干货 | 如何优雅的通过Key与Value分离降低写放大难题?



作者:阿里云数据库产品事业部 高级技术专家 傅忱
LSMs(Log Structured Merge Trees)结构在现今数据存储系统中非常流行,很多著名系统,包括 Google BigTable,HBase,RocksDB,Apache Cassandra 等等都采用了这一结构。Log Structured 是指,对于所有数据插入和更新,在关键路径上都是被添加到一个数据流末尾,形成一个新的版本。
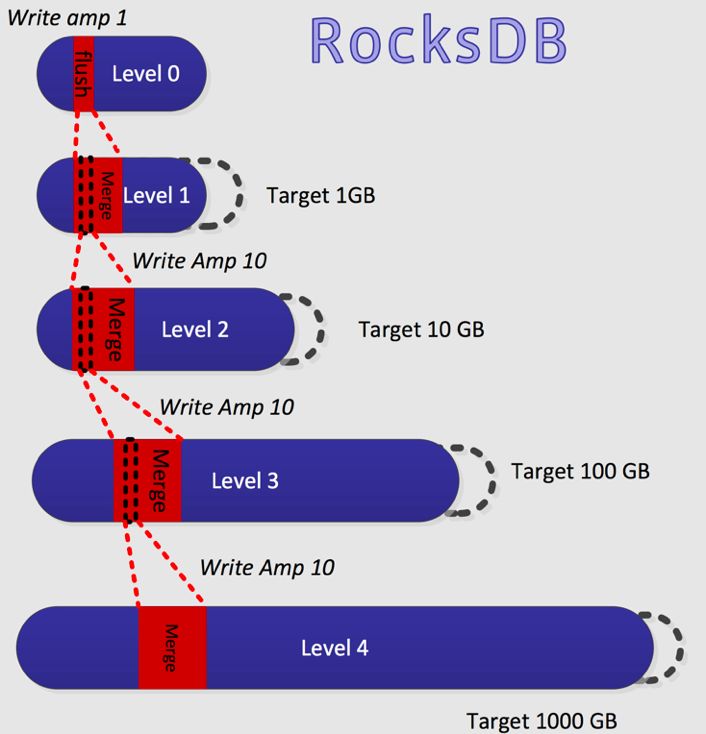
这一结构与传统的 B+ 树相比,大大提高了写性能,同时在一定程度上降低了磁盘的写放大。但是另外一方面,LSMs 后台用于清理过期版本的 compaction 过程还是会引起相当大的写放大,在著名的 RocksDB 中,数据量水位高的时候,写放大最坏可达 40倍(https://www.slideshare.net/HiveData/siying-dong-facebook)。
这种情况下,系统中只有可怜的不到 5% 的 I/O 带宽是用来服务客户的,其他都用来 compaction 了。
近年来,为了解决这个问题,学术界和工业界都出现了一些新的方案,在 value 的数据比较大的时候,把数据中 key 和 value 分开存储。
本文将为大家介绍为什么这样能够有效的降低写放大,然后聊聊几个 key value 分离系统的结构,包括两篇影响比较广泛的学术论文,以及 HBase在 key value 分离方面的设计思想。限于本人水平, 如有纰漏欢迎指正。
作为背景介绍,我们先来简单看一下LSMs。它与传统 B+ 树最重要的区别在于 Log Structured:针对任意一个 key 的插入或者更新都是加在数据流尾部,形成一个新的版本,而不像传统 B+ 树去寻找已有的 key 做原地更新。每隔一段时间,LSMs 用异步的 compaction 过程将已有数据重新排序,同时清除不用了的老版本。因此,本文后面把数据的插入和更新请求都称为更新请求。
一般而言,LSMs 的结构如下图,每个三角形代表一棵排序树。数据更新请求到来的时候,先写到 Write Ahead Log(WAL)里面,以防止在服务器异常当机的时候数据丢失。然后加到内存中的 write cache 中(灰色三角形)。
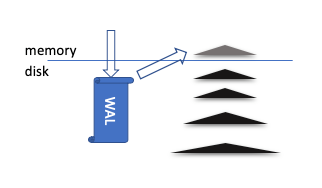
Write Cache 是一棵内存中的排序树,可动态更新。当 write cache 满了之后,其内容会写到盘上形成一棵不可更新的排序树,大多数时候用 B+ 树结构。时间长了以后,盘上会有很多棵树。为处理读请求,LSMs 必须查找所有的树。
