麻省理工 HAN Lab 提出 ProxylessNAS 自动为目标任务和硬件定制高效 CNN 结构
机器之心发布
作者:Han Cai, Ligeng Zhu, Song Han
论文:ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware.
网站:https://hanlab.mit.edu/projects/proxylessNAS/
论文: https://arxiv.org/pdf/1812.00332.pdf
代码:https://github.com/MIT-HAN-LAB/ProxylessNAS
摘要:NAS 受限于其过高的计算资源 (GPU 时间, GPU 内存) 需求,仍然无法在大规模任务 (例如 ImageNet) 上直接进行神经网络结构学习。目前一个普遍的做法是在一个小型的 Proxy 任务上进行网络结构的学习,然后再迁移到目标任务上。这样的 Proxy 包括: (i) 训练极少量轮数; (ii) 在较小的网络下学习一个结构单元 (block),然后通过重复堆叠同样的 block 构建一个大的网络; (iii) 在小数据集 (例如 CIFAR) 上进行搜索。然而,这些在 Proxy 上优化的网络结构在目标任务上并不是最优的。在本文中,我们提出了 ProxylessNAS,第一个在没有任何 Proxy 的情况下直接在 ImageNet 量级的大规模数据集上搜索大设计空间的的 NAS 算法,并首次专门为硬件定制 CNN 架构。我们将模型压缩 (减枝,量化) 的思想与 NAS 进行结合,把 NAS 的计算成本 (GPU 时间, GPU 内存) 降低到与常规训练相同规模,同时保留了丰富的搜索空间,并将神经网络结构的硬件性能 (延时,能耗) 也直接纳入到优化目标中。我们在 CIFAR-10 和 ImageNet 的实验验证了」直接搜索」和「为硬件定制」的有效性。在 CIFAR-10 上,我们的模型仅用 5.7M 参数就达到了 2.08% 的测试误差。对比之前的最优模型 AmoebaNet-B,ProxylessNAS 仅用了六分之一的参数量就达到了更好的结果。在 ImageNet 上,ProxylessNAS 比 MobilenetV2 高了 3.1% 的 Top-1 正确率,并且在 GPU 上比 MobilenetV2 快了 20%。