DeepMind游戏AI登上Science:雷神之锤多智能体合作,超越人类玩家
机器之心报道
参与:Shooting、杜伟
去年年中,DeepMind 介绍了其在游戏智能体方面的新进展,聚焦于雷神之锤 III 竞技场的夺旗模式。当时,DeepMind 设计的为 FTW 智能,达到了人类水平,能够与其它智能体或人类相互合作。今年,DeepMind 继续发力,提出基于 self-play 的新智能体,该智能体甚至能够超越人类水平。
没有什么游戏的操作原理比夺旗更简单的了(除了抓人或踢罐子游戏)。两队各自在己方的基地中设有标记物,然后争夺对方的标记物并将其安全送回基地。这太简单了!
但是,对于人类很容易就能理解的东西,机器却不能快速掌握。在夺旗游戏中,电脑控制角色通常基于启发式和规则进行编程,在游戏中自由度不高。
不过,AI 和机器学习有望颠覆这种固定的角色设定模式。DeepMind 研究人员在发表于《Nature》的论文(Human-level performance in 3D multiplayer games with population-based reinforcement learning)中介绍了一种系统,这种系统不仅能够在《雷神之锤Ⅲ竞技场》中学习如何夺旗,而且制定了全新的团队游戏策略。
DeepMind 研究科学家 Max Jaderberg 表示:「没有人告诉 AI 如何玩这款游戏——只有在胜利或失败后才知道 AI 是否了解怎么玩游戏。利用 AI 玩游戏的魅力在于你永远不知道智能体会表现出哪些行为」。即,智能体主要依靠自学来打游戏。
他进一步解释道,游戏中起作用的关键技术是强化学习。在 DeepMind 智能体的案例中,它利用奖励机制驱动软件策略实现目标,不管智能体团队是否在游戏中获胜。
论文地址:https://science.sciencemag.org/content/364/6443/859

他说道:「从研究视角来看,真正令人兴奋的是算法的新颖之处。我们训练 AI 的特定方式就很好地展示了如何扩展和实施一些经典的演化观念。」
DeepMind 的 For The Win(FTW)智能体借助卷积神经网络直接根据屏幕上像素学习,该卷积神经网络是一组根据视觉皮层模型分层排列的数学函数(神经元)的集合。
