作者 | Pallavi Bharadwaj et al
编辑 | 丛末
深度学习的黑盒问题一直以来都是机器学习领域的一大难题,而直接导致这一难题的便是神经网络中除输入层和输出层以外的隐藏层。
隐藏层不直接接受外界的信号,也不直接向外界发送信号,因而如何认识隐藏层内部的工作原理和运行机制,也成为深度学习研究中的一大挑战。
对此,来自西蒙弗雷泽大学的几位学生Pallavi Bharadwaj、Inderpartap Cheema、Najeeb Qazi 以及 Mrinal Gosain 合作写作了一篇文章,不仅指出了了解神经网络隐藏层的重要性,还详尽地介绍了如何可视化神经网络以及隐藏层的过程。
大脑皮层中神经元之间的连接,启发了模仿这些复杂连接的算法的开发。简而言之,可以将神经网络的学习方法理解为类似于新生儿通过一段时间的观察和聆听来学习辨认父母的方式。
一旦神经网络接收到相当大的所需数据集后,该网络就会使用其精确的知识“权重”来证明或识别未知数据样本上的模式。
例如在面部识别的任务中,网络首先分析来自输入层图像的各个像素。在输入层之后,“隐藏层”反复学习识别几何形状和特征,这些几何形状和特征由眼睛、嘴唇、疤痕等特定的特征构成。在最终的输出层中,它根据计算出的概率信息对人脸进行了充分的猜测,并识别该面孔到底是谁。
显然,这些隐藏层在最终将输入分解为有价值的信息方面,起着至关重要的作用。从输入到输出的过程中每一层处理的信息越来越复杂,而且通常而言,隐藏层,顾名思义,这个名词笼罩着神秘的色彩,但是它们是这样吗?