在同等的 top-1 准确率下 (74.5% 以上), ProxylessNAS 的手机实测速度是当今业界标准 MobileNetV2 的 1.8 倍。在用 ProxylessNAS 来为不同硬件定制神经网络结构的同时,我们发现各个平台上搜索到的神经网络在结构上有很大不同。这些发现为之后设计高效 CNN 结构提供新的思路。
背景
近期研究中,神经结构搜索(NAS)已经在各种深度学习任务(例如图像识别)的神经网络结构设计自动化方面取得了很大成功。然而,传统 NAS 算法的计算量需求往往令人望而却步,例如 NASNet 需要 10^4 GPU hours 来运行。以 DARTs 为代表的 Differentiable NAS 虽减少了计算需求,可随着搜索空间线性增长的内存成了新的瓶颈。由于这些局限,之前的 NAS 都利用了 Proxy 任务,例如仅训练少量 Epoch,只学习几个 Block,在较小的数据集上搜索(e.g. CIFAR)再迁移。这些 Proxy 任务上优化的结构,并不一定在目标任务上是最佳的。同时为了实现可转移性,这些方法往往仅搜索少数结构 Block,然后重复堆叠。这限制了块的多样性,并导致性能上的损失。依赖 Proxy 同时也意味着无法在搜索过程中直接权衡延迟等硬件指标。
在这项工作中,我们提出了一个简单而有效的方案来解决上述限制,称为 ProxylessNAS:它直接在目标任务和硬件上学习结构而不依赖于 Proxy。我们还移除了先前 NAS 工作中的重复块的限制:所有 stage 都可以自由的选择最适合的模块。此外,为了直接在目标硬件上学习专用网络结构,在搜索时我们也考虑了硬件指标(例如延迟)。
ProxylessNAS 是第一个在没有任何代理的情况下直接学习大规模数据集(例如 ImageNet)上的 CNN 结构的 NAS 算法,同时仍然允许大的候选集并消除重复块的限制。它有效地扩大了搜索空间,实现了更好的性能。
我们为 NAS 提供了一种新的路径级剪裁视角,显示了 NAS 与模型压缩之间的紧密联系(Han et al。,2016)。我们通过使用路径级二值化将内存消耗节省一个数量级。
我们提出了一种新的基于梯度的方法(作为一个正则函数),来处理硬件目标(例如延迟)。针对不同的硬件平台:CPU / GPU / FPGA / TPU / NPU,ProxylessNAS 实现了针对目标硬件 CNN 结构定制。据我们所知,这是第一个来研究不同硬件结构下的专用神经网络结构的文章。
