【Scientific Reports】《多中心影像诊断的联邦学习:心血管疾病的模拟研究》

引言
-
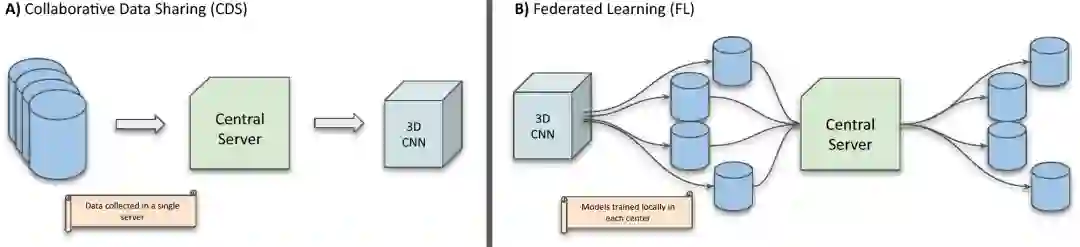
据我们所知,我们提出了第一个关于CMR诊断的联邦学习研究,并证明FL的性能可与CDS相媲美,同时保护了病人隐私。 -
我们提出了一种技术,通过利用地面真相掩模来诱导模型的不同先验,说明了一种有效的方法来约束解决方案的空间,并在两种协作学习设置中提高基于深度学习的多中心CMR诊断的性能。 -
我们应用一组不同的数据增量来人为地增加数据规模,并以一种原则性的方式研究它们对协作学习框架的影响,用不同的CNN权重初始化重复实验,以获得对模型鲁棒性的估计。我们还测试了FL算法在此背景下的一个变体,即给训练数据中的所有中心分配相同的投票,并表明它在某些情况下是有益的。 -
最后,通过使用两种不同的重复交叉验证设置--一种是将所有中心的一部分作为每个折叠的测试集,另一种是将整个中心作为每个折叠的测试集--我们得到了对现场和场外性能的估计,表明这两者有很大不同,并强调了它们对未来诊断研究的重要性。 -
为了促进该领域的未来研究,我们为研究界提供了我们的代码。
专知便捷查看
便捷下载,请关注专知人工智能公众号(点击上方蓝色专知关注)
后台回复“FLMID” 就可以获取《【Scientific Reports】《多中心影像诊断的联邦学习:心血管疾病的模拟研究》》专知下载链接



登录查看更多
相关内容

Arxiv
0+阅读 · 2022年11月22日

相关VIP内容
相关资讯