选自Github
作者:Jiahui Yu
机器之心编译
参与:Jamin、思
自己的照片有路人甲入镜是常有的事,但有些未免太过抢镜,甚至盖过了主角的风头。P 图高手往往选择自己手动去掉背景里不相干的人,但开发者不想那么麻烦,于是开发了一些项目来一键消掉路人甲。
![]()
项目地址:
https://github.com/JiahuiYu/generative_inpainting
该项目的作者是 Google Brain 的华人研究员 Jiahui Yu,刚刚在 2020 年获得了 University of Illinois at Urbana-Champaign 的 PhD 学位,导师为 Thomas Huang。他本科 2016 年毕业于中国科学技术大学。作者曾在多家 AI 相关公司丰富实习经历,如旷视、Adobe、Snap、百度研究院、微软亚研等。主要的研究方向在于视觉感知,生成模型,序列以及高性能计算。
![]()
该项目因最近引入了 ICCV 2019 Oral 论文《Free-Form Image Inpainting with Gated Convolution》中的方法提升了效果而突然火起来,在GitHub上的star量达到1.5k。这篇论文的一作就是这位华人。
论文链接:https://arxiv.org/pdf/1806.03589.pdf
很多时候,我们对于图像补全的效果都持有怀疑态度,论文上展示的生成效果,或者 Demo 视频演示的效果看起来非常惊艳,但实际我们采用预训练模型时,修复效果并没有那么理想。如下可以先看看理想情况下的修复效果,尤其是第二行,地面上的线条和手推车都有补全。
![]()
作者在项目中提供了交互式 Demo,我们可以自由 Mask 掉图像的某些部分,然后查看它的生成效果。Deepfill v2 一共提供了两个模型,分别在 Places2 和 CelebaHQ 两个数据集上进行了预训练。从效果上看,至少对于这两个数据集,在场景和人脸图像上,它做得还是非常不错的,尤其是人脸的补全效果。
![]()
第一行为真实图像,第二行为抹掉细节的图像,第三行为 DeepFill v2 修复的图像。
后面,我们就要试试自己的图像了,看看模型的泛化能力怎么样。当然,因为预训练模型取自 Places2 和 CelebaHQ 数据集,我们也会找相似的图像进行测试。
作者表示
,该项目的依赖项主要只有三项,即 Python 3、TensorFlow 和他做的一个 TF 工具包 neuralgym。其中作者在 TF 1.3、1.4、1.5、1.6、1.7 版本上都测试,且各种模型超参都放在了 YML 文件中,方便调整。
如果读者有自己的数据集或者想要复现一下,可以具体看看原 GitHub 项目,后面我们将下载预训练模型,并试试它的效果。
python test.py --image examples/places2/case1_input.png --mask examples/places2/case1_mask.png --output examples/places2/case1_output.png --checkpoint_dir model_logs/places2_256
从总体运行情况来看,因为是新建的环境,所以除了项目描述的库外,还需要 OpenCV、PIL 和 YAML 三个包,它们的安装都还简单。我们先运行了一下测试样本,得到的效果确实非常不错,和论文中描述的差不多:
![]()
下面,我们就要试试网上找到的图片,试试模型的泛化效果了:
![]()
因为试了几次,手动构建的 Mask 图像都存在一些问题,因此这里直接用已有的 Mask 图像,试试模型泛化到互联网图片的效果。为了不为难模型,我们找了一张背景稍微简单的图像:
![]()
图像的修复效果还是挺不错的,线条与背景都没多大问题。之前机器之心测试过的图像修复模型,很多都只能在特定数据上有比较好的效果,模型过拟合现象比较明显。而在这个项目中,即使从网上找一张图像,效果也还挺不错。
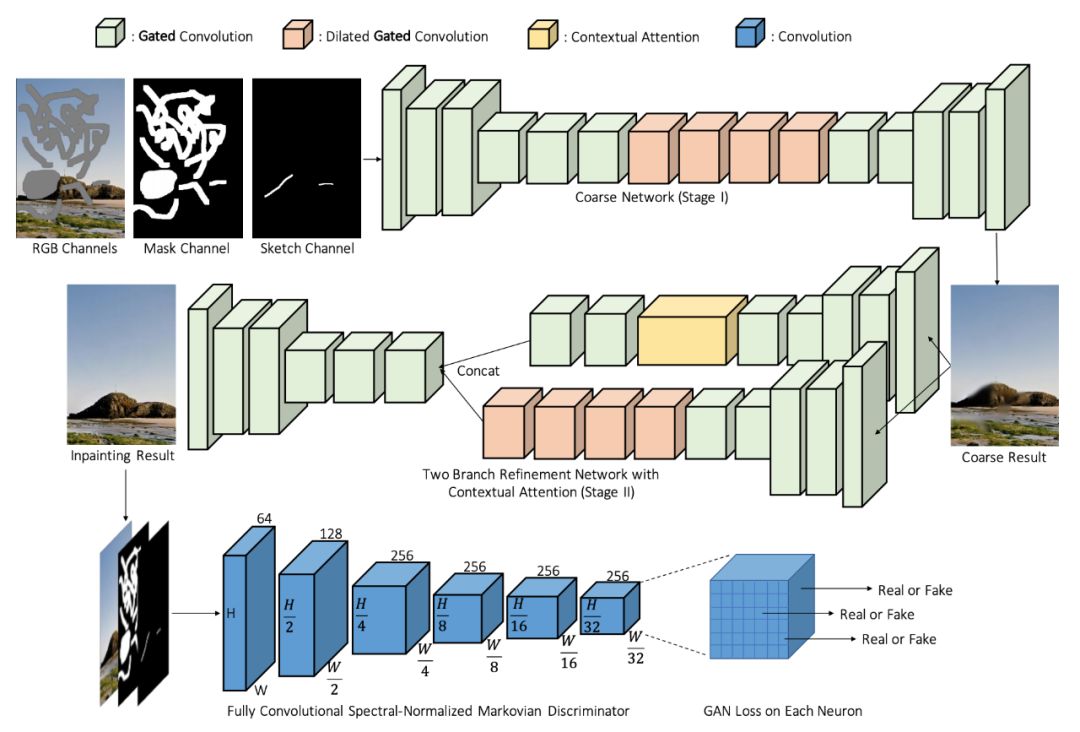
这么优秀的效果,它的论文也非常不错,DeepFill v2 的原论文被 ICCV 2019 接收为 Oral 论文。作者提出了一种新型门控卷积神经网络来修复图像,论文利用了 GAN 生成与判别模式,生成的修复图会经过提炼,并期待能欺骗判别器,令判别器将其判断为「真实修复图」。
![]()
整体模型的主要框架,它能对各种缺损的图像进行修复。
最后,这个 1.5K Star 量的项目,还有论文都值得读者们入手测试测试。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content
@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com