机器推理系列第四弹:基于推理的多轮语义分析和问答
编者按:自然语言处理的发展进化带来了新的热潮与研究问题。基于一系列领先的科研成果,微软亚洲研究院自然语言计算组将陆续推出一组文章,介绍机器推理(Machine Reasoning)在常识问答、事实检测、自然语言推理、视觉常识推理、视觉问答、文档级问答等任务上的最新方法和进展。此前我们介绍了机器推理的系列概览,机器推理在常识问答和事实检测任务中的应用,以及跨语言预训练,本文是该系列的第四篇文章。
推理是自然语言处理领域非常重要且具有挑战性的任务,其目的是使用已有的知识和推断技术对未见过的输入信息作出判断(generate outputs to unseen inputs by manipulating existing knowledge with inference techniques)[1]。在本文中,我们介绍机器推理在多轮语义分析和问答任务的最新方法和进展。
对话中的多轮问答(conversational question answering)和语义分析(semantic parsing)是自然语言处理领域的两个核心问题,对语音助手、聊天机器人和搜索引擎等应用都至关重要[2]。
多轮问答的目的是在交互式场景中正确回答自然语言问题。以图1的基于知识图谱的多轮问答为例,人们常常省略实体(如第二个问句),或省略意图(如第三个问句),使对话更加简洁和连贯。类似地,在图2的基于表格的多轮问答样例中,我们可以看到同样的省略现象。因此,有效理解对话历史对多轮问答系统至关重要。
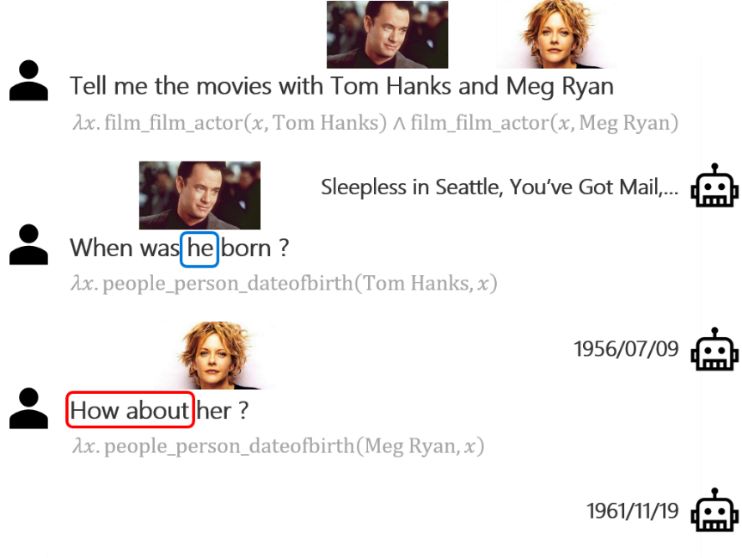
图1:基于知识图谱的多轮问答和语义分析示例

图2:基于表格的多轮问答和语义分析示例
语义分析是解决问答任务的一个理想方向,其目的是把自然语言转换成机器可理解可执行的语义表达(meaning representation),该语义表达通常遵循某一语法(如lambda calculus, SQL),具有很强的语义组合性,并且可以精确地反映问题的推理过程,可以在某个知识表示(如知识图谱、表格)上直接执行获得结果。