输入的数据传递到两个循环的长短期记忆(LSTM)网络或者能够学习长期依赖性的网络。两个网络分别在快和慢时间尺度上运行,并通过一个变分目标进行耦合,这个变分目标是两个递归网络共同用来预测游戏行为并通过模拟游戏控制器输出动作记忆。
FTW 智能体与 30 个玩家进行训练,这为它们提供了足够多的游戏队友和敌人,同时游戏场地也随机选择,防止智能体形成记忆地图。每个智能体学习各自的奖励信号,使它们能够生成相应的内部目标(如夺旗)。此外,研究人员还利用双层流程来优化智能体的内部奖励机制以及施加于这些奖励的强化学习,从而获得取胜之道。
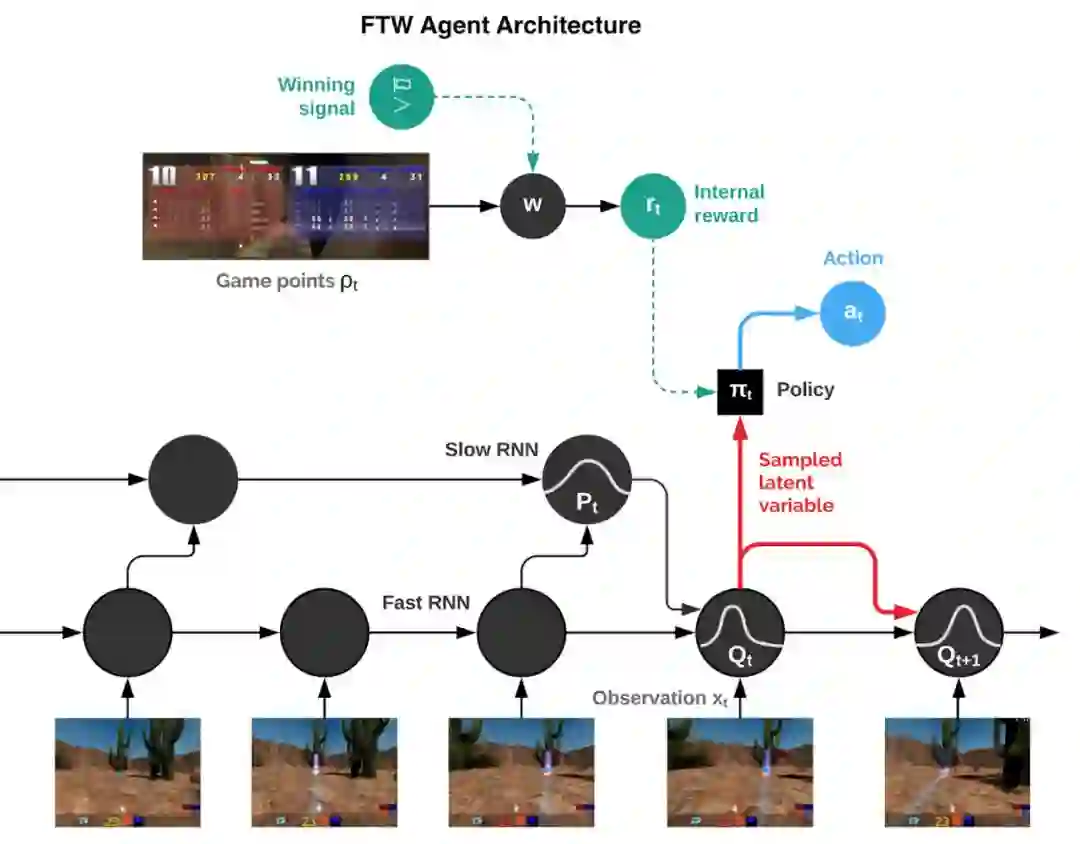
FTW 智能体架构示意图。该智能体在快速和慢速时间尺度上的 RNN 网络,包括共享的记忆模块,并学习从游戏点数到内部奖励的转换。
总之,每个智能体各自参与了 45 万场夺旗游戏,这相当于四年左右的游戏经验。
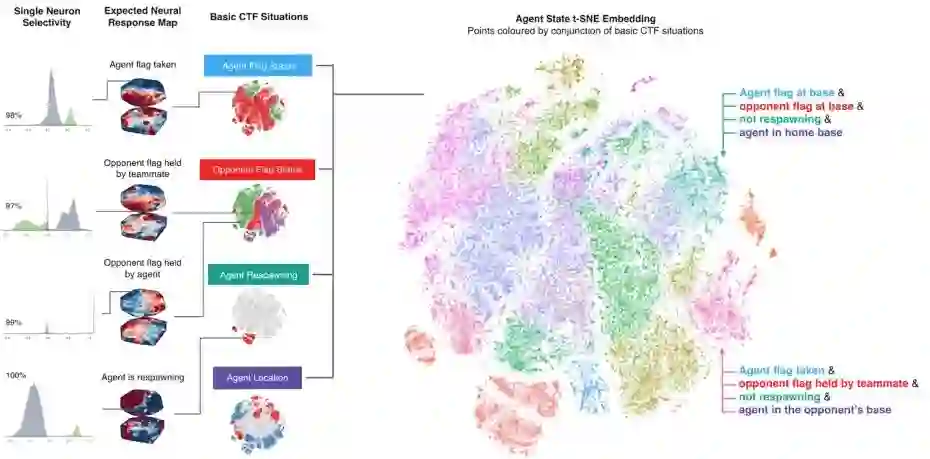
DeepMind AI 系统中的激活图示。图源:DeepMind。
DeepMind 研究科学家 Wojciech Marian Czarnecki 表示:「这是一个非常强大的学习范例,你实际上是在提升性能——从这项研究的成功来看,多智能体的方式实际上让我们的生活变得更轻松了。」Wojciech 曾参与 AlphaStar 的研究。
完全训练好的 FTW 智能体运行在商用 PC 硬件上,它采用了能够泛化至地图、队伍名册和团队规模上的策略。它们学会了人类玩家的行为,比如跟随队友、在敌方的基地扎营以及保护自己的基地免受攻击。随着训练的进行,它们舍弃了那些不太有利的行为(比如紧跟队友)。
所以,智能体最终会怎么样?在一场有 40 个人类玩家参与的比赛中,人类玩家和智能体在游戏中随机配对(既有作为队友的,也有作为敌人的),FTW 智能体比基线方法更熟练。实际上,它们的胜率远远超过了人类玩家。与「厉害」人类玩家的 1300 和普通玩家的 1050 相比,智能体的 Elo(获胜概率)为 1600。
