从知乎[悟空]看一个成熟的Anti-Spam系统演进之路
导读:作弊是互联网应用最常碰见的问题之一。有作弊就有反作弊,如果高效的对作弊内容进行识别,识别后又该如何处理作弊内容,每家公司都有自己的独门绝技。本文作者对知乎反作弊系统的演进进行了介绍,深入剖析了该系统的架构设计和演进历程,十分耐读。
Hi there! 距离 2015 年 4 月「悟空」正式与大家见面,已经整整三个年头了。随着知乎的不断发展壮大,过去的一段时间,「悟空」不断面临着新的考验,并持续地在优化升级。接下来跟大家系统分享一下这几年「悟空」的架构演进和构建过程中积累的经验与教训。
业务现状
截止2018年5 月,知乎已拥有 1.6 亿注册用户,近几年在问答,专栏文章之外,社区衍生出了一些新的产品线和产品形态。因此「悟空」对接的业务形态也得到了扩展,从最初重点控制的内容类 Spam ,扩展到行为类 Spam,交易风险等等。目前「悟空」已经覆盖了知乎 10 个业务线,近 100 个功能点。
总的来说,在知乎长期存在,且比较典型的Spam 有这么几类:
内容作弊Spam:这类Spam 的核心获益点一方面是面向站内的传播,另一方面,面向搜索引擎,达到 SEO 的目的。内容类的 Spam 是社区内主流的 Spam 类型,目前主要包括四种形式:
导流内容:这类Spam 大概能占到社区中 Spam 的 70% - 80%,比较典型的包括培训机构, 美容,保险,代购相关的 Spam。导流内容会涉及到 QQ,手机号,微信,url 甚至座机,在一些特殊时间节点还会出现各类的专项 Spam,比如说世界杯,双十一,双十二,都是黑产大赚一笔的好时机。
品牌内容:这类内容会具有比较典型的SEO 特色,一般内容中不会有明显的导流标识,作弊形式以一问一答的方式出现,比如提问中问什么牌子怎么样?哪里的培训学校怎么样?然后在对应的回答里面进行推荐。
诈骗内容:一般以冒充名人,机构的方式出现,比如单车退款类Spam,在内容中提供虚假的客服电话进行诈骗。
骚扰内容:比如一些诱导类,调查类的批量内容,非常严重影响知友体验。
行为作弊spam:主要包括刷赞,刷粉,刷感谢,刷分享,刷浏览等等,一方面为了达到养号的目的,躲过反作弊系统的检测,另一方面通过刷量行为协助内容在站内的传播。
治理经验
治理上述问题的核心点在于如何敏捷、持续地发现和控制风险,并保证处理成本和收益动态平衡,从Spam 的获益点入手,进行立体防御。所谓立体防御,就是通过多种控制手段和多个控制环节增强发现和控制风险的能力。
三种控制方式
策略反作弊:在反作弊的初期,Spam 特征比较简单的时候,策略是简单粗暴又有用的方式,能够快速的解决问题,所以策略在反作弊解决方案里是一个解决头部问题的利器。
产品反作弊:一方面通过改变产品形态来有效控制风险的发生,另一方面通过产品方案,对用户和Spammer 痛点趋于一致的需求进行疏导,有时候我们面对 Spam 问题,对于误伤和准确会遇到一个瓶颈,发现很难去区分正常用户和 Spammer,这种情况下反而通过产品方案,可能会有比较好的解决方案。