AI 领域流传了一个关于神经网络的故事,以检测坦克为目标来训练神经网络,结果神经网络却学会了检测一天的时间。
美国陆军希望使用神经网络来自动检测伪装的敌方坦克。研究人员用两组数据来训练神经网络,一组是50张坦克伪装在树林中的照片,另一组是50张没有坦克的树林照片。然后,研究人员又拍摄了另外一组100张的照片,并进行了测试。
神经网络将剩余的所有照片都进行了正确的分类。并且分类结果得到成功确认!研究人员将他们的检测方式移交给了五角大楼,五角大楼很快将其退还了,他们抱怨在该神经网络上的测试完全失败。
事实证明,在用于训练的数据集中,伪装坦克的照片是在阴天拍摄的,而平原森林的图像是在晴天拍摄的。神经网络只不过是学会了区分多云和晴天,而不是学会识别伪装的坦克。
无论故事是否真实,它都突出了深度学习中的“数据偏向”这一重要问题,但同时也让一些人认识到,他们只有在得到最终输出的结果后才能知道神经网络正在学习什么。即使结果对于给定的数据而言是正确的,但是更重要的是知道网络是如何给出这些结果的,这就是为什么我们必须要了解隐藏层的工作原理。
我们回到网络的基本构建模块——神经元。神经元的各层构成了复杂、性能最佳的神经网络。但问题是,每个神经元学到了什么?是否可以捕获在任意特定的时间上的网络图像并查看每个神经元的行为?俗话说“一图胜千言”,现阶段所需要的就是可视化。
