学界 | 人工智能告诉你如何组队发文章?KDD 2018 论文提出多元多类型集合的表征学习方法
AI 科技评论按:在即将召开的数据挖掘顶会 ACM SIGKDD 2018 上,圣母大学计算机系 DM2 研究团队(DM2 Laboratory, CSE, University of Notre Dame)的论文《Multi-Type Itemset Embedding for Learning Behavior Success》被主会录用。本文作者为圣母大学计算机系 DM2 研究团队三年级博士生王达恒,导师是圣母大学计算机系助理教授蒋朦。
Multi-Type Itemset Embedding for Learning Behavior Success(ACM SIGKDD 2018)
DM2 Laboratory, CSE, University of Notre Dame (圣母大学计算机系DM2研究团队)
引出问题
对于博士学生来说,如何提高科研质量和产量一直是学术生涯里的中心话题。相较于高年级的博士生而言,刚踏入科研领域的低年级博士生往往由于缺乏足够的知识积淀与经验,对于估计论文中稿的可能性与找出提高中稿率的办法显得力不从心。我自己作为一名刚刚跨过第二个学年的博士生,对这一点的体验格外深刻。
理想情况下,当我们开始一个新的以论文发表为导向的研究项目的时候,我们希望拥有合适的研究团队(其中包含多个技能互补的学者与专家),足够清晰的研究问题,科学合理的研究方法,以及定位恰当的目标会议。但在现实中,我们往往很难在一开始就达到这样的配置。那么我们能否利用人工智能来从大量的成功经验(以往成功发表的论文)当中建立起预测模型来帮助我们判断呢?更进一步地,我们是否能够让人工智能算法给我们推荐能够提高论文中稿率的办法呢?是否邀请自己院系当中的另外一位教授参与进来就能够大大地提高项目成功的可能性?或者说有哪些优秀的文章值得一读、甚至必须一读,以提高论文中稿率?这些都是非常实用且有趣的问题。
问题难点
客观上来说,每一篇学术论文都是一个非常复杂的行为产物,包含了多种不同类型的上下文信息。常见的成功发表论文一般会有多个作者,一些框定研究领域和具体问题的关键词,大量的文献引用,以及发表的会议信息。因此,准确地判断一篇论文在目标会议上的命中率也是一个尤为困难的问题。而从数据中千千万万的备选中找出最具备技能互补性的研究者来推荐给我们,更是困难。我们需要的是一个能够有效地表示论文行为以及其上下文信息的载体。
