输入图像信息以后,一个CNN网络将首先对图像进行特征抽取,得到一个卷积tensor。
随后,在step1阶段,模型先对车型进行分类(即图中右侧所示的Model-level)。我们可以把这看作一个初步的细粒度识别过程。
当车型分类完成以后,模型会首先对输出结果做一个Transformer net的变换,生成一个注意力模型,然后才在Step2中,根据得到的注意力嵌入向量判断应该在同样的物体类别(如都是奥迪A6)中观察哪些地方,从而才能将同属这个类别的车辆分开。
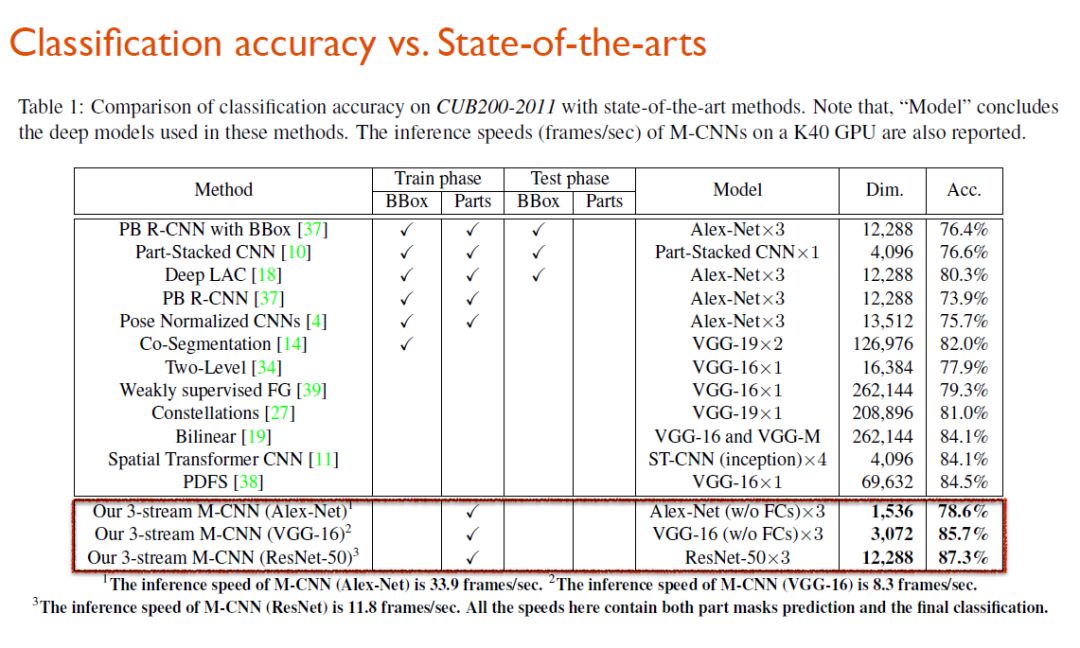
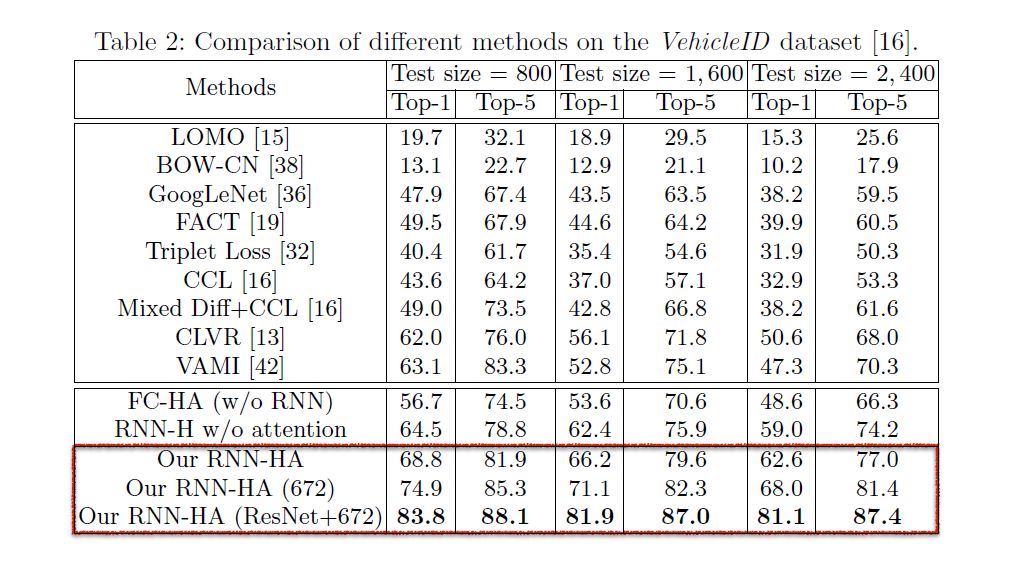
研究人员将该模型在两个权威的数据集VeRi(50, 000 张图,776种车辆)、VehichleID(221, 763张图,26267辆车)上进行了实验。结果显示,在这两个数据集上RNN-HA都超越了当前最优的方法。