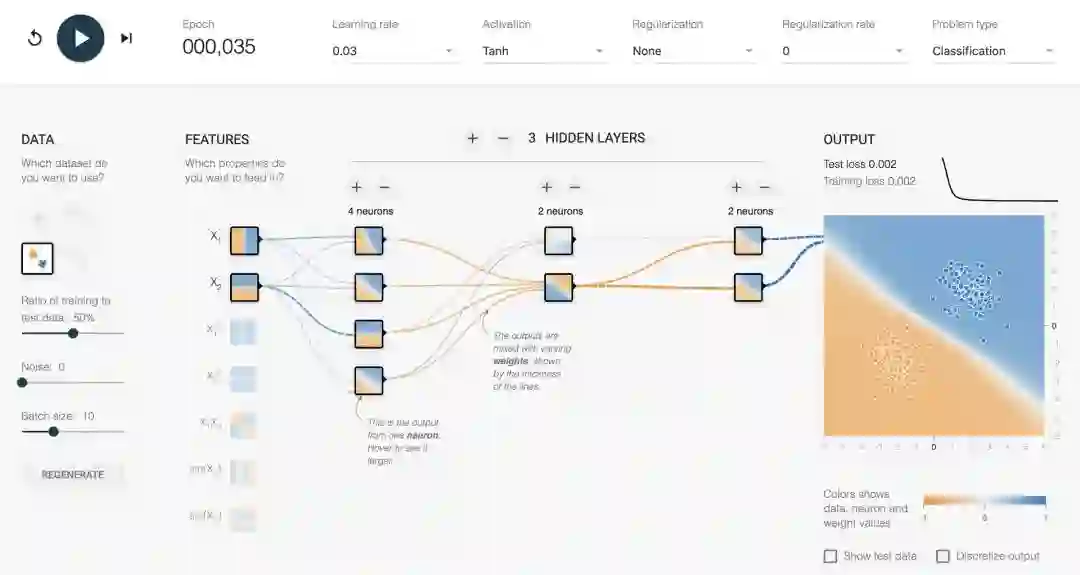
在最近的项目中,Tensorflow.js的合著者之一Daniel Smilkov和谷歌大脑团队的Shan Carter共同创建了一个神经网络训练场( Playground),旨在通过让用户与其进行交互和实验来可视化隐藏层。
The Tensorflow Playground
有趣的是,我们在给机器学习建立更好的模型过程中,得到了关于大脑运作方式的新信息。处理和可视化隐藏层是开始此过程的好方法,同时也让更多的人能够理解深度学习这一概念。
当你对Tensorflow Playground的感受从玩的很开心转换到厌烦时,你就可以加入我们,来学习如何亲自构建可视化。
让我们先来了解下 Keras可视化工具包(Keras-vis),这是一个用于可视化和调试训练过的神经网络的高级开发库。
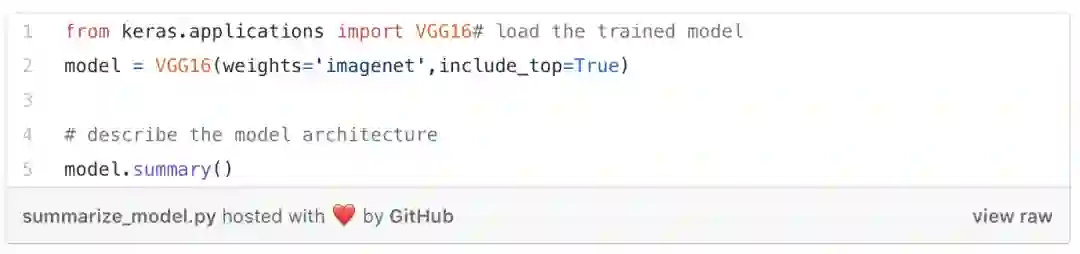
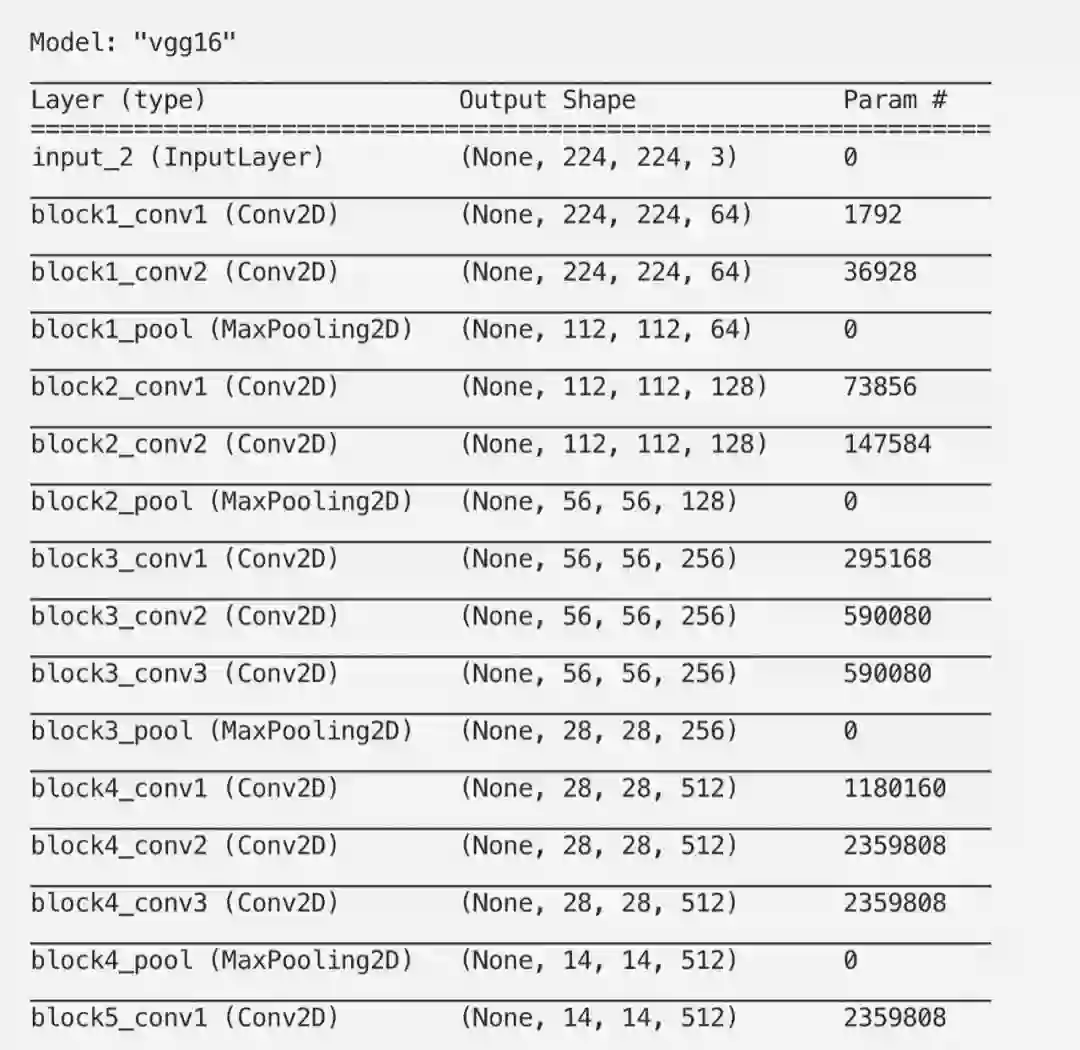
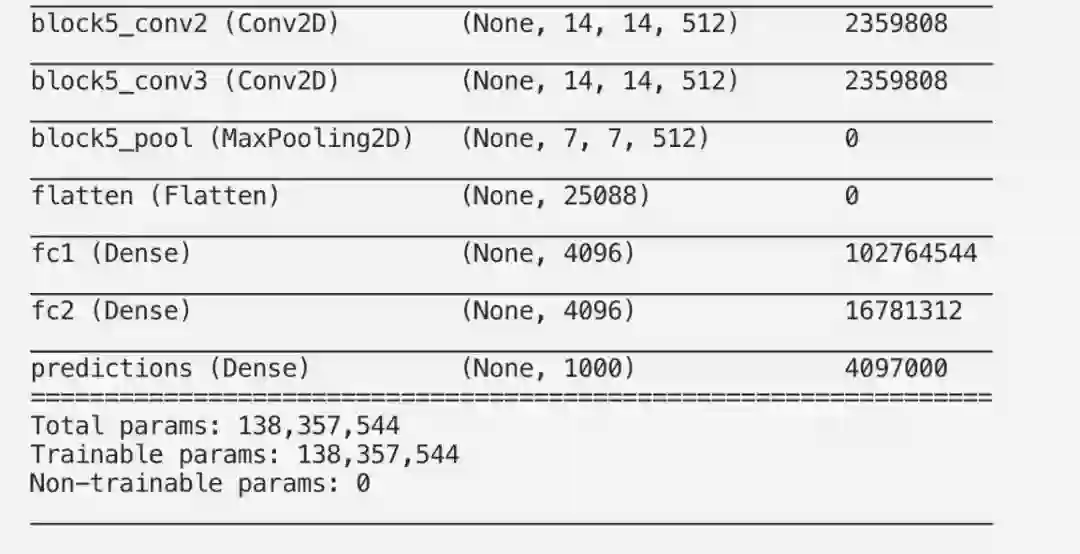
我们使用在ImageNet 数据集的子集上经过训练的VGG16网络的预训练权重,ImageNet 数据集由120万张手工标注的图像组成,属于1/1000的预定义类。
![]()
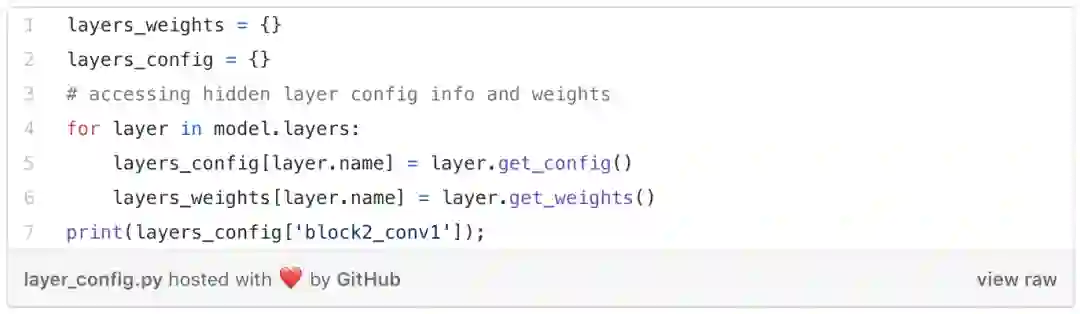
