面对突发流量激增Coinbase如何扩展其交易平台
导读:2017年以来,世界范围内都在关注加密货币,Coinbase流量压力激增。Coinbase怎么应对这些流量压力,又怎么在流量非高峰时期做准备,这是很多技术人都关心的话题。本文作者是Coinbase工程师团队成员,就这些问题给出了详尽的解释。
2017年以来,世界范围内都在关注加密货币,因此其整个生态系统的市值从200亿美金跃升至6000亿美金。在此期间,coinbase的所有技术组件都经历了实战的检验,我们除了需要关注安全性之外,平台的可靠性和可扩展性也是非常重要的。我们在MongoDB World 2018上,我们谈到了2017年技术上的收获,以及如何扩展我们现有平台。这里有演讲视频[1],本文是这次演讲的概述。
2017年的教训
2016年的时候,coinbase的流量还比较平稳。我们也预计过可能碰见的问题,因为后端平均每分钟处理25000个API请求,所以我们将流量红线设置为每分钟10万个API请求。
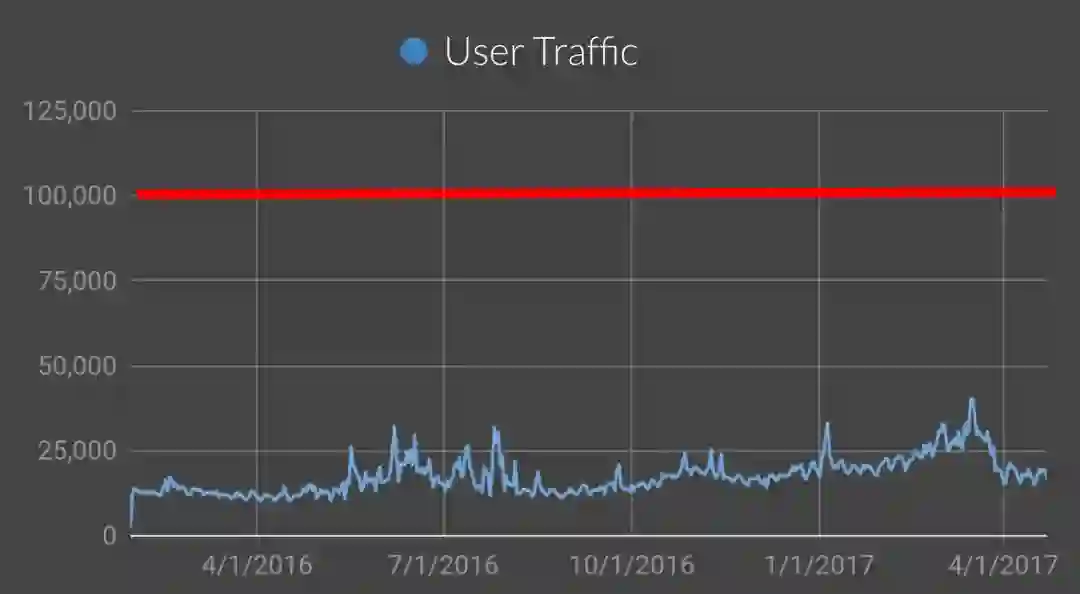
然而,随着2017年5月-6月以太坊价格飙升,流量超过了红线,因此我们也经历了服务宕机的情况。