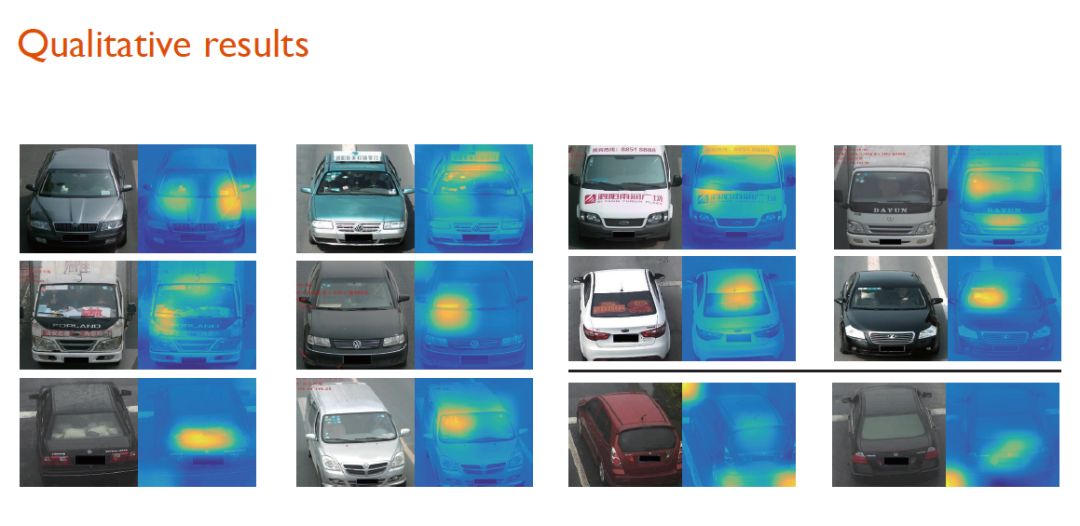
下图展示了车辆细粒度识别的部分可视化效果。可以看到,系统准确抓住了车辆上细微的区分标识(装饰物、年检标识等)。
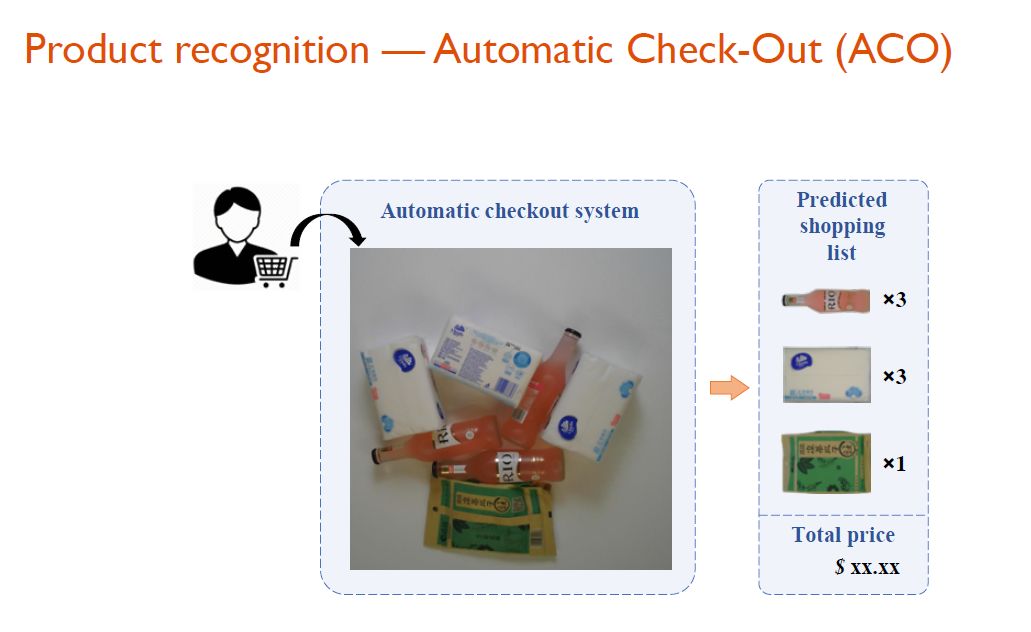
应用2:新零售场景下的自动商品结算
零售业是人力密集型行业,其中收银结算占有相当高的成本。随着深度学习发展,借助图像识别技术实现零售行业的降本增效已是大势所趋。自动收银结算(Automatic Check-Out/ACO)是其中的核心场景,旨在根据收银场景图像生成结算清单,并与计算机视觉技术的融合不断加深。
CV 技术+场景,从来不是一条坦途。从图像识别角度讲,ACO 的落地布满荆棘,其中既有来自数据本身的问题,也有模型训练的因素,最后可归结为 4 个方面: 1)large-scale,2)fine-grained,3) few-shot 和 4)cross-domain。