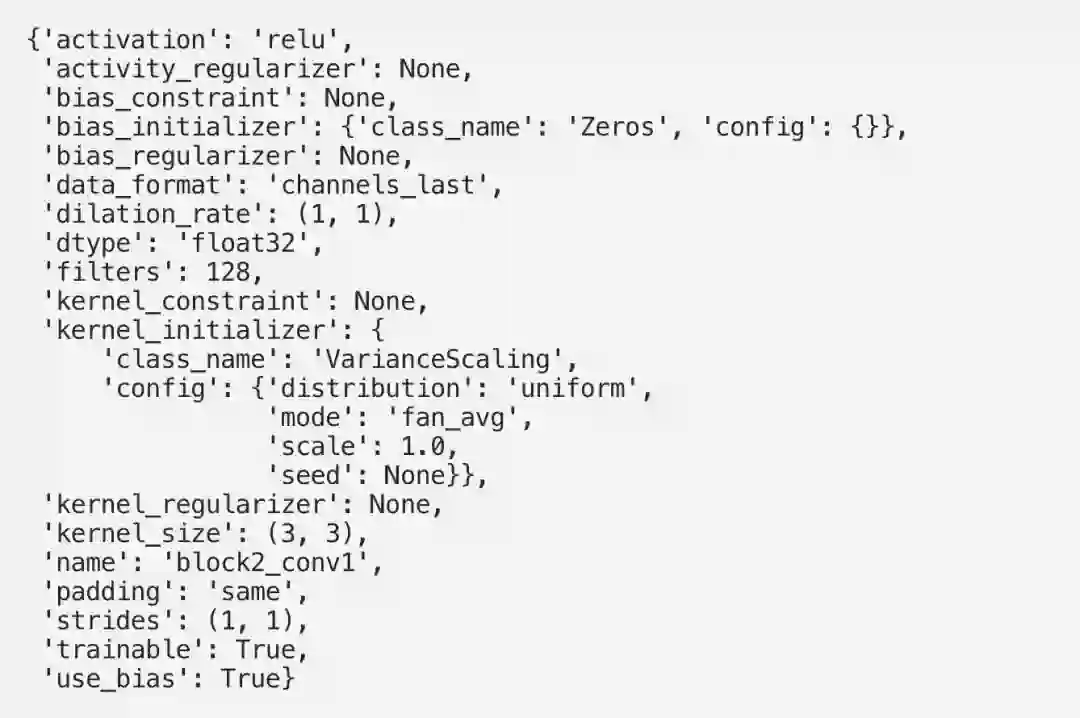
这让我们可以深入地了解使用的层的类型、过滤器大小、可训练的参数等。请注意,由于池化层不可训练,因此该层有0个参数。最大池化层通过选择窗口中的最大值来减小输入的大小,并且此过程不涉及任何权重更新。
如果我们要将一个“图像分类问题”的输出层可视化为一个图像,那么我们需要将输出层的激活函数转换为线性函数而不是softmax函数。了解一种检索与模型各层关联的配置参数和权重的方法,会派上用场。
这为我们提供了一些有价值的信息,例如每一层使用的激活函数,该层是否可训练,过滤器大小,使用了哪种类型的正则器等等。
该实用程序生成的输入可最大化特定过滤器在给定层上的激活值。在这里,我们尝试分析模型将输入的图像分类为黑熊的期望。
作为人类,我们知道熊的共同特征是身躯大,腿长,鼻子长,耳朵小而圆,毛发蓬乱,五个不能伸缩的爪子和短尾巴。
这里,神经网络有多个层次的决定需要做,最后结合这一类别得出结论。我们需要知道这是一张动物的图片,这只动物是熊,然后再根据熊的显著特征将其缩小到熊的种类(极地熊/黑色熊/棕色熊等)。
我们知道黑熊生活在森林里,北极熊生活在多雪的地区。作为人类,即使图像以白色为背景,我们仍然能正确地识别出黑熊的图像。因此一个训练有素的网络应该具备这种跨多层学习的能力。
我们不需要网络区分绿色和白色背景,需要的是它们根据熊的特征来分辨熊的类型。我们都不想重蹈覆辙都市传奇的故事,不是吗?
