


分享嘉宾:乔嘉林博士 清华大学 编辑整理:张德通 Treelab 出品平台:DataFunTalk
**导读:**本文将介绍Apache IoTDB,它是一个基于开放数据格式的数据库。 今天的介绍会围绕下面四点展开: * Apache IoTDB 简介 * 时序文件格式 TsFile * 基于开放文件的数据库架构 * 开源社区建设 01****Apache IoTDB 简介
IoT是物联网的缩写,DB是数据库的缩写,IoTDB的名字直接说明了它物联网数据库的定位。物联网场景下时序数据主要来自传感器的采集,如风力发电机上用于探测风速的传感器,每秒采集一条数据,随着时间推移,这些数据就会形成时间序列,时间序列数据就反映了当时风力的变化情况。图中的绿色部分展示了草帽风的现象。由于形状类似草帽因此称之为草帽风,此类风会对风机叶片产生负面影响,进而降低风机寿命。

物联网时序数据是工业设备物理量的数字化记录,在轨道交通、能源管控、智能制造等领域有广泛应用。 ① 轨道交通
在轨道交通领域,通过将大桥安装传感器、对传感器数据进行采集和分析,可以检测桥梁的状态,如挠度、应变、振动、支座位移情况等,从而可以进行有针对性的健康检测和加固,避免桥梁坍塌,保障人民出行安全。IoTDB已有该领域的用户案例。 ② 能源管控
一些IoTDB的开源用户对化工厂进行能耗监测、报警管理、预测优化,实现节能、减排、增效,响应“碳达峰、碳中和”政策。 * 能耗监测:通过监控工厂的实时用水流量,查找供水系统的跑、冒、滴、漏以及水力平衡等问题,如果出现工厂停工后用水量依然不断增加的情况,及时进行排查。 * 报警管理:根据测点值进行异常判断,及时进行声、光、电话报警,降低能源系统故障所造成的影响。 * 预测优化:建立能源预测模型,优化生产排期,达到降低污染的目标。
③** 智能制造**
以烟厂对IoTDB的应用为例,烟厂通过对设备状态监控和统计过程控制,提高生产效率,实现制造业升级。 * 设备运行监控:收集设备关键数据,检查某时刻设备生产过程关键数据(嘴棒数、卷烟纸、水松纸)。 * 制丝质量评价:根据实时监测数据(烟丝整丝率、碎丝率等),对烟丝质量进行判定。 * 统计过程控制(SPC):根据叶丝含水率、出料温度等工艺质量数据,区分产品质量的随机波动、异常波动与发展趋势,根据趋势判断是否需要加料、减料,保证生产过程稳定。
