人体姿态估计(Human Pose Estimation)经典方法整理
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:Poeroz
https://zhuanlan.zhihu.com/p/104917833
本文已由原作者授权,不得擅自二次转载
前言
上学期搬砖期间做了一些pose estimation相关的工作,但一直没有系统的整理过相关方法。近日疫情当头封闭在家,闲暇之余重温了一下之前看过的论文,对pose estimation的部分经典方法做了一个整理。内容大多为个人对这些方法的理解,所以本文也算是一个论文笔记合集吧。
本文涉及到的工作仅包含个人读过的部分论文,按时间顺序进行了整理,并不能代表pose estimation这一领域完整的发展历程。比如bottom-up中的PersonLab、PifPaf,以及传统top-down/bottom-up方法之外的一些single-stage方法等,都是近年来出现的一些值得研究的工作,由于个人还没有仔细了解过暂时没写,之后可能会继续更新。
本文目录如下:
top-down
CPM
Hourglass
CPN
Simple Baselines
HRNet
MSPN
bottom-up
openpose
Hourglass+Associative Embedding
HigherHRNet
在整理过程中,我参照了以下几篇文章的思路,也添加了一些个人的理解。这几篇文章整理的思路都非常清晰,作者的水平也都比我高得多,推荐大家阅读。
重新思考人体姿态估计 Rethinking Human Pose Estimation
https://zhuanlan.zhihu.com/p/72561165
A 2019 guide to Human Pose Estimation with Deep Learning
https://nanonets.com/blog/human-pose-estimation-2d-guide/
正文开始之前还是希望各位带着批判的眼光阅读,毕竟本人目前大三水平有限,可能有理解不到位或不正确的地方,希望大家批评指正,欢迎大家评论区或私信随时交流。
Review of 2D Human Pose Estimation with Deep Learning
人体姿态估计(Human Pose Estimation)是计算机视觉中的一个重要任务,也是计算机理解人类动作、行为必不可少的一步。近年来,使用深度学习进行人体姿态估计的方法陆续被提出,且达到了远超传统方法的表现。在实际求解时,对人体姿态的估计常常转化为对人体关键点的预测问题,即首先预测出人体各个关键点的位置坐标,然后根据先验知识确定关键点之间的空间位置关系,从而得到预测的人体骨架。
姿态估计问题可以分为两大类:2D姿态估计和3D姿态估计。顾名思义,前者是为每个关键点预测一个二维坐标 

对于2D姿态估计,当下研究的多为多人姿态估计,即每张图片可能包含多个人。解决该类问题的思路通常有两种:top-down和bottom-up:
top-down的思路是首先对图片进行目标检测,找出所有的人;然后将人从原图中crop出来,resize后输入到网络中进行姿态估计。换言之,top-down是将多人姿态估计的问题转化为多个单人姿态估计的问题。
bottom-up的思路是首先找出图片中所有关键点,然后对关键点进行分组,从而得到一个个人。
通常来说,top-down具有更高的精度,而bottom-up具有更快的速度。下面分别对这两种思路的经典算法展开介绍。
Top-down
由上文我们知道,top-down的方法将多人姿态估计转换为单人姿态估计,那么网络的输入就是包含一个人的bounding box,网络预测的是人的 
