![]()
「今天我保守报一个 30% 以上的性能提升,很保守。未来这个技术会再次大幅刷新人们对远场语音的认知。我自己的判断是,三年以内远场语音技术的识别率将达到近场识别率,因为有了这个技术,远场识别问题基本可以得到解决,这是一个很大的跨学科创新。」
讲起百度最近在语音技术上的一项技术突破,百度语音首席架构师贾磊变得激昂澎湃起来。
对于贾磊,大家不会陌生,他是互联网圈子里首位(也是目前唯一一位)全国劳动模范(2015 年),是一位「每天睁开眼睛就是工作,走路坐车都在思考」的人物。
贾磊向记者详细讲述了他们在远场语音交互中的一项新的突破:
基于复数卷积神经网络的语音增强和声学建模一体化端到端建模技术
。(很长的一段话,关键词:复数CNN、端到端、增强和建模一体化)
据贾磊介绍,这项技术颠覆了传统基于数字信号处理的麦克阵列算法,因为它直接抛弃了数字信号处理学科和语音识别学科的各种先验假设,直接端到端进行一体化建模。相较于传统基于数字信号处理的麦克阵列算法,
错误率降低超过 30%
;而国际上采用类似思路方法的相对错误率降低约为 16%。
我们来看下,30% 的错误率降低,百度是如何做到的。
目前,语音识别技术在高信噪比场景下表现良好,但在低信噪比场景下,往往表现不稳定。远场语音识别是一个典型的低信噪比场景。在远场环境下,目标声源距离拾音器较远,就会使目标信号衰减严重,加之环境嘈杂,干扰信号众多,最终导致信噪比较低,语音识别性能较差。用户站在 3 米甚至 5 米远处与智能音箱进行语音交互就是一个典型的远场语音识别应用场景。
![]()
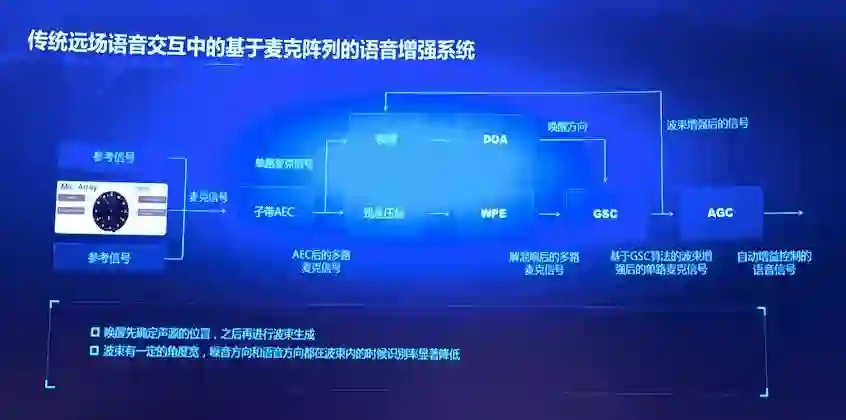
传统上,为了提升远场语音识别的准确率,一般会使用麦克风阵列作为拾音器。利用多通道语音信号处理技术,增强目标信号,提升语音识别精度。
目前,绝大多数在售的智能音箱产品系统所采用的多通道语音识别系统,都是由一个前端增强模块和一个后端语音识别声学建模模块串联而成的:
![]()
前端增强模块通常包括到达方向估计(DOA)和波束生成(BF)。DOA 技术主要用于估计目标声源的方向,BF 技术则利用目标声源的方位信息,增强目标信号,抑制干扰信号。
后端语音识别声学建模模块,会对这一路增强后的语音信号进行深度学习建模。这个建模过程完全类似于手机上的近场语音识别的建模过程,只不过输入建模过程的信号不是手机麦克风采集的一路近场信号,而是用基于麦克阵列数字信号处理技术增强后的一路增强信号。
近些年,前端语音增强技术也逐渐开始用深度学习来做到达方向估计(DOA)和波束生成(BF),不少论文中和产品中也都提到了用深度学习技术来替代麦克阵列系统中的传统数字信号处理技术,也获得了一些提升。
