全国Top3!!极市联合电子科技大学取得京东AI时尚挑战赛三等奖荣誉(附技术方案)
“啦啦啦啦啦啦
我是卖报的小行家
不管风雨有多大
一边跑一边叫
今天的新闻真真好”
本以为听多了卖报歌
听到任何新闻都会波澜不惊
然而当我听到......
极市联合电子科技大学夺得京东AI时尚挑战赛Top3!

震!惊!
这究竟是怎么肥四,一起来看看

努力吃瓜的寄己
﹀
﹀
﹀
北京时间2018年9月16日,由京东AI平台与研究部发起的从七月开始的京东AI时尚挑战赛正式在ChinaMM2018大会上圆满落幕!

大会现场
而经过两个多月的角逐,由极市与电子科技大学开发者组成的团队extreme-WJLD成功夺得时尚风格识别赛道top3,并受邀到大会上做了竞赛相关的报告!

极市与电子科技大学团队受邀颁奖照
撒花~✿✿ヽ(°▽°)ノ✿
﹀
﹀
﹀
摘要
京东AI Fashion-Challenge竞赛子任务时尚风格识别旨在通过衣物的宏观搭配以及局部的设计细节识别出衣物的风格。与之前阿里举办的Fashion AI比赛类似,衣物风格识别面临许多的问题,如姿势,光照以及相同风格间的外观差异。我们主要通过以下几个方面改善识别性能:数据增强、迁移学习、模型融合以及风格间的相关性。尽管方法看上去直观简单,但我们的方法仍旧以0.6524的F2-score居于排行榜第三位,取得了令人满意的性能。
1引言
视觉时尚风格识别近年来因其在研究领域和商业领域的广泛应用而受到越来越多的关注。 广泛的研究工作致力于服装分类([1]-[3]),属性预测([4],[5])和服装项目检索([6],[7])。 这是一项具有挑战性的任务,因为服装项目之间的差异很大,例如姿势,光线,比例和外观的变化。 为了减少这些变化,现有的工作通过寻找信息区域(例如服装边界框,语义局部[8]或人体关节[9])来解决这些问题。 但是,在实际情况下很难获得这些额外的标签。
挑战赛的目标是引导计算机自动识别衣服的时尚风格类别。公布的数据集包含54908个用于训练和验证的图像,以及10000个用于最终测试的图像。数据集由时尚专业人士标记。每个图像都标有13个二进制标签(属于类别或不属于),每个图像属于至少1种风格。表1中列出了13个样式类及其相应的索引。
表1. JD AIFashion数据集风格汇总
我们还对图1中的类分布进行了统计汇总。正如我们所看到的,数据分布严重不平衡。例如,运动风格的比例(索引1)为0.189%。另一方面,一些风格是密切相关的,而一些风格是反向相关的。这些样式的条件概率如图2所示。可以看出,某些类密切相关(例如,第1类和第2类),而某些类(第4类,第5类,第6类和第7类)从不一起出现。因此,类别不平衡是我们必须关注的巨大挑战,而我们的模型设计主要是围绕上述问题以避免过拟合。
由于深度卷积神经网络在图像分类方面取得了巨大的成功[10],我们的方法也是基于这一进展。 为了应对这一挑战,我们的解决方案主要应用了以下技巧:数据增强,迁移学习和风格关系建模。总的来说,我们在测试集上取得了0.6524(F2-score),在排行榜上获得了第3名。
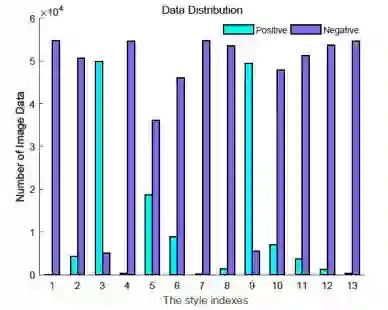
图1. 训练集和验证集的数据分布
2公布的方法
对于风格识别任务,我们考虑了以下四个方面:数据增强,网络结构,迁移学习,代价敏感的学习和风格关系。
A.数据增强
(1)训练集重新采样
为避免过拟合,我们对训练集进行了重新采样,以确保每个训练批次包含合适数量的正样本。此外,我们对第1、2、4、7、8、10、11、12、13类的负样本进行了欠采样,并保持第3、5、6、9类的原始比例。这项行动的核心思想是努力在改善正负样本的比例和维持原始数据分布之间取得平衡。
(2)随机擦除[11]
这是用于训练卷积神经网络的数据增强方法。在训练过程中,我们在图像中随机选择一个矩形区域,并用随机值擦除其像素。因此,它将生成具有不同程度遮挡的训练样本,这可以降低过拟合的风险。
(3)随机旋转和随机裁剪
由于服装图像包含不同的姿势和比例,我们以±15°之间的角度随机旋转训练图像,并随机裁剪图像作为输入,以使模型对姿势和比例更具鲁棒性。
如果没有明确说明,下面的所有实验都默认基于数据增强。
B.网络结构
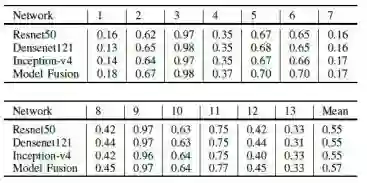
我们使用几种最先进的网络架构进行了实验,例如Resnet50 [12],Densenet121 [13]和Inception v4 [14]。 在数据增强处理之后,我们单独训练这些模型。 表2列出了不同网络架构的实验结果(在验证数据集上)。 我们可以看到,Resnet50在运动和日系方面取得了更好的成绩,而Densenet121在少女,朋克和休闲方面表现更好。此外,Inception-v4的性能可以达到大多数类的中等水平。 此外,由于互补学习,模型融合可以进一步将性能提高到新的差距。
表2. 不同网络结构在不同类别上的性能
C.迁移学习
给定一个源域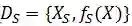
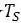
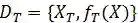
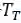
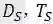