在本文中,我们介绍如何利用推理的方法有效地解决多轮问答和语义分析问题。我们以基于知识图谱[3-4]的多轮问答进行介绍,对基于表格的多轮问答感兴趣的读者请阅读我们发表在 NLPCC-2019 的工作[5]。
具体来说,任务的输入包含知识源(如知识图谱或表格)、当前轮的问题及对话的问答历史,任务的输出是当前轮问题的答案。为了理解整个模型的推理过程,我们使用语义分析的方式,即对每个输入问题输出一个语义表达,该语义表达在输入的知识源上执行即可获得答案。
我们提出了如图3所示的机器推理模型,其中共利用了三种知识:第一种是语法知识(grammar knowledge),该模型会在语法知识的指导下生成语义表示中的每个单元,对于语义分析任务来说,生成的语义表达要在语法正确的前提下正确表达问题的含义;第二种是对话历史中的上下文知识,该模型会记录历史问句的语义解析结果,并利用其生成当前轮问题的语义表示,这对处理多轮问答中的省略(实体省略或意图省略)尤为重要;第三种是数据知识,我们从训练数据自动检索与当前数据相似的实例,通过基于元学习(meta-learning)的推断方法获得与当前样例更相关的“个性化”模型。
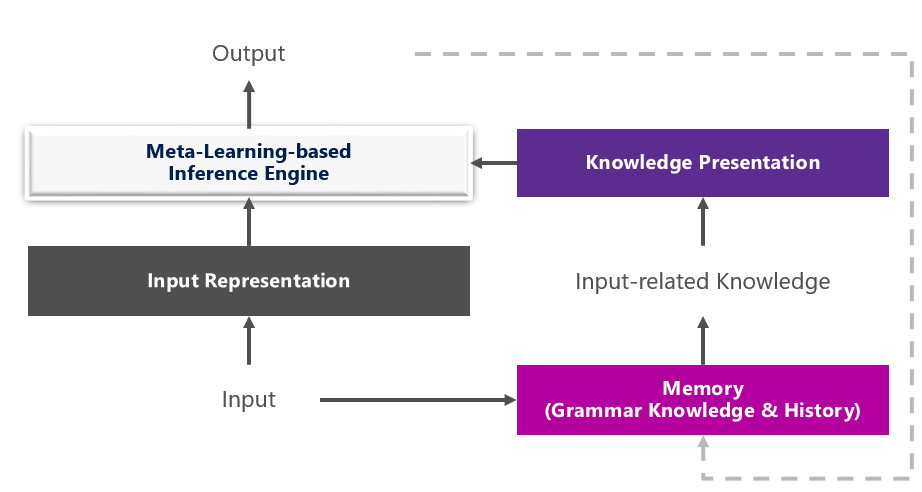
图3:基于机器推理的多轮语义分析和问答框架
在基于知识图谱的问答场景下,我们定义了如图4的语法操作,包括查找、比较、计数、复制历史逻辑表达等。语法中每个动作操作都可以看做一个推演规则,左边是数据的类型,右边是可以推演出该类型数据的函数,函数中包含特定类型的参数。
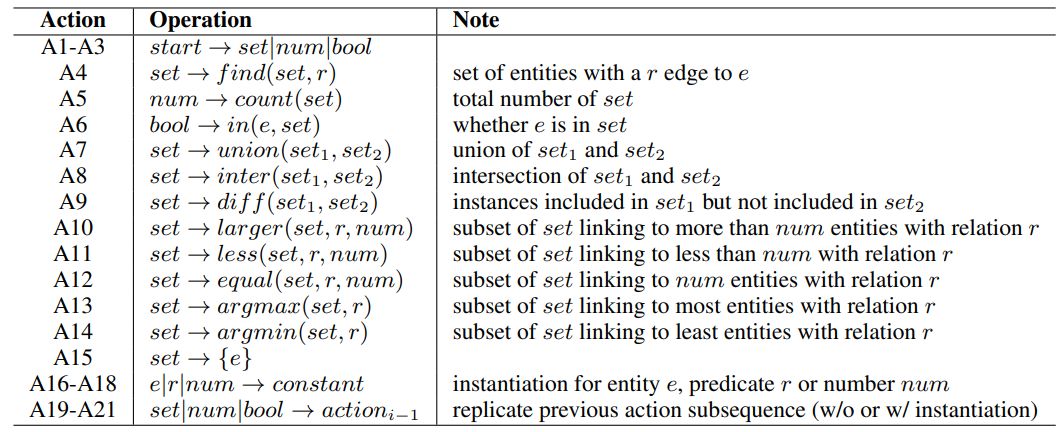
图4:基于知识图谱的多轮问答任务中定义的语法
在此基础上,我们使用自顶向下的方式预测当前问题的逻辑表达。我们使用了序列到动作(sequence-to-action)的模型,该模型将输出序列化语义表示转换为输出遵循语法的动作序列,不仅可以利用编码器-解码器框架建模序列的优势,还可以保证输出的语法正确性。此外,该模型可以非常自然地利用上下文知识。如图5所示,我们在 Dialog Memory 中记录了历史问句的语义解析结果,在输出每个动作时都有一定的概率复制历史的语义表示子序列。模型的具体细节请参考[3]。