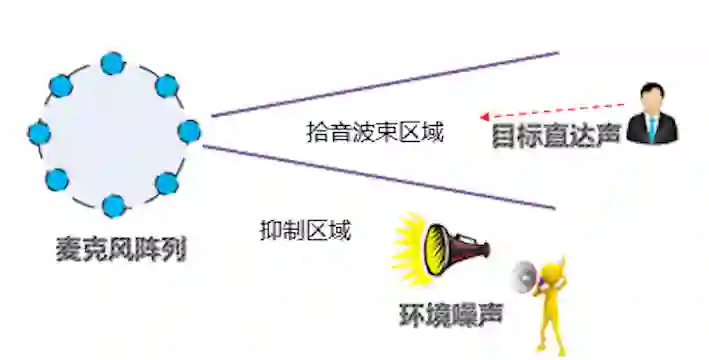
1)波束区域拾音方法有局限性。
上面这一类语音增强技术大都是采用基于 MSE 的优化准则,从听觉感知上使得波束内语音更加清晰,波束外的背景噪音更小。但是听觉感知和识别率并不完全一致。而且这种方法在噪音内容也是语音内容的时候(例如电视和人在同一个方向时),性能会急剧下降。
2)增强和识别模块优化目标不一致。
前端语音增强模块的优化过程独立于后端识别模块。该优化目标与后端识别系统的最终目标不一致。目标的不统一很可能导致前端增强模块的优化结果在最终目标上并非最优。
3)真实产品环境复杂,传统方法会影响使用体验。
由于真实产品场合,声源环境复杂,因此大多数产品都是先由 DOA 确定出声源方向后,再在该方向使用波束生成形成波束,对波束内的信号的信噪比进行提升,同时抑制波束外的噪音的干扰。这样的机制使得整个系统的工作效果都严重依赖于声源定位的准确性。同时用户第一次说唤醒词或者是语音指令的时候,第一次的语音很难准确利用波束信息(例如你说完一句话后,换到了别的方位),影响了首次唤醒率和首句识别率。
2017 年谷歌团队最早提出采用神经网络来解决前端语音增强和语音声学建模的一体化建模问题。
![]()
文章从信号处理的 Filter-and-Sum 方法出发,首先推导出时域上的模型结构,然后进一步推导出频域上的模型结构 FCLP(Factored Complex Linear Projection),相比时域模型而言大幅降低了计算量。
该结构先后通过空间滤波和频域滤波,从多通道语音中抽取出多个方向的特征,然后将特征送给后端识别模型,最终实现网络的联合优化。
谷歌提出的 FCLP 结构仍然是以信号处理方法为出发点,起源于 delay and sum 滤波器,用一个深度学习网络去模拟和逼近信号波束,因此也会
受限于信号处理方法的一些先验假设
。
比如 FCLP 的最低层没有挖掘频带之间的相关性信息,存在多路麦克信息使用不充分的问题,影响了深度学习建模过程的模型精度。
再比如,beam 的方向(looking direction)数目被定义成 10 个以下,主要是对应于数字信号处理过程的波束空间划分。这种一定要和数字信号处理过程看齐的深度学习模型结构设计,严重影响了深度学习技术在该方向上的发挥和延伸,限制了深度学习模型的模型结构的演变,制约了技术的创新和发展。
最终谷歌学术报告,通过这种方法,相对于传统基于数字信号处理的麦克阵列算法,得到了 16% 的相对错误率降低。
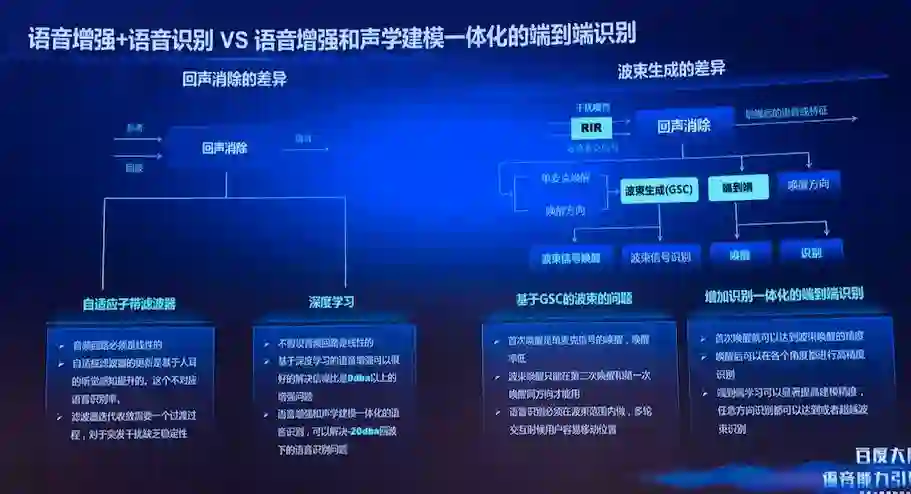
百度采用了类似的思想,即做「语音增强和语音声学建模一体化」的端到端建模,不过他们所采用的是「基于复数的卷积神经网络」。