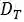
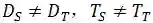
DeepFashion包含超过80万种不同的时尚图像,从精美的商店图像到无约束的消费者照片。此数据集中的每个图像都标有50个类别,1000个描述属性,边界框和服装标记。我们的预训练任务集中在对50种衣服属性进行分类。为了获得更好的预训练模型,我们清理了数据集并选择了20个具有更平衡数据分布的属性。实验结果如表3所示。
表3. 迁移学习在不同类别上的性能
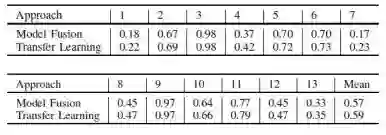
从结果可以看出,第1、2、4、7、8、10、11、12、13类从迁移学习中受益匪浅。另一方面,DeepFashion的预训练在第3类,第5类,第6类和第9类中效果就没有那么的好,因为他们已经有足够的正例图像。 此外,为了更好地利用风格关系,我们还从相关模型初始化权重。详细地,我们使用类2初始化类1的权重,并使用类8初始化类4的权重。
D.代价敏感的学习
由于我们的评估标准是F2分数(召回率比精确度更重要),因此F2分数的正样本错误分类和负样本错误分类的代价差别很大。为了最大化F2分数,我们采用了代价敏感学习[16]进行数据挖掘。代价敏感型学习是数据挖掘中的一种学习方法,它将错误分类代价考虑在内。 代价敏感学习的目标是最小化总代价。具体而言,它以不同的方式处理不同的错误分类。我们增加了假阴性的代价惩罚,同时保持假阳性不变。因此,成本函数倾向于优化召回率而不是精确度。在我们的实验中,我们只对第1、4、7、8、11、12、13类应用代价敏感学习。对于假阴性,惩罚权重设定为1:5。
E.风格关系
如图2所示,服装款式密切相关或反向相关。例如,当图像属于第3类风格(Office lady)时,它可能属于第9类(Lady),概率为99%。此外,一些风格从未出现过(日系和韩系)。 很明显,风格关系包含丰富的信息。
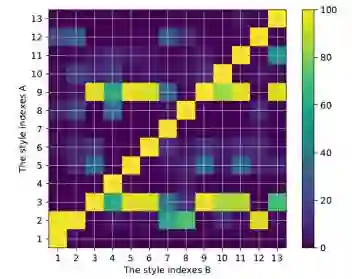
图2. 当风格B发生时风格A的条件概率图
我们尝试训练多标签分类网络,在所有样式中共享最低层,共享相关样式的较高层。但是,最终F2分数的贡献可以忽略不计。其原因在于多标签分类网络无法实现数据的重采样。因此,我们用式(1)分析了给定标签的条件概率。
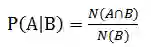
其中, 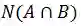
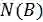
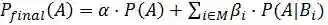
其中,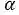
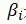
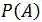
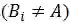
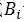
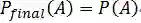
F.部署细节
我们采用交叉验证方法来评估单个模型和融合结果。具体来说,我们分割了43926张用于训练的图像和10981张用于验证的图像。如式(3)所示,通过F2-score评估提交结果。
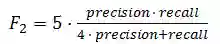
所有的训练和验证过程均在单张Nvidia 1080 Ti GPU上进行。训练批次大小尽量设置为GPU内存所能容纳的大小。首先我们对Deepfashion数据集进行清洗然后在其上训练基础模型。然后我们对数据集进行重新采样,并使用数据增强和代价敏感的学习策略对预训练好的模型进行了微调。
对于验证过程,我们融合模型和遍历搜索决策阈值。由于我们单独处理每个类,13个预测可能有一些明显的逻辑错误(例如,不可能存在所有的负面或所有正面。因为根据训练数据集的统计,每个图像属于至少1种样式,最多5种样式)。因此,对于后期处理,我们应用风格关系来进一步改进预测。这些步骤的平均F2-score显示在表4中。我们可以看到,所有步骤在最终结果中都发挥着不可或缺的作用。
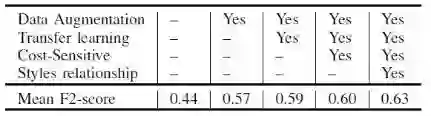
表4. 本文阐述方法的平均F2-score结果
总结
我们的方法从数据增强,网络结构,迁移学习和代价敏感的学习等方面解决了这个问题。此外,我们调查了后期处理的风格关系。通过上述提出的方法,我们在测试集上获得了0.6524的F2-score,这是排行榜的第3位。
﹀
﹀
﹀
看了团队的技术方案
你是否也想....
竞赛极市奖金两手抓
数据时间随时查
个人品牌专访打造
算法直接对接项目需求
......

极市平台满足你所想

不包括奇奇怪怪的想法(划掉
作为国内首家视觉算法开发和分发平台,极市不仅想要帮助开发者算法零成本变现,同时也致力于让开发者个人的价值得到更大发挥,与开发者一起打造一个专业性的开源性的视觉开发者社区,而比赛合作是我们开发者计划中的一环。
如果你也希望与我们合作参赛,或者有意向为打造视觉算法开发者社区和极市共同努力,欢迎联系我们~
合作联系

极市小助手微信二维码