模型反作弊:机器学习模型可以充分提高反作弊系统的泛化能力,降低策略定制的成本。模型应用需要酌情考虑加入人工审核来保证效果,直接处理内容或用户的模型算法,要千万注意模型的可解释性。我们过去的使用经验来说,初期一些无监督的聚类算法能够在比较短时间内达到较好的效果。而有监督的分类算法,在时间上和人力上的耗费会更多,样本的完整程度,特征工程做的好坏,都会影响算法的效果。
三个控制环节
事前:事前涉及到的几个环节包括风险教育、业务决策参与、监控报警以及同步拦截。反作弊需要提升业务的风险意识,明确告知反作弊可以提供的服务;并在早期参与到业务决策,避免产品方案上出现比较大的风险;业务接入后,针对业务新增量、处理量、举报量,误伤量进行监控,便于及时发现风险;在策略层面,在事前需要针对头部明显的作弊行为进行频率和资源黑名单的拦截,减轻事中检测的压力。
事中:面向长尾曲线的中部,主要针对那些频率较低,且规律没有那么明显的作弊行为,针对不同嫌疑程度的行为与帐号,进行不同层级的处理,要么送审,要么限制行为,要么对内容和帐号进行处罚。
事后:面向长尾曲线最尾部的行为,即那些非常低频,或者影响没那么大,但是计算量相对大的作弊行为。由一些离线的算法模型和策略负责检测与控制,另外事后部分还涉及到策略的效果跟踪和规则的优化,结合用户反馈与举报,形成一个检测闭环。
悟空V1
初期「悟空」主要由事前模块和事中模块构成。
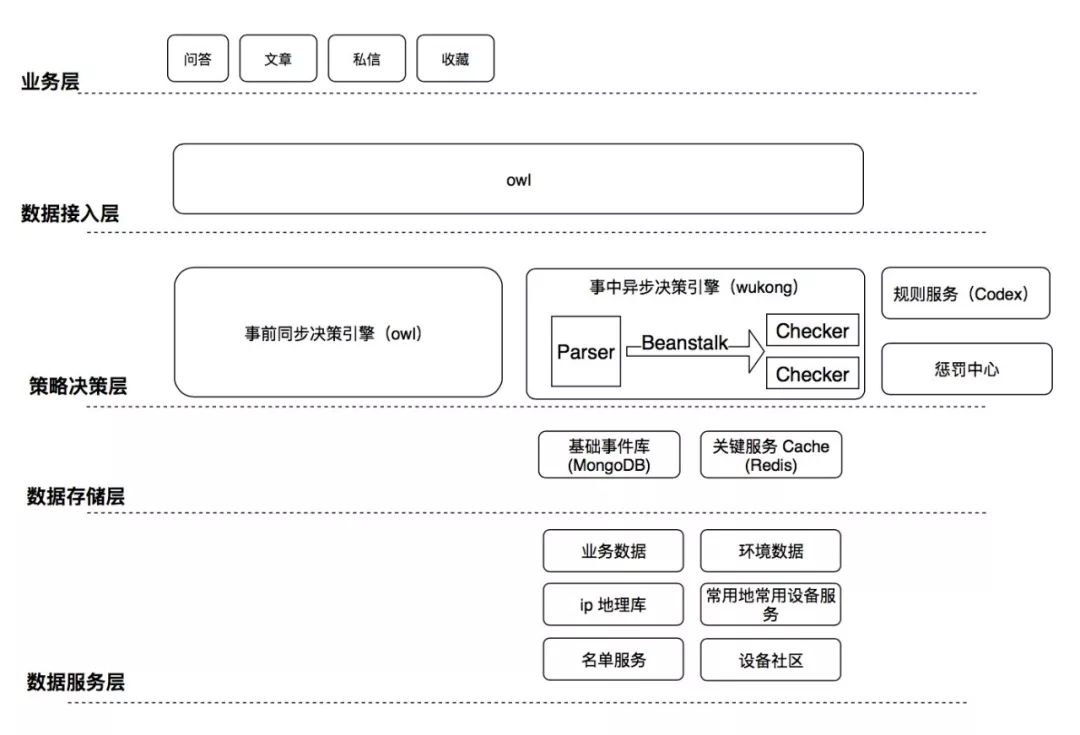
事前模块与业务串行执行,适用于做一些耗时短的频率检测,关键词和黑白名单拦截。由于是同步接口,为了尽量少的减少对业务的影响,大部分复杂的检测逻辑由事中模块去处理。
事中模块在业务旁路进行检测,适合做一些相对复杂,耗时长的检测。事中主要由Parser 和一系列 Checker 构成,Parser 负责将业务数据解析成固定格式落地到基础事件库,Checker 负责从基础事件库里取最近一段时间的行为进行策略检测。
事件接入
在反作弊的场景数据落地一般会涉及到这几个维度:谁,在什么时间,什么环境,对谁,做了什么事情。对应到具体的字段的话就是谁(UserID) 在什么时间 (Created) 什么环境 (UserAgent UserIP DeviceID Referer) 对谁 (AcceptID) 做了什么事情 (ActionType ObjID Content)。有了这些信息之后,策略便可以基于维度进行筛选,另外也可以获取这些维度的扩展数据(e.g. 用户的获赞数)进行策略检测。
策略引擎
「悟空」的策略引擎设计,充分考虑了策略的可扩展性。一方面支持横向扩展,即支持从基础维度获取更多的业务数据作为扩展维度,例如用户相关的信息,设备相关的信息,IP 相关的信息等等。另一方面纵向扩展也被考虑在内,支持了时间维度上的回溯,通过检测最近一段时间内关联维度 (e.g. 同一个用户,同一个 IP) 上的行为,更高效地发现和打击 Spam。
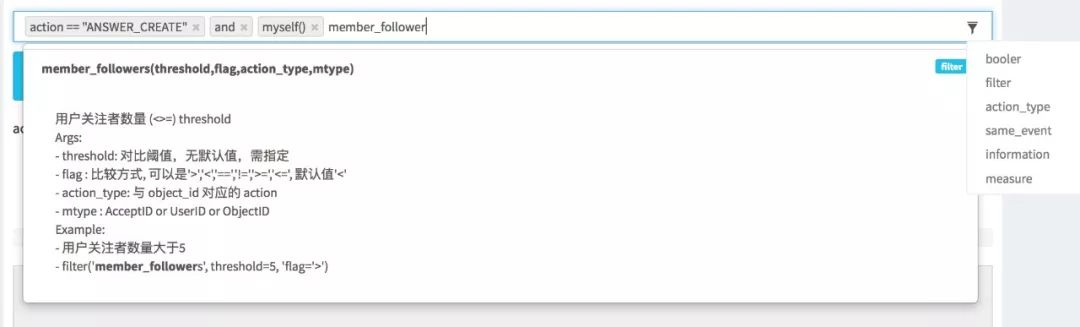