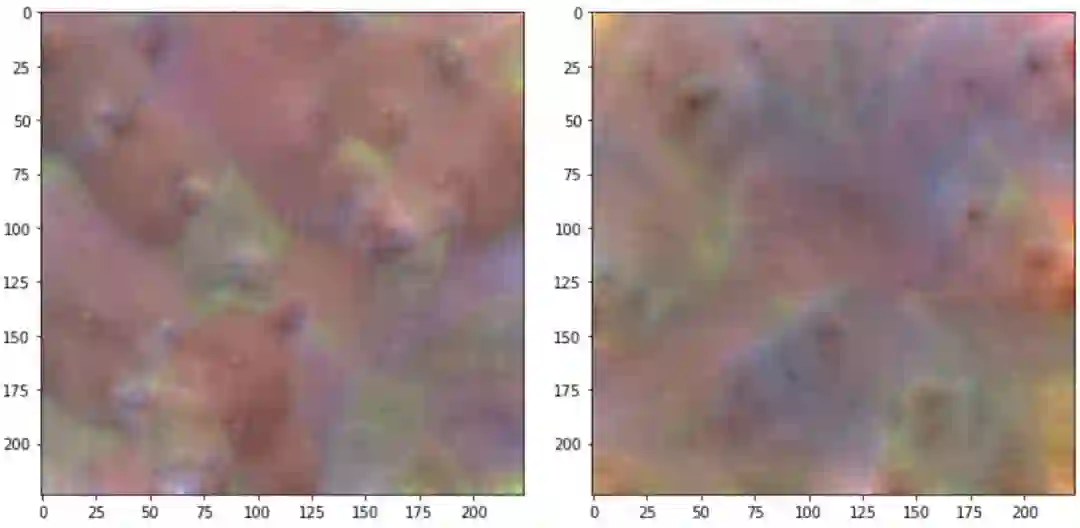
我们尝试将模型期望的输入可视化,并将该输入分类为黑熊。要将一个图像分类为黑熊,我们需要激活输出层的第295个索引,因为该索引与“黑熊”相对应。所以我们通过激活输出层的这个节点来逆向构造一个输入图像。
(输出层的每个节点都对应一类图像。如果要查看ImageNet 数据集的所有类和索引,可以进行以下操作。)
从上图可以看出,在最后一层,模型正在寻找上述提到的熊最重要的特征。在训练过程中,模型也逐步学习各类型特征的微小差异。现在,我们可以确信网络正在学习正确的一系列特征,来识别熊!
您可能想知道每个隐藏层是如何对输出层的最终结果起作用的。对模型进行微调以获得预期的结果,这一点尤为重要。那怎么做呢?了解具体每一层最突出的一系列特征,使我们能够在需要时,使用跳跃连接( Skip Connection)来略过这些特性。
让我们考虑一下前面关于熊分类的例子。现在试着了解网络在整个分类过程中是如何被引导的。我们尝试提取网络的一组隐藏层(block1_conv1、block2_conv1、block3_conv1、block4_conv1)的输出,并在每个层中绘制图像。
