【紫冬分享】网络结构搜索的起源、发展和未来

【今日聚焦】
目前,深度学习广泛地流行,作为深度学习进一步需求的神经网络结构自动化设计也逐渐受到关注。本文将介绍神经网络结构自动搜索中的难点问题以及当前的部分代表性工作。
在深度学习和神经网络还没兴起之前,数据的特征提取方法都是利用人工设计特征提取器,比如,图像领域著名的SIFT[1], SURF[2]等特征。2012年左右,深度神经网络逐步替代了人工设计特征的工作,在图像、语音、文本等领域逐步超越传统方法。研究人员设计了各种性能良好的神经网络结构,从AlexNet[3]、VGG [4]到ResNet [5] 、DenseNet [6] 、Inception [7] 、以及Dual Path Network[8]等等. 这些神经网络不断刷新着很多领域的记录,如图像分类、检测分割、文本生成等等。
然而,深度神经网络的流行也带来了新的问题。良好神经网络的结构通常需要研究者在拥有丰富经验的情况下,不断尝试,消耗大量的人力和计算资源来设计。而这样设计出来的网络结构通常情况下仍然存在着各种各样的问题,比如参数量过大,训练速度慢等等。因此,神经网络结构自动化设计逐渐成为深度学习的进一步需求。
作为一个搜索问题,网络结构自动设计的主流方法可以分为强化学习和进化算法两大类。在强化学习中,网络的结构被抽象成离散的编码,搜索问题转化为连续决策问题,决策器根据上一层的信息选择下一层的结构。对于所构建的网络结构,进一步对其进行训练和测试,将验证集精度作为强化学习的reward来更新决策器。在进化算法中,初始化一群模型,从中挑选较优的模型进行变异,同时将较差的模型删除,不断迭代来产生更好的结构。
本文将介绍神经网络结构自动搜索中的难点问题及当前的部分代表性工作。
神经网络结构自动搜索最早可以追溯到上世纪,即卷积神经网络这一概念刚刚提出的时代。但当时的计算资源连普通的卷积神经网络都满足不了,更别提结构自动搜索了。让该任务再次引起关注的是Google于2017年公开的一篇文章NAS [9],研究者使用800块GPUs,耗时28天,在CIFAR-10上搜索到了一个能够接近人工设计网络中最高精度的网络结构。这篇文章的出现引起了相关领域的轰动,同时也展现了自动网络结构搜索的两个难点:
1. 搜索空间大
不同的深度、宽度、连接方式、卷积类型等等构成的神经网络结构的数量是指数级别的,想从中找到最佳的网络结构如同大海捞针。

图1. Extremely Huge Search Space
2. 单个结构评价难
对于搜索过程中产生的每个网络结构,如何评价其性能好坏,也是一件非常麻烦的事情。同时,面向精准所设计网络性能评价需求,需要把该网络训练到收敛,这也是非常消耗时间和计算资源的。