以上应用都是在各种设备上加装了大量传感器,而如何加,是每家工业企业需要结合业务特点进行确定的。在设计数据采集的同时,也需要设计如何对数据进行存储。通常采集的数据越多、粒度越细越好。一台高端设备,如飞机有8万个传感器;一台挖掘机上会装配四五百个传感器,但挖掘机数量众多,一家用户有两万台挖掘机,就有千万级时间序列数据;两万台风力发电机,每年能产生120PB数据。时序数据在物联网领域的体量是庞大的。 飞机、挖掘机、风电机离我们的日常生活遥远,但对于飞行员、挖掘机驾驶员和电厂监控平台管理人员来说,每台设备都是有生命的个体,时序数据就是设备的心电图。时序数据是重要的资产,为了更好地管理时序数据,我们在2011年受到国家863计划支持下发起了物联网时序数据库——Apache IoTDB项目。 接触工业物联网用户、为用户管理时序数据,是清华大学软件学院在2011年开始的一个方向。随着我们对产业和时序数据相关的研究与思考的深入,我们开始自研时序数据库,在2017年推出了IoTDB第一个版本并在Github公开源码。2018年我们将项目捐赠给Apache基金会。经过两年的摸索,IoTDB在2020年9月成为了Apache顶级项目。至此,IoTDB是首个入选Apache的工业物联网时序数据库项目,也是首个中国高校发起的Apache顶级项目。IoTDB被来自德国、美国、中国的工业互联网厂商和智能制造厂商使用和打磨,产品和功能在开源社区中不断成熟。

IoTDB产品易用、好用,部署灵活,能开箱即用一键部署,具有高写入吞吐和低查询延迟,支持丰富的时间序列操作,与现有大数据生态系统集成比较完善。

IoTDB能够支持复杂负载。传统数据库应对简单负载更加友好,但对复杂负载的处理表现不理想。简单负载中,设备测点少,采样频率低、几秒一个点甚至几分钟一个点,这种情况下表数据量小,一张表就可以满足设备一周到一个月的存储。但设备数据量大时需要进行分表,用户的使用上会造成不便。关系表也更加适用于管理规整的数据,例如一个设备的多个传感器采集时间相同,则表中不需要存储空值;但当每个设备上维护各自的时钟,独立地上报数据,此时时间难以对齐,表的数据稀疏,空值多。 复杂负载单体设备可能会产生上千甚至数万的点,如飞机采样频率比较高,转动传感器每秒钟采集几十甚至几百个数据点,或者人工去分表都难以满足需求。但IoTDB会针对这些复杂负载进行优化。
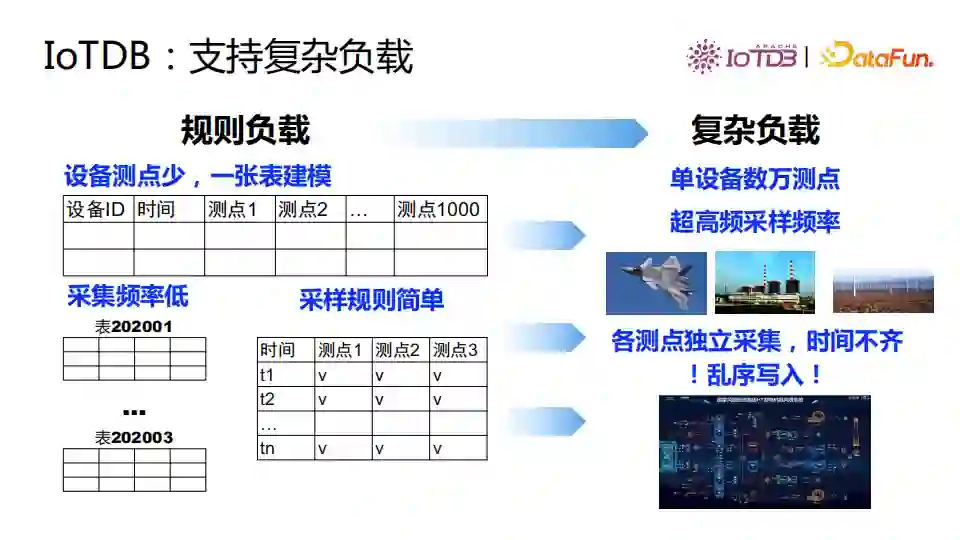