树多了会让读性能下降。所以 compaction 过程会用 merge sort 把多棵树合并成一棵,写回盘上以减少树的数量,保证读性能不会下降太多。
这样我们看到,compaction 除了需要清除无用废旧版本数据之外,还需要保证树的个数在一个合理范围内。这样,在更新频繁的系统中,compaction 也必须频繁进行,导致高的写放大,提高了整个系统的成本。
但是反过来看,如果 compaction 只需要清除废旧版本,而不需要保证排序树的数量在一个范围的话,那么我们可以简单的通过扩大可用磁盘空间的办法来推迟 compaction,以达到降低写放大的目的。这就是 key value 分离的基础之一。
那为什么 key value 分离可以降低写放大呢?其实这样做并不是所有情况下都能降低写放大。但是在 value 比 key 大很多的情况下是的。比方说 key 有 16 字节,value 有 1KB ,如果 key 的写放大是10,value 写放大是1的时候,整体写放大是 (10 × 16 + 1024) / (16 + 1024) = 1.14,远远小于 10。
同时,在现今存储系统中,顺序存取和随机存取的差别大大减小甚至消失了。这得益于 I/O 系统的并行度的大大提高。在单 SSD 中就可以支持多线程同时读写。RAID SSD 让并行度进一步提高。大规模多租户分布式文件系统更是提供了无以比拟的并行度。
这样让存储系统可以放松对数据存放顺序的限制而不影响性能。这一限制的放开,就让大家有很大的空间来设想和实现多种数据组织结构,来降低写放大。
下面我来先介绍两篇科技论文中描述的数据组织结构,看看它们降低写放大的成果如何。这两篇论文是 WiscKey和 Hash KV。
下载地址:
WiscKey——https://www.usenix.org/system/files/conference/fast16/fast16-papers-lu.pdf
Hash KV——https://www.usenix.org/system/files/conference/atc18/atc18-chan.pdf
WiscKey 一文发表在 FAST 16。文中假设所有 key 都很小,16B 左右。Value 范围大概在 100B 到数 KB。在 LSMs 结构中存储 Key 和 一个指向相应 value 位置的指针,而Value 存在另外一个结构中。这个结构因为不需要排序, 可以让研究人员有更大的自由度来研究不同的结构以降低写放大。
3.1. 存储结构简介