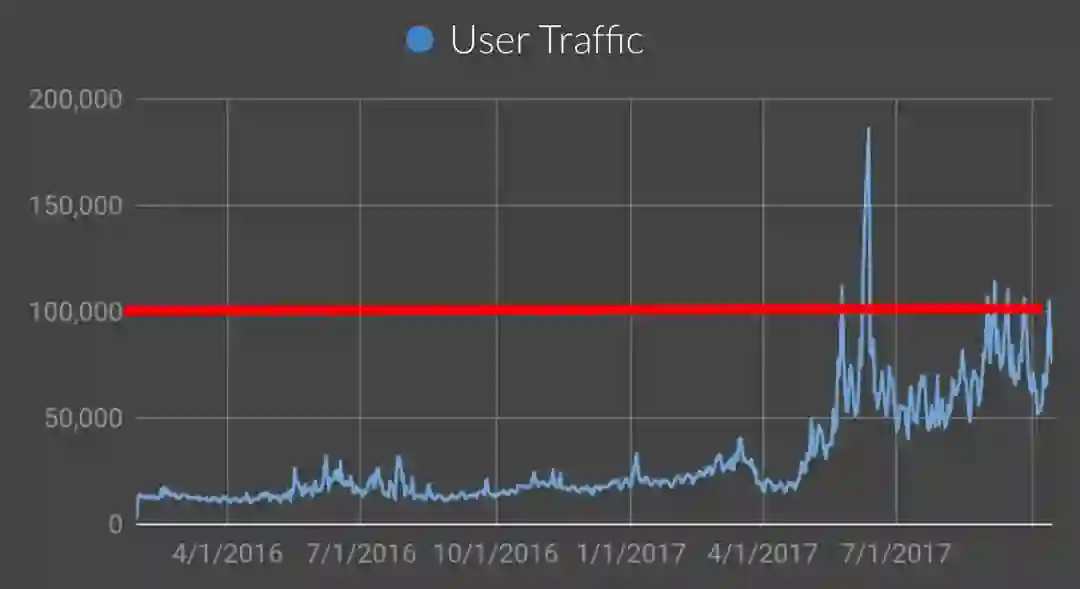
为了快速解决问题,Coinbase的工程师团队首先关注环境中的瓶颈。我们坐了很多工作比如,垂直拆分扩展,升级数据库版本(以利用新版本的特性),优化索引以及将热点数据库拆分等。所有的这些措施都为我们带来很大改进,然而流量持续攀升,仅仅靠这些还不够。
在每次出问题的时候,出问题的模式都是类似的:我们的监控平台显示有非常高的(100倍)延迟,并且伴随着ruby服务器和mongodb数据库之间事物处理时间的不匹配。我们主要使用Mongdb存储数据,在流量大的时候会遇到这种高延迟,然而ruby服务的时间却没有增加。
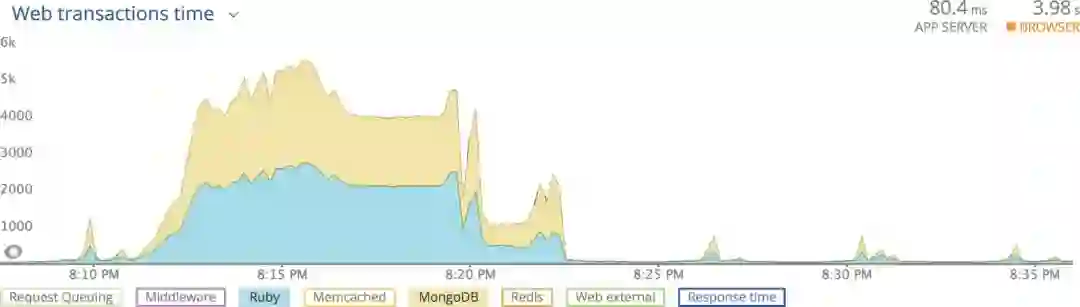
因为我们的监控工具无法为这些问题的原因提供答案,因此我们称之为幽灵问题。这些查询来自哪里?查询看起来在做什么?为什么ruby处理时间也有峰值?问题是在应用程序这边吗?
简而言之,我们的监控系统无法利用我们所有环境。我们需要一个框架来回答这些问题,并且将之可视化。
我们开始通过修改mongodb驱动来追踪查询,可以记录超过响应时间阈值的查询,以及request/response大小,响应时间,源代码行等信息。
