机器之心转载
来源:知乎
作者:知乎用户@迪迦奥特曼
前不久看到了美团微信公众号上的宣传,更新发布了新版 YOLOv6,还放出了 arxiv 论文,更新了之前的 N/T/S 小模型,也放出了 M 和 L 版本的大模型,论文实验表格多达十几个,看的出来是很用心的做了,YOLO官方也认可了这个起名。
之前本人写了一个 YOLO 合集的文章(迪迦奥特曼:从百度飞桨 YOLOSeries 库看各个 YOLO 模型:https://zhuanlan.zhihu.com/p/550057480) ,对 YOLOv6 介绍的不多,现在还是先重新来具体分析下这个全新版 YOLOv6。此外想聊聊关于怎么选 YOLO 模型去训业务数据集的一些感想。
-
对于 N/T/S 版本的小模型,采用 EfficientRep,也就是第一版 v6 的结构;
-
对于 M/L 版本的大模型,采用 CSPBepBackbone,是借鉴 CSP 思想这次新加的;
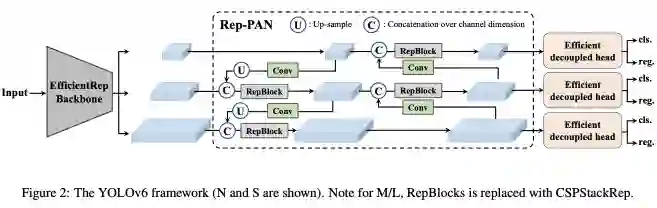
![]()
图虽然直观但是不全,具体还是看代码好理解。可以看出两个 backbone 差别只在于基础模块 block 用的不同,一个 是 RepBlock 一个是 BepC3,此外还有一个通道划分因子 csp_e 区别。
-
https://github.com/meituan/YOLOv6/blob/main/yolov6/models/efficientrep.py#L37
-
https://github.com/meituan/YOLOv6/blob/main/yolov6/models/efficientrep.py#L142
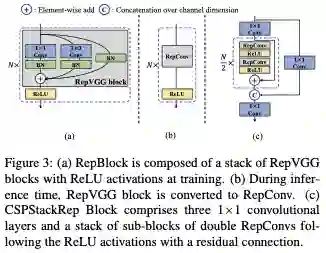
核心模块还是 RepVGG,今年的 yoloe、yolov6、yolov7 都相继使用了,只是使用范围幅度不一。
![]()
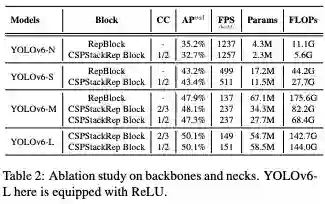
有意思的是 v6 做了实验对比 RepBlock 和 CSPStackRepBlock,CSP 形式确实大大的减少了参数量 FLOPs。也难怪要新设计 CSPStackRep,v6-M 上看原先 RepBlock 结构参数量计算量简直大到爆炸。CSP 形式在小模型上表现不太行,但是 v6-M 的 2/3 设置又有点诡异。
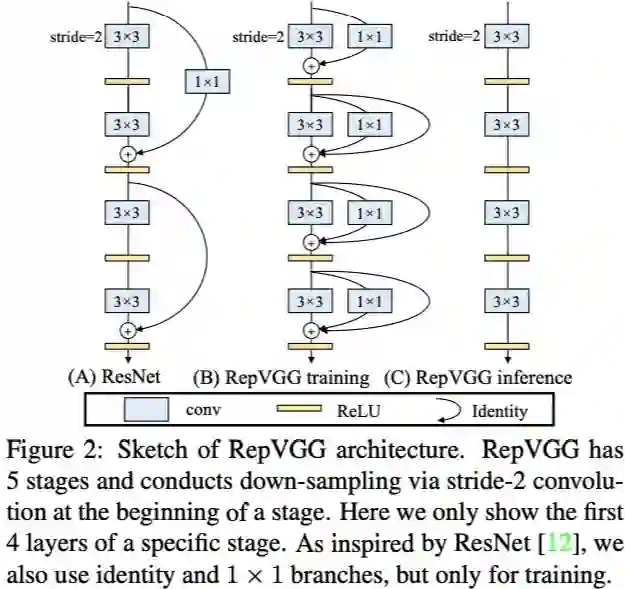
![]()
![]()
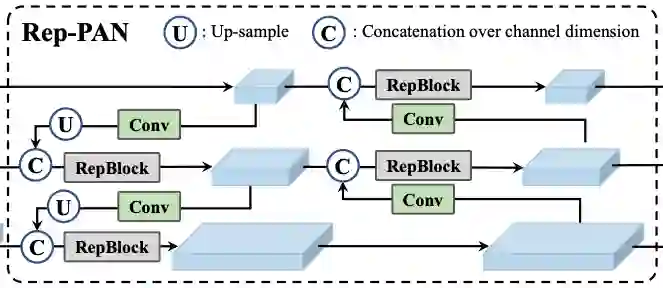
基于 YOLOv5 YOLOX 的 PAFPN 结构也进行了改进:
-
对于 N/T/S 版本的小模型,采用 RepBlock 替换 CSPBlock;
-
对于 M/L 版本的大模型,采用 CSPStackRepBlock 进行替换;
同样也是一个是 RepBlock 一个是 BepC3,此外还有一个通道划分因子 csp_e 区别。
-
https://github.com/meituan/YOLOv6/blob/main/yolov6/models/reppan.py#L23
-
https://github.com/meituan/YOLOv6/blob/main/yolov6/models/reppan.py#L148