WiscKey 结构如下图所示。它用一个 circular value log (vLog)结构存储 value,实际上存的是 key-value pair。在 WiscKey 收到一个数据更新请求的时候,先把 <key, value> 写到 vLog 的 head 处。这里 vLog 取代了 WAL,省掉一次 I/O。然后把 value 在 vLog 中的地址和 key 一起写入到 LSMs 中。
这样 vLog 可以完全取代 WAL。在读取的时候, WiscKey 用用户指定的 key 来查询 LSMs,从中找到 value 在 vLog 中的地址,再从 vLog 中读取 value。这样,WiscKey 在单点查询的时候,关键路径上会比纯 LSMs 结构多一次读操作,在 SSD 和多租户云存储系统中这个操作通常会增加一个比较小的延迟,小于 1ms。
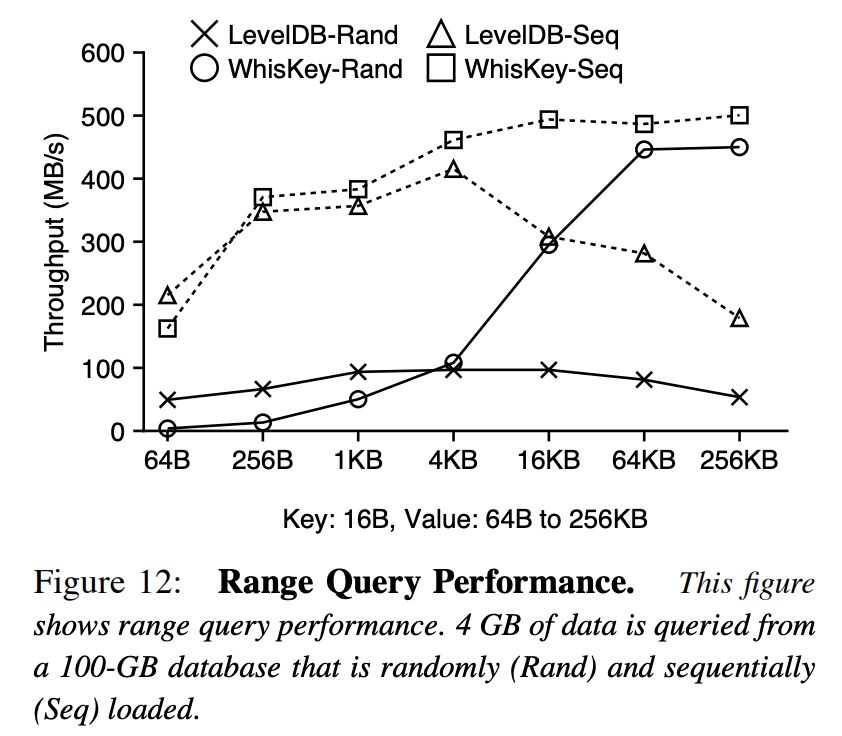
在 range scan 中,WiscKey 可以在 LSMs 中拿到多个地址,并行取多个 value。在高并行化的云存储系统中这种做法会更有优势。
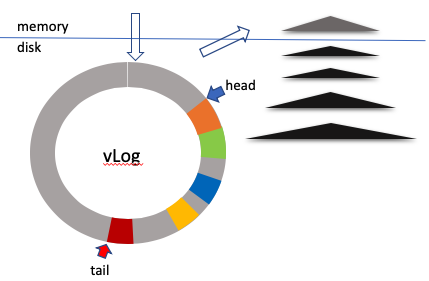
由于大 value 不写入 write cache。这样,比起纯 LSMs 的方案来说,在同样的写入量下,write cache 需要写盘的频率大大降低,产生排序树的个数会少很多。这样也就减小了 compaction 的压力,降低了写放大。
3.2. vLog 中的 Garbage Collection
WiscKey 中 LSMs 的 compaction 不变。同时, vLog 中需要另外的 garbage collection 以移除已经过时的数据版本。为了这一目的,整个 vLog 是组织成一个环形结构,如下图。head 和 tail 是两个指针,都向逆时针方向前进。每次新写入的 <key, value> 都是加在 head 处,导致 head 指针逆时针前进。如果这样无休止的进行下去,head 早晚会追上 tail。为了避免这种情况发生,WiscKey 会定期从 tail 开始读取老的 <key, value>,用 key 去查询 LSMs。
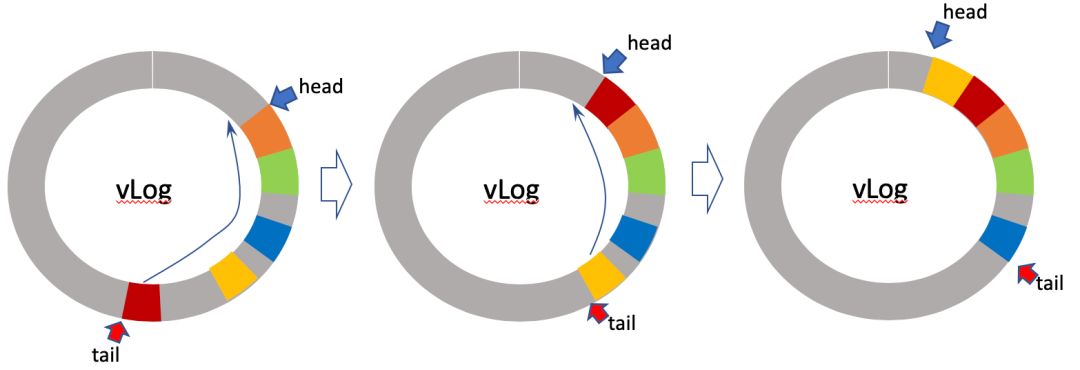
如果查询结果表明 key 还存在,而且相应地址吻合,那么我们就知道当前这个 <key, value> 需要保留。这时WiscKey 会把它 append 到 head 处,然后让 tail 指针逆时针移动。如果当前 <key, value> 不需要保留了,那么我们可以让 tail 指针直接逆时针移动。这样就清除了 vLog 中不需要保留的 <key, value>,释放了存储空间,让后续数据能够继续写入。