IoTDB允许设备定义数据模式。使用传统关系型数据库时,用户首先要定义表结构,然后才能写入数据。IoTDB允许用户不预先定义表结构,直接写入数据,这个特性降低了用户使用负担,也更加适应物联网设备快速迭代升级的场景。假如一个设备装了3、4个传感器,随后又新增了其他感应器收集测点,这时使用传统数据库需要Alter Table修改表结构,但使用IoTDB即可不用修改表结构直接向数据库内写入数据,写入过程中自动完成数据模式的创建。
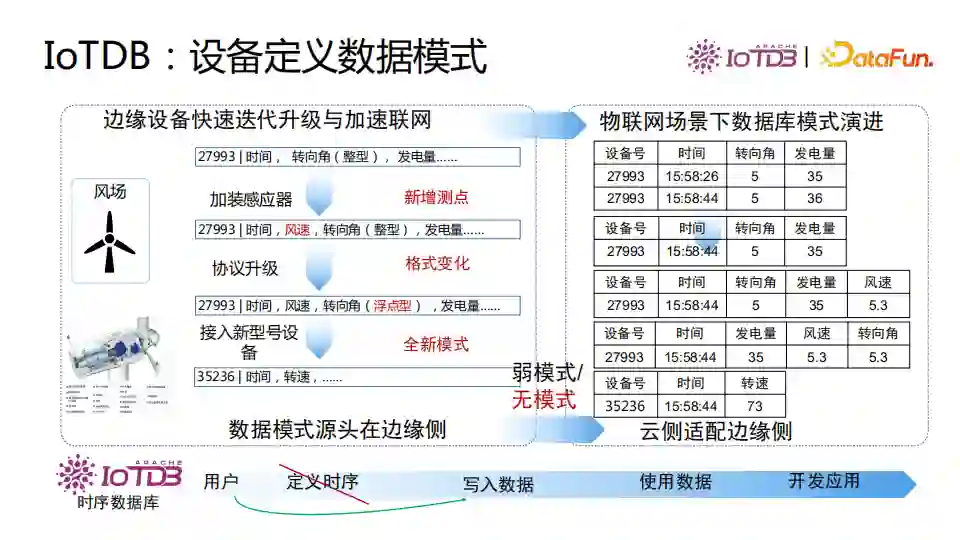
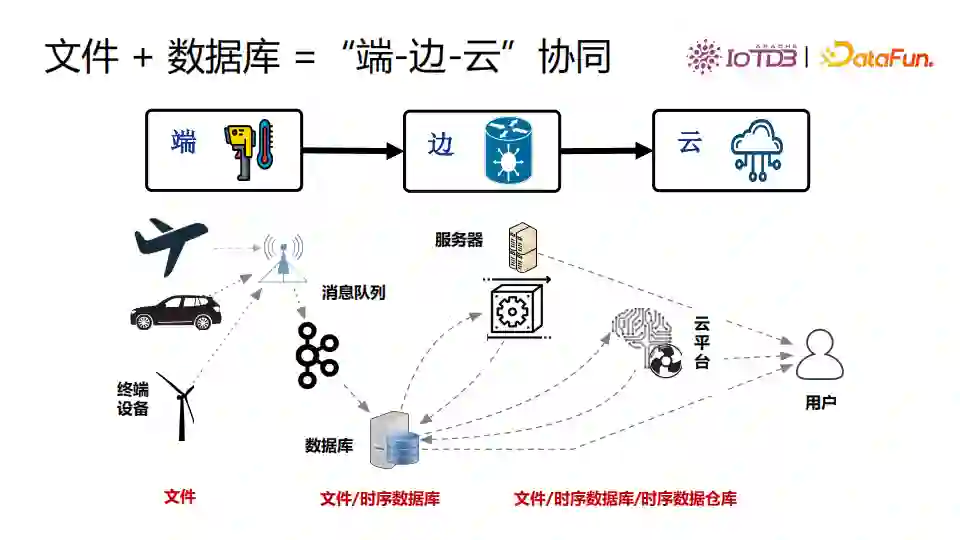
IoTDB支持端云同步。端云同步是物联网领域中常见的场景。终端设备采集数据,一条条地发送数据到云端数据库。该过程中需要在端侧对数据编码为二进制流,在云数据库侧解码数据后写入数据库。终端数据大量增长时,存在云端压力不断增加,网络带宽消耗大的现象。 对此我们提出了基于文件的数据同步方法,在终端把数据写为压缩的文件,再把文件同步到云端。由于网络传输的是压缩好的文件而不是原始数据,网络流量消耗降低。云端也不需要在解析数据后一条条地写入数据,只需要加载上传的文件即可,降低了云端CPU消耗。
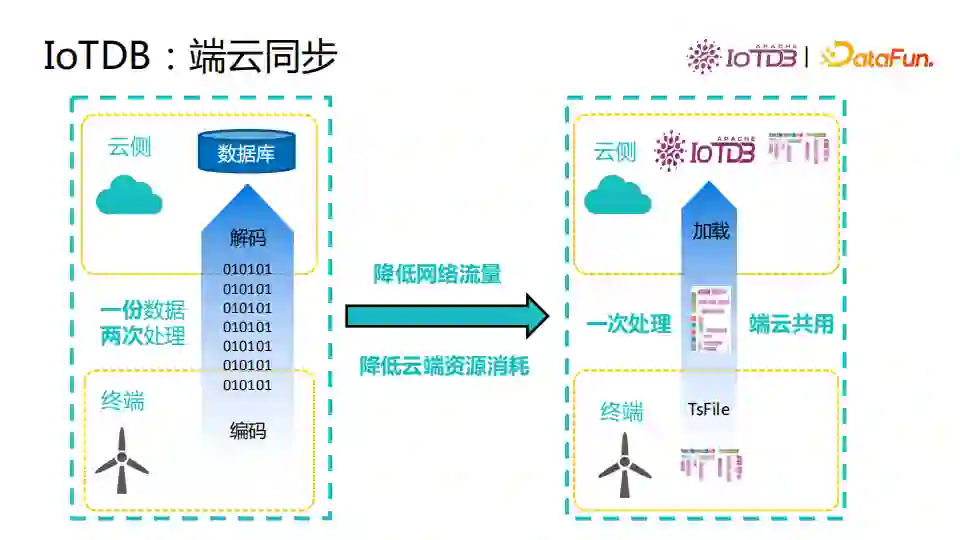
IoTDB专注于数据的存储管理,为了支持更多对数据的全生命周期处理,我们与众多开源项目进行了集成。IoTDB支持PLC4X等工业采集协议,也适配了Kafka、Flink、Spark,还对数据交互软件和可视化工具做了支持如Grafana, zeppelin等。用户可以自由地利用开源软件满足自己的数据采集、处理、分析的需求。
IoTDB产品形态分为三部分: ① 部署在嵌入式终端设备的时序“数据文件”
在端上,数据存储为时序数据zip文件,支持高性能写入,高压缩比存储,支持简单查询。 ② 部署在边缘计算设备的时序“数据库”
边缘计算设备上,可以支持高效丰富的时间序列查询引擎,提供增删改查,以及聚合查询时序对齐等高级功能。 ③ 部署在云端数据中心的时序“数据仓库”
IoTDB可以与大数据分析框架无缝集成,支持时序数据处理、挖掘分析、机器学习。

IoTDB与传统数据库不同,IoTDB把文件作为重要的概念,是系统的底层基石。02****时序文件格式 TsFile
1. 文件vs数据库