新版使用的是像 TOOD Head 那样的形式,使用 ATSS assign 作为 warmup 阶段的标签分配机制,后期则使用 TAL assign,相比第一版几乎就 YOLOX 的 head 算好的了。之前瞄到了 [yoloseries](https://github.com/nemonameless/PaddleDetection_YOLOSeries) 库里的 paddle yolov6 的复现,才发现简直和 PPYOLOE head 是一模一样,包括 assign 过程和 loss 过程。不过 v6 head 区别在于没有用到 PPYOLOE 里的 ESEAttn 注意力,分类和回归的特征 v6 也是有公用的一个 stem,而 PPYOLOE 里是分离的 stem。估计各家为什么这么设计也是实验证明过的吧,都有自己的道理。此外 v6 head 还有 distill 的部分 loss,算是自己的特色 trick 刷点来看还是很有用的。
-
原版 v6 head:https://github.com/meituan/YOLOv6/blob/main/yolov6/models/effidehead.py
-
库里的 v6 head 的实现,包括 loss:https://github.com/nemonameless/PaddleDetection_YOLOSeries/blob/release/2.5/ppdet/modeling/heads/effide_head.py yoloseries
-
PaddleDetection 的 ppyoloe head 的实现,包括 loss:https://github.com/PaddlePaddle/PaddleDetection/blob/develop/ppdet/modeling/heads/ppyoloe_head.py
-
原版 v6 head loss:https://github.com/meituan/YOLOv6/blob/main/yolov6/models/loss.py
看总体设计还是看代码配置文件。但其实 v6 的配置很不统一,包括之前 v7 也是不统一,都像是每个模型单独调优。看到 yoloseries 库的作者的总结:
-
YOLOv6 n t s 模型使用 EfficientRep 和 RepPAN,YOLOv6 m l 模型使用 CSPBepBackbone 和 CSPRepPAN,Params(M) 和 FLOPs(G) 均为训练时所测;
-
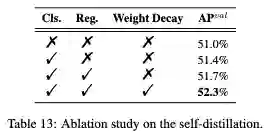
YOLOv6 m l 模型训练默认使用蒸馏自监督辅助训练,且使用 dfl_loss 和设置 reg_max=16,其余 n t s 模型则未使用;
-
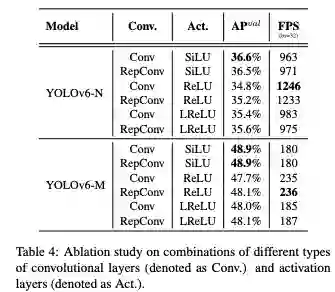
YOLOv6 l 模型原文默认激活函数为 silu,其余 n t s m 模型则默认为 relu;
-
YOLOv6 n t 模型原文训练默认会使用到 siou loss,其余 s m l 模型则默认使用到 giou loss;
此外还有优化器一些参数的不同吧太琐碎了。以前用习惯了 yolov5 yolox 的配置,大模型和小模型差别就改个 width depth 参数,yoloe 也是这样,就很方便和统一。虽然有实验证明大模型小模型用哪个好,但是这样的设置每个模型单独调优就只为了争 0. 几的 mAP 也位面太麻烦了,而且只是 COCO 数据集的 mAP,模型原模原样重训两遍 0.3 以内的 mAP 波动都还算正常的。