,即直接对坐标进行回归,网络的输出是经过fc层输出的
个数字
个heatmap,即为每个关键点预测一个heatmap作为关键点的中间表示,heatmap上的最大值处即对应关键点的坐标。对于改种方法,heatmap的ground truth是以关键点为中心的二维高斯分布(高斯核大小为超参)
 ,即
,即 个数字
个数字早期的工作如DeepPose多为直接回归坐标,当下的工作多数以heatmap作为网络的输出,这种中间表示形式使得回归结果更加精确。接下来我们介绍top-down发展过程中的一些landmark。
需要说明的是,CPM和Hourglass提出时主要面向的是单人姿态估计,因为当时还没有COCO数据集,多使用MPII数据集进行evaluation。但top-down的方法本质上也是在解决单人姿态估计问题,所以将这两个模型放在此处介绍。
CPM
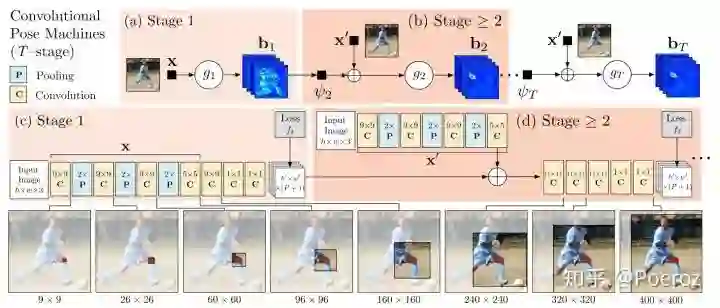
CPM,Convolutional Pose Machines,是2015年CMU的一个工作。这个工作提出了很重要的一点:使用神经网络同时学习图片特征(image features)和空间信息(spatial context),这是处理姿态估计问题必不可少的两样信息。在此之前,我们多使用CNN来提取图片特征,使用graphical model或其他模型来表达各个身体部位在空间上的联系。使用神经网络同时学习这两种信息,不仅效果更好,而且使端到端(end-to-end)学习成为可能。
CPM是一个multi-stage的结构,如下图所示。每个stage的输入是原始图片特征和上一个阶段输出的belief map,这个belief map可以认为是之前的stage学到的spatial context的一个encoding。这样当前stage根据这两种信息继续通过卷积层提取信息,并产生新的belief map,这样经过不断的refinement,最后产生一个较为准确的结果。
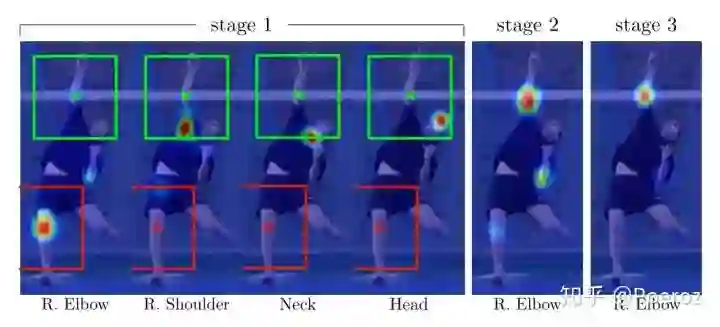
下面这张图给出了一个具体的例子来强调spatial context的重要性,也展现了refinement的过程。在stage1时,错误的将right elbow定位到了right knee处;在stage2时,由于有了stage1提供的spatial context信息,我们根据right shoulder的位置能够对right elbow的位置进行纠正,从图中可以看到响应的峰值已经基本到了正确位置。在stage3时,stage2中一些错误的响应(left elbow、right knee)彻底被消除,right elbow的定位也更加精确。
这篇文章还提出了很重要的一点,就是通过intermediate supervision来解决梯度消失的问题。由于我们的网络可以包含许多个stage,随着网络的加深,梯度消失问题的出现导致网络无法收敛。因此,在每个stage结束后我们给当前的belief map加一个监督,可以有效缓解梯度消失的问题,后面可以看到在multi-stage的网络中这是比较常用的一种技巧。
Hourglass
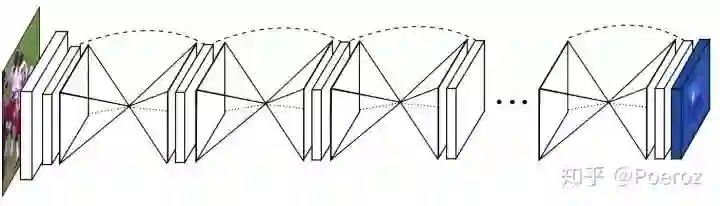
Hourglass也是一种multi-stage的结构,是2016年的一个工作,与CPM相比更加简洁一些,如下图所示。这个网络由多个堆叠起来的Hourglass module组成(因为网络长的很像多个堆叠起来的沙漏)。每个Hourglass module的结构都包含一个bottom-up过程和一个top-down过程,前者通过卷积和pooling将图片从高分辨率降到低分辨率,后者通过upsample将图片从低分辨率恢复到高分辨率。
