单模型可完成6项NLP任务,哈工大SCIR LTP再度升级,4.0版本面世
机器之心编辑部
迄今为止,这一 NLP 开源基础技术平台在 GitHub 上共获得了 2.5k 的 Star 量,760 多个 Fork 数量,被包括清华大学、北京大学、CMU 等国内外众多大学及科研机构在内的 600 余家研究单位签署协议使用。
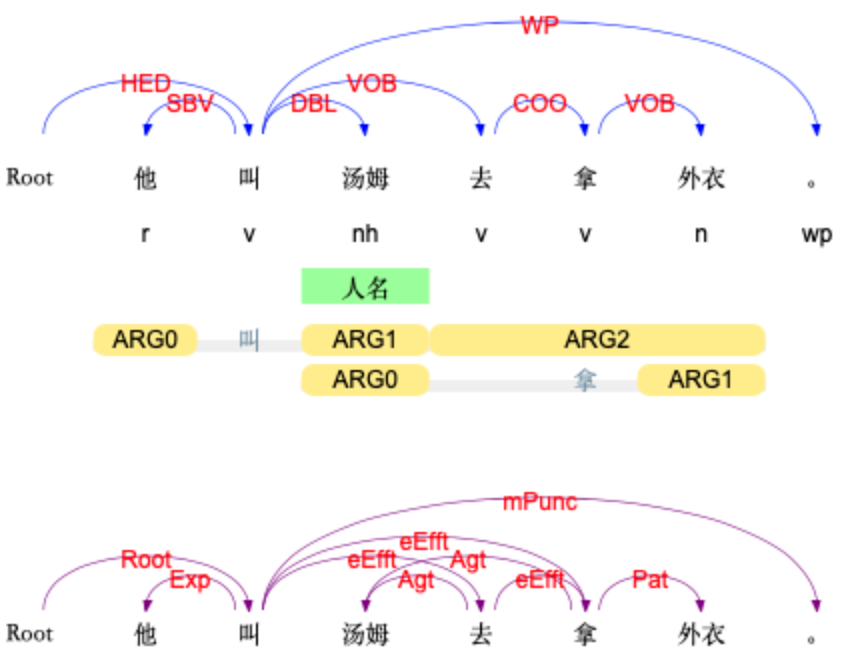
基于多任务学习框架进行统一学习,使得全部六项任务可以共享语义信息,达到了知识迁移的效果。既有效提升了系统的运行效率,又极大缩小了模型的占用空间
基于预训练模型进行统一的表示 ,有效提升了各项任务的准确率
基于教师退火模型蒸馏出单一的多任务模型,进一步提高了系统的准确率
基于 PyTorch 框架开发,提供了原生的 Python 调用接口,通过 pip 包管理系统一键安装,极大提高了系统的易用性。
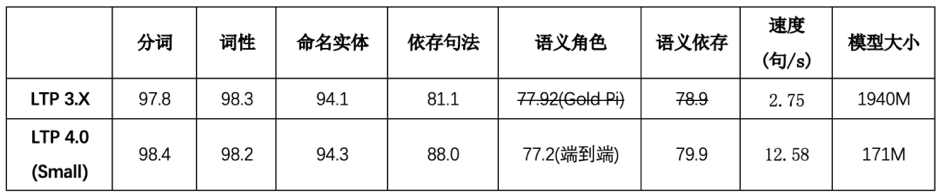
Python 3.7
LTP 4.0 Batch Size = 1
CentOS 3.10.0-1062.9.1.el7.x86_64
Intel(R) Xeon(R) CPU E5-2640 v4 @ 2.40GHz
from ltp import LTP
ltp = LTP() # 默认自动下载并加载 Small 模型
segment, hidden = ltp.seg(["他叫汤姆去拿外衣。"])
pos = ltp.pos(hidden)
ner = ltp.ner(hidden)
srl = ltp.srl(hidden)
dep = ltp.dep(hidden)
sdp = ltp.sdp(hidden)
登录查看更多
相关内容





相关VIP内容
相关资讯
相关论文