自监督蒸馏是一个 v6 的特色,涨点很多如下表,之前 yolov7 的 1280 P6 大尺度模型也使用了辅助头蒸馏,是个不错的 trick。总的来看,自监督至少有 1.0+ mAP 的增益。
![]()
精度上看,v6 确实足够高了,但对比发现,L 版本默认换成了 silu,不和 N/T/S/M 的 relu 统一了,虽然单列了一个 L-relu,估计是速度够快了为了再加强些精度再训的 silu 版本,乍一看 Model Zoo 还以为所有模型都是 silu 只是 L 单独训了一个 relu 的。速度上看 relu 真的测速度会更快的多!在第一版发布的时候早有大佬说过。不得不说这个实验严谨程度让人钦佩。
![]()
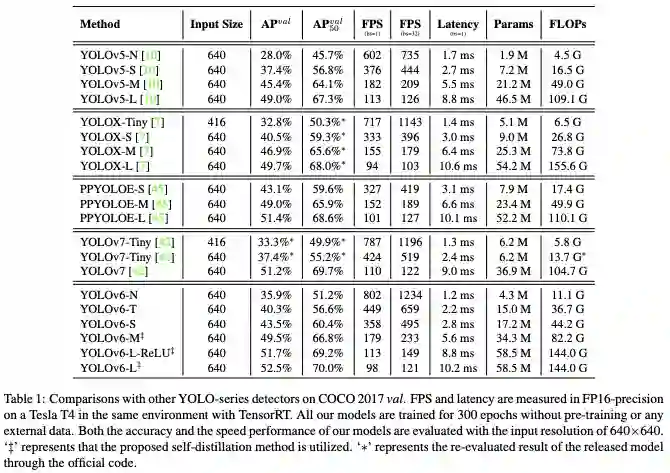
此外还有很多表格对比实验验证,这也是各个模型配置文件不统一的主要原因。小模型可能 siou 更适合,tiny 第一版是 depth=0.25 width=0.50,现在改成了 depth=0.33 width=0.375 正常配置,掉了点精度换的了参数量更小速度更快。此外大模型 M 和 L 的自监督蒸馏提了不少点,其中 M 的 depth 是 0.6 而不是常用的 0.67,而最诡异的是调个通道划分因子 csp_e 就能涨 0.8 之多。最后没有像 v7 v5 那样有大模型 X 版本和 1280 尺度有点遗憾,可能参数量 flops 过大,精度性价比不高了。
![]()
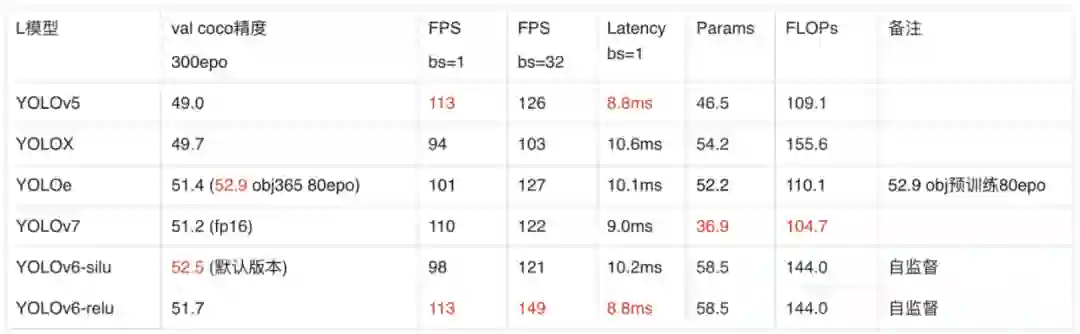
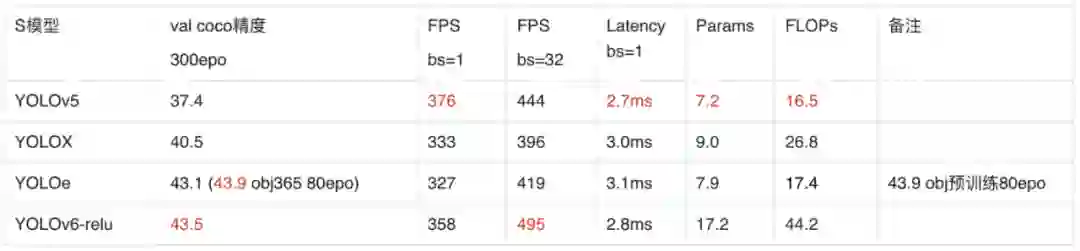
根据上述表格,本人抽空整理了下的最常用的 S 和 L 版本的几个 YOLO 模型的数据,按发布时间顺序,供大家参考:
![]()
![]()
注意:速度由于各个 YOLO 的平台环境不同,甚至版本和框架不同都会有影响,实际还是得自己实测,也要注意几次测波动不同也是正常的。
今年堪称 YOLO 内卷元年,先是 yolov5 yolox yoloe 神仙打架,各大用户用的正欢,一看美团 v6 出来了哇新 yolo 马上就换 v6,再一看 v7 出来了立马再换 v7,再一看 v6 又更新了精度更高再重新换 v6,很多时候就是在来回折腾,数据量少重训一遍还好,数据量大简直就像扛着炸药包折返跑,训完了新的精度搞不好还低了。
所以在这样的内卷期,作为普通用户我们应该怎么选择模型呢?个人发表一点拙见。
首先需要明确自己项目的要求和标准,精度和速度一般是最重要的两个指标,另外还有模型参数量、计算量等等,注意这些还都必须在自己项目的设备上为前提。
1. 首先是
精度
,一看各家 YOLO 首页的折线图就知道了,都是恨不得自己一条最高全面压住所有对手,当然这也是各家的主要卖点。这个复现也是最有保证的。
但是我想说的是,虽然各家都会刷权威的 COCO 精度,但真到业务数据集上的时候,效果哪个高就不一定了,尤其是 COCO 精度差距在 1.0 以内的模型,其实选哪个都行,再说也不能纯看 mAP,还有 ap50 ap75 recall 等指标呢。
训业务数据要高精度,最重要是一点是加载超强的 pretrain 权重!!!这个恐怕还是很多新手不知道的。COCO 预训练可以极快收敛并达到比 imagenet-pretrain 训更高的精度,一个超强 pretrain 顶过绝大多数小修小改的 tricks。
之前 yoloe 也更新了一版 yoloe plus 也叫 yoloe+,放出了 objects 365 预训练,这个简直是超级外挂,全量 coco 只训 80epoch 刷的超高,我用了之后自己数据集相比加载原先 coco 预训练涨了 5 个点 mAP!还是缩短一半训练 epoch 的情况下。