文件不是一个长活服务,不会丢失;而数据库作为长活服务,需要保持在线,为此需要为数据库设计高可用、保活等策略,需要检查数据库运行状态是否正常。文件的运维负担会比数据库的运维负担轻。写入模式方面文件是追加写入的方式,数据库提供了增删改查功能。写入文件的数据需要在文件关闭后进行查询,而数据库数据写入后即可进行查询。文件的查询流程和管理需要自己实现,而数据库使用SQL即可完成数据的查询。 对数据时效性和查询负载不复杂的场景中,数据存储到文件的模式更加轻便、简单。数据库更适用于数据应用逐渐丰富、对查询要求高的场景。 2. 常见文件结构
Spark、Hive、Presto广泛使用了CSV、ORC、Parquet这些文件结构。ORC和Parquet是支持嵌套的列式存储文件结构。当使用这些文件结构存储数据时也需要进行建模,包括定义每列的数据类型和名称等。
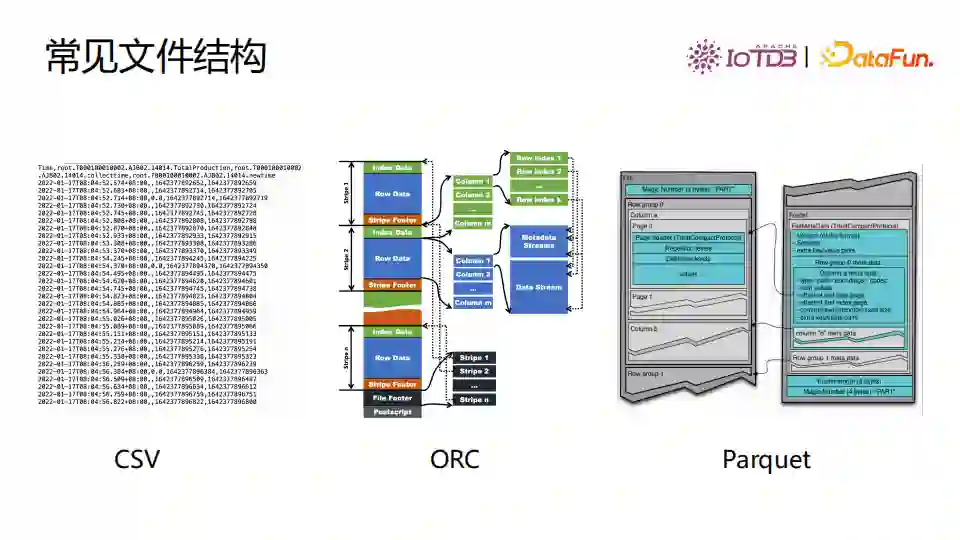
3. 建模方式
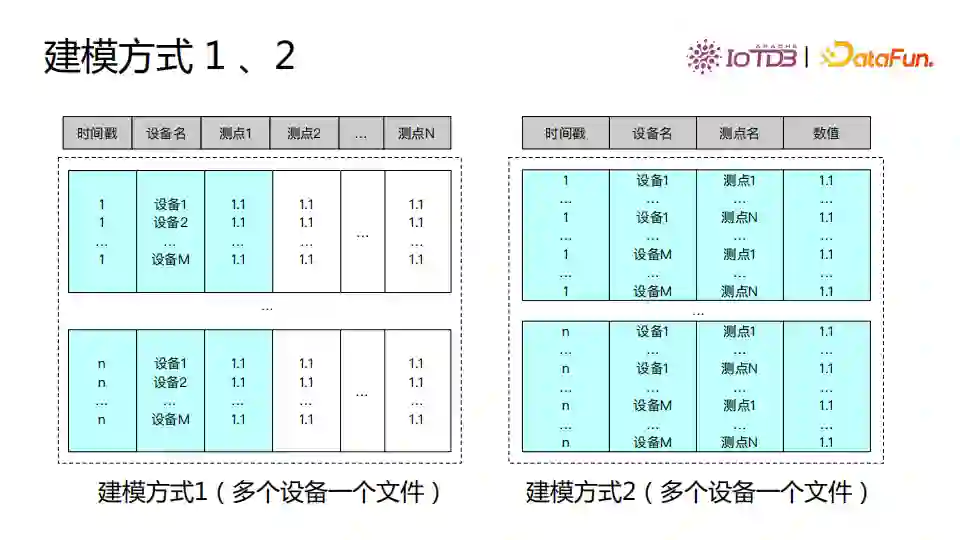
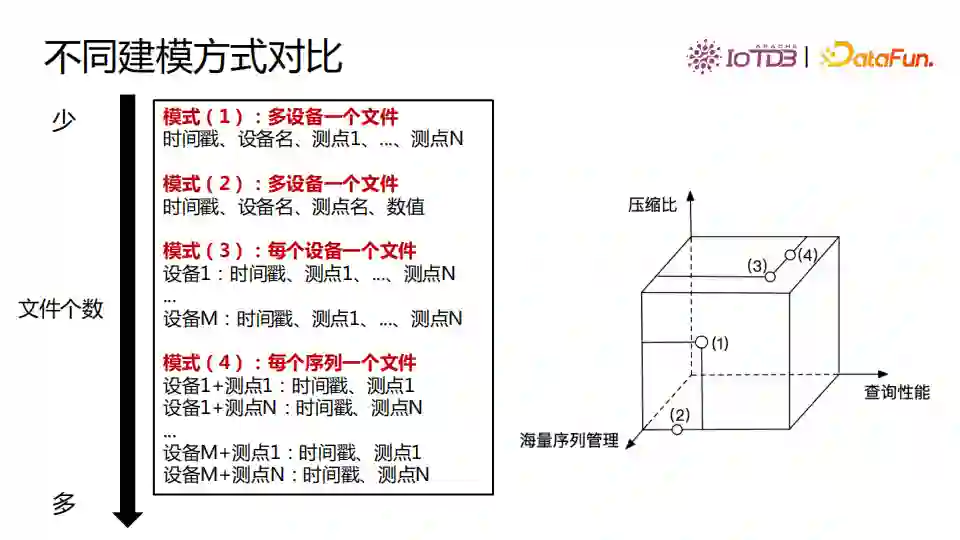
数据有多种建模方式。 一种建模方式是把所有设备数据都存到一个文件里面,此时文件中表结构第一列是时间戳,第二列是设备名,后面是这个设备的所有的测点数据。可以看到这种建模方式下,一个文件可以管理多个设备的数据,但设备名字是被重复存储的。当查询一个设备的一个测点的时间序列时,下图中建模方式1的蓝色部分需要全部读出来进行过滤后才能得到结果。 第二种建模方式也是可以在一个文件里管理多个设备的,整个文件只有四列,其中设备名和测点名是重复存储的,查询时就需要读取更多的数据,基本上需要把所有数据都查找一遍才能拿到需要的数据。
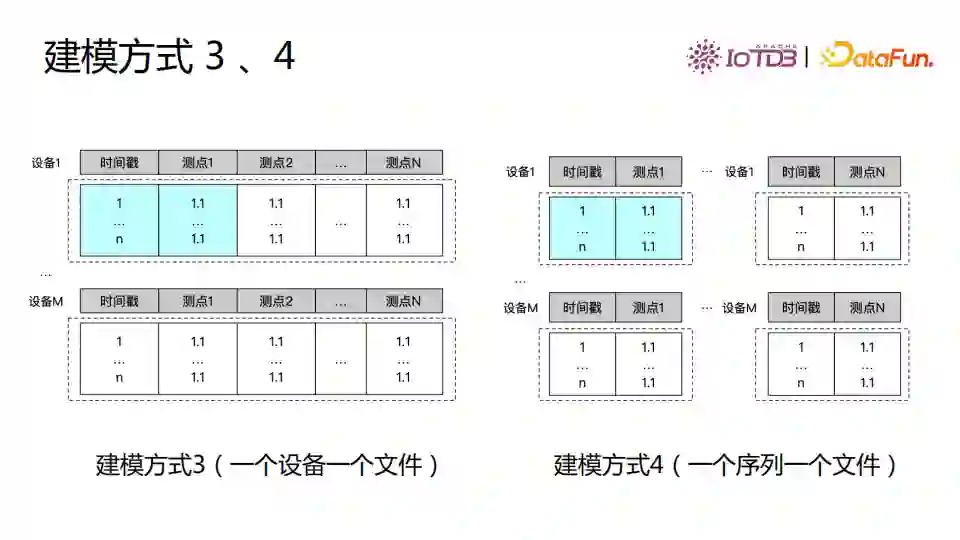
第三种建模方式是每一个设备一个文件。这种模式没有重复存储的数据,但在一个应用里设备数量较多、达到上千万量级,而上千万个文件同时写入是不能实现的方式,此外大量文件对文件系统也是负担。 第四种建模方式是一个时间序列存储为一个文件。这种方式相比第三种在实际应用中更不可行。
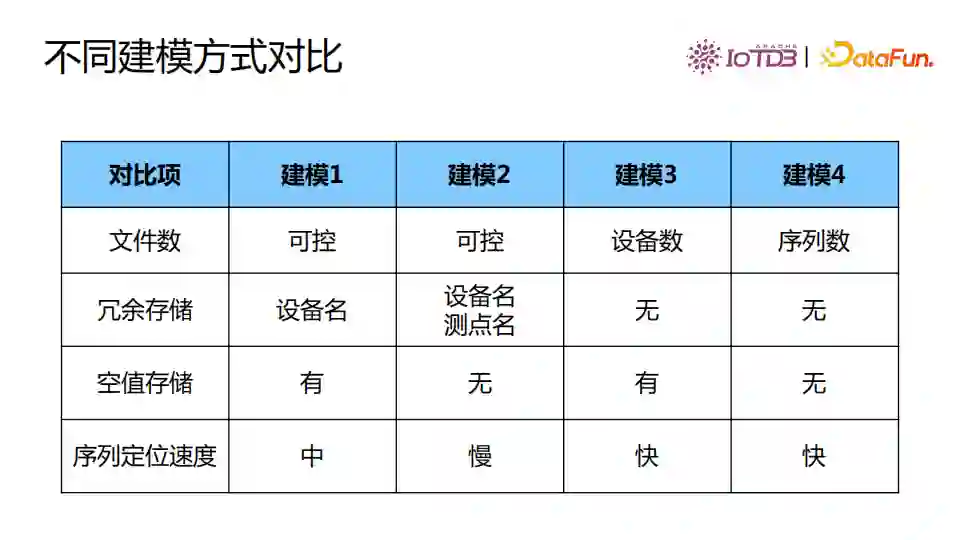