下面是一条典型的V1 的策略:
action == "ANSWER_CREATE" and len(user(same_register_ip(register_time(same_topics(same_type_events(10)),register_interval=3600)))) >= 3
这条策略主要实现了这样的逻辑:
最近10 分钟在同一话题下创建的回答,与当前用户,注册时间在一小时之内,同一 IP 下注册的用户数大于等于 3 个。
基本上这样的模式足够满足日常的Spam 检测需求,但是我们可以发现这种嵌套结构对于书写与阅读来说还是不太友好,这个部分的优化会在 V2 作详细描述。
考虑到策略变更会远大于基础模块,在V1 的架构中,我们特别将策略维护的逻辑单独拆分成服务,一方面,可以实现平滑上下线,另一方面,减少策略变更对稳定性带来的影响。
存储选型
存储上,我们选择了MongoDB 作为我们的基础事件存储,Redis 作为关键 RPC 的缓存。选择 MongoDB 的原因一方面是因为我们基础事件库的业务场景比较简单,不需要事务的支持;另一方面,我们面对的是读远大于写的场景,并且 90% 都是对最近一段时间热数据的查询,随机读写较少, 这种场景下 MongoDB 非常适合。另外,初期由于需求不稳定,schema-free 也是 MongoDB 吸引我们的一个优点。由于我们策略检测需要调用非常多的业务接口,对于一些接口实时性要求相对没那么高的特征项,我们使用 Redis 作为函数缓存,相对减少业务方的调用压力。
悟空V2
「悟空V1」已经满足了日常的策略需求,但是在使用过程我们也发现了不少的痛点:
策略学习曲线陡峭, 书写成本高:上面提到的策略采用嵌套结构,一方面对于产品运营的同学来说学习成本有点高,另一方面书写过程中也非常容易出现括号缺失的错误。
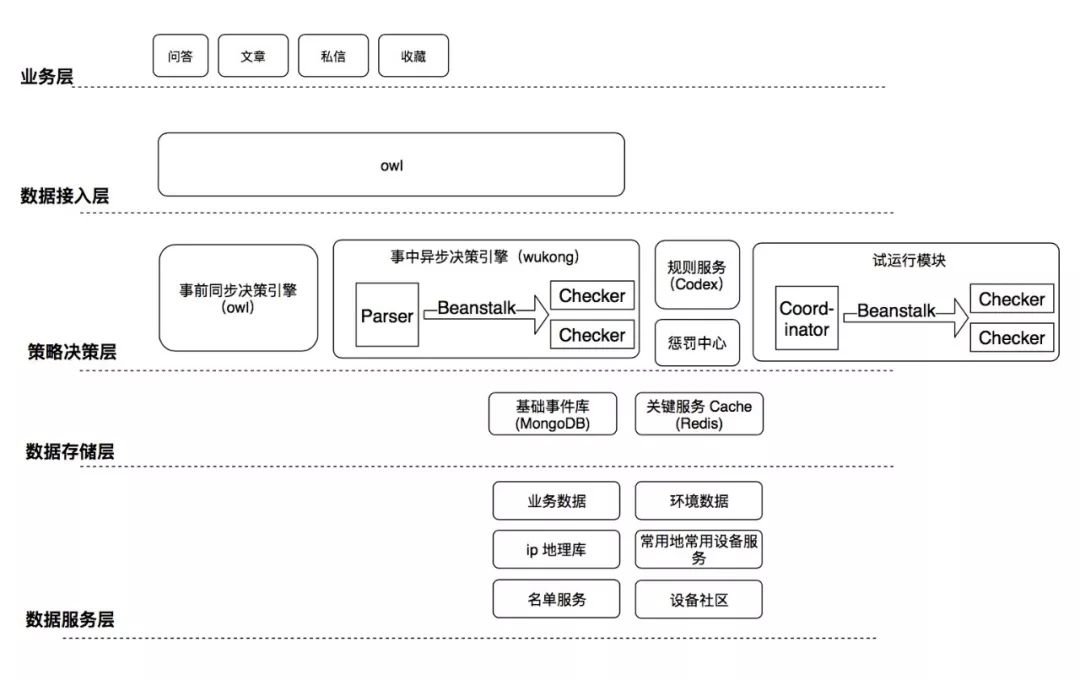
策略制定周期长:在「悟空V1」上线一条策略的流程大概会经过这几步, 产品制定策略 - 研发实现策略 - 研发上线策略召回 - 产品等待召回 - 产品确认策略效果 - 上线处理。整个环节涉及人力与环境复杂,策略验证麻烦,耗时长,因此策略试错的成本也会很高。
鉴于此,「悟空V2」着重提升了策略自助配置和上线的体验,下面是「悟空 V2」的架构图:
策略结构优化
参考函数式语言,新的策略结构引入了类spark 的算子:filter, mapper, reducer, flatMap, groupBy 等等,一般基础的策略需求通过前三者就能实现。
举个例子,上面提到的策略在优化之后,会变成下面这种格式:
action == "ANSWER_CREATE" and same_type_events(10).filter('same_register_ip').filter('register_time',register_interval=3600).filter('same_topics',mtype='AcceptID').mapper('userid').reducer('diff').length >= 3