从这里我们可以看出,vLog Garbage Collection (GC)只需要清除废旧版本数据,而不需要为读性能进行数据重排。在这种情况下,只要为 vLog 准备的空间足够大,GC 就可以推迟,然后在一次操作的时候清楚更多的废旧数据,降低 GC 频率和写放大。
3.3. 性能分析
作者认为这种设计避免了反复排序,因而能够大大降低写放大。在 random load 测试(随机顺序将 100G 数据写入 store)中,WiscKey 比 LevelDB 在 thoughput 上占绝对优势,因为它有很小的写放大
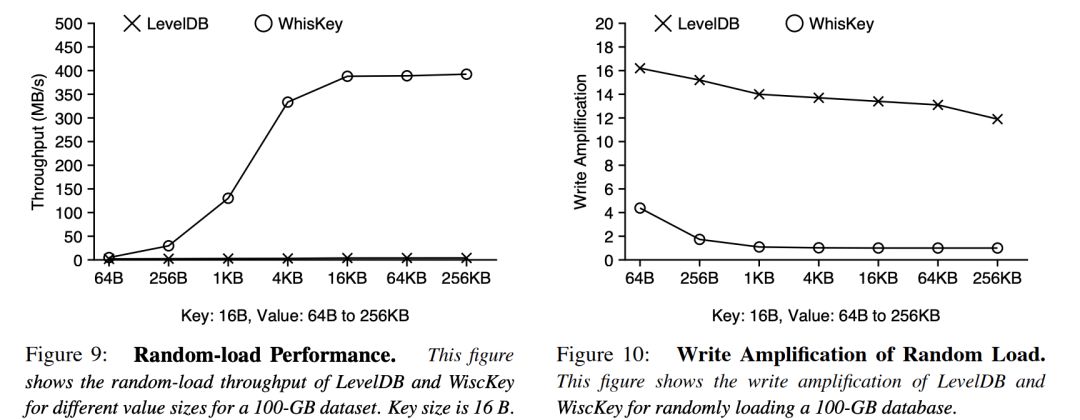
在查询 throughput 的比较上,WiscKey 也是全面占优。作者认为因为WiscKey 中 LSMs 结构小了几十上百倍,在文件大小不变的情况下,一次 LSMs 查询需要查找的文件数量会大大减少,这是 thoughput 占优的原因。
遗憾的是作者并没有给出每一次查询平均查找的文件数来支持这一说法。更加遗憾的是作者没有给出任何 latency 数据。
Hash KV 一文发表在 USENIX ATC 18。此文在 WiscKey 基础上做了更多的工作。文中论述,WiscKey 中的 value 存放方式有三个大问题。
第一是 circular log 结构决定了 GC 只能从 tail 指针处开始,没有办法灵活选择废旧数据最集中的地方开始。第二是 GC 过程中必须查询 LSMs 来确定当前 <key, value> 是否需要保留,这是一个费时费力的操作。第三是 WiscKey 没有做冷热数据分离,让冷数据也必须和热数据一起不断被 GC 重写。
文中先用实验说明 vLog 的写放大也很严重,实验中一个 52GB 大小的 vLog 先装载了 40GB 数据,然后针对同样的 keys 又写入了 40GB 的更新数据。在更新阶段,vLog 的写放大达到了 19.7。根 levelDB 差不多,大大高于 RocksDB。
我觉得这个实验对比并不公平,因为实验只对 vLog 有大小限制,不超过 52G,但是文中没有提到对 level DB 和 RocksDB 的可用空间做类似限制。如果给 LevelDB 和 RocksDB 也都限制只能用 52G 的磁盘空间,那么它们都会被迫频繁 compaction,大大提高写放大。
4.1. 存储结构
文中继承了 WiscKey 中把 key 存在 LSMs,k-v pair 另外存储在 vLog 的做法,但是提出来一个新的方案来改进 vLog。主要基于两个想法:1. Hash Based Data Partition。 2. 冷热分离。