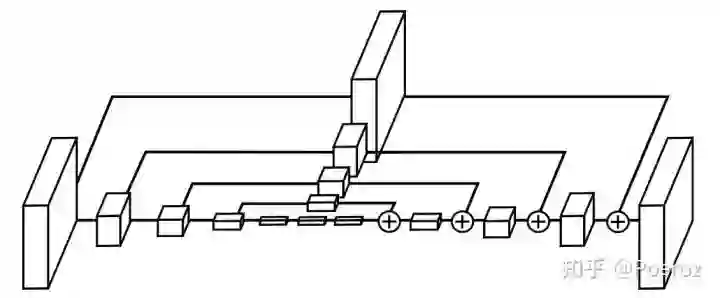
每个Hourglass module的结构如下图所示,其中每个box都是一个残差结构。可以看到在top-down阶段,对于两个相邻分辨率的feature map,我们通过upsampling(这里用的是nearest neighbor upsampling)对较低分辨率的feature map进行上采样,然后通过skip connection将bottom-up阶段较高分辨率的feature map拿过来,此时再通过element-wise addition将这两部分特征进行合并。通过这种方式,在top-down阶段将不同分辨率下的特征逐步进行了融合。
总而言之,Hourglass最大的特点就是能够提取并整合所有scale下的特征,这种设计的出发点也是出于我们在姿态估计时对各个不同scale下特征的需要。这种网络结构在当时达到了很好的效果。
值得注意的是,Hourglass也使用了intermediate supervision,对于multi-stage的网络这一点通常是必要的。
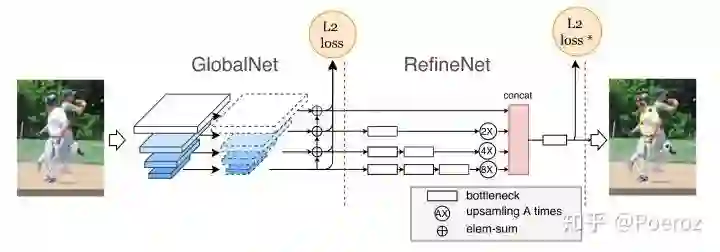
CPN
CPN,Cascaded Pyramid Network,是2017年旷视提出的一种网络结构,获得了COCO 2017 Keypoint Benchmark的冠军,网络结构如下图所示。这个网络可以分为两部分:GlobalNet和RefineNet,从名字也可以看出后半部分网络是在前半部分的基础上做refinement。GlobalNet的作用主要是对关键点进行一个初步的检测,由于使用了强大的ResNet作为backbone,网络能够提取到较为丰富的特征(在此之前的CPM、Hourglass都没有使用,因此网络的特征提取能力较差),并且使用了FPN结构加强了特征提取,在这个过程中像head、eyes这些简单且可见的关键点基本能够被有效地定位。而对于GlobalNet没有检测到的关键点,使用RefineNet进行进一步的挖掘,RefineNet实际上是将pyramid结构中不同分辨率下的特征进行了一个整合,这样一些被遮挡的、难以定位的关键点,根据融合后的上下文语境信息能够更好的被定位到。
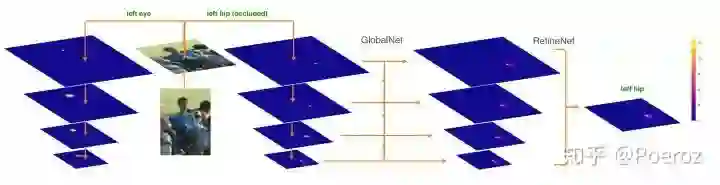
下面这张图给出了一个例子(绿点表示ground truth),对于eye来说较容易定位,通过GlobalNet即可定位到。而对于hip来说,在原图中被遮挡,仅仅使用GlobalNet难以直接精确定位。通过RefineNet将语境信息整合进来,才使得这些关键点被定位。
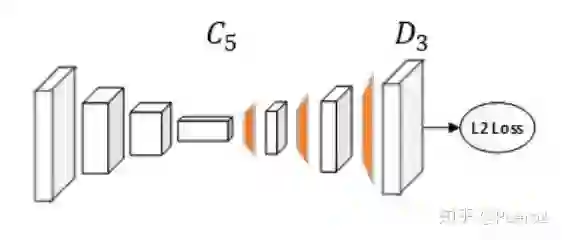
Simple Baselines
Simple Baselines,是2018年MSRA的工作,网络结构如下图所示。之所以叫这个名字,是因为这个网络真的很简单。该网络就是在ResNet的基础上接了一个head,这个head仅仅包含几个deconvolutional layer,用于提升ResNet输出的feature map的分辨率,我们提到过多次高分辨率是姿态估计任务的需要。这里的deconvolutional layer是一种不太严谨的说法,阅读源代码可知,deconvolutional layer实际上是将transpose convolution、BatchNorm、ReLU封装成了一个结构。所以关键之处在于transpose convolution,可以认为是convolution的逆过程。