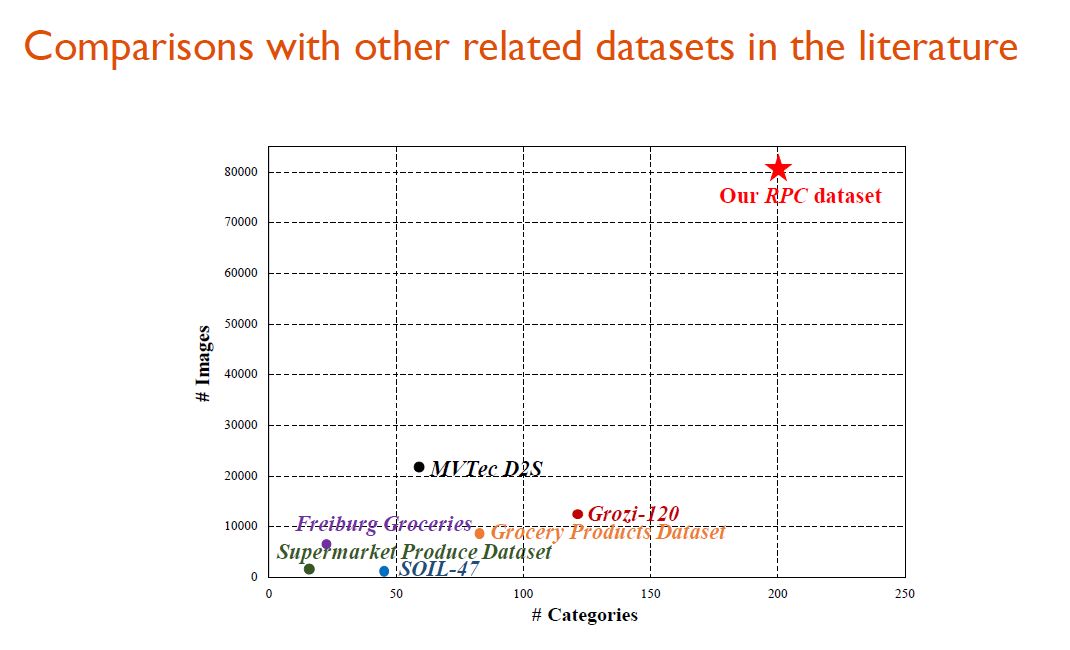
尽管存在上述问题,ACO 还是有着潜在的研究与商业价值。如果有标注精良的数据集,这一问题或可迎刃而解。为此,研究人员打造了一个目前最大的商品识别数据集——RPC(Retail Product Checkout),来推动新零售自动收银场景的相关研究和技术进步,它的商品种类高达 200,图像总量达 83k,真实模拟零售场景,且逼真度超过现有同类数据集,同时充分体现出 ACO 问题的细粒度特性。从下图可以看到,对于同一个大类的商品而言,其子类的商品差异度并不大,所以这是一个天然的细粒度识别问题。
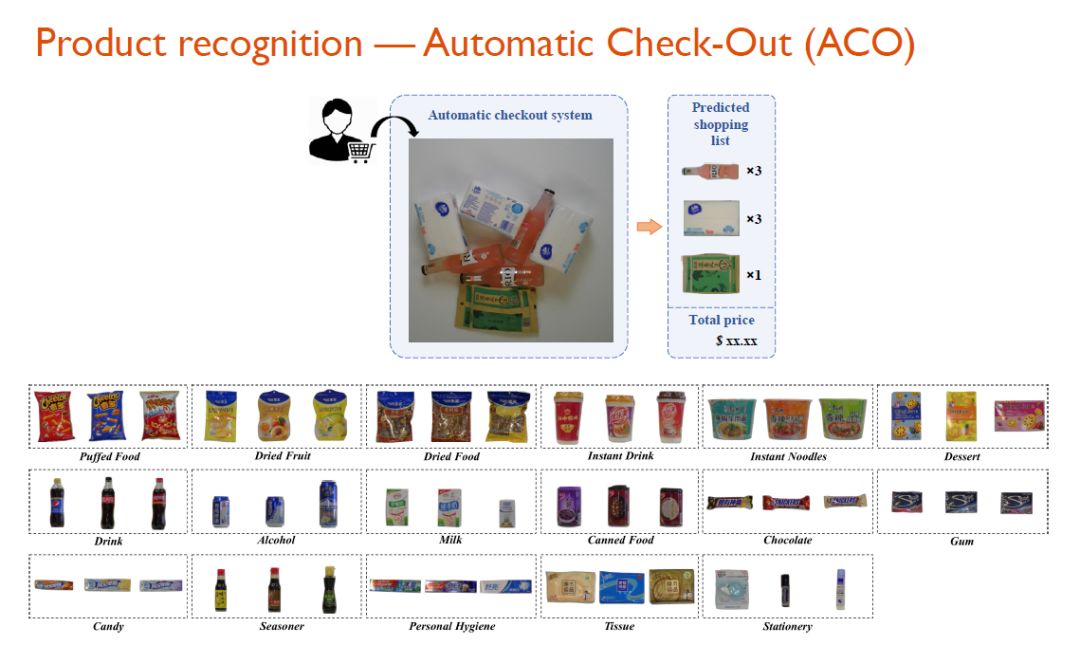
需要说明的是,这里的RPC数据集在商品种类和图像数量上都远超现有的同类数据集。
在进行具体的商品数据收集之前,研究人员首先对商品在结算时的摆放模式进行了分级,分为「简单」、「中等」、「困难」三种模式。