图2. Time Consuming for a single evaluxtion
1. 针对难点1:搜索空间大
在NASNet[10]中,来自 Google的研究人员提出了一种解决该问题的经典方法,其核心思想是将搜索空间从之前的网络全局,缩小为一个小的模块。类似于ResNet [5]由结构相同的残差模块重复拼接而成,NASNet [10]将搜索到的模块按照指定的数目进行拼接,得到最终的网络结构。该项工作将所需计算资源缩减到500块GPUs,计算时间缩短到4天,并首次在CIFAR-10和ImageNet分类任务上全面超过人工设计的结构。
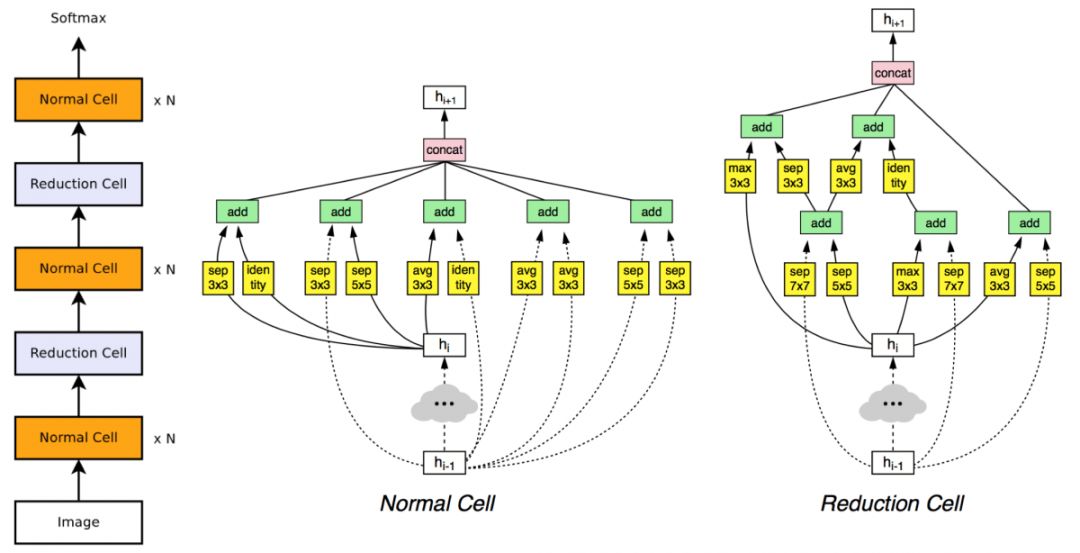
图3. NASNet网络结构
除了Google的NASNet以外,一些其它工作也提出了合理有效的搜索空间。比如,自动化所刘成林研究员课题组和商汤科技联合提出的Block-QNN[11],上海交通大学张伟南教授组提出的EAS[12]等。
2. 针对难点2:单个结构评价难
同样是Google的工作,ENAS[13]利用迁移学习的方法,大大减小了单个模型评价的耗时。在ENAS中,其核心思想是将搜索过程中训练模型得到的参数进行保存,并将这些参数继承给新产生的结构。这一设计原则的优点在于通过finetune来得到一个有关其性能精度的评价,从而避免了重新训练所需要的计算资源和时间。虽然通过finetune得到的精度可能没有常规的训练方法准确,但ENAS [13]仅用了1块GPU,半天的时间,就在CIFAR-10上达到了之前需要几百块GPU才能达到的效果。
3. 新的突破口?基于梯度的方法
几个月前,CMU公布了一篇基于梯度的网络结构搜索算法DARTS[14]。这篇工作跳出了传统的进化算法和强化学习的框架,将神经网络的结构抽象成连续的参数,从而通过梯度下降策略同时优化网络结构和网络参数。该项工作仅采用1块GPU,耗时1.5天,达到了与前人同样的效果。这篇文章的出现引发了很多研究者对这个方向新的思考。DARTS[14]目前ICLR在投,在还未中稿的情况下就已经有了30多次的引用量。
神经网络结构搜索也属于目前被炒的很热的AutoML中的一个重要任务.学术界对该方向较关注。但想要将其转换成为真正实用的技术,还有一系列的问题需要解决:
(1)如何弥补既定设计规则所带来的性能下降:上述的几篇代表性工作看似节约了很多计算资源,但其背后也存在着一定的牺牲。限制搜索空间实际上是加入了过多的人为先验,节约资源的同时也意味着牺牲掉了得到更优结构的可能性。目前有实验表明,NASNet [10]的结构虽然参数量小,但是运算速度和泛化性能比ResNet [5]等传统结构差得多。此外,ENAS [13]提出的参数共享的方法也在很大程度上牺牲了评价指标的准确性。
(2)如何实现神经网络结构设计的任务泛化:神经网络结构搜索这个方向目前进入了和卷积神经网络刚要兴起时一样的状态。人们在不断追求计算资源节约的同时,也带来了很大程度的牺牲和限制。现在还没有完善的方法来进行其它更难的任务上的网络结构搜索,如计算机视觉中的检测分割等.(上个月Google公布的搜索分割网络结构的文章 [15]只是在现有backbone上进行了微调,不是我们理解的网络结构搜索)。大多数检测分割等其它任务的数据集都比分类更难训练,数据量更大,目前的算法很难取得良好的效果。我们不禁要怀疑,到底是算力不够?还是算法不行?
逐步实现自动化的过程是科技发展的大趋势,神经网络结构也不会例外。就像神经网络学习的特征替代手人工设计特征一样,当算力和算法两者之一发展到一定程度时,现有的人工设计的网络结构也将和SIFT [1]一样成为历史。
参考文献
[1] David G. Lowe. Distinctive Image Features from Scale-Invariant Keypoints. IJCV 2004.
[2] Herbert Bay, Tinne Tuytelaars, Luc J. Van Gool. SURF: Speeded Up Robust Features. ECCV 2006.
[3] Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton. ImageNet Classification with Deep Convolutional Neural Networks. NIPS 2012.