几种建模方式从文件数的角度,建模方式一和二的文件数可控,一个文件就可以存储所有数据,在文件大小超过阈值后再写入新的文件。建模三的文件数就是设备数,建模四文件数是序列数。在一个应用中希望文件数比较可控,我们更倾向使用建模一和二,整个系统的稳定性是最重要的。在存储方面,建模三和四没有冗余的数据,在一些设备数比较少时会使用建模三。建模二的冗余数据又比建模一的更多。 为什么会出现空值?一个设备假如有一万个传感器,这一万个传感器的采集时间都是一样的,此时可以存成一行,且这一行没有任何的空值。但是一旦多个传感器的采集时间不同,就无法按时间对齐,存储时会出现空值的情况,空值也会影响文件的压缩比。建模一和三都会存储空值。 由于建模方式三、四都可以规避冗余数据,因此定位速度应该是最快的。建模方式一能够避免掉一些测点的读取,建模二需要读出所有数据,所以建模二的定位速度最慢。
可见,在压缩比、查询性能和海量序列管理几个维度上,前面的几个建模方式都不是完美的。是否有一种文件结构在管理时序数据时,文件数可控、无冗余数据、查询性能和写入性能比较高呢?它就是TsFile。
4. 针对时序数据的文件结构——TsFile
TsFile全称是Time Series File。它的数据模型是为了物联网领域设计的,包括设备、物理量(测点)、时间和值,用TsFile管理数据时只有这四个概念。存储优化方面,TsFile采用列式存储,编码和压缩可选多种方式,时间列可选是否由多列共享,TsFile提供了列式写入接口。查询优化方面,TsFile存储了预聚合信息、树形索引、向量化查询等。 ① TsFile数据模型
TsFile有设备、物理量(测点)、时间和值这四个状态,图中是两个TsFile的典型模型。

图中左侧是一个车辆有两个传感器,这两个传感器采集的时间是不对齐的,这时我们叫它非对齐的序列。那这种建模方式会把每一个时间序列里都存一列时间,这种方式是最节省空间的,没有存储任何空值。这种方式适合一个设备的不同传感器是独立采集的场景。 图中右侧这种设备GPS,有经度和纬度两个物理量,那这种数据一般都是同时采集的,会共享一列时间戳。这种方式两个列只存一列时间,我们称之为对齐序列。可以看到对齐还是不对齐应该是一个设备的属性,所以在设备层面有一个属性来做控制,在写入时也可以设置这个设备的属性。这个数据模型的特点是在0.13版本去引入的,3月会发布0.13版本。 在场景和模型的选择方面,非对齐序列更适合多物理量独立采集场景,对齐序列更适多物理量同时采集的场景。可以根据不同场景选择不同存储引擎。 ② 数据存储结构
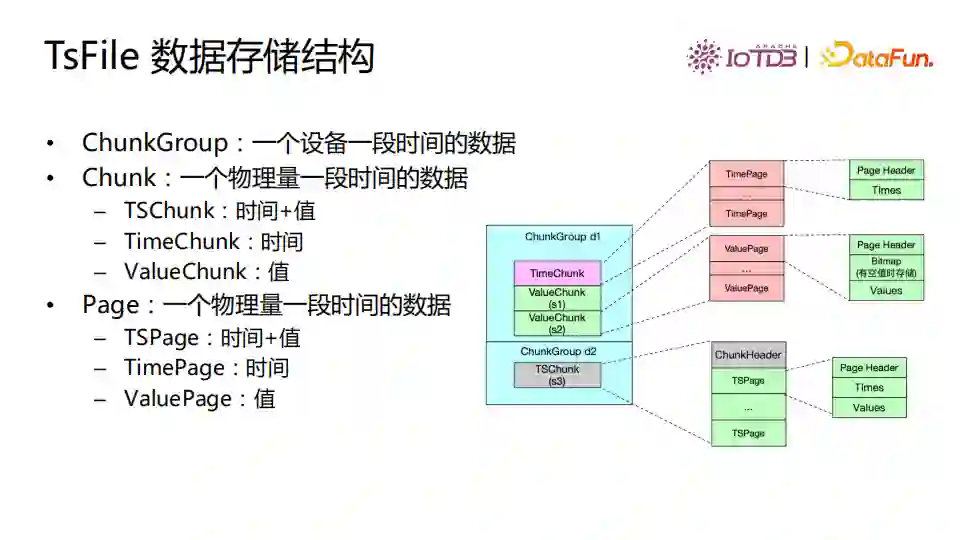