结构上变得更清晰了,可扩展性也更强了,工程上只需要实现可复用的算子即可满足日常策略需求,不管是机器学习模型还是业务相关的数据,都可以作为一个算子进行使用。
策略自助配置
完成了策略结构的优化,下一步需要解决的,是策略上线流程研发和产品双重角色交替的问题,「悟空V2」支持了策略自助配置,将研发同学彻底从策略配置中解放出去,进一步提升了策略上线的效率。
策略上线流程优化
如何使策略上线变得更敏捷?这是我们一直在思考的问题。每一条上线的策略我们都需要在准确率和召回率之间权衡,在尽量高准确的情况下打击尽量多的Spam,因此每条要上线的策略都需要经过长时间的召回测试,这是一个非常耗时并且亟待优化的流程。「悟空 V2」策略上线的流程优化成了:创建策略 - 策略测试 - 策略试运行 - 策略上线处理 - 策略监控。
策略测试主要用于对策略进行初步的验证,避免策略有明显的语法错误。
策略试运行可以理解成快照重放,通过跑过去几天的数据,快速验证策略效果,一切都可以在分钟级别完成。这部分的实现我们将策略运行依赖的资源复制了一份,与生产环境隔离,实现一个coordinator 将历史的事件从 MongoDB 读出并打入队列。值得注意的是,入队速度需要控制,避免队列被瞬间打爆。
通过试运行的验证之后,策略就可以上线了。上线之后,策略监控模块提供了完善的指标,包括策略执行时间、策略错误数、策略命中及处理量等等,数据有所体现,方能所向披靡。
悟空V3
2016 年中旬,知乎主站各业务开始垂直拆分,相应的,「悟空」业务接入成本的简化开始提上日程。
Gateway
Gateway 负责与 Nginx 交互,作为通用组件对在线流量进行风险的阻断。目前 Gateway 承担了所有反作弊和帐号安全用户异常状态拦截、反作弊功能拦截和反爬虫拦截。这样一来,这部分逻辑就从业务剥离了出来,尤其是在业务独立拆分的情况下,可以大大减少业务的重复工作。作为通用组件,也可以提升拦截逻辑的稳定性。Gateway 当前的架构如下图所示:
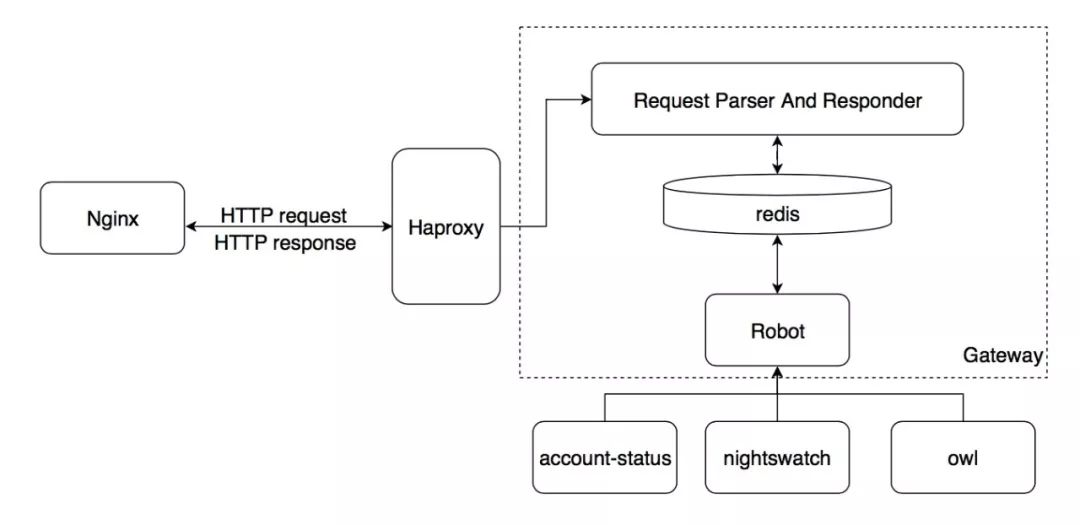
由于是串行组件,所有请求要求必须在10ms 内完成,因此所有的状态都缓存在 Redis。Gateway 对外暴露 RPC 接口(Robot),相关服务调用 Robot 更新用户,IP,设备等相关的状态到 Redis。 当用户请求到达时,Nginx 请求 Gateway,Gateway 获取请求中的 IP,用户 ID等信息, 查询 Redis 返回给 Nginx。当返回异常状态时 Nginx 会阻断请求,返回错误码给前端和客户端。
TSP - Trust & Safety Platform
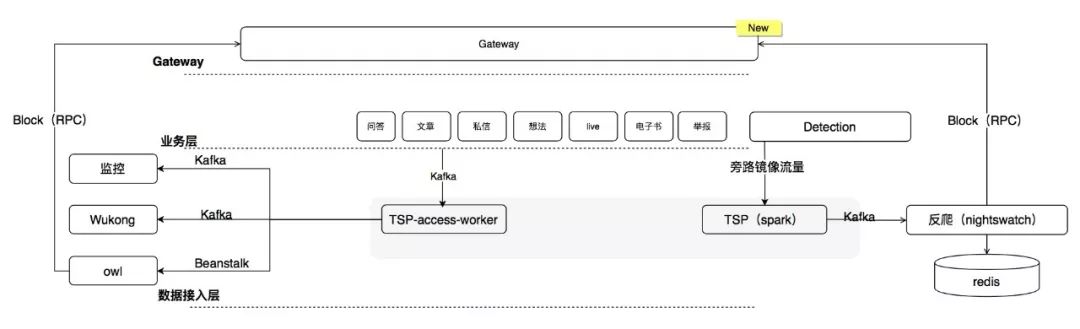