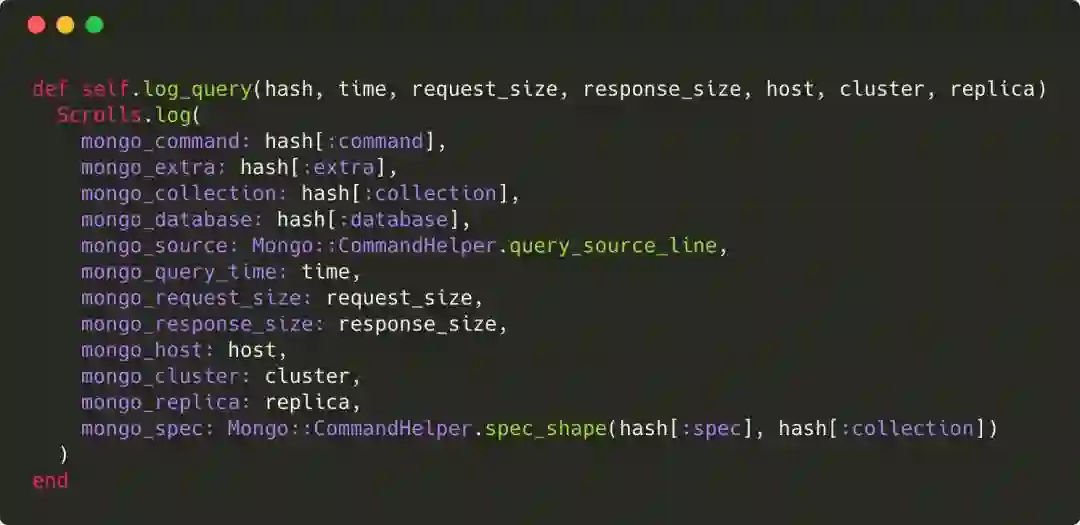
改进后的dashboard提供了更详细的数据,使我们能快速缩小问题的范围。我们注意到的第一个奇怪的现象是,我们用户登录购买或者查看仪表板的时候,会有大量查询。
这种情况的原因是我们的用户和设备之间是多对多关系。即某些用户可能有多个设备,某些设备对应多个用户。糟糕的设备指纹识别算法将大量用户置于同一设备中,从而导致单个设备对应大量user_id。

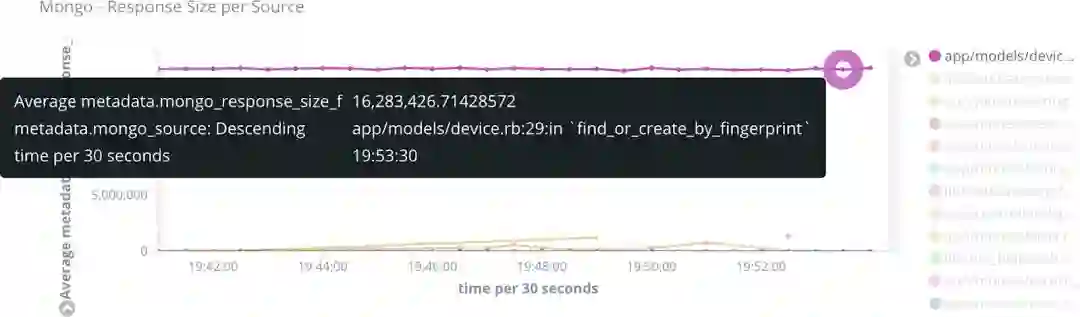
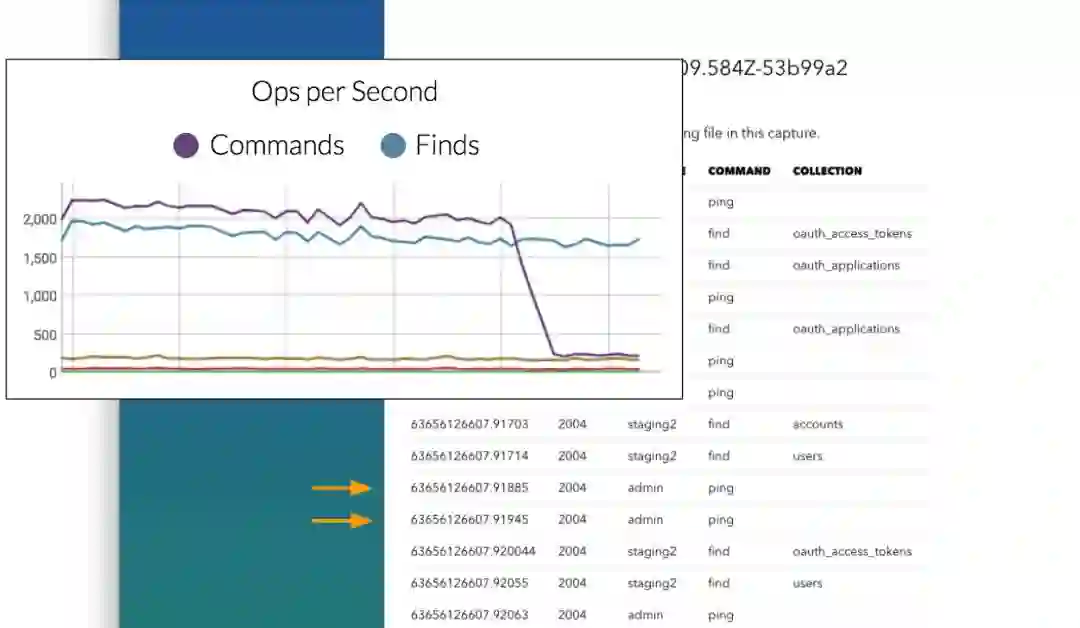
为了解决这一问题,我们将之重构为一对多关系,即每个设备只映射到一个用户。从下图可以看到,性能提升是很大的。
这也说明了良好的监控工具的必要性,在能够细粒度追踪数据库查询之前,几乎无法发现这一问题。使用新工具之后,就很容易发现问题了。
我们需要解决的另一个问题是热点集合的大量读取。我们决定使用memcached缓存查询结果,即在查数据库之前,所有请求都先查询缓存,在写数据库之前,也会先做操作使缓存失效。
为了能够尽量与业务解耦,缓存是在ORM和数据库驱动这一层添加的,这使得我们同时影响多个数据库集群。