首先是 Hash Based Data Partition: 所有的数据,根据 key,通过一个固定的 hash function 分配到多个 segment 里面去。每个 segment 都是 append only log structure。当存储空间水位到一定水平之后,GC 可以用多种策略在众多的 segment 中选一个进行处理。文中采用的选择策略是选最近一段时间 update 最多的 segment 来做 GC。
选定 segment 之后,GC 扫描整个segment,找到所有的还需要保留的 key value,仍然以 log structure 写入到新的存储空间中,然后把原来占用的存储空间释放。 因为存储是 log structure,最老的数据在 log 头上,最新的在尾巴上。那么同一个 key,肯定是靠近尾部的 version 比较新。
另外,同一个 key 总是会被分配到同一个 segment。为此可以不用查询 LSMs,只要扫描整个 segment 就能知晓那个数据是需要保留的。在这个过程中, GC 在内存里面需要维护一个 hash table,来查询每个 key 的最新 version。这个内存 hash table 的大小由 segment 的大小决定,可以通过细分 segment 的办法来限制 hash table 的大小,以避免内存占用过度。
第二是冷热分离。在每次 GC 某一个 segment 的时候,都会判断某个 key 是冷的或是热的。文中采用判断冷热的策略是:如果上次 GC 之后有两次 update 就算是热 key。否则就是冷 key。热 <k,v> 写到 segment 里面,冷 <k,v> 存到另外一个统一的 vLog 里面(与 WiscKey 中 vLog 相同)。
但是冷 <k,v> 会在 segment 里面留下一个 <k,tag> 表示这个 key 在冷数据 vLog 里面有 。这是为了下一次 GC 的时候可以不用查 vLog 就能马上看到同一个 key 有几次 update,用于决定 key 的冷热。不难看出,决定冷热的策略是有很多灵活度的。而且 vLog 需要自己的 Garbage Collector。
每次 GC 之后,需要保留的 <k,v> 被重写了。新的地址会在 GC 过程中 update 到 LSMs 里面。注意这里不管是 hash partition 还是冷热分离,都不会引起很多读放大。因为从 key 中通过一个固定的 hash function 就可以知道这个数据应该在哪一个 segment。而且从地址本身的某几位中可以看出数据是在 hot segment 还是在 cold vLog 中,所以我们可以在 LSMs 中拿到地址后,一次 I/O 就可以找到 value。不会需要查两个地方。