TSP 主要为反爬虫和反作弊提供服务,一方面解析旁路镜像流量,通过 Spark 完成流量清洗和基础计数,再通过 Kafka 将计数数据打给反爬虫策略引擎,进行检测和处理,从而实现业务零成本接入。另一方面,由于反作弊依赖较多业务数据,难以从流量中获取,故以 kafka 接入替代 RPC 接入,实现与业务进一步解耦,减少对业务的影响。
随着「悟空」策略上线效率的提升,在线的策略逐渐增多,我们开始着手优化「悟空」的检测性能与检测能力。
策略充分并行化
「悟空V2」策略检测以行为为单位分发,带来的问题是策略增多之后,单行为检测时长会大大增强。在 V3 我们优化了这部分逻辑,将策略检测分发缩小到以策略为粒度,进一步提升策略运行的并行度,并实现了业务级别的容器隔离。优化后,事中检测模块演化成了三级队列的架构。第一级是事件队列,下游的策略分发 worker 将数据落地,并按照事件的业务类型进行策略分发。策略执行 worker,从二级队列获取任务,进行策略检测,并将命中的事件分级处理,分发到对应的第三级队列。第三级队列即处理队列,负责对命中规则的内容或者用户进行处理。
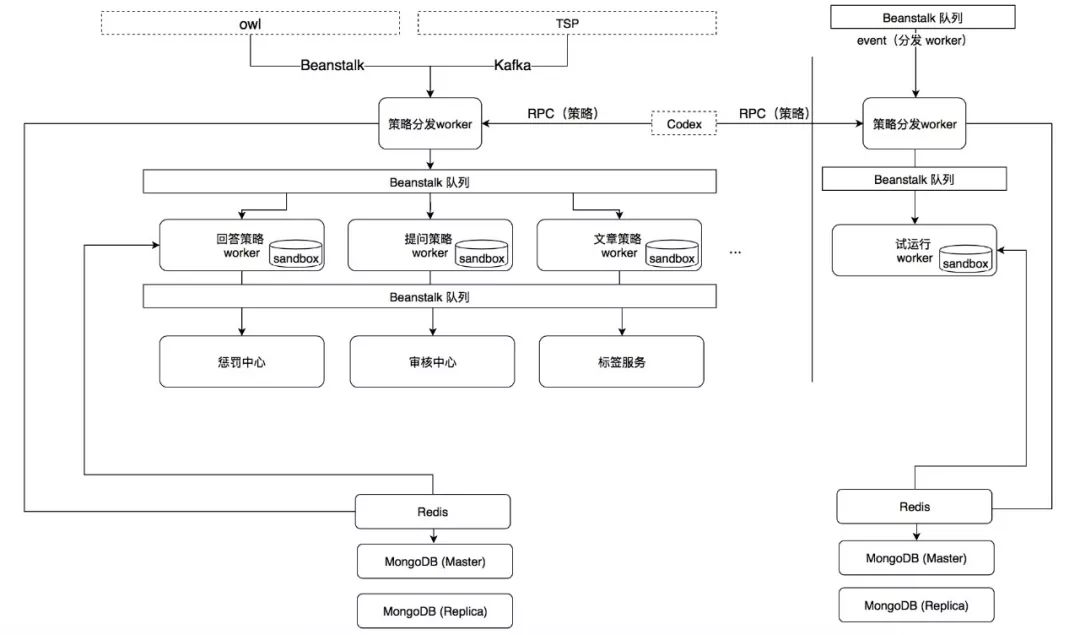
缓存优化
因为每个策略检测都会涉及到历史数据的回溯,自然会带来较多的重复查询,存储的压力也会比较大,所以存储上我们又增加了多级存储,除了MongoDB,在上层对于近期的业务数据,存储在 Redis 和 localcache。详细的内容过往的技术文章已经有了比较详细的介绍,感兴趣的同学们可以去看:Wukong 反作弊系统缓存的优化
图片识别能力增强
随着文本内容检测能力的增强,不少spam 开始使用图片的方式进行作弊。在「悟空 V3」我们增强了图片相关的检测能力:图片 OCR,广告图片识别,色情图片识别,违法违规图片识别,政治敏感图片识别。针对图片类的广告 Spam 的检测一直是我们的空缺,需要投入大量的人力进行模型训练,所以这一块我们借助第三方快速提升这一块的空缺。目前接入之后,着实提升了我们解决站内广告和诈骗图片 Spam 的能力。
风险数据进一步积累
早期由于系统还未成熟,我们很多的工作时间都花在Spam 问题的应急响应上,很少去做各维度的风险数据累积。在「悟空 V3」我们分别在内容、帐号、IP、设备维度开始累积相关的风险数据,供策略回溯和模型训练使用。 目前我们有三个数据来源:策略、第三方接口和人工标注。鉴于离线人工标注效率低,并且抽取数据项繁杂的问题,我们专门搭建了一个标注后台,提升运营同学标注数据的效率,使标注数据可复用,可追溯。以下是一些我们比较常用的风险维度:
内容维度:e.g. 导流类广告,品牌类广告,违反法律法规
帐号维度:e.g. 批量行为(批量注册,刷赞,刷粉等),风险帐号(社工库泄露等), 垃圾手机号,风险号段
IP 维度: e.g. 风险 IP ,代理 IP
设备维度:e.g. 模拟器,无头浏览器
回溯能力增强
在「悟空V3」,我们还增强了策略的回溯能力。一方面,搭建失信库覆盖新增内容中与失信内容相似的 Spam 内容,相似度的算法目前我们使用的是 consine-similarity 和 jaccard。另一方面,基于 Redis,我们支持了基于导流词、标签、社区的快速回溯。这样的话相关的行为更容易被聚集到一起,使得我们可以突破时间的限制,对相似的 Spam 一网打尽。