TsFile数据存储结构如图。ChunkGroups存储一个设备一段时间写入的数据。Chunk是一个物理量一段时间的数据,分为三种Chunk:(1)TSChunk,时间+值;(2)TimeChunk,时间;(3)ValueChunk,值。在Chunk基础上我们又把数据划分成Page,Page是一个物理量一段时间的数据,有三种Page:(1)TSPage,时间+值;(2)TimePage,时间;(3)ValuePage,值。通过这种方式,TsFile采用分级的数据存储结构进行管理。
③ Page 编码压缩算法
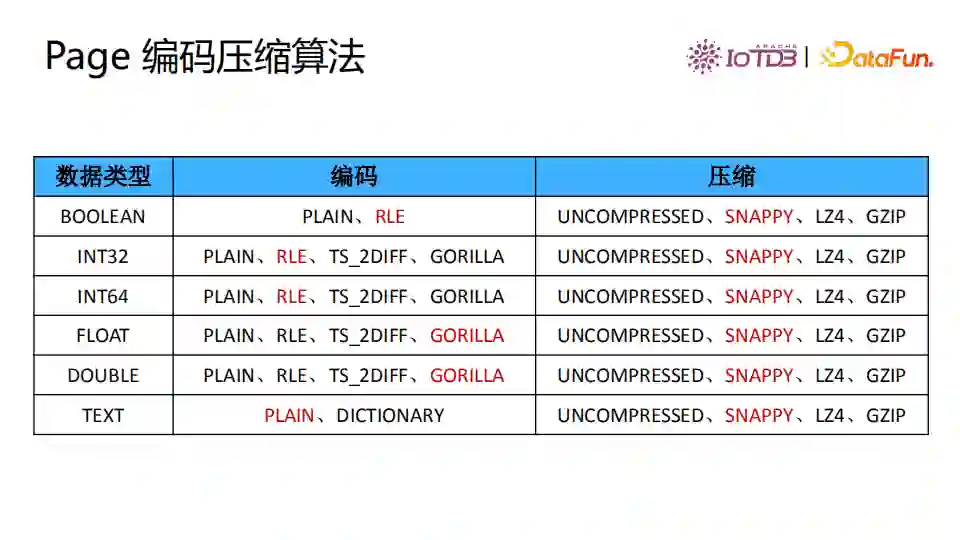
Page是数据最小粒度,可以对Page进行编码和压缩。图中展示了几种编码和压缩算法,红色的是数据类型的默认压缩编码与使用的算法。
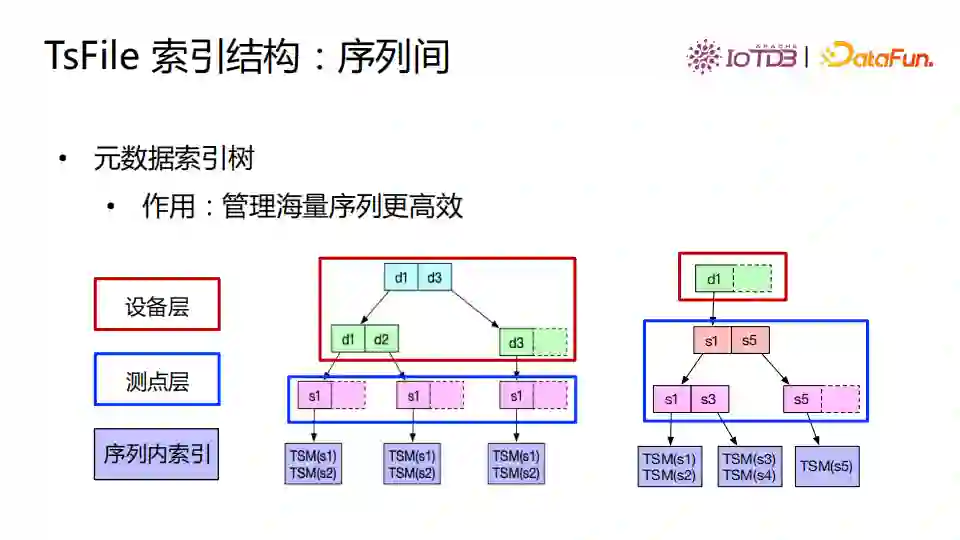
④ TsFile索引结构
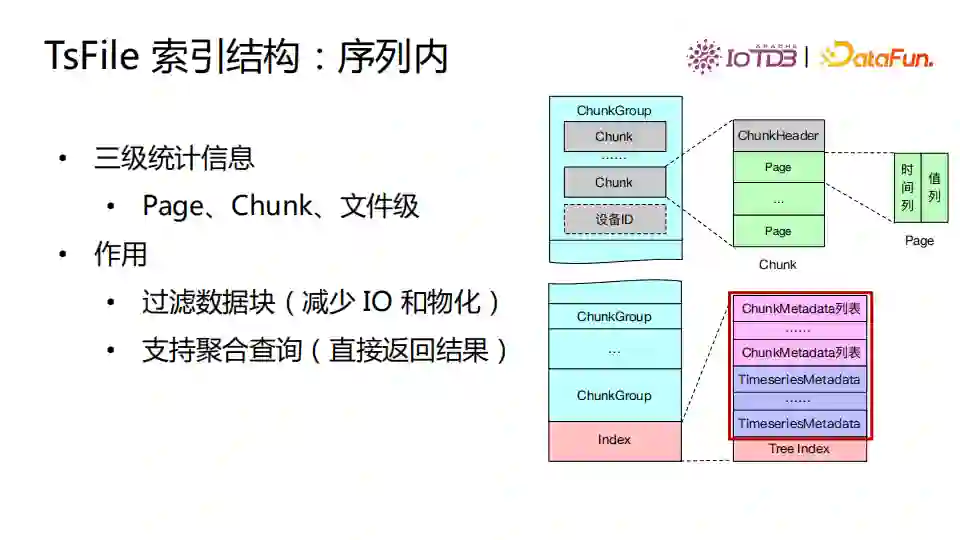
TsFile有丰富的索引结构。 TsFile序列内索引是三级统计信息(Page、Chunk、文件级),作用是过滤数据块(减少 IO 和物化)和支持聚合查询(直接返回结果)。
序列间索引是树形元数据索引,作用是管理海量序列更高效。
Parquet、ORC需要一次加载全量元数据,查询复杂度是O(N);TsFile只加载查询路径的元数据,时间复杂度O(log(N))。TsFile复杂度会比Parquet、ORC低很多。 ⑤ 向量化写入接口、查询引擎
在向量化的写入接口和查询引擎方面,我们引用了一个Tablet的概念。Tablet结构就是管理了一个小的子表。下图中右侧是它的具体的数据定义方式,可以看到它是一个列式的存储,采用了一些原生数据类型的数组,没有封装更多对象。这个结构也保持了IoTDB的高效的读写性能。

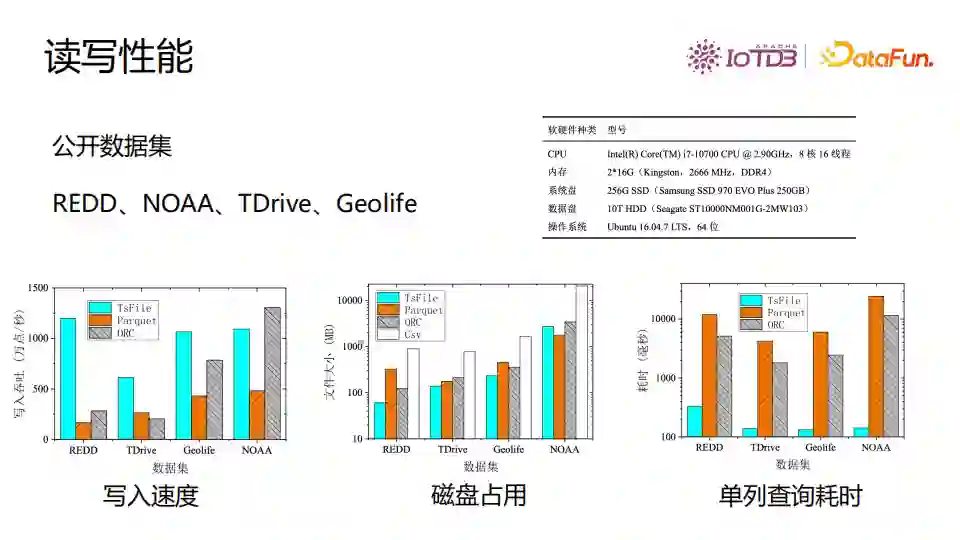
⑥ 读写性能
下图中是在公开的数据集合上TsFile的写入速度、磁盘占用、单列查询耗时三个指标与Parquet、ORC、CSV格式在四个公开数据集上的对比。
我们基于TsFile做IoTDB引擎,做数据库的目的是因为文件无法提供实时查询,而IOT有实时查询数据的监控的需求;文件难以处理乱序数据、数据更新困难,工业场景中常见乱序数据,也经常有更新数据需求;多文件管理、分析需要应用层处理。