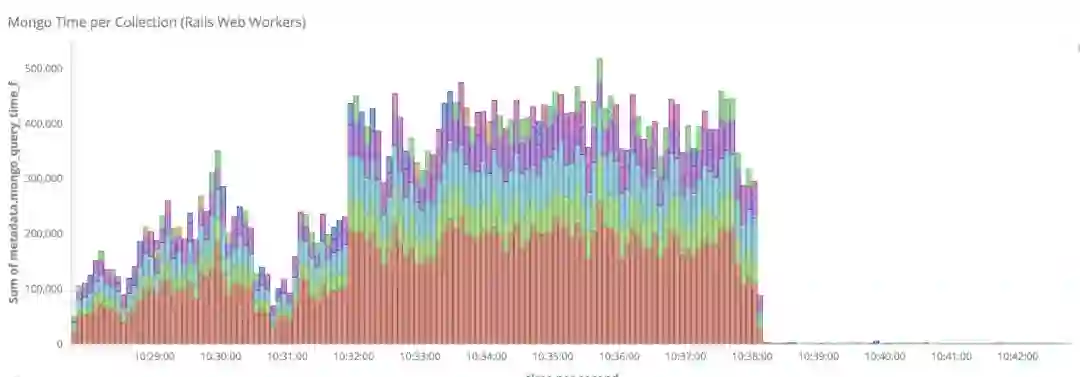
经过12月和1月份的流量激增证明,这些改进都是非常有效的措施。借助这些手段,我们能够成熟更大的流量激增。
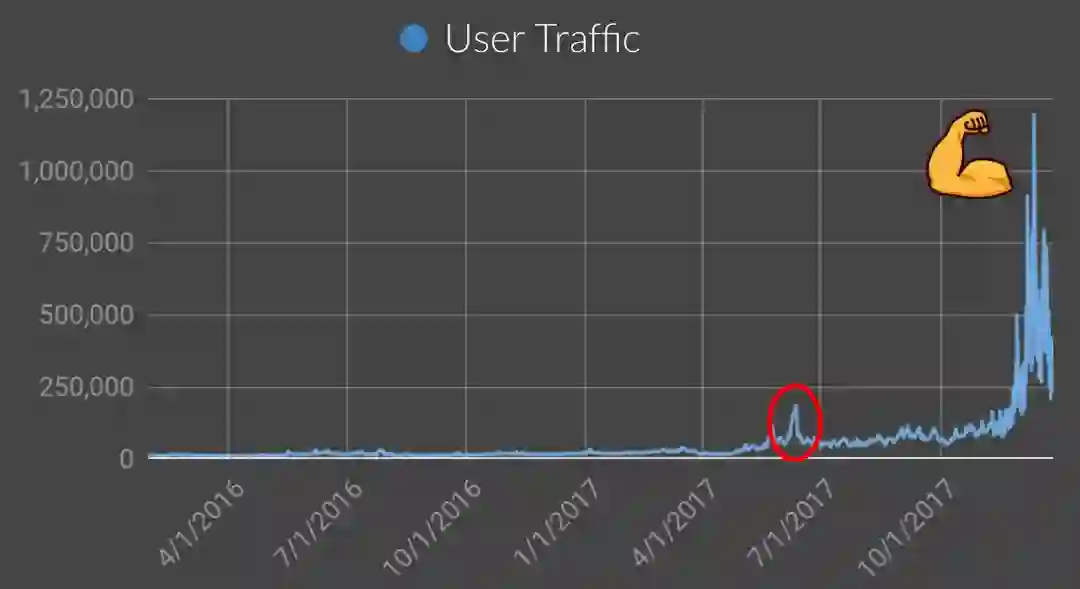
为了将来
现在我们正努力确保在下一次流量激增之前做好准备。虽然在流量激增期间可以做很多工作,但是我们需要找到一种方法来改善我们现有表现,以在流量较低的时间就可以做好准备。显然可以通过模拟流量激增来测试我们现有的环境,以发现我们下一个问题来自哪里。
我们选择的方案是流量捕获和回放,特别是在数据库上,按需生成流量。对我们来说,这种方式比伪造流量更为可取,因为不需要让测试脚本跟随业务迭代。每次运行测试套件时,我们都会确保查询捕获的数据准备映射到应用程序流量。
为此我们构建了一个名为capture的工具,它是mongoreplay的封装。在我们选定特定集群后,catpure会启动快照并开始捕获定向到该集群的应用服务器上的原始流量。之后对数据进行加密,并存储到S3上。当我们执行回放时,有另一个名为cannon的工具,将捕获的流量回放到新启动的集群。