此外,我们工程和算法团队在算法模型引入做了诸多尝试。
「结网- ZNAP (Zhihu Network Analysis Platform)」
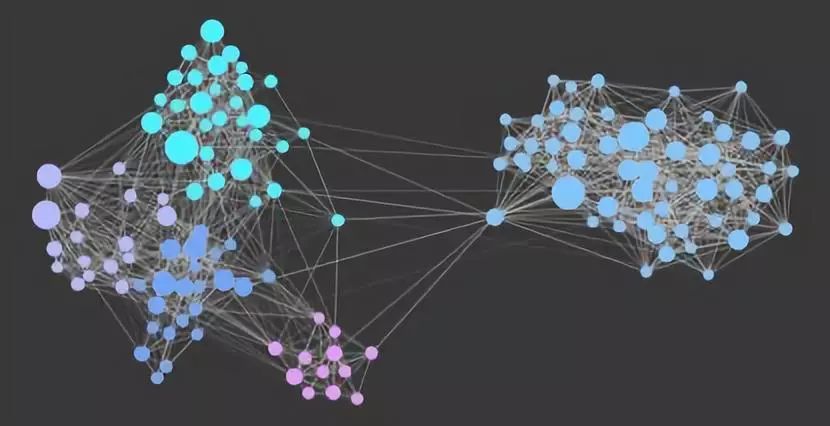
过去做反作弊的很长一段时间,我们花了很多功夫在行为和内容层面去解决Spam 问题。但换个角度,我们会发现,黑产团伙固然手上的资源巨多,但是也得考虑投入产出比,不管怎么样,资源都会存在被重复使用的情况,那用什么方式去表示这种资源的使用情况呢?我们想到了图,也成为了我们做「结网」这个项目的出发点。我们将这个项目分成了几个阶段:
第一阶段,实现基于图的分析能力:这个阶段旨在提供一种通过网络图谱分析问题的渠道,提升运营和产品的效率,快速进行社区(设备,IP..)识别,团伙行为识别以及传播分析。帮助我们养成从图的角度去挖掘问题的习惯,并帮助我们在日常分析的过程中,总结一些经验,输出一些策略。图谱分析平台的数据基于用户的写行为,将用户,设备,IP, Objects (提问,回答..) 作为节点,具体行为作为边。当行为发生时,将用户与设备,用户与IP, 用户与对应的 object 关联, 而每个节点的度就代表发生关联的数量。图数据存储的部分我们当时调研了Titan, Neo4j 和 TinkerPop,三者之中最终选择了 TinkerPop 作为存储框架,底层用 HBase 作为存储。TinkerPop 是 Apache 的顶级项目之一,是面向 OLTP 及 OLAP 的图计算框架,其扩展性非常之强,只要实现了 TinkerPop 定义的 API,就能作为驱动让存储支持图查询,可以减少存储额外维护和迁移的成本。目前 Tinkerpop 支持 HBase, Neo4j, OrientDB 等等。另外也通过 GraphComputer 支持使用 Spark 进行查询和计算。Gremlin 是 TinkerPop 定义的 DSL,可以灵活的用于图数据的查询。
第二阶段,基于图实现社区发现的能力:将相似的用户通过社区的形式化成一个圈子,便于日常分析和策略运用基于一个圈子去处理。我们采用了modularity + fast-unfolding 实现了社区发现的算法,拿设备社区为例,算法的输入是设备与用户的关联,输出是每个设备节点和每个用户节点以及他们的社区号。模块度(modularity)是衡量网络划分非常常用的维度,模块度越大,意味着比期望更多的边落在了一个社区内,划分效果越好。Fast-unfolding 则是一个迭代算法,主要目标就是提升划分社区效率,使得网络划分的模块度不断增大,每次迭代都会将同一社区的节点合并,所以随着迭代的增加,计算量也在不断减少。迭代停止的条件是社区趋于稳定或者达到迭代次数上限。