这样 HashKV 达到三个目的: 1. 数据分块,这样 GC 可以选择从哪里开始。 2. 避免 GC 时候查询 LSMs。 3. 冷热分离。
4.2. 性能测试
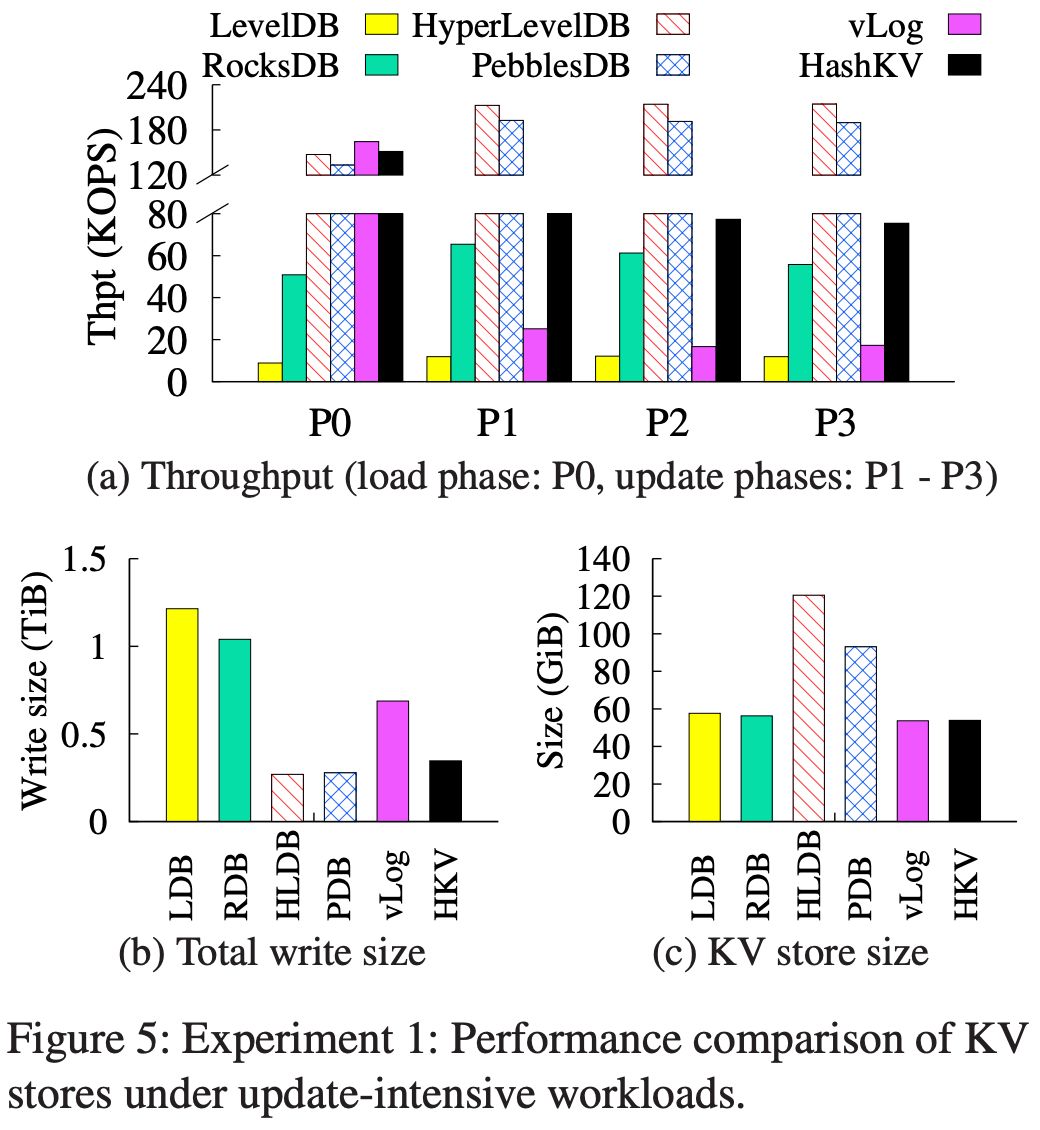
为了测试 compaction GC 带来的写放大,文章作者做了以下实验设定:实验分四个阶段, 在 P0 阶段把 40GB 数据插入空数据库, P1 ~ P3 每次按照 Zipf distribution 来 update 数据库中已有的 key。每次 update 总体积是40GB。实验中测量各个阶段的 write throughput。
实验比较 LevelDB, RocksDB, HyperLevelDB, WiscKey 和 HashKV。注意对于 HashKV 和 WiseKey,作者限制了存储空间, 基准空间 40G 加 30% 的预备空间 12G,一共 52G。 而对于其他数据库则没有这个限制。在我个人看来这是一个非常不公平的设定。可用存储空间大小会直接影响写放大,这一设定对于 HashKV 和 WiscKey 十分不利。
实验结果如下图所示, HashKV 在 write throughput 和总写入量(用于测量总写放大)上优于除 HyperLevelDB 和 PebblesDB 之外的所有其他方案。但是从 (c) 图可以看出,HyperLevelDB 和 PebblesDB 的优异 write throughput 是用大量的存储空间换来的。
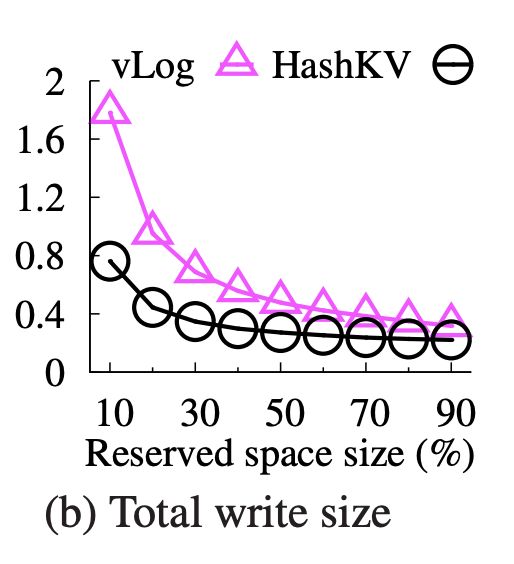
实验也显示了存储空间大小对 vLog 和 HashKV 写放大的直接影响,如下图所示,在预备空间到达基准空间的 90% 左右时候,vLog 与 HashKV 的写放大相差无几。
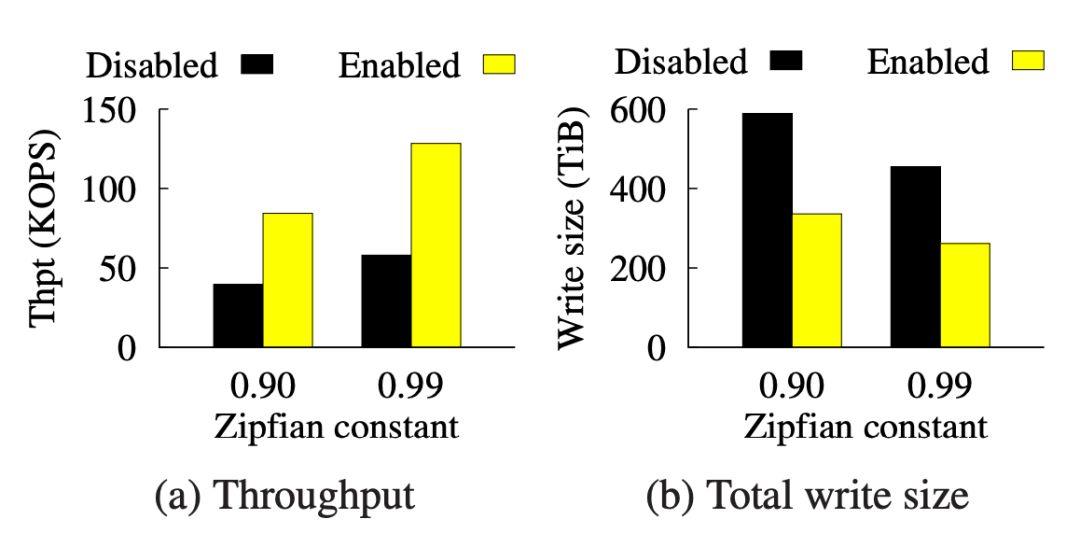
注意 P1 ~ P3 每次 update 都是按照 Zipf 分布来做的,这会造成一少部分的 hot key 和大部分的 cold key。下图显示了 HashKV 中冷热分离的功效。可以看到在打开(enabled)和关闭(disabled)冷热分离时候对写放大和最终 write throughput 影响都是非常显著的。
