教AI逐帧搓招玩《铁拳》通关最高难度,现在的街机游戏爱好者有点东西啊
博雯 发自 凹非寺
量子位 | 公众号 QbitAI
现在的AI都开始学着逐帧搓招打街机了?
《拳皇98》、《街头霸王》、《死或生》……一干童年回忆全都玩了个遍,其中还有号称要打5000场才能入门的3D格斗游戏《铁拳》:

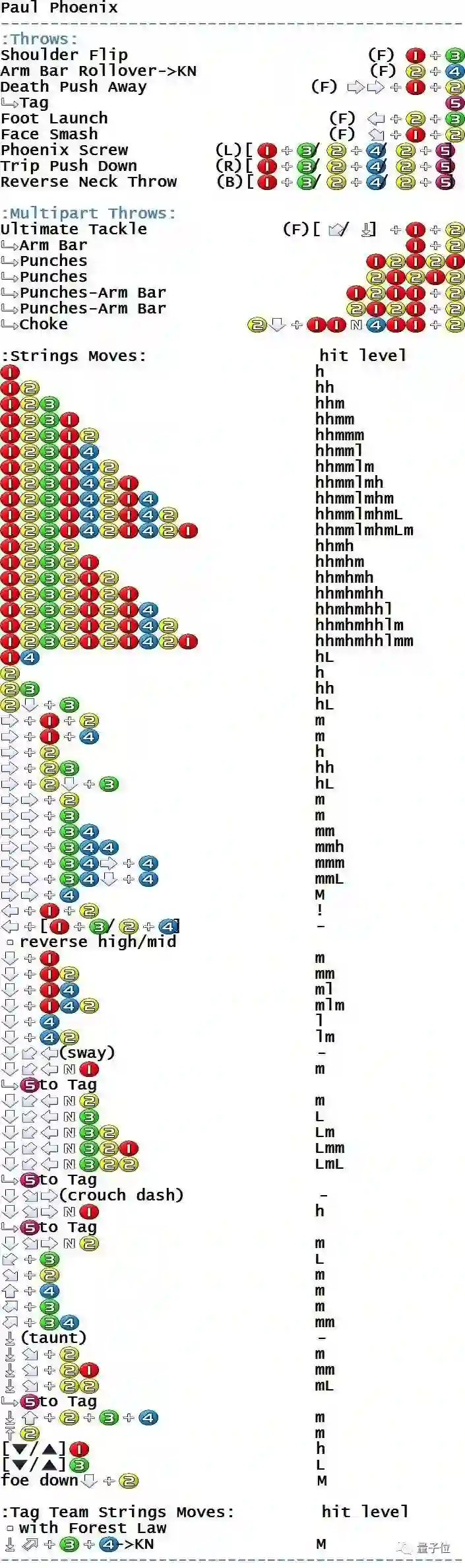
没错,就是那个对新手极不友好的《铁拳》,随便拉一张角色的搓招表感受一下这个复杂度:
(没错,各种压帧判定的JF技就是其特色之一)

△铁拳 TT2出招表
但AI偏偏就能在入坑没多久就通关了最高难度:

△左侧为AI
这款AI的背后是一位个人开发者,也是一位骨灰级的街机游戏爱好者。
他训练出来的新手“铁匠”在Reddit的“比赛录播”已经有近500的热度:
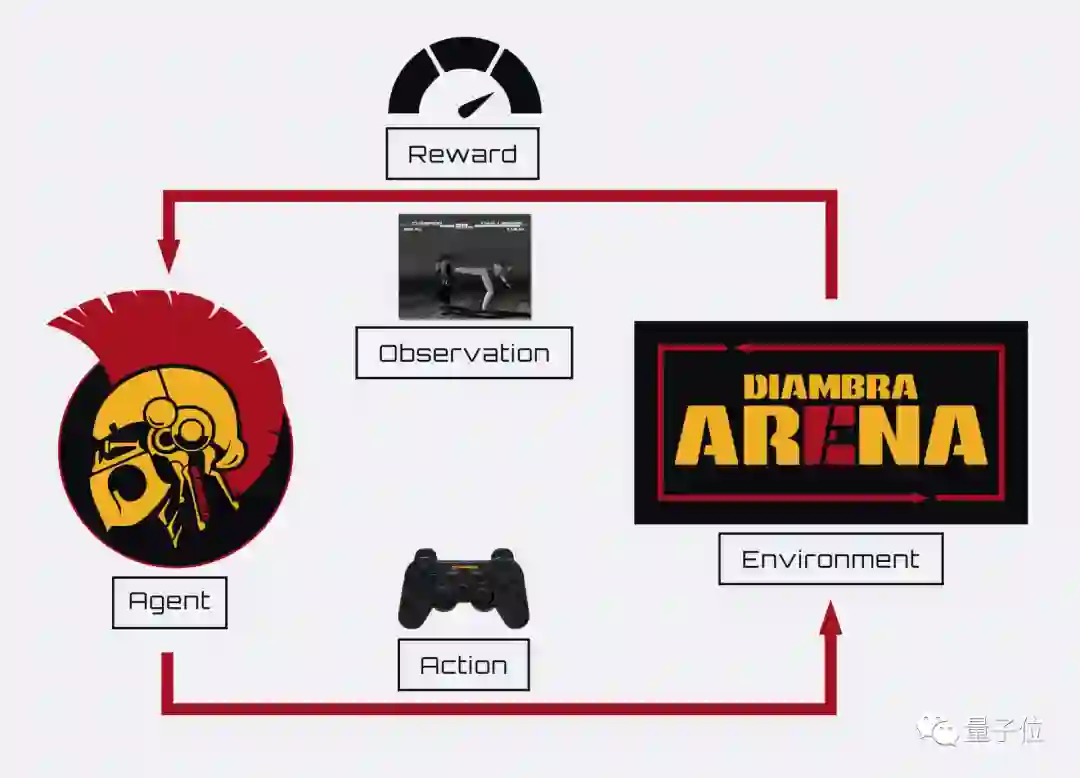
强化学习训练框架
这位AI铁匠的背后,是一个叫做DIAMBRA Arena的强化学习交互框架。
DIAMBRA Arena提供了多个强化学习研究和实验环境,具有情节性的强化学习任务,由离散的动作(如游戏手柄按钮)和屏幕中的像素和数据(如人物血条)组成。
在这一框架中,智能体会向环境发送一个动作,环境对其进行处理,并相应地将一个起始状态转换为新状态,再将观察和奖励返回给智能体,以此交互循环:
要实现上述循环的代码也非常简单:
import diambraArena
# Mandatory settings
settings = {}
settings["gameId"] = "doapp" # Game selection
settings["romsPath"] = "/path/to/roms/" # Path to roms folder
env = diambraArena.make("TestEnv", settings)
observation = env.reset()
while True:
actions = env.action_space.sample()
observation, reward, done, info = env.step(actions)
if done:
observation = env.reset()
break
env.close()
这一框架目前支持Linux、Windows、MacOS等主流的操作系统。
而这款AI的“实战场”为早期的Tekken Tag Tournament,当然,搓招复杂度完全不逊色于之后的新版本……
开发者选择了风间仁(Jin)和吉光(Yoshimitsu)两名具有代表性的角色作为主要操作对象。
输入分别为:从RGB转换为灰度,并缩小到128 x 128px的游戏屏幕像素值、对战局数(Stage)、人物血条、游戏界面的一侧。
训练中的奖励是一个基于生命值的函数,如果对方生命值损伤则得到正面奖励,己方控制的角色生命值损失则得到负面惩罚。
同时,AI的动作速率也被限定为最大速率的1/10,即游戏中每6步发送一个动作。
由于框架使用的是一种离散的动作空间,因此,智能体在训练中的同一时间只能选择一个移动动作9向上,向下等)或攻击动作(冲击,踢,出拳)。
因此,虽然一个连击组合的实战能力更强,但由于AI无法同时点击两个动作,在真实的对战中,便会出现AI频繁使用踢(Kick)和更换角色(swap)两个动作的情况:

评论区有资深PVP爱好者表示,想要看到这种顶级AI选手互虐的激烈场景,而开发者本人对此非常赞同:
我们正在创建一个平台,在这个平台上,程序员将提交他们训练有素的AI并互相对抗,并在我们的频道上播放比赛。

AI锦标赛
现在,开发者团队已经开始正式筹备这个“AI游戏锦标赛”,背后的程序员和开发者们相当于是“教练”或者“选手家长”,最终的获胜者可获得1400瑞士法郎(折合人民币9261元)。

“比赛项目”也不止是铁拳一种,开发者表示,这些格斗游戏的底层机制都比较类似,只需要修改一下组合技、人物血条数值等游戏的差异性属性。
所以,他们的DIAMBRA Arena框架面向各类街机视频游戏提供完全符合OpenAI Gym标准的Python API。
像死或生、街头霸王等多个流行的街机游戏都被囊括其中:
GitHub链接:
https://github.com/diambra/diambraArena
视频链接:
https://www.youtube.com/watch?v=9HAKEjhIfJY
参考链接:
[1]https://www.reddit.com/r/reinforcementlearning/comments/sq1s3f/deep_reinforcement_learning_algorithm_completing/
[2]https://www.reddit.com/r/MachineLearning/comments/sqra1n/p_deep_reinforcement_learning_algorithm/
— 完 —
「智能汽车」交流群招募中!
欢迎关注智能汽车、自动驾驶的小伙伴们加入社群,与行业大咖交流、切磋,不错过智能汽车行业发展&技术进展。
ps.加好友请务必备注您的姓名-公司-职位哦~

点这里👇关注我,记得标星哦~
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~