第三阶段,在社区的基础上,实现社区分类的能力:能够有效地识别可疑和非可疑的社区,帮助日常分析和策略更好地打击Spam 团伙。我们使用的是可解释性比较高的逻辑回归,使用了一系列社区相关的特征和用户相关的特征进行训练,作为运营辅助数据维度和线上策略使用,都有非常好的效果, 从 2017 年 6 月以来我们已经积累了 4w 的可疑社区和 170w 的正常社区。
文本相似度聚类
知乎站内的Spammer 为了快速取得收效,往往倾向于大批量地产生相似的 Spam 内容,或者密集地产生特定的行为。针对这种大量,相似,和相对聚集的特点,我们使用 Spark 通过 jaccard 和 sim-hash 实现了文本聚类,通过把相似的文本聚类,实现对批量行为的一网打尽。详细的内容可以参见:Spark 在反作弊聚类场景的实践
未登录热词发现

品牌类内容也是知乎站内占大头的Spam 类型。目前站内大部分的恶意营销都是出于 SEO 的目的,利用知乎的 PageRank 来提升搜索引擎的关键词权重。因此这类内容的特点就是大量的关键词(品牌相关,品类属性相关的词汇)会被提及。由于都是一些小众品牌和新品牌,这类关键词一般都未被切词词库收录,就是我们所谓的未登录词 (Unknown Words), 于是我们从词汇的左右信息熵和互信息入手,去挖掘未登录词, 并取得了比较好的效果。关于我们实现的细节,可以参考我们的系列文章:反作弊基于左右信息熵和互信息的新词挖掘。
导流词识别
针对站内的导流内容,最开始在识别导流信息上采用的是干扰转换+正则匹配+匹配项回溯的方式进行异常导流信息的识别与控制,取得了很好的效果。此外,随着整治加强,我们发现站内导流变体的现象也在愈演愈烈,对此,我们也成功引入模型进行整治,通过 BILSTM-CRF 来识别导流变体,目前在提问和回答的识别准确率分别达到 97.1%、96.3%。想要了解的同学快去看看我们的系列文章:算法在社区氛围的应用(一):识别垃圾广告导流信息。
通用垃圾内容分类
对于垃圾内容的治理,虽然线上一直有策略在覆盖,但是策略的泛化能力有限,始终会有新型的Spam 绕过策略。我们尝试使用深度学习构建通用垃圾文本分类模型。模型使用字向量作为输入,多层 Dilated Convolution 提取文本特征,通过 Attention 对卷积后的表达重新加权得到高层特征,最后得到垃圾内容的概率。针对近期我们遇到的批量 Spam 内容单条规则召回率可以达到 98% 以上,准确率达到95.6%。对于「通用垃圾内容」定义,样本的筛选以及模型训练的过程,我们也积累了一些经验和教训。后续我们的工程师也会单独介绍细节,敬请关注噢。
至此,「悟空」整个体系的架构演进已经跟大家介绍完了,当前的整体架构如下图所示一共有这么几个部分:
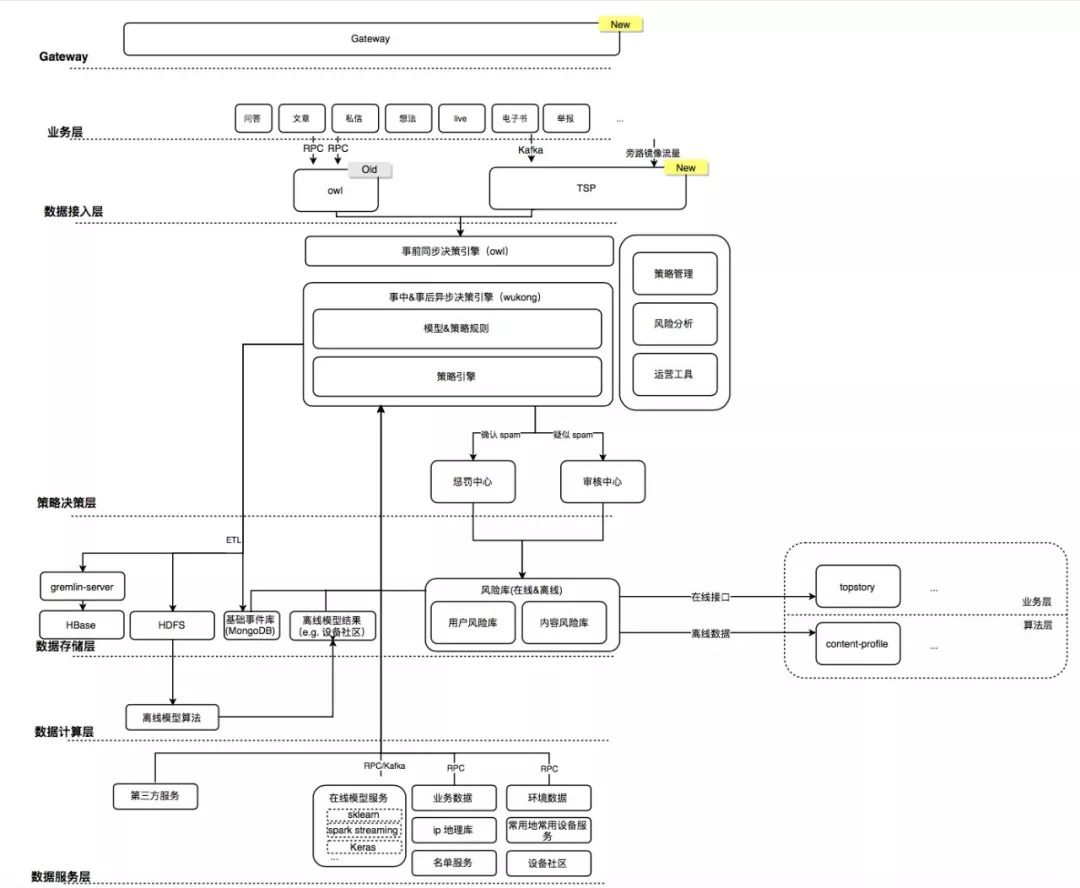
Gateway: 负责异常用户状态拦截,业务同步拦截,反爬拦截。
业务层:对接的各个业务方。
数据接入层:数据接入层有两种方式,一种通过RPC 透传,一种通过 kafka 消息,实现业务与反作弊系统的解耦。
策略决策层:策略决策层,分为事前同步决策和事中事后异步决策,横向对应的还有策略管理服务,一系列风险分析和运营工具。根据决策结果的可疑程度不同,要么送审要么进行不同程度的处理,确认是Spam 的行为会进入风险库,回馈到策略再次使用。