之后还要训一个 20 万张图的数据集,比 coco 量级还大的时候 coco 预训练就不够用了,训 300
epoch 甚至 80epoch 都和蜗牛一样慢,而 obj365 预训练正好派上用场估计训 30epoch 就行。
此外自监督半监督等策略,确实是可以提精度,作为大厂自己 PR 还是可以的,但是就用户使用而言可能会有点鸡肋麻烦,有点耗时耗资源。
2. 其次是第二卖点
速度
,这个不像精度很快就能跑复现证明的,鉴于各大 YOLO 发布的测速环境也不同,还是得自己实测过才知道。
另外各大 YOLO 发布的速度只是去 NMS 去预处理的纯模型速度,真正使用还是需要加上 NMS 和预处理的,NMS 的参数对速度影响极大,尤其是 score threshold 还有 top k keep k。score threshold 一般为了拉高 recall 都会设置 0.001 0.01 之类的,这种范围的低分框其实没什么用,NMS 阶段会极大的浪费时间。但是调成 0.1 0.2 速度就飙升了,不过代价是掉一些 mAP。而调 top k keep k 也会影响速度,尤其 top k,但是都对 mAP 影响较小,具体可以自己实践。
总之实际应用需要自己实践不能只看论文速度,并且是算上 NMS 的耗时的,而 NMS 耗时又是自己可控的。
3. 然后是
计算量参数量
,这个一般不会着重考虑,但也不能太离谱毕竟有些设备还是有限制,堆模块改成原版两倍 3 倍级别换来一点点 mAP 的提升是 AI 竞赛常用的套路,而且一般会牺牲些速度,意义不大。另外还有些特殊模块,比如 ConvNeXt 参数量极大但是 FLOPs 很小,会掉速度,可以刷点但也意义不大。csp 形式的设计极大的降低了参数量 FLOPs,也许以后新模块都可以设计个 csp_xxx 去使用。
总之,YOLO 内卷时期要保持平常心,针对自己的需求,选准适合自己的模型。
YOLOv6 论文:YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications, https://arxiv.org/abs/2209.02976
YOLOv6 代码:https://github.com/meituan/YOLOv6
YOLOSeries 代码:https://github.com/nemonameless/PaddleDetection_YOLOSeries
PPYOLOE 论文:PP-YOLOE: An evolved version of YOLO, https://arxiv.org/abs/2203.16250
PaddleDetection 代码:https://github.com/PaddlePaddle/PaddleDetection
原文链接:https://zhuanlan.zhihu.com/p/566469003
声纹识别:从理论到编程实战
《声纹识别:从理论到编程实战》中文课上线,由谷歌声纹团队负责人王泉博士主讲。目前,课程答疑正在持续更新中。
课程视频内容共 12 小时,着重介绍基于深度学习的声纹识别系统,包括大量学术界与产业界的最新研究成果。
同时课程配有 32 次课后测验、10 次编程练习、10 次大作业,确保课程结束时可以亲自上手从零搭建一个完整的声纹识别系统。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com