在收集商品的图像数据过程中,研究人员将单个商品置于一个旋转的台面,拍下其各方位的图像。该过程模拟了真实商店进行商品录入的过程。
研究人员期望,基于这些单品示意图,开发出能够在上述3种商品摆放模式中准确识别商品种类并计数的模型。

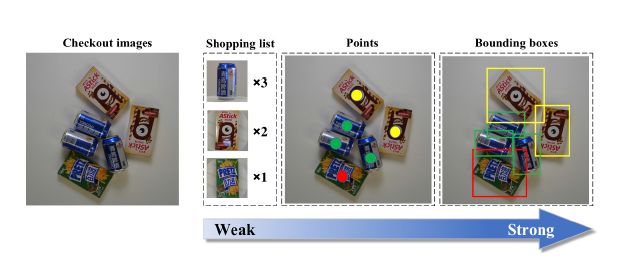
另外,研究人员也为每一个结算图像分别添加了三种不同强度的监督标签,从弱到强,最强的是边界框,其次是点,最弱的是仅仅给出图中出现的购物单。
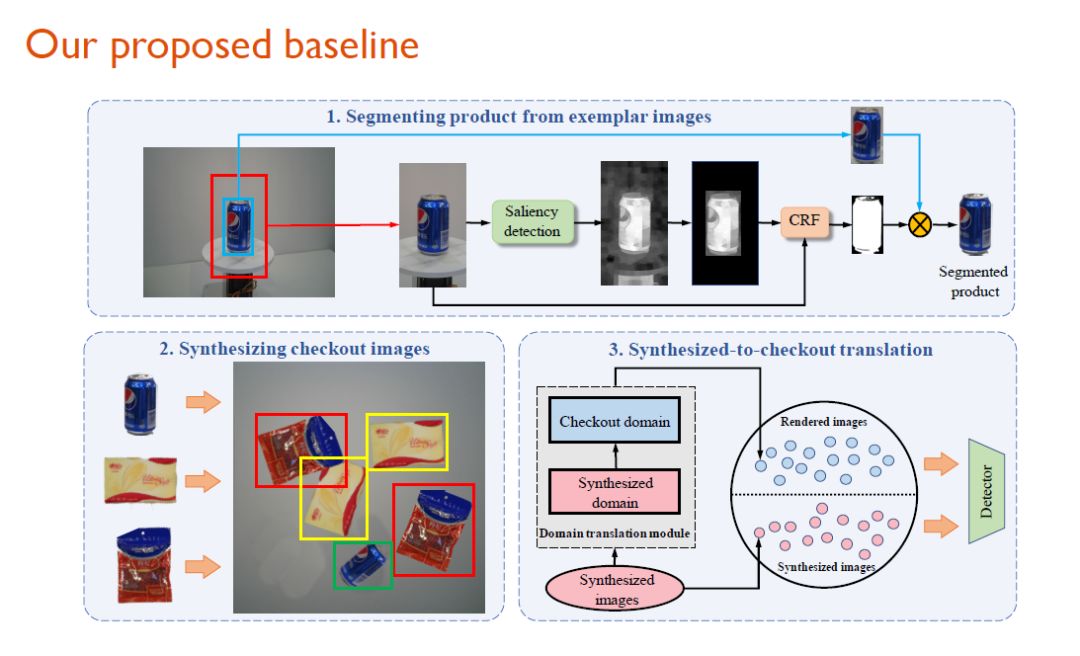
基于“单品图作训练、结算图作测试”的思想,研究人员提出了一个baseline方法。具体而言分为三步,先通过Saliency detection和CRF将商品从原始数据中抠出来。
然后利用自动合成方法,将这些商品图像直接在结算背景上进行组合。自然地,合成系统也可以为商品加上边界框。
由于这样合成的结果不够真实,所以研究人员在第三步使用了渲染方法,把合成图转换成接近真实的图像。