从图中看可以发现Simple Baselines的网络结构有点类似Hourglass中的一个module,但可以发现:①该网络没有使用类似Hourglass中的skip connection;②该网络是single-stage,Hourglass是multi-stage的。但令人惊讶的是,该网络的效果却超过了Hourglass。我个人认为有两点原因,一是Simple Baselines以ResNet作为backbone,特征提取能力相比Hourglass更强。二是Hourglass中上采样使用的是简单的nearest neighbor upsampling,而这里使用的是deconvolutional layer,后者的效果更好(后面可以看到在MSRA的Higher-HRNet中依旧使用了这种结构)。
HRNet
HRNet,是2019年MSRA的工作,网络结构如下图所示,这个网络结构和之前的相比还是很novel的。我们知道,要想准确定位关键点,既离不开高分辨率的表示,也离不开低分辨率的语义信息。之前提到的几种网络结构也都着力于充分利用多个分辨率的信息,但之前的网络比如Hourglass、Simple Baselines,都是经历了一个先bottom-up再top-down的过程,换言之,我们得到的高分辨率的feature map都是从低分辨率的feature map经过upsampling/deconvolution恢复过来的,这样总会有一些潜在的信息丢失。HRNet的最大特点就是将不同分辨率feature map之间的连接从串行改成了并行,从图中可以清楚的看到,在整个过程中一直保持高分辨率分支的存在,并且随着网络的深入,逐渐添加低分辨率的分支,最后网络结构就是同时保持多个分辨率分支的并行网络。
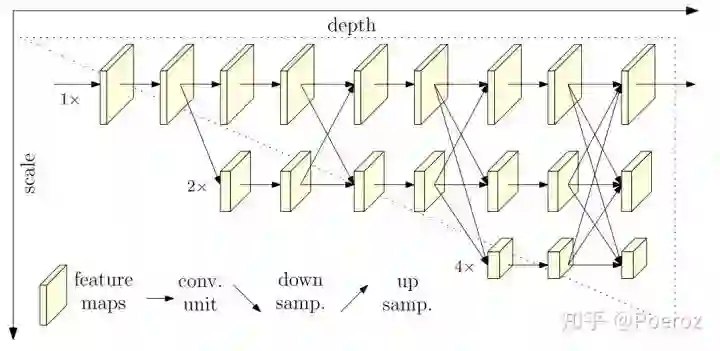
此外非常重要的一点,从图中我们也可以看到,为了使不同分辨率之间的信息融合在一起,从而获得包含多个分辨率下信息的feature map,在相邻的stage之间(每添加一个新的低分辨率分支时视为一个新stage的开始)加了fusion结构,fusion直观上类似在两边的feature maps之间加了一个fc层,下采样通过多个 

值得一提的是,MSRA后来在HRNet上做了一点微小的改动,称为HRNetv2。HRNetv1输出的feature map(heatmap)是最后一层最高分辨率的feature map,HRNetv2输出的feature map(heatmap)是最后一层所有分辨率的feature map变换scale后concat在一起。之后他们将该任务应用到了object detection、semantic segmentation、facial landmark detection等其他多个任务上,在许多数据集上达到了SOTA。
MSPN
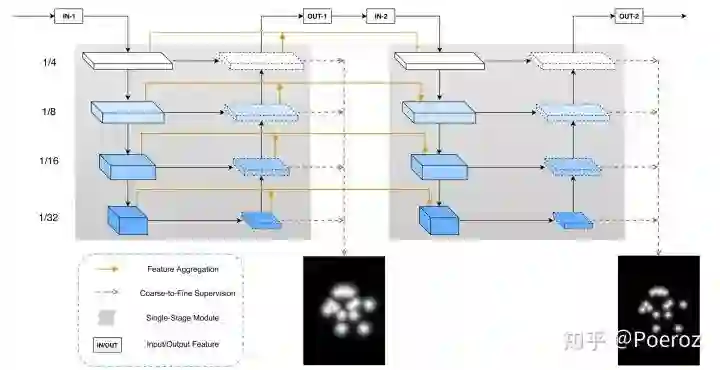
MSPN,是2019年旷视的工作,网络结构如下图所示。此前我们介绍的网络中,有single-stage的例如CPN、Simple Baselines,也有multi-stage的如CPM、Hourglass,理论上multi-stage的效果应该更好,但实际上在COCO数据集上single-stage的表现超过了multi-stage。MSPN沿用了multi-stage的思路,并做出了一系列改进,最终使得MSPN的效果超过了当前的single-stage网络。
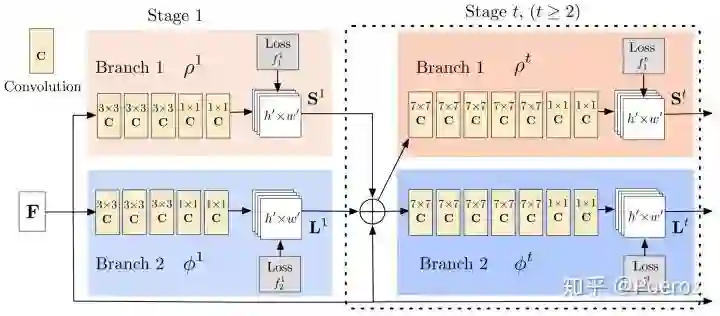