数据存储层:数据存储层包括基础的基础的事件库,风险库,离线HDFS 的数据落地等等, 这一块的数据不仅仅面向反作弊系统开放使用,并且会提供给外部进行模型训练使用和在线业务使用。
数据计算层:这一层包括一些离线的机器学习模型,每日定时计算模型结果,并将数据落地。
数据服务层:因为反作弊不仅仅要依赖自己内部的数据,还会涉及到从业务取相关的数据,所以这一层会涉及到与业务数据,环境数据以及模型算法服务的交互。
经过三年的团队的努力,「悟空」构建了一个模型& 策略识别 - 决策 - 管控 - 评估 & 改进的闭环。未来「悟空」还会面临更大的挑战,我们的目标不止于处理垃圾信息,更重要的是保护用户的体验,「悟空」的升级之路没有止境。我们会持续在知乎产品(Zhihu-product)、技术(Hacker's log )专栏中和大家介绍知乎反作弊的相关信息,欢迎关注。
参考文献:
[1] Facebook Immune System https://css.csail.mit.edu/6.858/2012/readings/facebook-immune.pdf
[2] Fighting spam with BotMaker https://blog.twitter.com/engineering/en_us/a/2014/fighting-spam-with-botmaker.html
[3] Fighting Abuse @Scale 2018 https://atscaleconference.com/events/fighting-abuse-scale/#
[4] Spam Fighting @scale 2016 https://code.fb.com/security/spam-fighting-scale-2016/
[5] 美团点评业务风控系统构建经验 https://tech.meituan.com/risk_control_system_experience_sharing.html
更多关于wukong的信息:
- 反作弊基于左右信息熵和互信息的新词挖掘 https://zhuanlan.zhihu.com/p/25499358
- WuKong 反作弊系统缓存的优化 https://zhuanlan.zhihu.com/p/23509238
- Spark 在反作弊聚类场景的实践 https://zhuanlan.zhihu.com/p/23385044
- 知乎反作弊系统「悟空」演变 http://www.infoq.com/cn/presentations/zhihu-anti-cheat-system-evolution
- 「悟空」和大家见面啦 https://zhuanlan.zhihu.com/p/19998740?refer=zhihu-product
相关阅读:
高可用架构
改变互联网的构建方式

长按二维码 关注「高可用架构」公众号