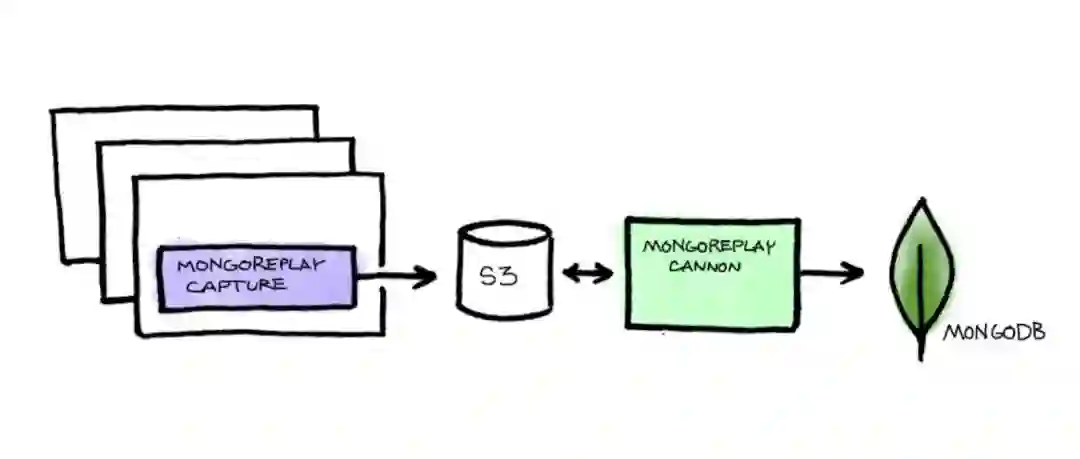
这个模式的一个挑战是如何跨越多个应用服务器捕获所有mongodb流量。cannon会打开10MB缓冲区,同时合并和过滤捕获的流量来解决问题。
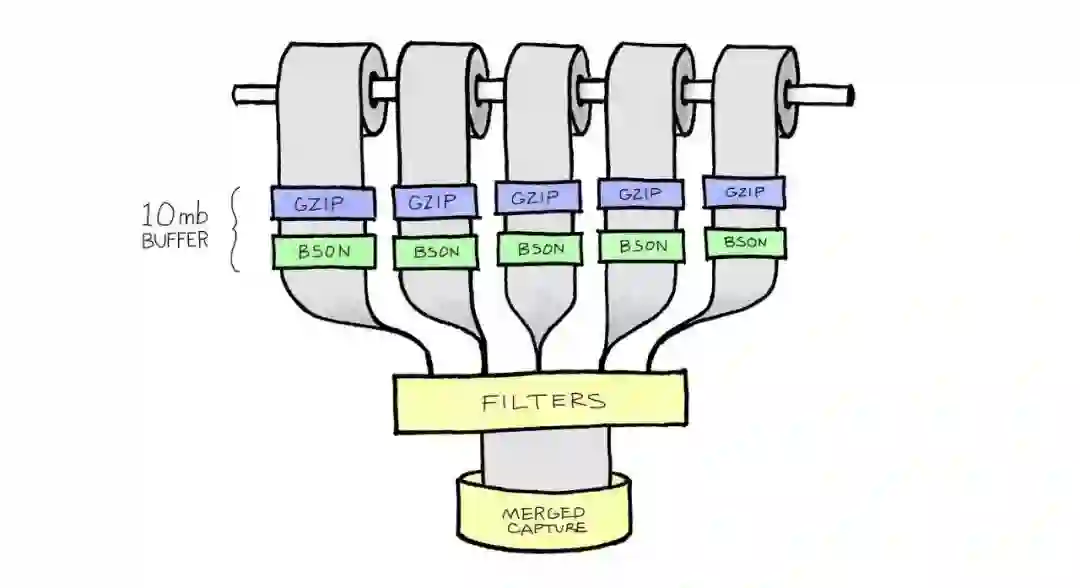
最终的结果是合并到一个文件中,cannon可以将其定向到新推出的mongodb集群。cannon允许精确选择重放的速度,以模拟数千倍的流量负载。
我们刚开始使用capture 和cannon,然而已经得到不错的结果。
其中一个重大发现来自cannon的调试功能,cannon能够检查捕获流量文件的前100条消息。经过检查,我们发现了一些有趣的事情。
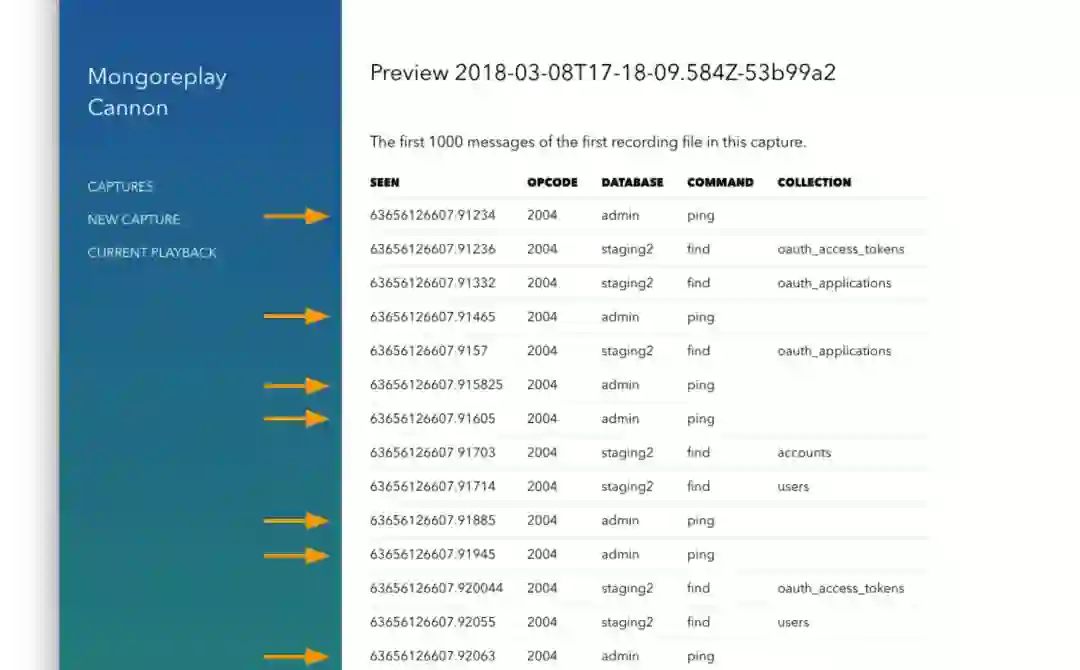
请注意ping和find混合在一起。事实证明,mongodb的ruby驱动未遵循正确的mongodb驱动规范。在每次find之前都执行ping命令以检查副本集状态。这种行为虽然不太可能导致停机,但是基本可以肯定,这是前文所述幽灵行为的原因。