最后,研究人员用渲染以后的图片来训练detector。
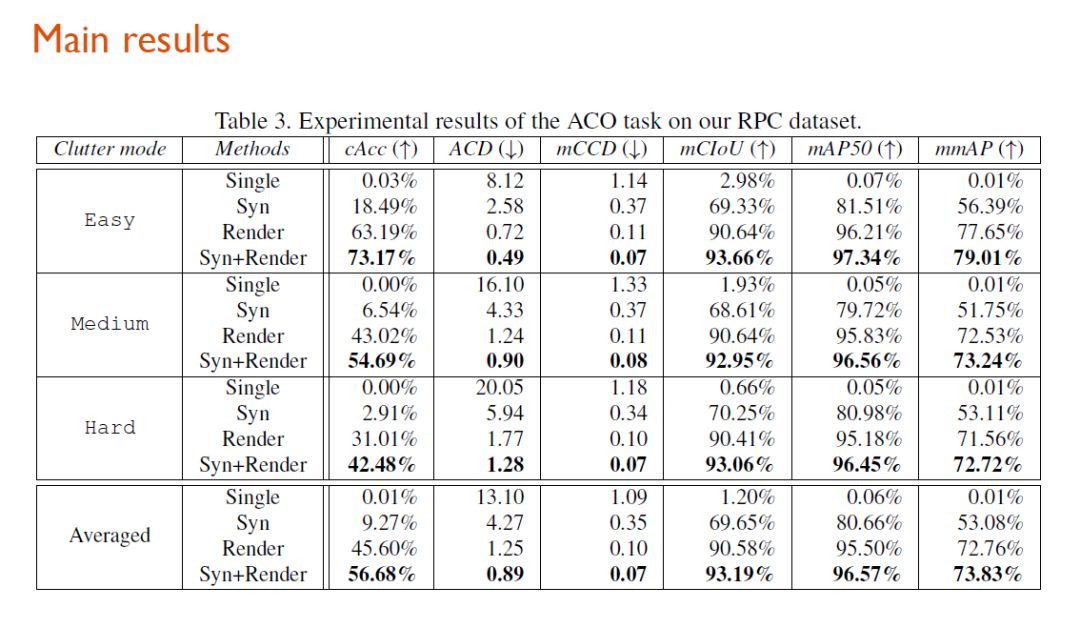
从baseline的结果来看,虽然detection任务做得很好,但是就ACO任务最关心的整单正确率(cAcc)来说,还有非常大的提升空间,这也鼓励更多相关研究人员来进一步设计新的视觉算法来解决这一问题。
细粒度图像分析发展展望
少量样本细粒度图像识别
目前所有细粒度图像识别任务均需借助大量、甚至海量的标注数据。对于细粒度图像而言,其图像收集和标注成本巨大。如此便限制了细粒度研究相关的发展及其在现实场景下的应用。反观人类,我们则具备在极少监督信息的条件下学习新概念的能力,例如,对于一个普通成年人可仅借助几张图像便学会识别鸟类的一个新物种。为了使细粒度级别图像识别模型也能像人类一样拥有少量训练样本下的学习能力,研究人员提出并研究了细粒度级别图像识别的少量样本学习任务。
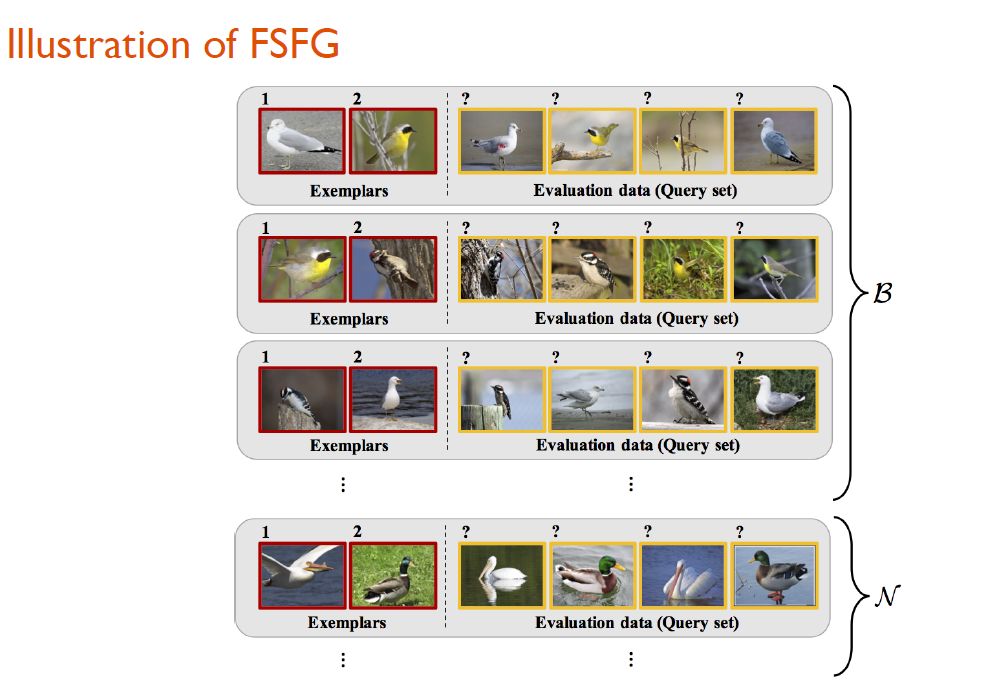