上面我们看了两个来自于学术界的方案。现在我们来看看 Open Source 方面的成果。HBase 的 MOB 项目(欢迎使用阿里云HBase免费体验:https://cn.aliyun.com/product/hbase),和 TiDB 的 Titan Engine 实现了 selective key value separation,就是在 value 大小超过一个上限的时候,把 <key, value-address> 存到 LSMs 数据结构中,而把 <key, value> 存到另外的 value file 里面,在 value 小于这个限制时候不做分开存储的处理,直接存到 LSMs 中。
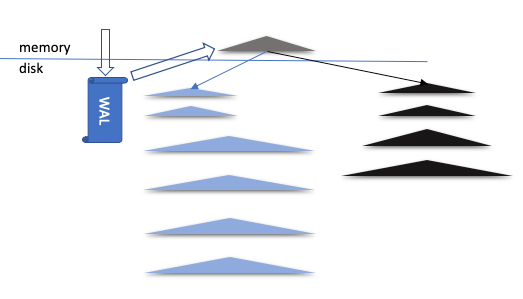
从结构上来看,HBase MOB 以及 Titan Engine 类似,都像是用了两个平行的 LSMs,如下图所示。来自客户的数据更新 <key, value> 仍然先写进 WAL,然后是 write cache。
在 write cache 满了之后写盘时,其内容分成了两部分:大个 <key, value> 写入 value file(蓝色三角形),其对应的 <key, value-address> 和小个的 <key, value> 写到原来的 LSMs 中(黑色三角形)。所有的读请求都走 LSMs ,从中查到 <key, value-address> 的时候,可以根据 value-address 到 value file 中读取 value。
注意在 write cache 满了写盘的时候,因为 LSMs 中需要写入大 value 在 value file 里面的地址,那么写 value file 的线程需要和写 LSM 的线程协同。为避免这个协同工作,HBase MOB 中的 value-address 只包含了 value file 的文件名,而不包含 value 在文件里面的位置。
这样读的时候需要在 value file 中做查询,对读性能有影响。但是 Titan Engine 中的 value-address 包含了文件名和文件内位置,用写盘时候的协同来提高了读性能。
左边 Value files 的组织形式和 LSMs 类似,每个文件也是排序的,它们的 compaction 同 LSM 中的 compaction 算法相同,都是用的 merge sort。但是 compaction 频率和选择文件的方式有很大区别。因为 value file 中排序树多了并不影响读性能,只要有足够大的存储空间,compaction 就可以推迟,避免频繁 compaction 带来的写放大。
这个结构在工程实现上有比较大的优势。因为新的 value files 结构与原来 LSMs 结构类似,很多代码可以重用而不必另外开发,就能达到降低写放大的目的,让开发成本和周期大大缩小。