在经过这些努力之后,我们为coinbase目前的可靠性而自豪。2017年的事件证明,客户访问和查看资金的能力,对于达成我们的目标(购买,销售,管理加密货币)至关重要。虽然安全始终是我们的首要任务,但是可靠性同样重要。
原文地址:
https://blog.coinbase.com/how-were-scaling-our-platform-for-spikes-in-customer-demand-4a047cb3139c
文中链接:
[1] https://www.youtube.com/watch?v=i6ws1JpvNs0
本文作者Luke Dem,由方圆翻译。转载本文请注明出处,欢迎更多小伙伴加入翻译及投稿文章的行列,详情请戳公众号菜单「联系我们」。
参考阅读:
活动预告:
11 月 23 ~ 24 日,GIAC 全球互联网架构大会将于上海举行。GIAC 是高可用架构技术社区推出的面向架构师、技术负责人及高端技术从业人员的技术架构大会。今年的 GIAC 已经有微软,腾讯、阿里巴巴、蚂蚁金服,华为,科大讯飞、新浪微博、京东、七牛、美团点评、饿了么,才云,格灵深瞳,Databricks,等公司专家出席。
本期 GIAC 大会上,系统架构部分精彩的议题如下:

参加 GIAC,盘点2018最新技术。点击“阅读原文”了解大会更多详情。