所谓少量样本细粒度识别,即通过让系统在少量样本上学习,从而在测试数据上达到较好的细粒度识别效果。以下图为例,整个灰色区域被称为一个“episode”,类似于传统深度学习的一个batch。系统通过在名为“1”、“2”两只鸟的训练数据上进行训练,进而对后面的evaluation data展开识别。

在模型的训练过程中,研究人员设计了一种Meta-learning的fashion。他们借助一个辅助数据集进行类别与图像的采样,并希望以这种方法来模仿测试集上真正要执行的任务。基于这个辅助数据集,研究人员构造出了若干类似于上图中测试数据的episode。系统通过对每个episode的样本进行学习,可以得到一些分类器或者是特征向量,进而可以在evaluation data上产生loss。借助这种方法,系统可以学习到一个在测试数据集上泛化能力较好的网络。
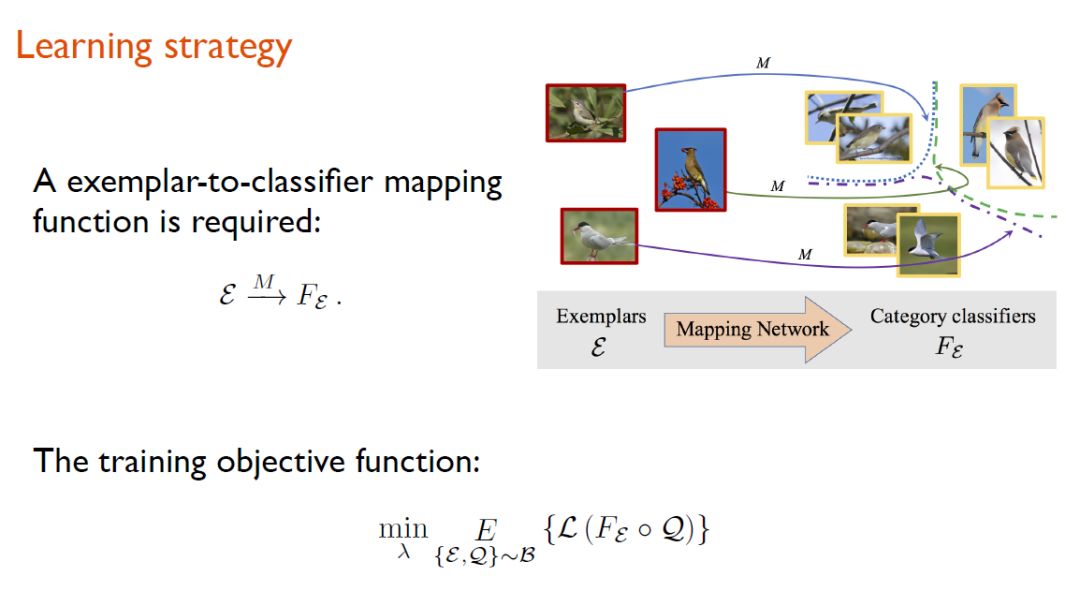