要注意的是,初始层正在学习识别形状和边缘等低级特征。这些层了解输入的要点。在随后的图层中,网络会尝试接触越来越多的模糊图案,如腿、耳朵、眼睛、颜色等。这就是为什么我们会说,网络越深,它学得越好。
网络中神秘的隐藏层逐渐捕获了输入的最复杂的特征。
3、显著图(Saliency Map)
图像中的显著性是指图像在视觉处理环境中的独特特征(像素、分辨率)。它们代表了图像中最具视觉吸引力的位置。显著图是它们的地形表示法。这种可视化技术使我们能够认识到每个像素在生成输出过程中的重要性。
论文《 Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps》(《深度卷积网络:可视化图像分类模型和显著图》)最早介绍了这项技术,论文地址:https://arxiv.org/pdf/1312.6034v2.pdf
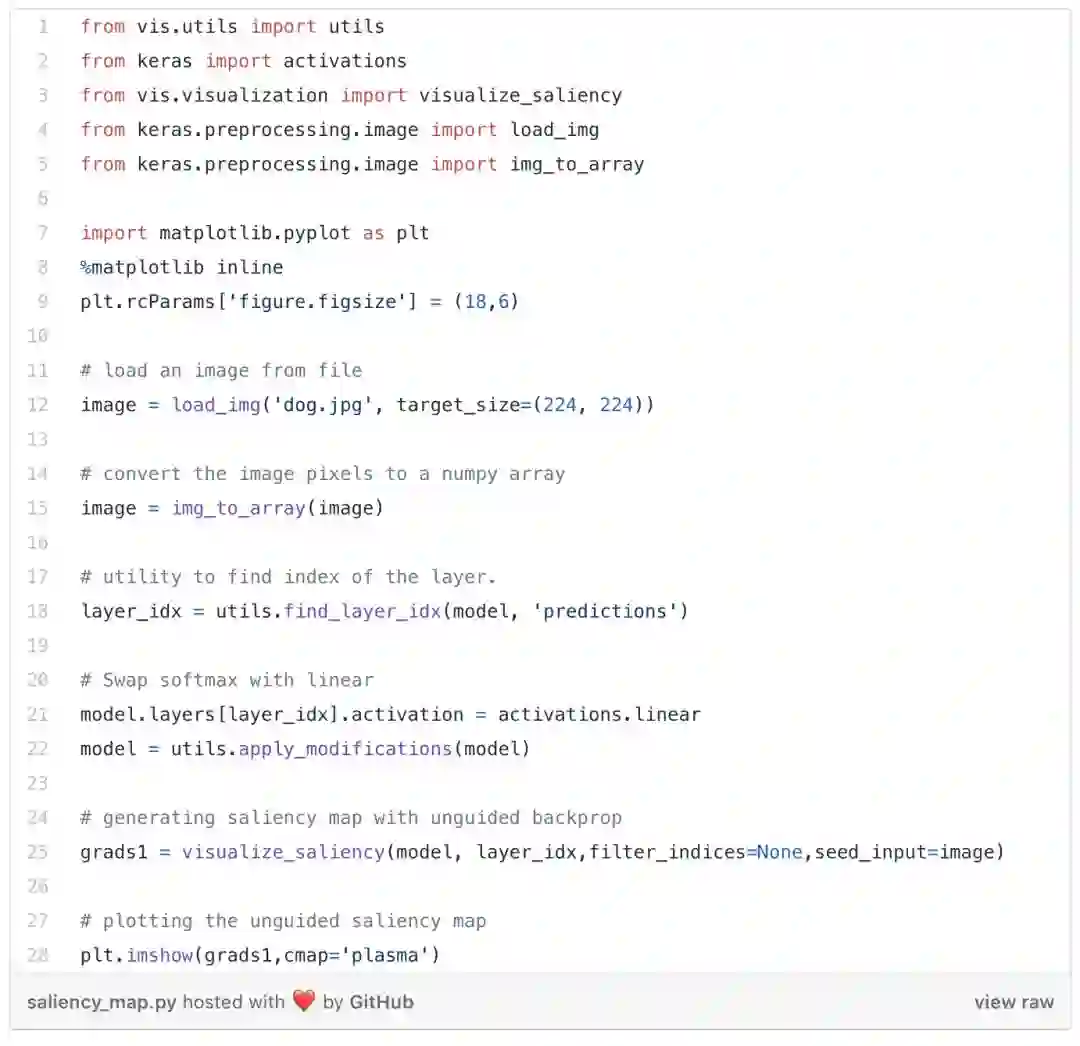
