高能预警 | 饿了么IT老兵如何构建列式存储内存数据库?

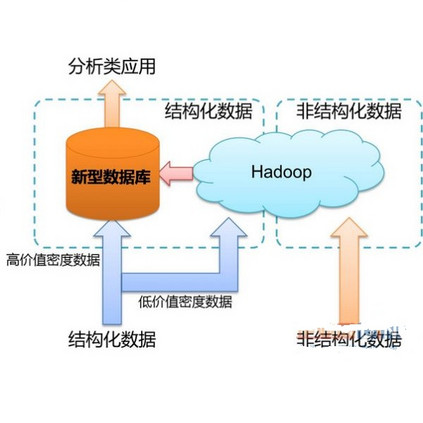
诸如Hadoop体系的通用大数据存储计算平台一般无法满足数据处理的时效性,一般只支持T+1的时效性和关键业务小时级别的数据延迟;很多场景下大数据量的磁盘IO(或首次IO)会引起查询响应延迟比较高,无法满足快速实时查询的要求。
很多技术团队采取预先聚合数据的方式来达到实时查看数据结果的目标,但缺点是无法分析和查询聚合前的详细数据,随着业务的深入发展,精细化运营经常会需要直接查询聚合前的原始数据。
内存数据库的优势在于查询性能快,在内存中直接对原始数据记录进行查询和聚合分析,采用了大量灵活的数据编码方法和压缩算法支持更大的数据容量限制。
想了解内存分析数据库的架构设计
及关键技术的选择?
弄清列式存储内存数据库特性及适用场景?
dbaplus社群特邀饿了么CI高级架构师
分享“构建列式存储内存数据库的实践之路”
今晚(2月27日晚上8点)约定你!


登录查看更多
相关内容

专知会员服务
15+阅读 · 2020年3月7日
Arxiv
11+阅读 · 2019年9月8日
Arxiv
7+阅读 · 2018年5月22日



相关VIP内容
专知会员服务
15+阅读 · 2020年3月7日
相关资讯
相关论文
Arxiv
11+阅读 · 2019年9月8日
Arxiv
7+阅读 · 2018年5月22日