首先,对于每个stage的module,MSPN采用了前面提到的CPN中的GlobalNet(backbone为ResNet),当然这里使用其他backbone也没问题。其次,MSPN增加了跨阶段的特征融合,即图中的黄色箭头。由于经过反复的下采样-上采样,会有不可避免的信息损失,故MSPN中将前一个stage下采样和上采样过程中对应分辨率的两个feature maps都连接过来,与当前stage下采样的feature map进行融合,这样当前stage得到的feature map就包含了更多prior information,减少了stage之间的信息丢失。此外,这种类似残差结构的设计也有助于缓解梯度消失问题。最后,MSPN还采用了coarse-to-fine supervision,我们知道姿态估计的ground truth是以关键点为中心的二维高斯分布,这里的高斯核大小是一个超参数。直观上来说,对于multi-stage网络,随着stage的增加,我们对keypoint的估计是一个coarse-to-fine的过程,这样我们进行intermediate supervision的时候,可以将ground truth也设置成coarse-to-fine的heatmap,也就是前面stage的高斯核较大,后面stage的高斯核较小,随着stage的增加要求关键点位置越来越精确。
Bottom-up
前面我们提到诸多top-down的方法都是将多人姿态估计转化为单人姿态估计问题,但在进行多人姿态估计时,top-down的方法有两个缺点:①性能受到detector性能的影响(虽然在CPN的论文中证明了当detector性能足够好时提高detector的性能对最后的结果提高很微小);②运行时间随着图片中人数增加而增加。而bottom-up的方法则是另一条思路:先检测出图中所有人的所有关键点,再对关键点进行分组,进而组装成多个人。这种方法的好处是性能受人数影响较小,实际上bottom-up的速度往往会比top-down的更快,几乎能做到real-time,在移动端部署的时候往往采用的也是bottom-up的方法。接下来介绍近年出现的一些有代表性的bottom-up的工作。
Openpose
Openpose是2016年CMU的一个工作,获得了COCO 2016 Keypoints challenge的冠军,这个工作在后来产生了很大的影响,github上目前有15.8k个stars。下图是openpose的pipeline,首先根据输入图片(a)生成一个Part Confidence Maps(b)和一个Part Affinity Fields(c):前者就是我们上文常提到的heatmap,用来预测关键点的位置;后者是本文的一个主要创新点)——PAF,PAF实际上是在关键点之间建立的一个向量场,描述一个limb的方向。有了heatmap和PAF,我们使用二分图最大权匹配算法来对关键点进行组装(d),从而得到人体骨架(e)。由于文字描述过于抽象,下面花一些篇幅引用原文中的一些数学表达形式来分别介绍这几部分。

对于生成heatmap和PAF的部分,使用了下图所示的网络结构。首先 










接下来需要说明heatmap和PAF的ground truth分别是怎样的。heatmap和top-down中的类似,对于第 




PAF的ground truth则更加复杂,对于第 







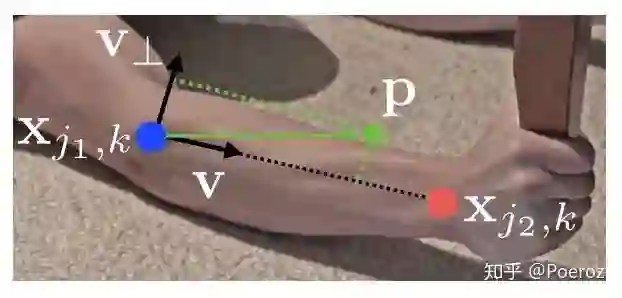
至于loss的计算,就是对每个stage的
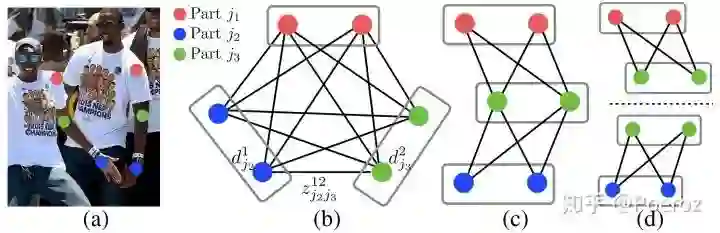
现在我们有了heatmap,在heatmap上采用nms可以为每个part找出一系列候选点(因为图中有不止一个人,以及false positive的点),这些候选点之间互相组合能够产生大量可能的limb,如何从中选出真正的limb,这就需要使用我们预测的PAF。首先定义两个关键点 