就具体的学习策略而言,研究人员希望系统直接根据输入图像学习到一个映射,映射的对象就是这个输入图像所属类别的分类器(classifier)。当系统学习到classifier以后,便可以对evalutation data进行分类。
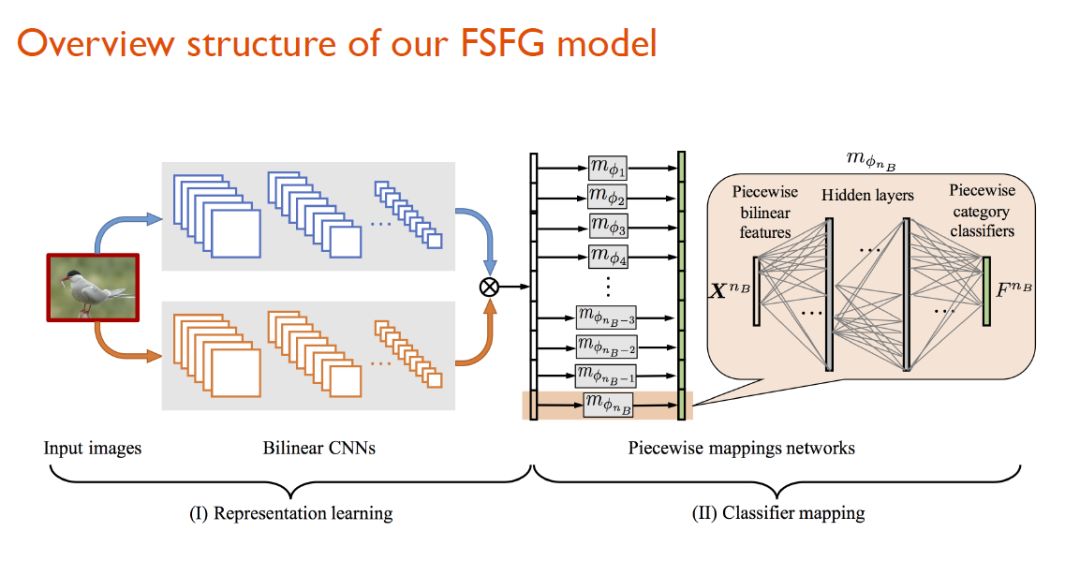
在FSFG框架中,研究人员首先提出了一个基于Bilinear CNN的方法,通过它,系统可以隐性的学到输入图像的一些part信息,进一步,这些part所对应的sub-vector可能就与物体细粒度层面的一些keyparts相关。
随后,研究人员分别对这些sub-vector进行分段映射,分段映射所对应的便是那些子分类器(sub-classifier)。通过将这些子分类器进行级联,系统可以学到有关整个物体的分类器。
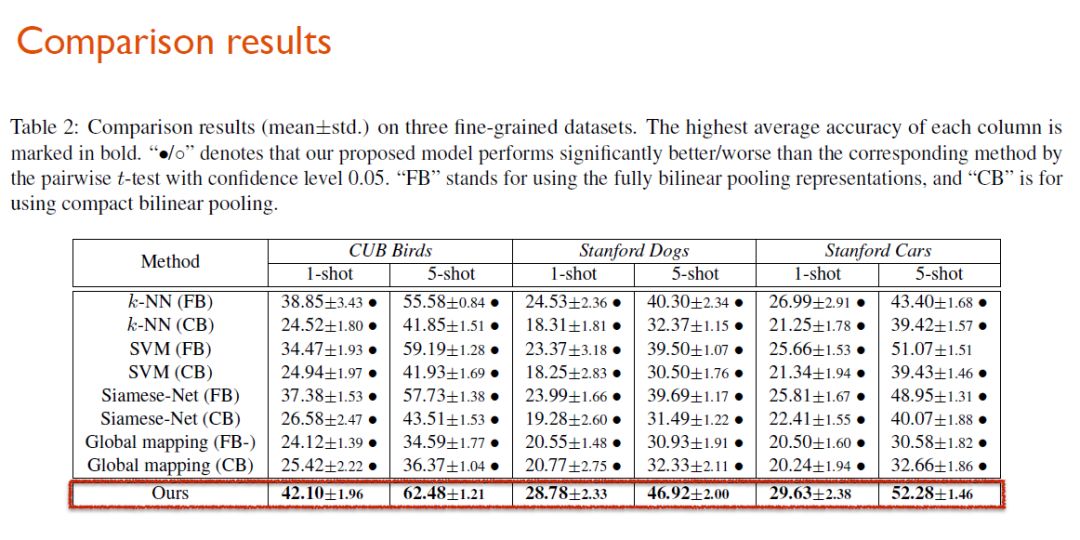
最后,研究人员将习得的模型在3个主流的细粒度图像数据集(CUB Birds、Stanford Dogs、Stanford Cars)上进行了性能验证,发现其达到了目前最先进的水平。
---------解读者介绍-------
魏秀参,博士,旷视科技南京研究院负责人,南京大学学生创业导师。主要研究领域为计算机视觉和机器学习,在相关领域顶级期刊如IEEE TPAMI、IEEE TIP、IEEE TNNLS、Machine Learning Journal等及顶级会议如ICCV、IJCAI、ICDM、ACCV等发表论文十余篇,并获得国际计算机视觉竞赛冠、亚军各一次。著有《解析深度学习——卷积神经网络原理与视觉实践》一书。曾获CVPR 2017最佳审稿人、南京大学博士生校长特别奖学金等荣誉,担任ICCV、CVPR、ECCV、NIPS、IJCAI、AAAI等国际会议PC member。
*延伸阅读
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

觉得有用麻烦给个好看啦~