开放的数据架构指的是IoTDB是由“时序文件 + 数据库引擎 + 分析引擎”三部分组装起来的松耦合、模块化的架构,类似于“存算分离”架构模式。这与传统数据库的黑盒子模式不同,这一架构对用户透明可见。 IoTDB具体架构如图所示。
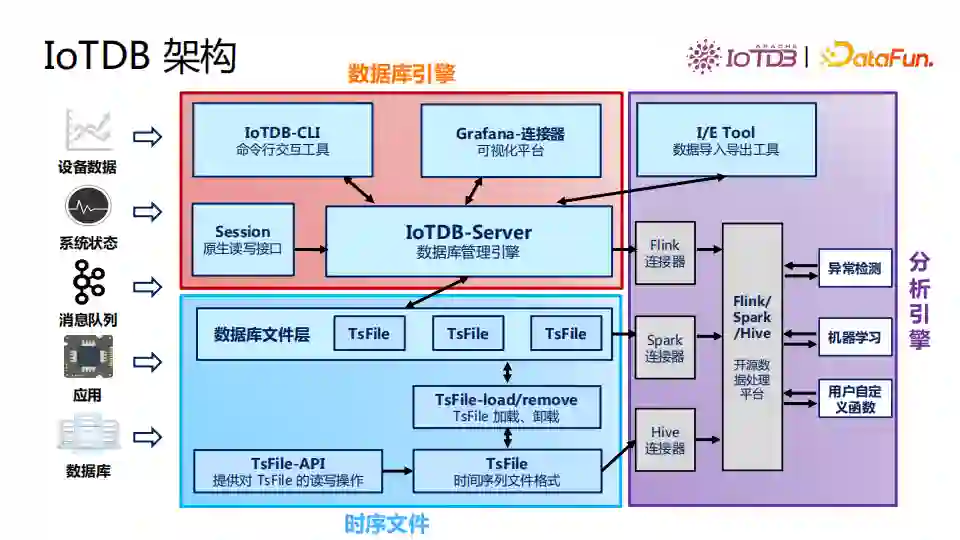
最左面是数据的来源,有设备数据、系统状态等。 数据可以通过图中蓝色部分的时序文件导入。我们提供了文件级的API,API和Parquet、ORC类似,可以对单个TsFile进行读写操作。我们把数据通过API写成TsFile文件格式后,可以通过TsFile的一些加载模块把文件加载到数据库中。此时数据文件层的TsFile是被数据库的引擎所索引的,它其实在磁盘上只是换了一个目录,我们还是能够看到这些文件。这里的文件可以加载进去再卸载出来,文件管理非常灵活。 文件层之上是数据库的引擎层。数据库的引擎能够管理多个数据文件,它还负责提供给用户更多访问数据库的接口,包括原生的读写接口session以及命令行,交互工具,还有可视化的平台。 分析引擎方面,我们开发了各种对接开源数据处理平台的连接器,IoTDB 和底层的数据文件,都可以和分析引擎进行对接。 IoTDB是一个比较开放的架构,架构的设计也是我们在不断地使用开源系统的过程中总结出来的。针对文件灵活的设计简化了数据库的运维,让我们可以随时从一个数据库里把数据文件拿来做分析。文件也可以从这个设备侧写完后再加载到数据库里去。 端侧应用的监控通常不需要非常及时,文件足够满足需求;端侧文件上传到边侧进行分析,也可以放到数据库中进行查询;云侧文件可以将文件对接Spark、Flink做数据分析,可以作为时序数据仓库使用。边侧和云测可以部署IoTDB数据库。
基于TsFile两层设备和物理量模型,我们在数据库层面扩展了丰富的树形结构的物联网数据模型。树形结构对应了层级管理设备资产的方式,即设备归属的区域、设备的类型、设备号。从Root到倒数第二层节点的全路径来定位设备ID。这种建模方式可以把一个应用的所有时间序列都统一到一棵树中进行管理。
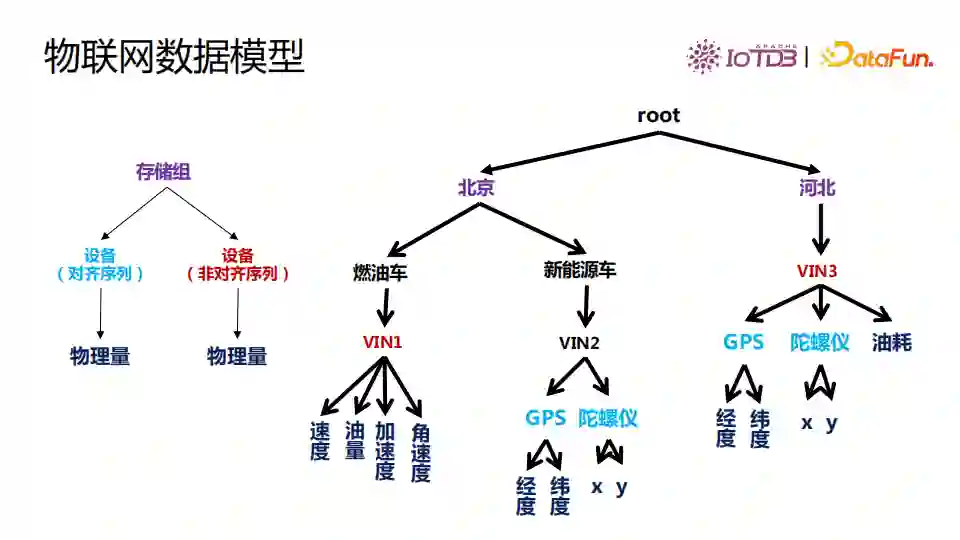
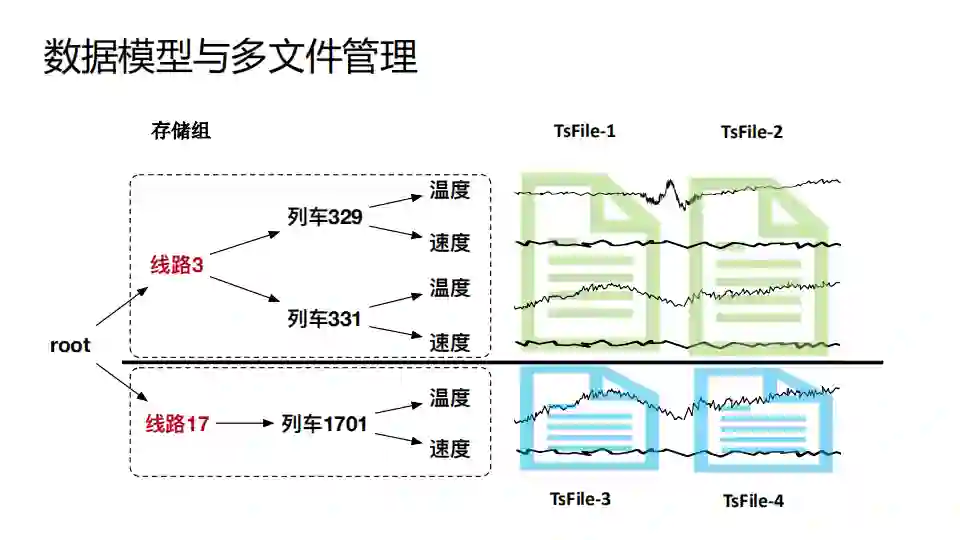
树形结构的数据模型与TsFile通过存储组进行连接。存储组可以让用户指定哪些序列可以存储到一个文件里,一个存储组一段时间的数据会形成一个TsFile。