知道了如何计算两个候选点之间组合的权值,对于任意两个part对应的候选点集合,我们使用二分图最大权匹配算法即可给出一组匹配。但如果我们考虑所有part之间的PAF,这将是一个K分图最大权匹配问题,该问题是NP-Hard的。因此我们做一个简化,我们抽取人体骨架的一棵最小生成树,这样对每条树边连接的两个part采用二分图最大权匹配来求解,不同树边之间是互不干扰的。也就是将原问题划分成了若干个二分图最大权匹配问题,最后将每条树边对应的匹配集合组装在一起即可得到人体骨架。
上述即openpose的整个pipeline,虽然看起来比较复杂,但许多想法都是围绕PAF展开的,毕竟PAF还是这篇文章最大的亮点。
Hourglass+Associative Embedding
Associative embedding,是一种处理detection+grouping任务的方法。也就是先检测再组装的任务,比如多人姿态估计是检测出所有关键点再组装成多个人体,实例分割是先检测出所有像素点的语义类别再组装成多个实例。往往这类任务都是two-stage的,即先detection,再grouping。这篇文章的作者提出了一种新的思路:同时处理detection和grouping两个任务,这么做的初衷是因为detection和grouping两个任务之间本身密切相关,分成两步来先后处理可能会导致性能下降。作者将该方法应用到了Hourglass上,在当时达到了多人姿态估计任务的SOTA。
在单人姿态估计时,我们网络的输出是m个heatmap,m表示关键点数量。现在在之前的基础上多输出了m个associative embeddings。Associative embeddings实际上是给heatmap的每个值都额外嵌入一个vector作为一个tag用于标识所在的组,拥有相同tag的所有关键点我们将其划分为一组,也就是属于某一个人。下图是Hourglass+Associative embedding的示意图,Hourglass输出了m个detection heatmaps(灰色)和m个associative embeddings(蓝色),根据heatmaps上的响应值确定关键点的坐标,根据embeddings上的tag(下图中不同tag用不同颜色表示)确定哪些关键点属于同一个人。
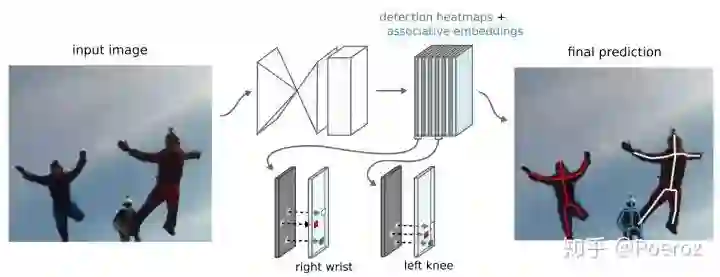
现在我们考虑ground truth,对于heatmaps来说和之前一样,不再赘述。对于embeddings来说实际上没有ground truth,因为tag的绝对值并不重要,只要保证同一个人的关键点tag相同,不同人的关键点tag之间互不相同即可。这里需要说明的是,tag虽然是一个vector,但vector的维数并不重要,实践证明1D vector已经足够(即一个实数)。为了使tag满足上述要求,我们需要设计一个loss来评价当前的tag是否符合实际的分组。用 







HigherHRNet
HigherHRNet,是微软在HRNet之后延续的一个工作。前面我们提到过HRNet在top-down的方法中表现的很好,是因为这种并行的结构使得最后的feature map能够包含各个分辨率的信息,尤其是对高分辨率信息保留的效果较之前提升尤为明显。在bottom-up的方法中,作者认为有两个问题需要解决:①scale variation,即图片中有各种scale的人,如果仅仅在一个分辨率的feature map下进行预测,难以保证每个scale的人的关键点都能被精确预测;②精确定位small person的关键点。之前一些网络在推理时使用multiscale evaluation,能够缓解问题①,但仍然无法解决问题②,对small person的预测不够精确。