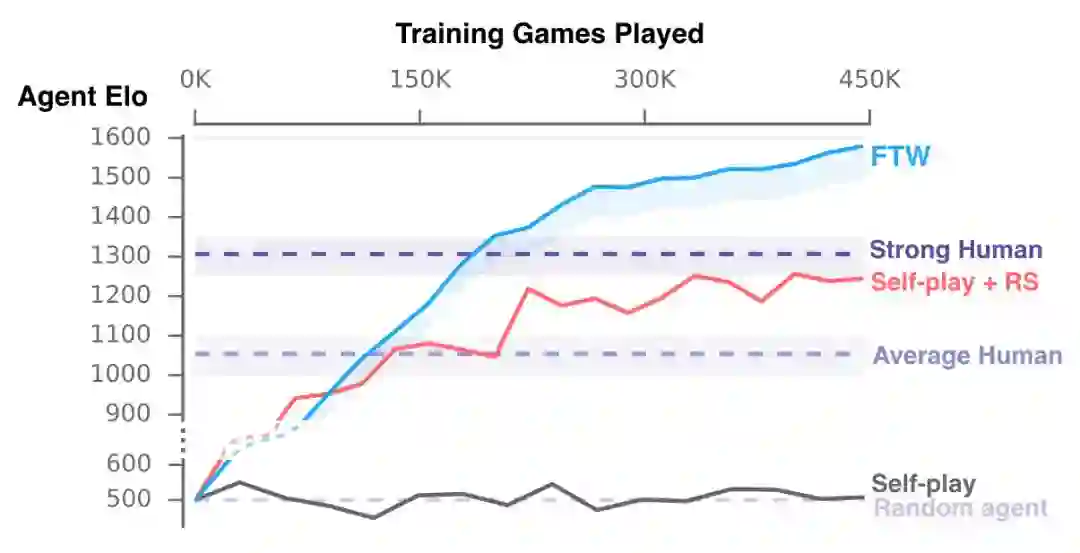
训练期间智能体(新的 self-play 智能体和 FTW 智能体)的表现。
出人意料的是,智能体的反应时间非常快,这让它们在最初的实验中略占优势。但即使它们的准确率和反应时间因为内置的 1/4 秒(257 毫秒)延迟而有所下降,它们的表现仍然超越了人类玩家。厉害人类玩家和中等水平玩家分别只在 21% 和 12% 的时间里赢过它。

另外,当研究人员在发表论文后将智能体放在《雷神之锤 III 竞技场》同类型游戏中时,智能体开始在测试比赛中挑战人类研究员的技能。当研究人员检查了智能体神经网络的激活模式(即负责定义给定输入数据的输出神经元功能)时,他们发现了代表房间的簇、旗帜状态、队友和敌人的可见性、智能体在或不在敌方基地/己方基地以及游戏中其它「有意义的方面」。
训练好的智能体甚至包含为特殊情况直接编码的神经元,例如当智能体的旗帜被夺走或者其队友夺旗时。「我觉得需要注意的一点是,这些想法、这些多智能体领域非常强大,论文证明了这一点。」Jaderberg 表示:「我觉得这就是我们过去几年里越来越了解的:如何构建强化学习的问题。强化学习在一些新的应用场景中真的很出色。」
DeepMind 科学家和伦敦大学学院计算机科学教授 Thore Graepel 表示,该研究突出了多智能体训练在推动人工智能发展方面的潜力。例如,它可能会为人机交互和(相互补充或协同工作)系统方面的研究提供信息。
「我们的结果显示,多智能体强化学习可以成功地拿下复杂的游戏,甚至让人类玩家觉得智能体比队友更优秀。结果还展示了对智能体训练行为、合作方式、如何表征环境的深入分析。」Thore 表示:「让这些结果看起来非比寻常的一方面是,这些智能体像人类玩家一样,以第一人称视角来感知环境。为了学习如何与队友进行战术配合,这些智能体必须依赖来自游戏结果的反馈——但是没有任何老师教它们怎么做。」

参考内容:https://deepmind.com/blog/capture-the-flag-science/
本文为机器之心报道,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


