学界 | 复现深度强化学习结果所面临的挑战与建议
选自arXiv
机器之心编译
参与:蒋思源、路雪
本论文对强化学习顶尖试验结果的复现性进行了详细的探讨,并讨论了超参数和随机种子等变量对强化学习模型复现性的重要影响。除此之外,作者还对复现实验所面临的挑战和实验技巧做出了详细的论述。机器之心简要介绍了该论文。
论文地址:https://arxiv.org/abs/1709.06560

近年来,深度强化学习(RL)被用于解决很多领域中的难题,并取得了令人瞩目的成绩。为了保持快速发展的局面,复现(Reproducing)已有的研究并准确评估新方法所带来的进步是很重要的。可惜,顶尖的深度强化学习方法很少能被简单的复现。尤其是,标准基准环境中的不确定性和不同方法之间的内在差异导致研究中的结果难以理解。如果实验过程缺乏显著性的度量和严格的标准化,则我们很难确定先前顶尖技术取得的进展是否有意义。在这篇论文中,我们研究了复现实验所面临的挑战、合适的实验技巧和报告流程。通过与常见基准进行对比,我们阐释了报告中度量方法和结果的可变性,同时提出了使深度强化学习未来的研究成果更易复现的指南。我们希望减小研究人员在不可复现和易误解的结果上花费精力,并引起大家对如何使该领域持续发展进行讨论。
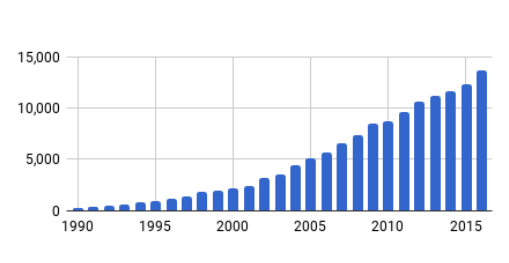
图 1:已发布的强化学习论文增长趋势图,展示了每年(x 轴)强化学习相关论文(y 轴)的数量。
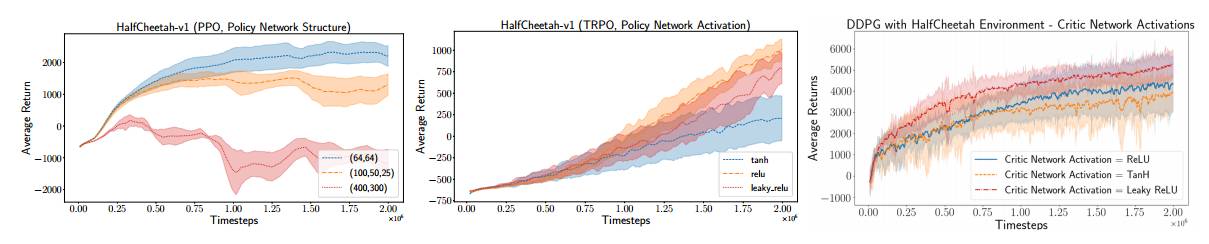
图 2:策略网络结构(Policy Network Structure)和激活函数 PPO(左)和 DDPG(右)的作用。
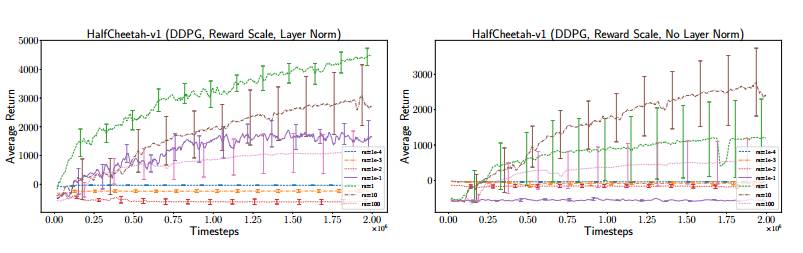
图 3:DDPG 在 HalfCheetah-v1 上的奖励尺度,左图有层范数(layer norm),右图无层范数。
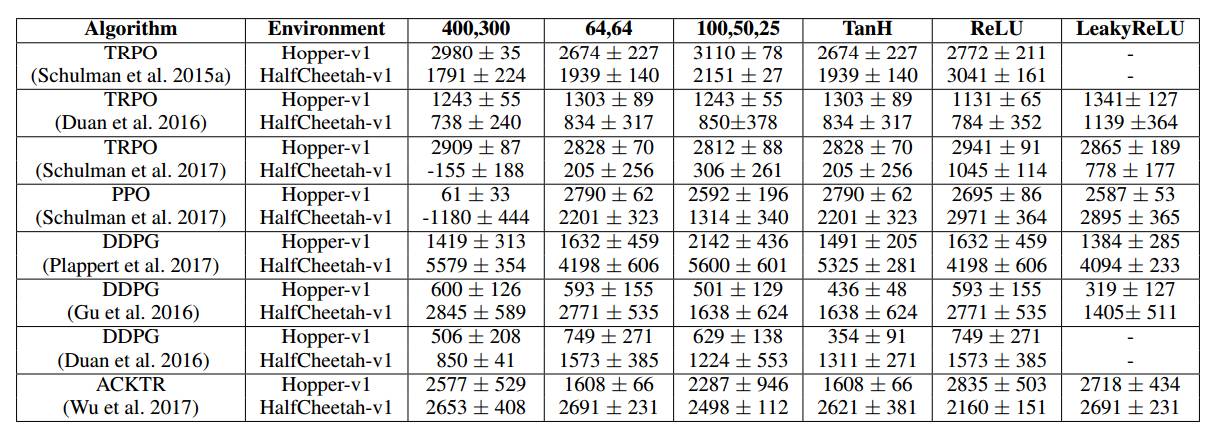