显著图生成激活类的种子输入热力图。让我们以下面这个例子来看看这是什么样的:
你认为上图中,网络应该关注图像的哪一部分?当然是图片中右侧的狗。
网络将忽略图像中的其余图像的像素,将该图像正确地分类为狗的图片。现在,我们如何知道网络是否专注于这一部分呢?这正是显著图发挥重要作用的地方。
显著图计算每个像素对结果的影响。这涉及到计算输入图像上每一个像素的输出梯度。正梯度表示像素值的变化会增加输出值。
正如我们上面所讨论的,这个模型把焦点放在了图中狗的脸上。由于梯度的大小等于图像的大小(在每一个像素计算出来的),因此提供了一种只有狗图像的直觉。
显著图有助于发现图像的独特特征,而遮挡图则有助于找出图像中对模型最重要的部分。
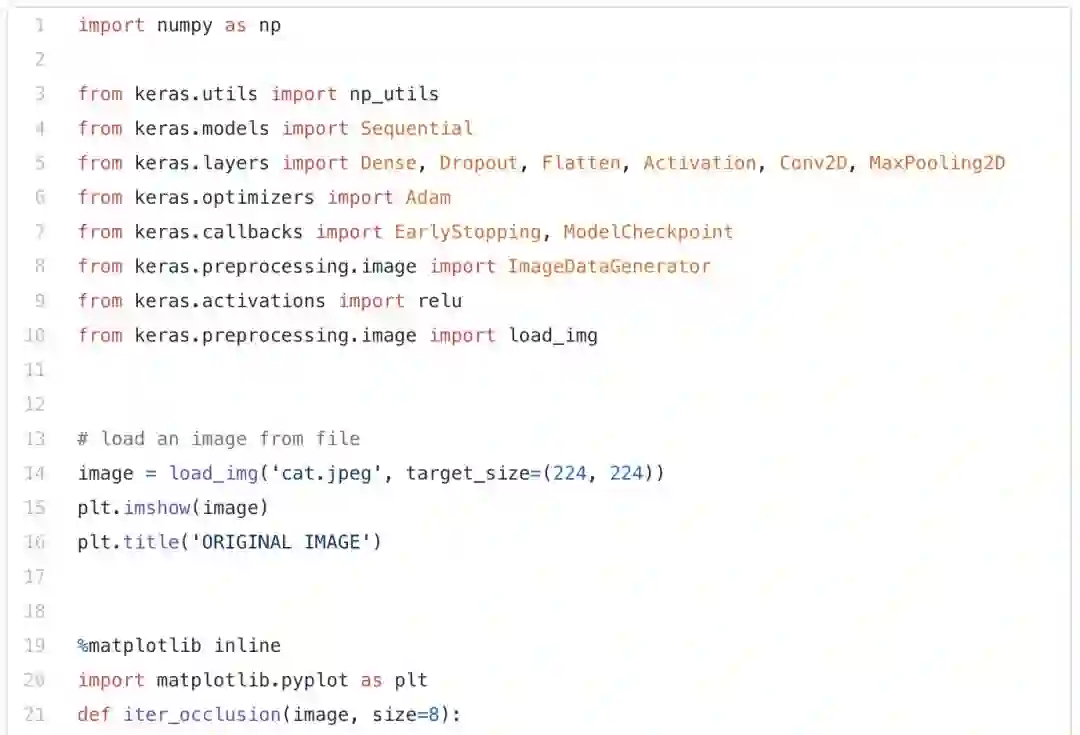
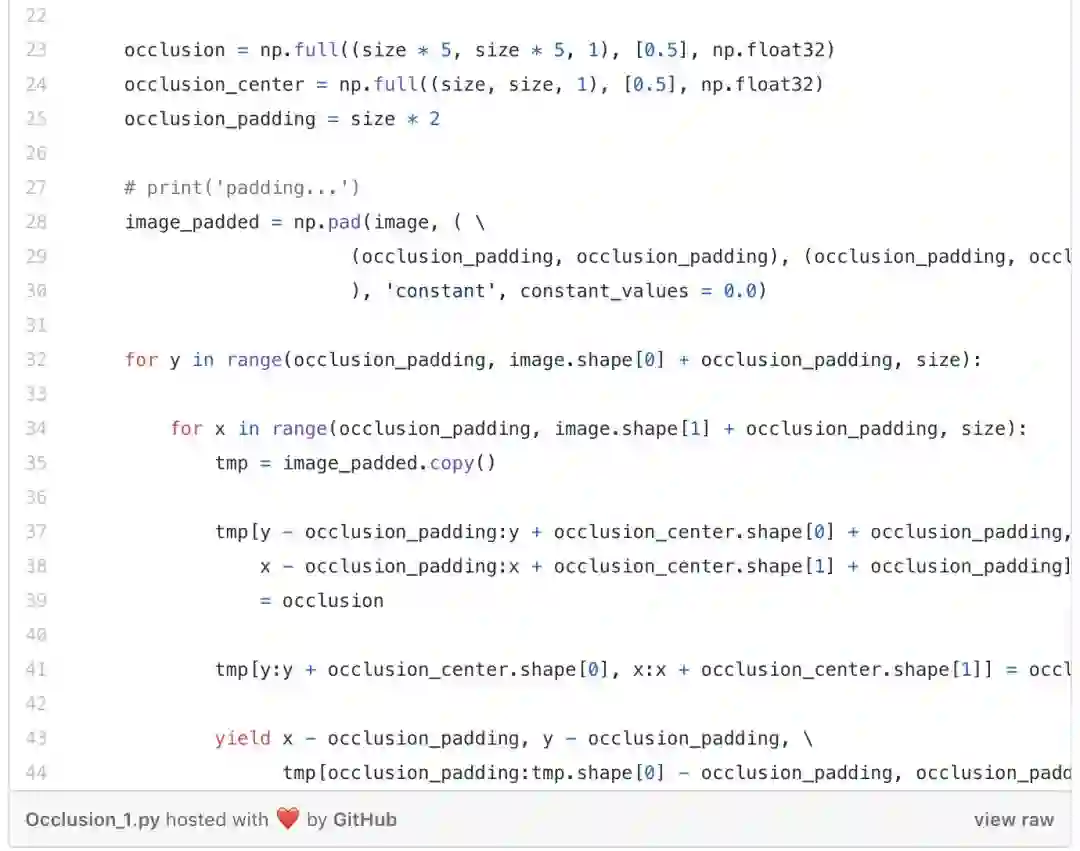
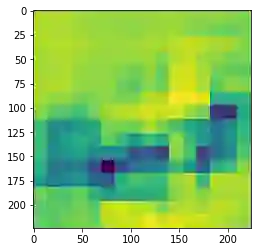