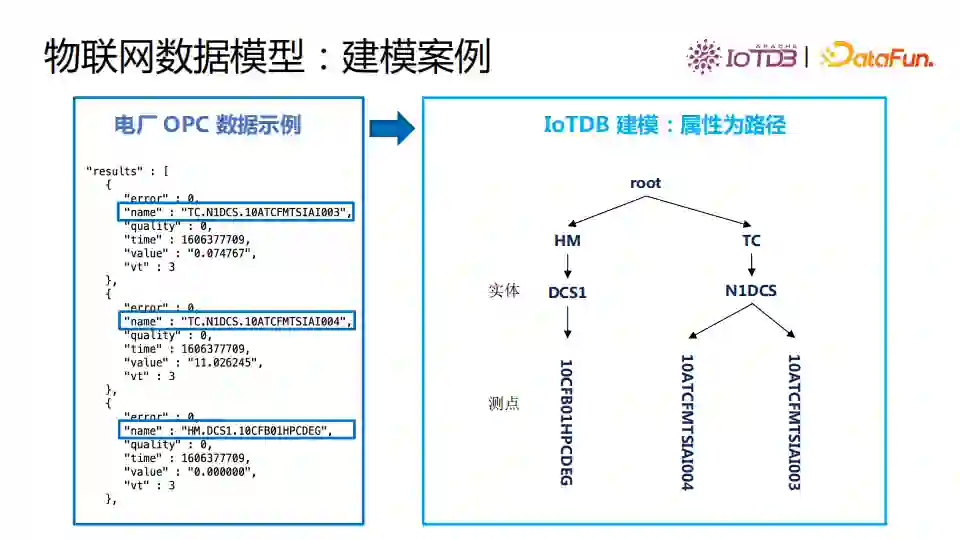
接下来我们看一些实际数据模型转化在IoTDB中建模的案例。图中是OPC Server采样的点位,这些点位是一个个Name,按点分割。这个结构和树形结构有天然的映射关系,我们可以在数据前面加一个root,按点进行树形模型拆解后构造成一棵树,映射非常自然。
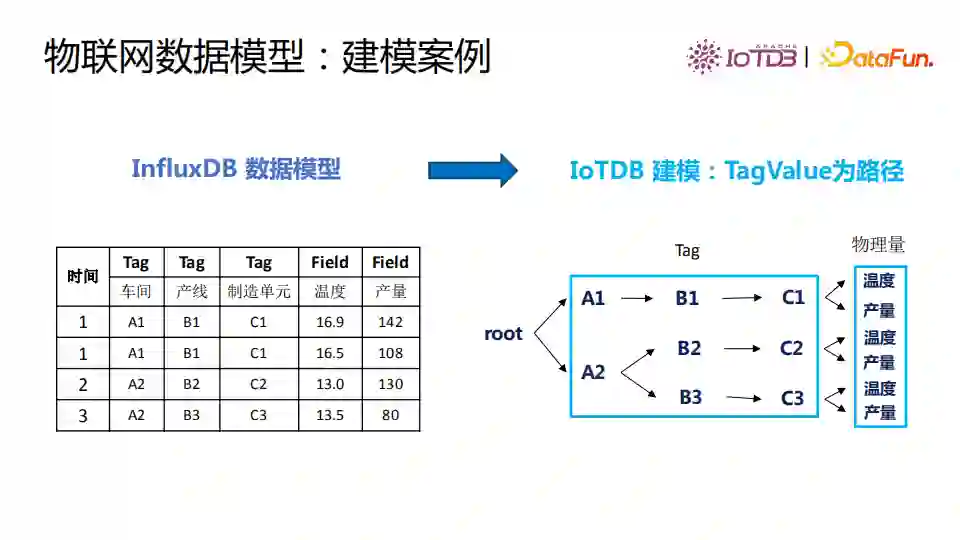
InfluxDB数据模型有Tag和Field,我们把Tag value当作树里的节点,Field name作为物理量。我们不重复存储Tag name,可以快速定位数据。
04****开源社区建设
1. 核心理念
开源社区建设方面,我们运营了两年开源社区,愈发感受到开源社区核心理念的重要性。 平常在公司和团队内工作与开源社区不同,开源社区需要更多地把沟通开放出来。IoTDB是一个基于文件的开放架构,思想也要对应地开放。清华软件学院团队的工作流程都需要文档化,向社区开放,同步项目进度。 作为开源贡献者,我们每个人都希望我们提的一件被尊重,对于开源社区来说这也是一个对待贡献者的基本态度。 有些贡献者除了提一些建议外还能给贡献代码,小的修改提一个pr社区就可以审阅合并,但更大的功能模块开发就需要分布式协作了。 我们建设开源社区的思路是通过开放架构、开放思想,尊重每个人的建议和分布式协作,达到为用户提供好用的开源软件的核心目标。 2. 建立了活跃的开源社区
IoTDB社区目前有160多位开发者,上千人的用户群。IoTDB经常举办培训会和开发者、用户见面会。
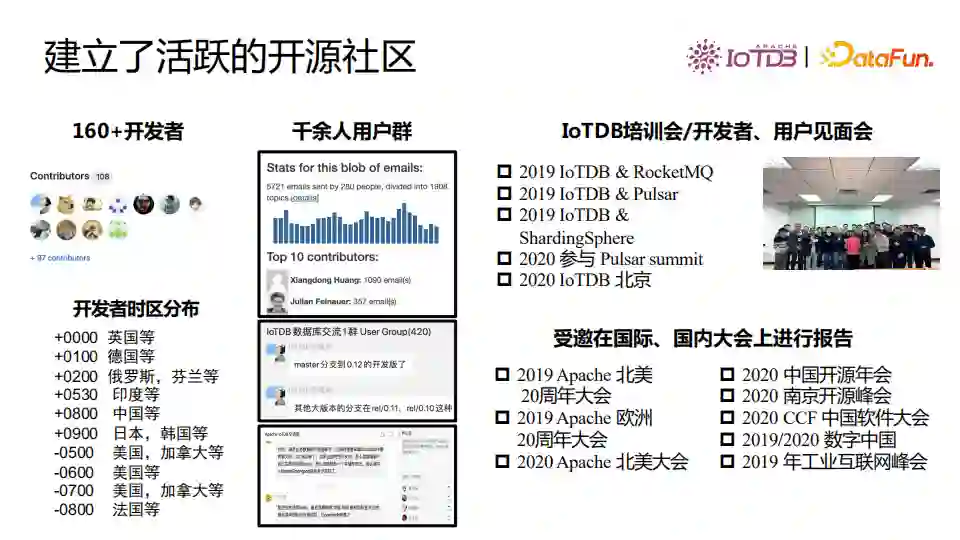
3. 社区影响力日益凸显
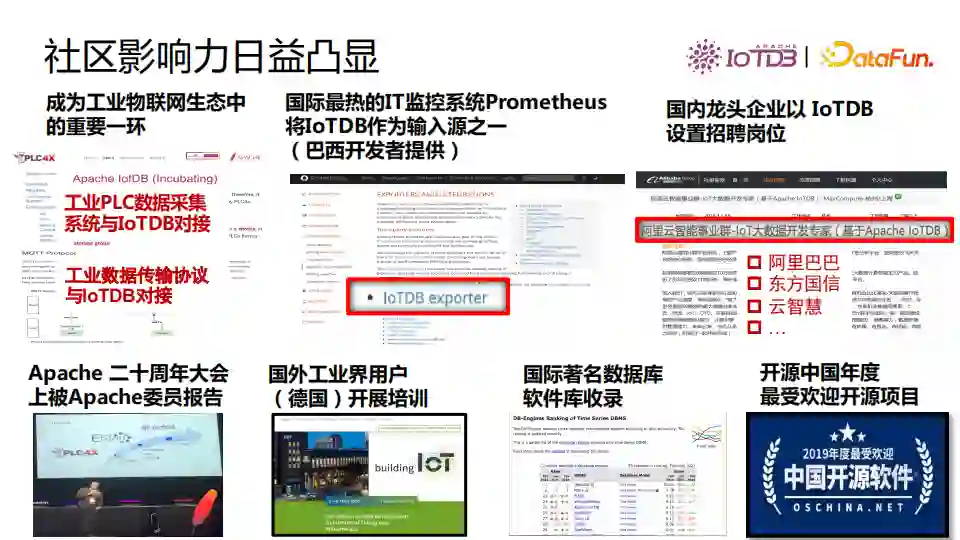
社区在软件开发过程中的影响力逐渐增加,工业PLC数据采集系统已经与IoTDB进行了对接和集成,巴西的一些开发者贡献了IoTDB作为Prometheus的底层存储。国内龙头企业也设置了IoTDB相关的工作岗位。
4. 应用案例
在应用方面:上海地铁运行了两年半,管理了100万时间序列数据。湖南湘潭和耒阳电厂数据管理系统应用IoTDB运行了20个月,管理1万条序列。东莞东城环卫管理系统中管理的各种环卫车的数据,运行两年多时间中管理着数千条序列。