广泛的实验证明了 Directness 和 Specialization 的优势。它在不同硬件平台(GPU,CPU 和 Mobile)延迟限制下,在 CIFAR-10 和 ImageNet 上实现了最好的性能。我们还分析了专用于不同硬件平台的高效 CNN 模型的偏好,指出不同硬件平台需要不同的神经网络结构。
方法
NAS 的路径级减枝视角
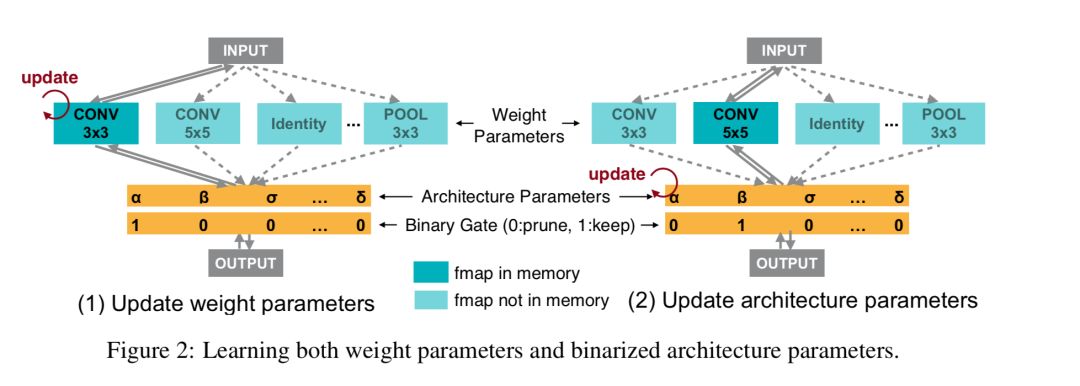
我们将 NAS 建模成一个路径级减枝的过程。如图 2 所示,我们首先构建一个过度参数化网络。这个网络在各个位置不是采用一个确定的操作,而是保留了所有可能的操作。我们引入架构参数来显示地学习各个位置上哪些操作是冗余的,然后通过去除这些冗余的操作,我们就得到了一个轻量的网路结构。如此,我们就只需要在网络结构搜索的过程中,训练这个过度参数化网络即可,而不需要训练成千上万个网络,也不需要使用一个额外的元控制器。
然而,直接去训练这样一个过度参数化网络是有问题的,因为其 GPU 显存会随着候选操作的数量线性增长。这里,我们利用到路径级二值化的思想来解决这个问题: 即将路径上的架构参数二值化,并使得在训练过程中只有一个路径处于激活状态。这样一来 GPU 显存的需求就降到和正常训练一个水平。在训练这些二值化的架构参数的时候,我们采用类似 BinaryConnect 的思想,使用对应的 Binary Gate 的梯度来更新架构参数:
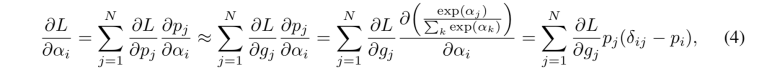
优化不可导的网络结构硬件指标
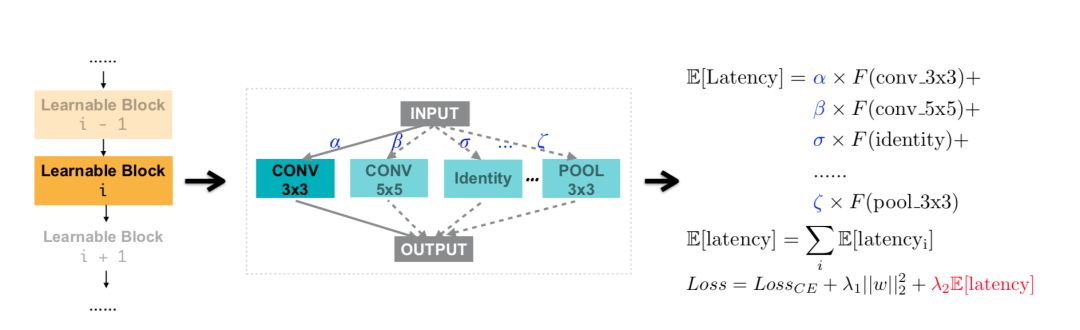
除了准确率之外,在设计高效神经网络结构的时侯,延迟(Latency)是另一个非常重要的目标。与可以使用损失函数的梯度优化的准确率不同,延迟这一指标是不可微的。在本节中,我们提出了两种算法来处理这种不可微分的目标。
如上图所示,我们将网络结构的延迟建模为关于神经网络的连续函数。通过引入一个新的延迟损失,我们可以直接使用梯度来对其进行优化。
此外,作为 BinaryConnect 的替代方案,我们也可以利用 REINFORCE 来训练这些二值化架构参数,这样也能很自然得处理这些不可微分的目标。
