一文读懂深度适配网络(DAN)

来源:知乎专栏
作者:Lukas Biewald
本文长度为2500字,建议阅读5分钟
本文为你介绍清华大学的龙明盛老师在ICML-15上提出的深度适配网络。
这周五下午约见了机器学习和迁移学习大牛、清华大学的龙明盛老师。老师为人非常nice,思维敏捷,非常健谈!一不留神就谈了1个多小时,意犹未尽,学到了很多东西!龙明盛老师在博士期间(去年博士毕业)发表的文章几乎全部是A类顶会,他在学期间与世界知名学者杨强、Philip S. Yu及Michael I. Jordan多次合作,让我非常膜拜!这次介绍他在ICML-15上提出的深度适配网络。
深度适配网络(Deep Adaptation Netowrk,DAN)是清华大学龙明盛提出来的深度迁移学习方法,最初发表于2015年的机器学习领域顶级会议ICML上。DAN解决的也是迁移学习和机器学习中经典的domain adaptation问题,只不过是以深度网络为载体来进行适配迁移。DAN是深度迁移学习领域的代表性工作,被UC Berkeley、HKUST等世界知名大学不断引用。杨强老师对DAN的评价很高,在Google Scholar上也有着很高的引用量,可以被看作是深度迁移学习领域的经典文章。值得注意的是DAN文章的最后一位作者是Michael I. Jordan,机器学习领域的泰山北斗。所以这篇文章的含金量非常的大。
背景
继Jason Yosinski在2014年的NIPS上的《How transferable are features in deep neural networks?》探讨了深度神经网络的可迁移性以后,有一大批工作就开始实际地进行深度迁移学习。我们简要回顾一下Jason工作的重要结论:对于一个深度网络,随着网络层数的加深,网络越来越依赖于特定任务;而浅层相对来说只是学习一个大概的特征。不同任务的网络中,浅层的特征基本是通用的。这就启发我们,如果要适配一个网络,重点是要适配高层——那些task-specific的层。
适配高层网络的代表性工作是Eric Tzeng等人在2014年发在arXiv上的《Deep domain confusion: maximizing for domain invariance》(至今没找到到底发在哪了)。这篇文章针对于预训练的AlexNet(8层)网络,在第7层(也就是feature层,softmax的上一层)加入了MMD距离来减小source和target之间的差异。这个方法简称为DDC。这篇文章概括一点说,就是适配了最高层网络,只有一层。那么,是否只适配这一层就够了呢?
介绍
DAN是在DDC的基础上发展起来的,它很好地解决了DDC的两个问题:
DDC只适配了一层网络,可能还是不够,因为Jason的工作中已经明确指出不同层都是可以迁移的。所以DAN就多适配几层;
DDC是用了单一核的MMD,单一固定的核可能不是最优的核。DAN用了多核的MMD(MK-MMD),效果比DDC更好。
方法
上面已经说过,DAN的创新点是多层适配和多核MMD。那么我们针对两个方面分别介绍。
多核MMD(Multi-kernel MMD,MK-MMD)
这个MK-MMD是基于原来的MMD发展而来的,它并不是这个文章提出来的,是由Gretton这位核方法大牛在2012年提出来的。原来的MMD呢,是说我们要把source和target用一个相同的映射映射在一个再生核希尔伯特空间(RKHS)中,然后求映射后两部分数据的均值差异,就当作是两部分数据的差异。最重要的一个概念是核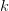
MK-MMD就是为了解决这个问题。它提出用多个核去构造这个总的核,这样效果肯定会比一个核好呀!对于两个概率分布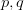
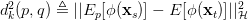
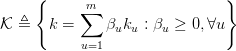
就是一个固定的函数嘛,现在我们把它用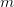
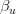
多层适配
这个就很好理解了。原来的DDC方法只是适配了一层,现在DAN也基于AlexNet网络,适配最后三层(6~8层)。为什么是这三层?因为在Jason的文章中已经说了,网络的迁移能力在这三层开始就会特别地task-specific,所以要着重适配这三层。至于别的网络(比如GoogLeNet、VGG)等是不是这三层那就不知道了,那得一层一层地计算相似度。DAN只关注使用AlexNet。
总的方法
好了,我们已经把DAN的两个要点讲完了。现在总的来看一下DAN方法。它基于AlexNet网络,探索source和target之间的适配关系。任何一个方法都有优化的目标。DAN也不例外。它的优化目标由两部分组成:损失函数和分布距离。损失函数这个好理解,基本上所有的机器学习方法都会定义一个损失函数,它来度量预测值和真实值的差异。分布距离就是我们上面提到的MK-MMD距离。于是,DAN的优化目标就是: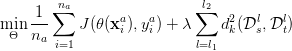
这个式子中,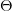
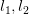
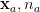
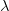
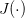
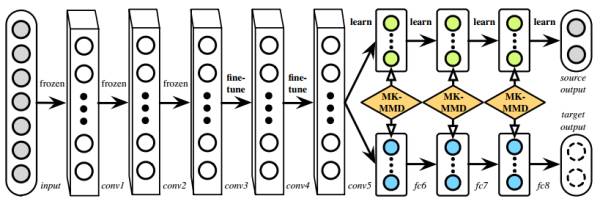
学习策略
现在已经把问题定义的非常明确了,可以开始训练和学习了。学习一共分为两大类参数:学习网络参数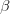
学习
对
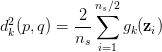
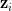
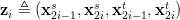
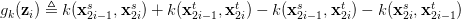
上面这些变换看着好恐怖。它是个什么意思呢?简单来说,它就是只计算了连续的一对数据的距离,再乘以2.这样就可以把时间复杂度降低到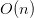
在具体进行SGD的时候,我们需要对所有的参数求导:对
学习
学习$\beta$主要是为了确定多个kernel的权重。学习的时候,目标是:确保每个kernel生成的MMD距离的方差最小。也就是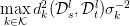
结论
DAN作为深度迁移学习的代表性方法,充分利用了深度网络的可迁移特性,然后又把统计学习中的MK-MMD距离引入,取得了很好的效果。作者在2017年又进一步对其进行了延伸,做出了Joint Adaptation Network (JAN),也发在了ICML 2017上。在JAN中,作者进一步把feature和label的联合概率分布考虑了进来,可以视作之前JDA(joint distribution adaptation)的深度版。下次我们介绍这个工作。总的来说,深度迁移学习在DAN和JAN的开创性工作面前,留给模型创新的空间已经不多了。这才是我们要思考的问题。如何推陈出新?
数学很重要!我们可以看到最重要的MK-MMD是搞数据的提出来的!好好学数学!
参考文献:
1. DAN文章:Long M, Cao Y, Wang J, et al. Learning transferable features with deep adaptation networks[C]//International Conference on Machine Learning. 2015: 97-105.
2. MK-MMD文章:Gretton A, Borgwardt K M, Rasch M J, et al. A kernel two-sample test[J]. Journal of Machine Learning Research, 2012, 13(Mar): 723-773.
作者简介:
王晋东(不在家),中国科学院计算技术研究所博士生,目前研究方向为机器学习、迁移学习、人工智能等。作者联系方式:微博@秦汉日记,个人网站http://jd92.wang/。

公众号底部菜单有惊喜哦!
企业,个人加入组织请查看“联合会”
往期精彩内容请查看“号内搜”
加入志愿者或联系我们请查看“关于我们”