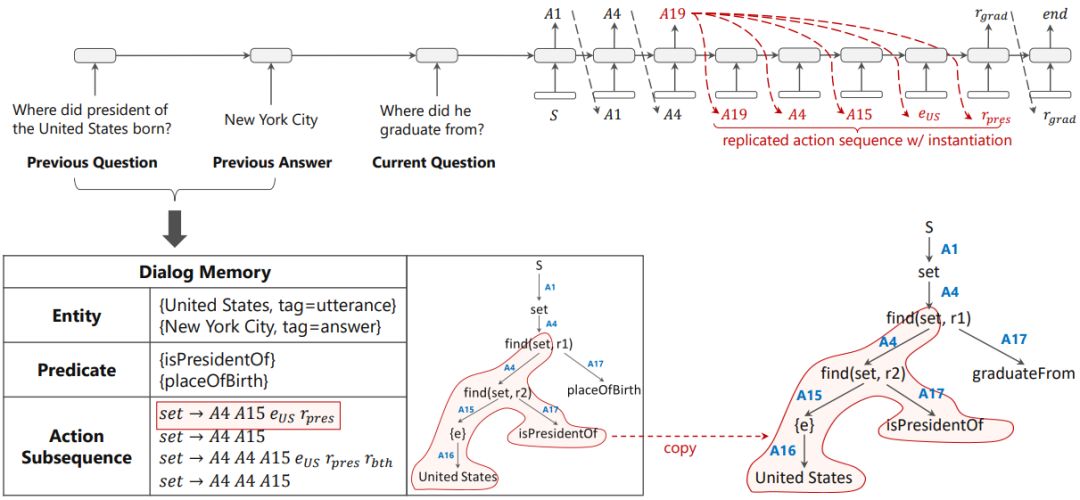
图5:基于知识图谱的序列到动作(sequence-to-action)模型[3]
受训练数据中统计分布的影响,基于神经网络的生成模型很容易生成通用的序列[6]。我们提出了基于元学习的推断模型缓解这一问题。具体地,对于任一输入,我们自动从训练数据集中查询与其语义相似的样本,随后在基本模型 f(θ) 的基础上微调,获得为当前样本量身定做的模型 f(θ^')。在训练的过程中,我们需要同时学习基本模型 f(θ) 和在查询样本上把 f(θ) 微调到 f(θ^') 的过程。我们将这一过程建模为元学习,在训练过程中同时训练这两个过程,如图6所示。更多细节请参考[4]。实验结果如图7所示,我们提出的多轮语义分析和问答方法在 IBM 研究院多轮复杂问答任务 CSQA 上取得了目前 state-of-the-art 的结果[3][4]。
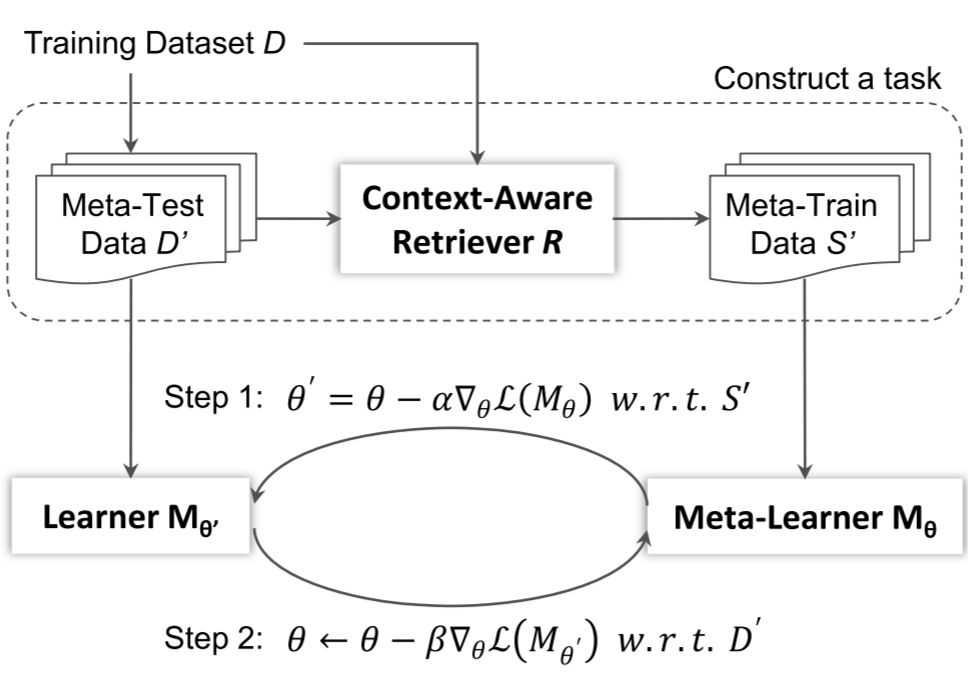
图6:基于元学习的推断模型
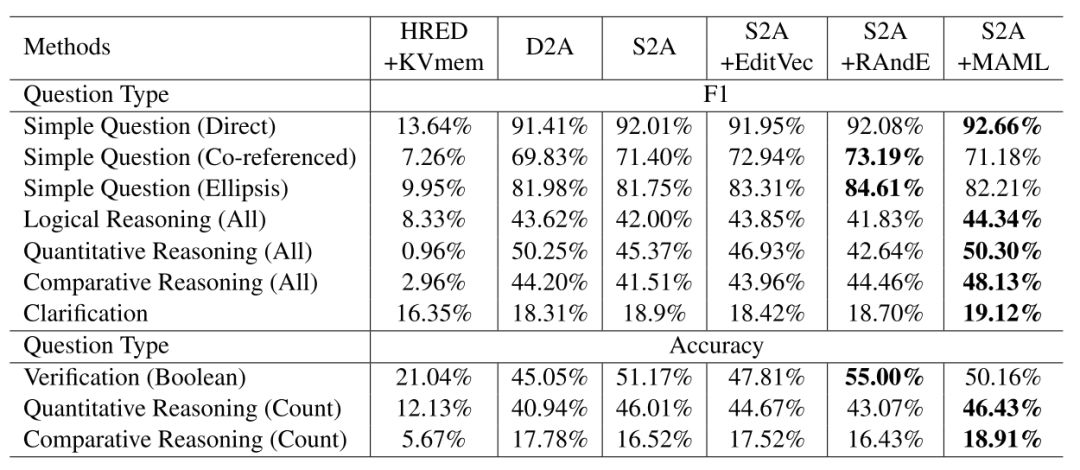
图7:我们提出的多轮语义分析和问答方法在多轮复杂问答任务 CSQA 上取得了目前的最佳结果[3][4]。
本文介绍了基于机器推理的方法在多轮语义分析和问答中的应用,该方法有效利用语法知识、上下文知识和数据知识,在多轮复杂问答任务 CSQA 上取得了目前 state-of-the-art 的结果。
敬请期待机器推理方法在更多推理任务上的应用!
参考文献:
[1] Ming Zhou, Nan Duan, Shujie Liu, Heung-Yeung Shum. Progress in Neural NLP: Modeling, Learning and Reasoning. Accepted by Engineering, 2019.
[2] 段楠,周明. 《智能问答》. 高等教育出版社,2018.
[3] Daya Guo, Duyu Tang, Nan Duan, Jian Yin, Ming Zhou. Dialog-to-Action: Conversational Question Answering over a Large-Scale Knowledge Base. NeurIPS, 2018.
[4] Daya Guo, Duyu Tang, Nan Duan, Ming Zhou, Jian Yin. Coupling Retrieval and Meta-Learning for Context-Dependent Semantic Parsing. ACL, 2019.
[5] Yibo Sun, Duyu Tang, Jingjing Xu, Nan Duan, Xiaocheng Feng, Bing Qin, Ting Liu, Ming Zhou. Knowledge-Aware Conversational Semantic Parsing Over Web Tables. NLPCC, 2019.
[6] Tatsunori Hashimoto, Kelvin Guu, Yonatan Oren, Percy Liang. A retrieve-and-edit framework for predicting structured outputs. NeurIPS, 2018
本文作者:郭达雅、唐都钰、段楠、周明
本文转载自公众号:微软研究院AI头条,作者:自然语言计算组
推荐阅读
Google工业风最新论文, Youtube提出双塔结构流式模型进行大规模推荐
T5 模型:NLP Text-to-Text 预训练模型超大规模探索
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。