结果
我们在 CIFAR-10 和 ImageNet 上进行了实验。不同于之前的 NAS 工作,我们直接在目标数据集上进行神经网络结构学习,为目标硬件(CPU / GPU / Mobile)进行优化,同时允许每一个 block 自由地选择操作。
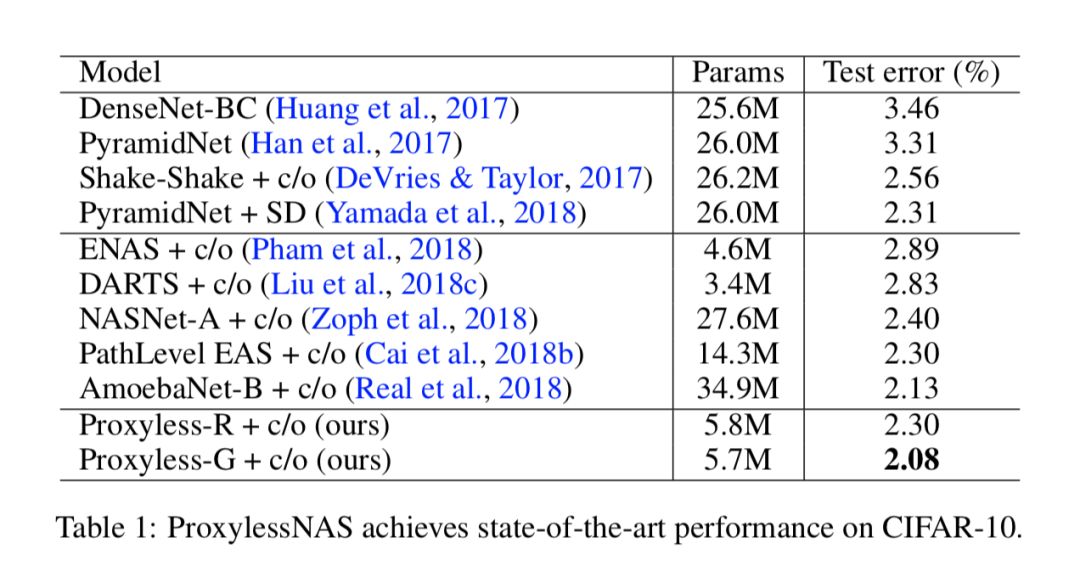
CIFAR-10 上与之前 SOTA(state-of-the-art)模型的对比总结在表 1 中。和他们相比,我们的模型不仅在测试错误率上更低,并且需要的参数量也更少。例如为了达到 2.1% 的错误率,AmoebaNet-B 使用 34.9M 参数,而我们的模型仅使用六分之一 (5.7M 参数)。这些结果证明了直接探索大型搜索空间而不是重复相同块的好处。
在 ImageNet 上,我们主要关注于学习高效的 CNN 结构。因此,这是一个多目标的 NAS 任务,我们需要同时兼顾性能与延迟(不可导的硬件指标)。我们在三种不同的硬件平台上(CPU / GPU / Mobile)进行了实验。实验所用的 CPU 是 2 x 2.40GHz Intel(R)Xeon(R)CPU E5-2640 v4 批大小 1, GPU 是 NVIDIA® Tesla® V100 批大小 8,Mobile 是 Google Pixel 1 单核无量化批大小 1。
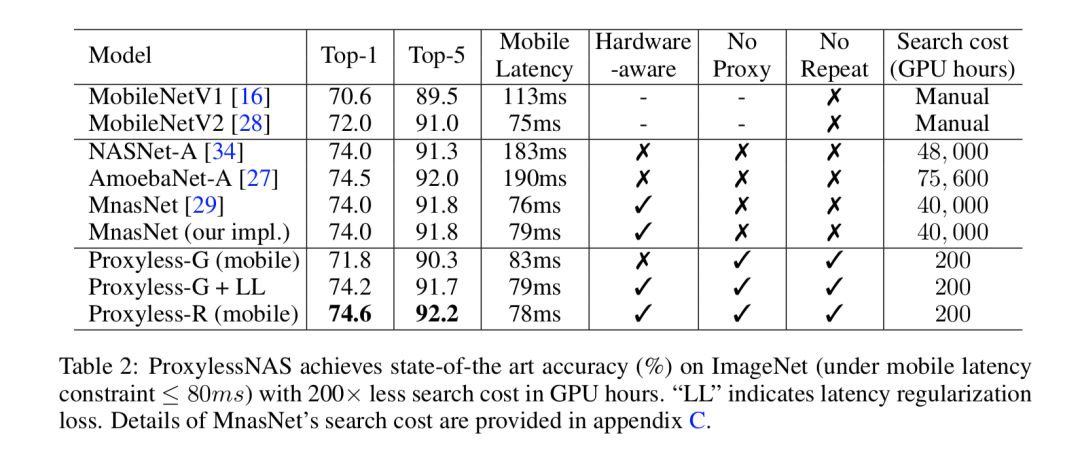
在移动端,与 MobilenetV2 相比,我们的 ProxylessNAS 在维持同等的延迟的前提下,TOP-1 准确率提升了 2.6%。此外,在各个不同的延迟设定下,我们的模型始终大幅优于 MobilenetV2:为了达到 74.6% 的精度,MobilenetV2 需要 143ms 的推理时间,而我们模型仅需要 78ms(1.83x 倍)。与 MnasNet 相比,我们模型在提升 0.6% Top-1 的同时保持略低的推理时间。值得一提的是,我们所消耗的搜索资源要比 Mnas 少得多 (1/200)。
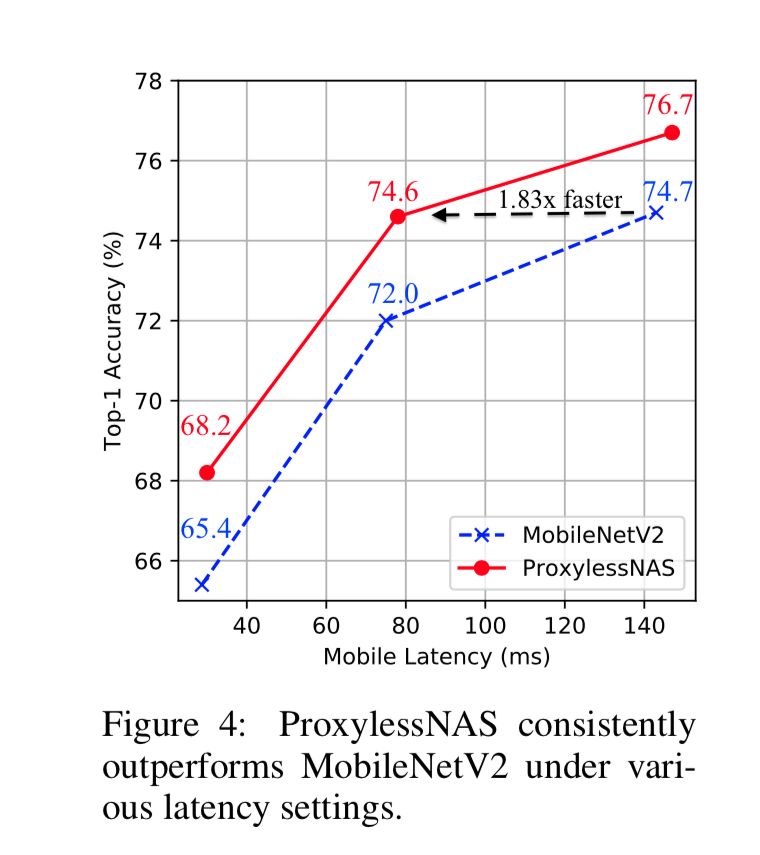
除了移动端,我们还应用 ProxylessNAS 为 CPU 和 GPU 定制 CNN 模型。和之间 SOTA 网络结构相比,ProxylessNAS 依旧表现出了更优的性能:在延迟低 20% 的情况下,ImageNet 上 top-1 准确率相比 MobileNetV2 提升了 3.1%。