表 1:我们的策略架构在不同的实现和算法中的排列结果。图中为 5 个返回试验结果的最终平均值 ± 标准误差。在 ACKTR 中,我们使用 elu 激活函数代替 leaky relu。
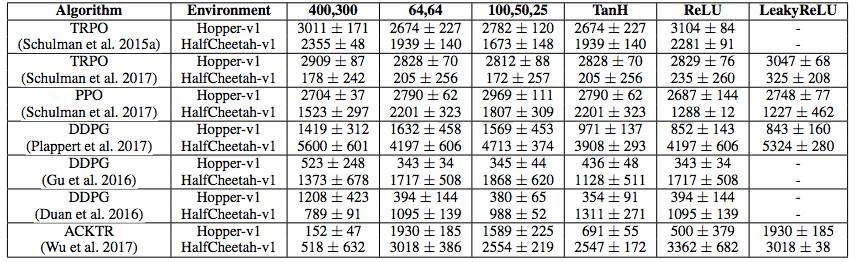
表 2:我们的价值函数(Q 或 V)架构在不同的实现和算法中的排列结果。图中为 5 个返回试验结果的最终平均值 ± 标准误差。在 ACKTR 中,我们使用 elu 激活函数代替 leaky relu。
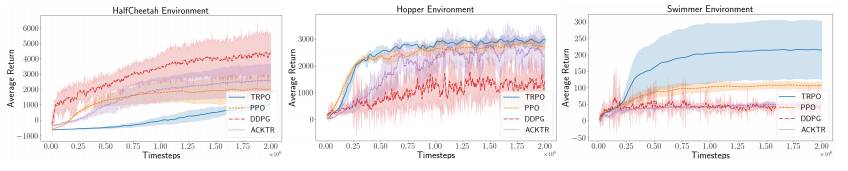
图 4:多个策略梯度算法在基准 MuJoCo 环境组中的表现。

表 3:bootstrap 平均值和环境实验子集的 95% 置信界限。使用了 10k bootstrap 迭代和枢轴法(pivotal method)。
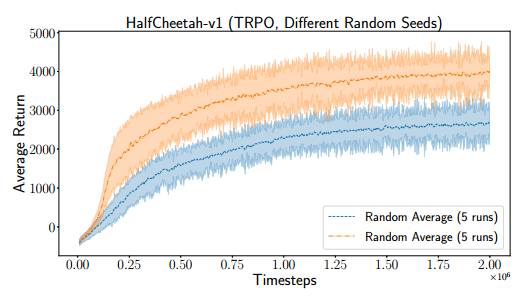
图 5:在 HalfCheetah-v1 运行的两个不同 TRPO 实验,两个实验具备同样的超参数,并在 5 个随机种子的两次中取平均值。
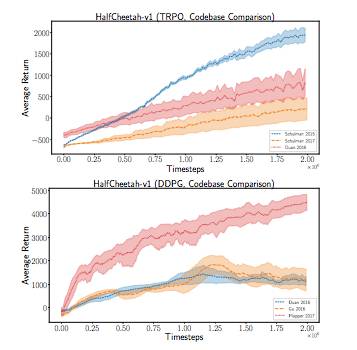
图 6:使用默认的超参数集对比 TRPO 代码库。
结语
通过对连续控制的 PG 方法进行实验和研究,我们探讨了 RL 中的复现性(reproducibility)问题。我们发现非确定性的内在源(如随机种子和环境属性等)和外在源(如超参数和代码库等)都可能导致复现基线算法出现困难。此外,我们发现由于内在源(intrinsic source)而产生的高度多样性结果加大了使用适当显著性分析的需要。我们提出了多种方法,并在实验子集上展示了它们的值。
我们能从这项实验中得到什么建议?
基于实验结果和调研,我们可以提出一些通用建议。不同的超参数在相同的算法和环境中可以产生截然不同的影响,因此通过标准优化和超参数搜索找出与原报告中基线算法性能匹配的工作集非常重要。同理,新的基线代码库(baseline codebase)需要匹配原代码库的结果。总体而言,由于强化学习算法的试验与随机种子有很大的差异性,在比较性能时,许多试验必须使用不同的随机种子运行。通过不同随机种子平均多次运行可以深入了解环境中算法性能的总体分布(population distribution),除非随机种子的选择是算法的明确部分。