HigherHRNet的思路是首先使用HRNet生成feature map(最高分辨率分支),然后接一个类似Simple Baselines中的deconvolution层,生成一个更高分辨率的feature map。显然,更高分辨率的feature map有助于更加精确地定位small person的关键点(实践证明接一层deconv. module足够)。在训练时,使用multi-resolution supervision,即对原图1/4和1/2大小的两个feature map同时进行监督,这样做是为了在训练时就使网络获得处理scale variation的能力,1/4的feature map主要处理大一些的人,1/2的feature map主要处理小一些的人,而不是在推理时依赖multiscale evaluation处理scale variation的问题。在推理时,使用multi-resolution heatmap aggregation,即将不同分辨率的heatmap取平均用于最后的预测,也是为了处理scale variation。

前面仅仅讨论了如何生成一个准确且scale-aware的heatmap,对于grouping采用的也是上文提到的associative embedding。最后这个工作达到了SOTA,是目前bottom-up方法中性能最强劲的网络之一。
参考文献
Convolutional Pose Machines, Wei etc, CVPR 2016
Stacked Hourglass Networks for Human Pose Estimation, Newell etc, ECCV 2016
Cascaded Pyramid Network for Multi-Person Pose Estimation, Chen etc, CVPR 2017
Simple Baselines for Human Pose Estimation and Tracking, Xiao etc, ECCV 2018
Deep High-Resolution Representation Learning for Human Pose Estimation, Sun etc, CVPR 2019
Rethinking on Multi-Stage Networks for Human Pose Estimation, Li etc, Arxiv 2019
Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields, Cao etc, CVPR 2017
Associative Embedding: End-to-End Learning for Joint Detection and Grouping, Newell etc, NIPS 2017
Bottom-up Higher-Resolution Networks for Multi-Person Pose Estimation, Cheng etc, Arxiv 2019
---End---
科研学术,寒假不打烊!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎加入CVer学术交流群。涉及图像分类、目标检测、图像分割、人脸检测&识别、目标跟踪、GANs、Re-ID、医学影像分析、姿态估计、OCR、SLAM、场景文字检测&识别、PyTorch和TensorFlow等方向。
▲扫码进群

▲长按关注我们
麻烦给我一个在看!