传统的方法是利用矩阵或者张量分解来得到低维度的数据对象表示。也就是说,我们可以构建一个巨大的矩阵,其中包含了所有论文以及上下文项的信息,然后通过分解这个矩阵来得到论文与上下文项的低维度表示。但这这并不适用于多个上下文项属于同一种类型的情况,例如在一篇论文中有多个作者与引用。而当我们的数据量变得更大的时候,用单个庞大的矩阵来表示整个数据集显然也不是个高效的选择。
表征学习的方法为我们提供了一些较好的思路:如果我们能够学习到论文以及其包含的上下文项的向量表征的话,我们关心的预测以及推荐问题将会迎刃而解。值得提到的是近两年比较流行网络嵌入学习。这些方法基于保存节点与节点之间邻近度的思路,能够将网中的节点快速地学习成向量表征。当拥有了节点的向量表征之后,我们能够轻易地利用向量內积来运算出节点与节点之间的相似度,从而帮我们完成节点分类与边预测等任务。但网络嵌入学习的方法并不能适用于我们的情况:我们关心的是由一组由多类型上下文项构成的论文是否能够在未来成功发表,而不是该篇论文是否和某一个作者在网中有较高的相似度。
我们的方法
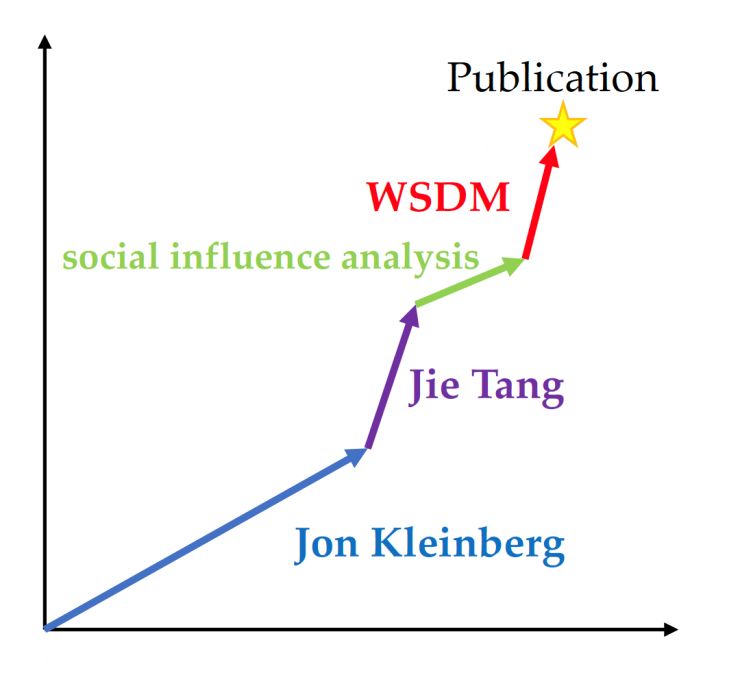
针对于这些问题,我们提出了全新的嵌入学习方法。首先,我们将所有的行为看做一个多类型集合的结构。例如一篇论文就可以被看做一个由作者、关键词、目标会议、引用等四种类型组成的集合结构;其中作者、关键词、引用允许有多个上下文项,而一篇论文只对应一个上下文项。

这样,一个行为的向量表征就可以由其包含的上下文项表征通过加权求和得到。
我们进一步通过运算行为向量的二阶模长(取双曲正玄值)来得到一个行为的成功率。
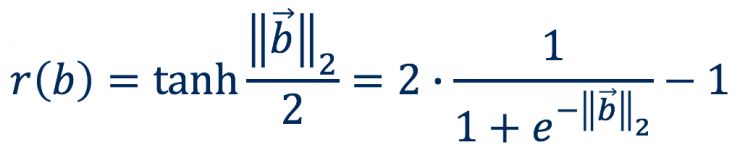
之后,我们通过随机梯度下降的方法来优化实际行为成功率分布于预测行为成功率分布之间的距离,最终学习得到数据集中所有行为以及上下文项的低维度向量表征。
在这里需要强调的有两点:1. 我们在低维度嵌入空间中保存了行为的成功特征(多类型上下文项集合的结构);2. 在大多数时候,我们的数据集中只包含了观测到的成功的行为,而不包含失败的行为数据。因此,我们也需要通过全新的负向采样的方式来构建训练负例。为此,我们提出了两种创新的多类型上下文项集合负向采样方法。
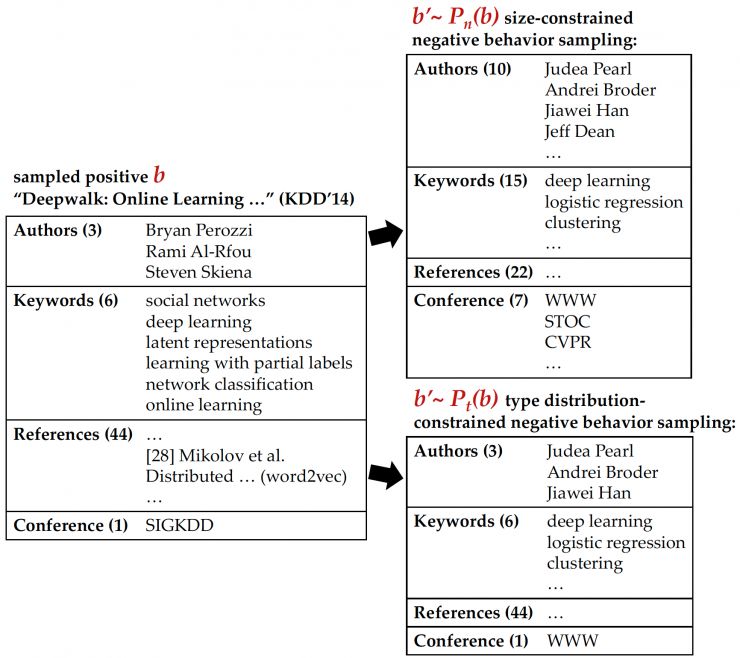
在第一种负向采样方法中,我们要求生成的负例需要与对应的正例拥有相同的上下文项数量。这样,我们能够避免完全随机采样所造成的不合理的负例子。而很多时候,我们会发现某一些类型的上下文项带有一些特点。例如一篇文章可以对应多个作者,但通常只对应一个目标会议。我们在此设计了我们更精细的第二种负向采样方法:要求生成负例的时候遵循正例的类型频率分布。这样,我们能够生成更近似于正例但是并不存在的负例用于训练。