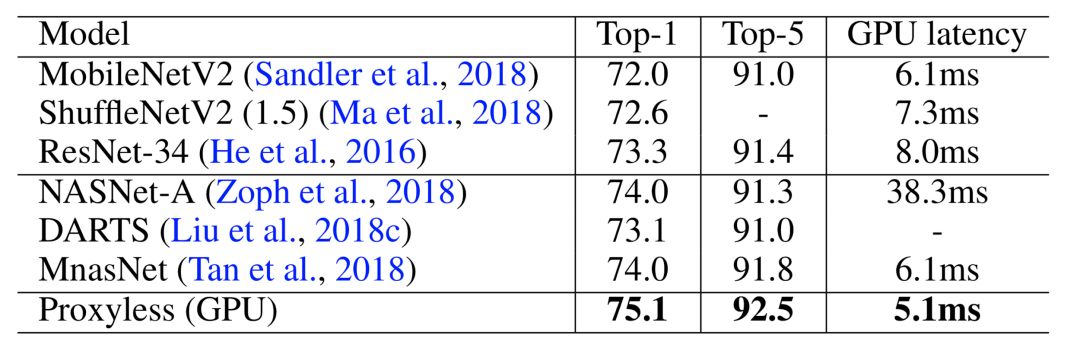
之前人们习惯于将一种同一种网络结构应用到多个平台上,而我们的实验结果表明,我们实际上需要为不同的平台定制神经网络结构:针对 GPU 优化的模型在 CPU 和移动端上运行速度并不快,反之亦然。
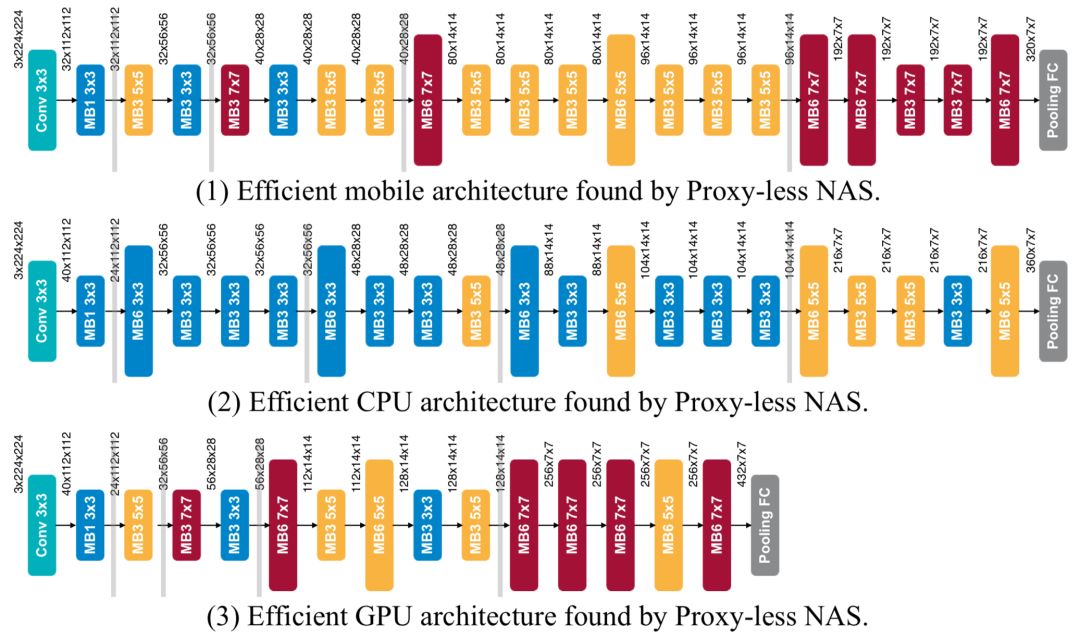
下图展示了我们在三个硬件平台上搜索到的 CNN 模型的详细结构:GPU / CPU / Mobile。我们注意到,当针对不同平台时,网络结构呈现出不同的偏好:(i)GPU 模型短而宽,尤其是在 feature map 较大时;(ii)GPU 模型更喜欢大 MBConv 操作(例如 7x7 MBConv6),而 CPU 模型则倾向于小操作。这是因为 GPU 比 CPU 有更高的并行度,因此它可以更好地利用大 MBConv。另一个有趣的观察是,当特征地图被下采样时,所有的网络结构都倾向于选择一个更大的 MBConv。我们认为这可能是因为大 MBConv 操作有利于网络在下采样时保留更多信息。值得注意的是,这是之前强制 block 之间共享结构的 NAS 方法无法发现的。
PS:我们可视化了,网络结构随着搜索而变化的趋势,视频在下链中。
https://hanlab.mit.edu/files/proxylessNAS/visualization.mp4
NIPS 大会期间,韩松教授将于在 workshop 分享更多本工作的信息,有兴趣的同学 / 老师欢迎前来交流。
12.7 9:30AM @ Room 512 Compact Deep Neural Networks with industrial applications
12.7 4:00PM @ Room 514 Machine Learning on the Phone and other Consumer Devices.
12.8 9:35AM @ Room 510 Machine Learning for Systems workshop
本文为机器之心发布,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com