今天和大家介绍了一下多种利用 key value 分开存储来降低写放大的方案。从我个人来说,感觉来自于学术界的方案比较大胆,步子迈得比较大。而来自 HBase 和 Titan Engine 的方案则相对更注重于开发成本和周期,稳扎稳打,为了稳妥起见放弃了一些优化。
比方说我们前面提到了,在 WiscKey 中 vLog 可以完全取代 WAL,不仅少了一次 I/O,而且因为大 value 不写进 write cache,在同样的写入量下, write cache 写盘的频率会大大降低。这让盘上 LSMs 排序树的数量减小,会减小 LSMs 部分 compaction 的压力。HBase 和 Titan Engine 中都没有采用这一优化。
同时,从工程成本角度出发,HBase 和 Titan Engine 中 value files 是排序的。这意味着可以重用原来 compaction 的代码而不用另外开发 GC 模块。上面 WiscKey 和 HashKV 两篇论文中则论述,非排序的 value file 在顺序 scan 时候能提供明显优于原 LSMs 的性能。文章认为,在 RAID SSD 系统中的并行能力已经可以让随机读取发挥很好的性能,非排序的 value 存放结构不会对性能有很大影响。所以排序操作是不必要的。
这几个方案虽然大方向一致,但是出发点不同,注重因素不同,最终实现也大不相同。可是它们都给我们提供了大量的灵感。我们正在积极的在此基础上继续创新,打造下一代高精尖的数据存储系统。
欢迎大家加入阿里巴巴数据库产品事业部NoSQL团队(校招&社招具体信息请点击阅读原文),一起探索学习数据库及存储计算的创新动向。
我们专注于大数据场景,紧跟世界最新科技趋势,根据客户的需求,勇于开拓创新,为客户提供多样化,高可用,高性能,低成本的数据服务(包括HBase、Phoenix、Solr、Spark等相关领域)。我们的服务已被阿里集团、蚂蚁金服、菜鸟及阿里云等企业客户广泛使用。
在这里,你会遇到
亿级别访问的尖峰时刻
错综复杂的场景需求
在这里,你会担负
万台规模服务器集群的运营支撑
迎接业务全球化等各类技术挑战
在这里,你会有机会学习
全球学术界和工业界顶尖的技术
领会创新的苦与乐
在这大数据+云计算的快速融合发展窗口
我们邀你同经风雨,共见彩虹,历证未来!
简历投递地址:c.fu@alibaba-inc.com
工作地点:杭州、深圳、硅谷

点击“阅读原文”
了解更多职位信息

阿里巴巴数据库技术
微信:alibabadba

分享数据库前沿
解构实战干货
长按二维码关注