[4] Karen Simonyan, Andrew Zisserman. Very Deep Convolutional Networks for Large-Scale Image Recognition. ICLR 2015.
[5] Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun. Deep Residual Learning for Image Recognition. CVPR 2016.
[6] Gao Huang, Zhuang Liu, Laurens van der Maaten, Kilian Q. Weinberger. Densely Connected Convolutional Networks. CVPR 2017.
[7] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, Zbigniew Wojna. Rethinking the Inception Architecture for Computer Vision. CVPR 2016.
[8] Yunpeng Chen, Jianan Li, Huaxin Xiao, Xiaojie Jin, Shuicheng Yan, Jiashi Feng. Dual Path Networks. NIPS 2017.
[9] Barret Zoph, Quoc V. Le. Neural Architecture Search with Reinforcement Learning. CoRR 2016.
[10] Barret Zoph, Vijay Vasudevan, Jonathon Shlens, Quoc V. Le. Learning Transferable Architectures for Scalable Image Recognition. CVPR 2018.
[11] Zhao Zhong, Junjie Yan, Wei Wu, Jing Shao, Cheng Lin Liu. Practical Block-wise Neural Network Architecture Generation.CVPR2018
[12] Han Cai, Tianyao Chen, Weinan Zhang, Yong Yu, Jun Wang. Efficient Architecture Search by Network Transformation. AAAI 2018.
[13] Hieu Pham, Melody Y.Guan, Barret Zoph, Quoc V.Le, Jeff Dean. Efficient Neural Architecture Search via Parameters Sharing. 2018.
[14] Hanxiao Liu, Karen Simonyan, Yiming Yang. DARTS: Differentiable Architecture Search. CoRR 2018.
[15] Liang-Chieh Chen, Maxwell D. Collins, Yukun Zhu, George Papandreou, Barret Zoph, Florian Schroff, Hartwig Adam, Jonathon Shlens. Searching for Efficient Multi-Scale Architectures for Dense Image Prediction. CoRR 2018.
Hyperparameter – 超参数(Part 1):大部分深度学习算法都有许多超参数来控制不同方面的算法表现。有些超参数会影响算法运行的时间和存储成本。有些超参数会影响学习到的模型质量,以及在新输入上推断正确结果的能力。

文章为作者独立观点,不代表自动化所立场。
更多精彩内容,欢迎关注
中科院自动化所官方网站:http://www.ia.ac.cn
欢迎后台留言、推荐您感兴趣的话题、内容或资讯,小编恭候您的意见和建议!如需转载或投稿,请后台私信。
作者:陈玉康
审稿:向世明
编排:周芳旭
编辑:鲁宁


中科院自动化研究所
微信:casia1956
欢迎搭乘自动化所AI旗舰号!