相比于谷歌的方法,该方法
彻底抛弃了数字信号处理学科的先验知识
,模型结构设计和数字信号处理学科完全脱钩,充分发挥了 CNN 网络的多层结构和多通道特征提提取的优势。
![]()
具体来讲,该模型底部以复数 CNN 为核心,利用复数 CNN 网络挖掘生理信号本质特征的特点。采用复数 CNN,复数全连接层以及 CNN 等多层网络,直接对原始的多通道语音信号进行多尺度多层次的信息抽取,期间充分挖掘频带之间的关联耦合信息。
在保留原始特征相位信息的前提下,这个模型同时实现了前端声源定位、波束形成和增强特征提取。该模型底部 CNN 抽象出来的特征,直接送入端到端的流式多级的截断注意力模型(SMLTA)中,从而实现了从原始多路麦克信号到识别目标文字的端到端一体化建模。
整个网络的优化准则完全依赖于语音识别网络的优化准则来做,完全以识别率提升为目标来做模型参数调优。
贾磊介绍说:「我们的模型能提取生物的信号本质特征,作为对比,Google 的系统是假设两路麦克信号对应频带之间的信息产生关系,这没有挖掘频带之间的信息,这也是 Google 在识别率上偏低的原因。」
![]()
如前面提到,相对于百度智能音箱线上产品所采用的基于传统数字信号处理的前端增强模块和一个后端语音识别声学建模过程串联的方法,这种基于复数卷积神经网络的语音增强和声学建模一体化端到端建模技术,获得了错误率超过 30% 以上的降低。
除此之外,贾磊在演讲中还列举了这种端到端语音识别的 5 个特点:
![]()
这里值得一提的是,目前百度的这种一体化建模方案
已经被集成到百度最新发布的鸿鹄芯片中,该网络所占内存不到200K。
30% 的降低,这也是近期深度学习远场识别技术中,最大幅度的产品性能提升。
贾磊认为,这揭示了「端到端建模」将是远场语音识别产业应用的重要发展方向。
「本质上人类语音交互都是远场。手机麦克风放在嘴边的近场语音交互,只是人们最初在做语音识别时,由于无法解决远场识别问题而做的一个限制。
如果远场语音技术在未来三年成熟以后,所有的语音都是远场唤醒方式,唤醒之后随意连续的输入,任何一个家电设备或者汽车设备,都可以携带语音交互功能,进行本领域的查询。所以这个技术成熟意味着远场语音识别将走进千家万户,在所有我们看到的设备上,都会以远场语音交互为主体,如果再配合芯片的发展,语音识别、语音合成,将一体化地来解决人类终端交互,我觉得是可以期待的。」
当记者问到贾磊博士,相关的技术是否写成论文发表时,贾磊语速匆匆地表示「我太忙了,没有时间写论文。」这可能就是全国劳模的样子吧,忙到没有时间把成果写成论文。
![]()
![]() 点击“阅读原文”查看 “端到端语音识别” 公开课
点击“阅读原文”查看 “端到端语音识别” 公开课