实验结果
我们搜集了接近一万篇公开发表的计算机领域相关论文用于实验。
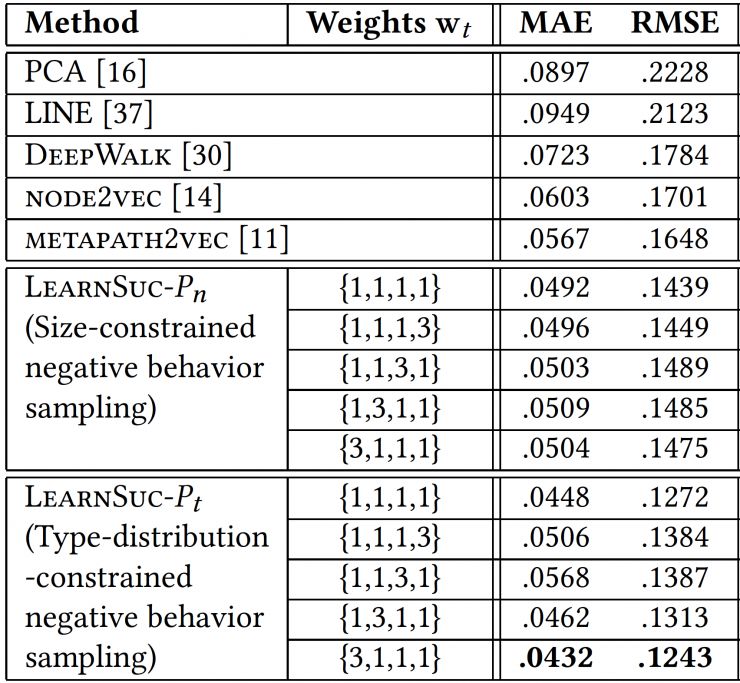
在预测任务当中,我们的模型表现优于所有网嵌入学习模型(LINE,DeepWalk,Node2Vec,Metapath2Vec)以及经典的降维模型 PCA。其中,第二种负向采样方法(Pn)优于第一种负向采样方法(Pt)。 而且当我们设置相对较高的权重给作者类型的时候,我们能得到整体最优的效果。
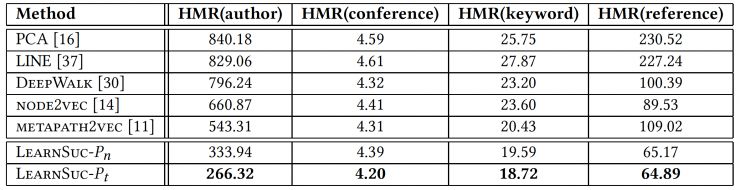
在推荐任务中,我们能得到一致的结论,我们的模型同样优于其他模型。特别是对于相对较难的推荐作者任务和推荐引用任务(总量分别为12300与18971),我们的模型拥有更明显的优势。
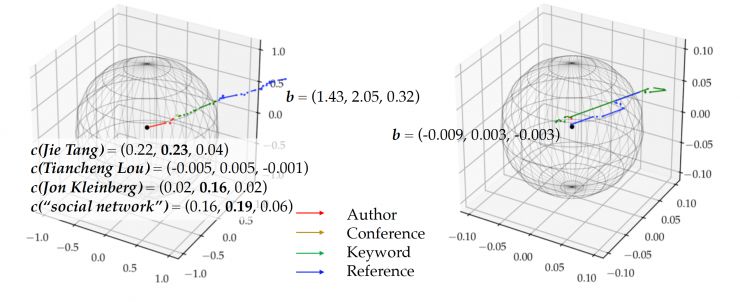
对于我们模型的优势,一个更直观的方法是把测试例中真实的文章与假文章在低维度嵌入空间中可视化出来。我们可以看到左边的真实论文向量在空间中明显地延伸;而假论文的向量接近于原点。这样一长一短的文章向量显示了我们的预测模型有足够的能力去鉴别真实论文与假论文之间的差别,从而提供准确地命中率预测给我们。
有趣的发现
另外,我们在实验过程中也有一些有趣的发现。
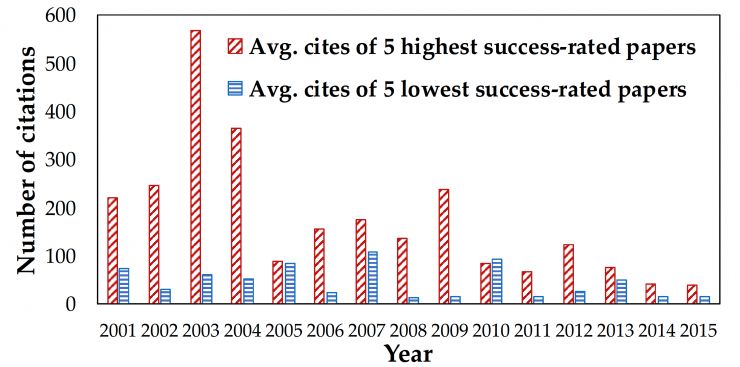
我们另外从 Google Scholar 中搜集了测试例中真实论文的引用数量。从图中我们能够发现在我们模型中得到更高预测命中率的论文相较于预测命中率更低的论文明显得到了更多次的引用。这样的结论几乎出现在2001至2015所有的年份当中。
最后,希望我们的发现与研究对你有所帮助。
原版论文请参照:
Wang, D., Jiang, M., Zeng, Q., Eberhart, Z., & Chawla, N. V. (2018, July). Multi-Type Itemset Embedding for Learning Behavior Success. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (pp. 2397-2406). ACM.
论文原文可移步雷锋网 AI 研习社社区资源区下载。
地址:
https://club.leiphone.com/page/resourceDetail/372