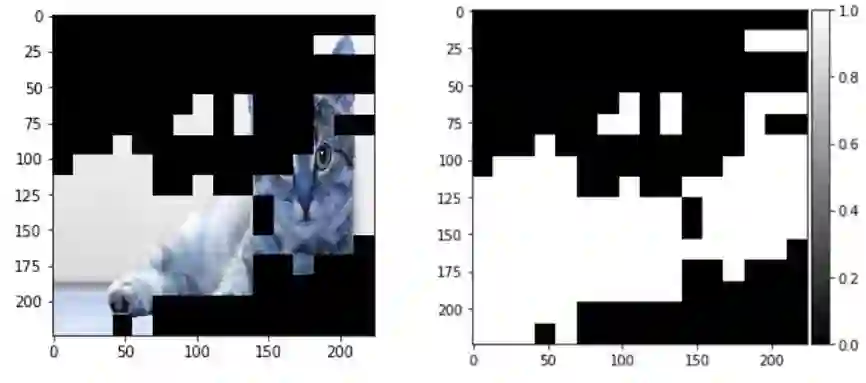
遮挡,在英语中的意思是“隐藏或阻挡”某物。这就是遮挡图的工作原理。图像的某些部分被遮盖或“遮挡”,与此同时计算类的概率。如果概率减少,则图像的这部分很重要,否则就不重要。
通过下图中的这个小怪物的图像可以更好地理解遮挡图:
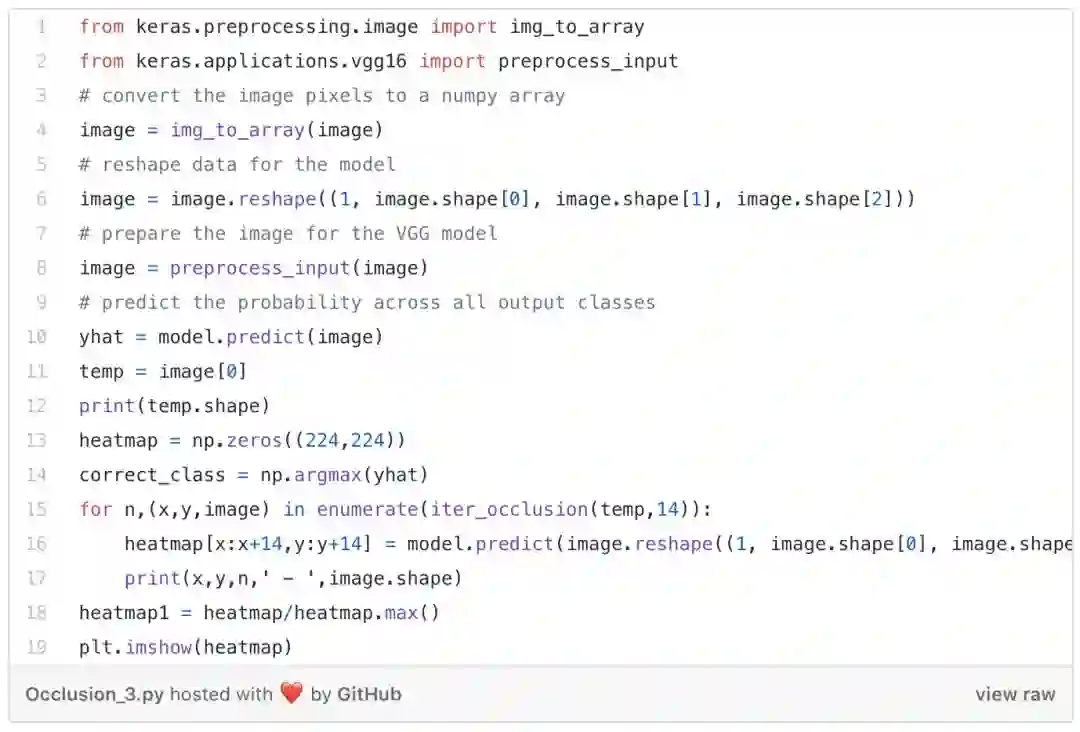
我们首先加载此图像,然后绘制它。下一步是通过掩盖图像的不同部分来生成概率热图。
现在,使用标准化的概率将遮挡图转换成灰度掩码,最后,将其叠加到图像上。
这样我们可以清楚地看到模型进行图像分类的侧重点。这为了解错误分类的原因,提供了更深入的说明。
via https://medium.com/sfu-big-data/unveiling-the-hidden-layers-of-neural-networks-6269615fb8a9
![]()
![]()
![]() 点击“阅读原文” 前往 AAAI 2020 专题
点击“阅读原文” 前往 AAAI 2020 专题