由于这些影响,进行适当的显著性检验(significance testing)是非常重要的,因为它可以确定更高的平均奖励是否能够代表实际上更优的性能。我们强调了几种显著性检验的形式,发现在考虑到置信区间时,它们能给出普遍预期的结果。此外,我们展示了 bootstrapping 和 power analysis 作为了解试验运行次数的可行方法,以对算法性能增益的显著性做出明智的决定。然而一般来说,复现性最重要的步骤是报告所有基线对比方法和前沿工作的超参数、实现细节、实验设置和评估方法等。如果没有发布与实现相关的具体细节,那么在复现顶尖研究工作上浪费精力会给研究社区带来困扰,并减缓研究进度。
未来的调研线路是什么?
由于超参数对性能的极大影响力(特别是奖励尺度/reward scaling),未来比较重要的调研路线就是构建超参数不可知(agnostic)的算法。这种方法可以确保在比较奖励尺度、批量大小或网络结构等算法未知的参数时,从外部源不会引入不公平性。此外,虽然我们调研了一系列显著性度量(significance metrics),但它们可能并不是比较 RL 算法的最佳方法。
我们如何确保深度强化学习的重要性?
我们讨论了影响强化学习算法复现性的多种不同因素。然而,RL 算法是以优化预先指定的奖励函数为中心的。这些奖励函数类似于机器学习中的成本函数,而 RL 算法就是一种优化方法。由于某些算法特别容易受到奖励尺度和环境动力学(environment dynamics)的影响,也许我们更需要强调 RL 算法在现实任务中的适应性,就像成本优化(cost-optimization)方法那样。
也许新方法应该回答这样的问题:哪些设定使该研究有用?在研究社区中,我们必须使用公平的对比确保结果是可控的和可复现的,但是我们同样还需要用什么方法能够确保强化学习保持其重要性。
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



