ACL 2019 | 南大NLP,知识库问答中的表示映射学习

作者 | 南大NLP
编辑 | 唐里
本文来自公众号南大NLP,AI科技评论获授权转载,如需转载请联系原公众号。
背景介绍
知识库问答可以通过结构化知识库,对自然语言问题进行准确回答。目前,知识库问答在搜索,对话领域都起着重要的作用。基于神经网络的知识库问答一般可以分为实体链接和关系检测两个子任务。实体链接可以从问句中得到表示问句主体的词语,关系检测可以从候选关系集合中选择正确表达问句语义的关系。本文主要关注于关系检测子任务。

关系检测模型的训练需要一个有标注的问答训练集,可以形式化为 <问句,关系>。我们发现已有的模型大多数只能处理训练集中存在的关系(已登录关系,seen relation),而对于训练集中不存在,但仍然在知识库范围内的关系(未登录关系,unseen relation),已有模型处理能力很弱。这严重的制约了知识库问答的发展。因为对庞大的知识库标注足量的语料用以训练深度学习模型是不现实的。我们还发现,目前广泛使用的知识库问答数据集 SimpleQuestion 中,测试集 99%的关系均在训练集中出现过。这说明已有的数据集不能很好的评估未登录关系检测的性能。
针对未登录关系检测,已有的工作将关系分为词级别表示和全局级别表示。词级别表示指的是将关系拆分为词分别建模;全局级别的表示指的是将关系当做一个记号(token),通过训练集学得其表示。直觉上,词表示可以显著提高未登录关系检测的性能,但是全局级别表示由于是通过训练集学习的,未登录关系的这部分表示仍然是缺失的。
知识库本身可以通过一些无监督的算法学得其中的实体和关系的表示,这其中既包括已登录关系的表示也包括未登录关系的表示。由于预训练任务和特定任务的差异性,利用这些表示一般都会使用先初始化再微调(fine-tune) 的方法。我们认为微调表示纵然可以为已登录关系学得一个好的表示,但是对于潜在的未登录关系反而是有害的。对此,我们提出Adapter来连接通用表示和任务特定表示,并将其整合到目前最好的关系检测模型中。我们也重新组织了 SimpleQuestion 数据集用来更公平的同时评价已登录和未登录关系检测。
解决方案
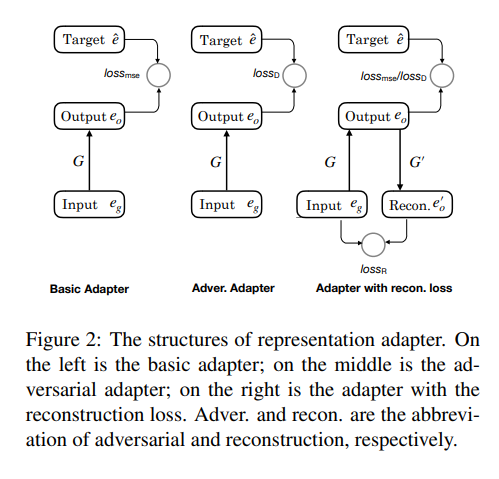
我们的 Adapter 采用一层线性神经网络将关系表示从通用的表示空间,映射到任务特定的表示空间。通用空间的表示通过一些无监督的算法在知识库层面训练得到,任务特定空间具有的表示通过具体的下游任务训练得到。我们提出的 Adapter 与简单增加网络层数不同的一点在于,我们使用特殊设计的损失函数来优化这一映射,而不是简单的将其作为下游任务网络的一部分进行优化,实验部分我们会比较这一点的。损失函数可以使用任何评价两个表示相似程度的指标。对于基本 Adapter(Basic Adapter) 我们使用均方误差来优化这一映射。我们也提出了使用对抗损失来优化 Adapter 的参数。注意到上述两种方法均只能利用已登录关系的表示,而忽视了未登录关系所具有的有效信息,我们增加一个反向 Adapter 将正向 Adapter 得到的表示映射回通用表示空间。
我们在目前的 SOTA 模型 HR-BiLSTM(Yu et al., 2017)的基础上融合 Adapter ,得到下图所示的模型:
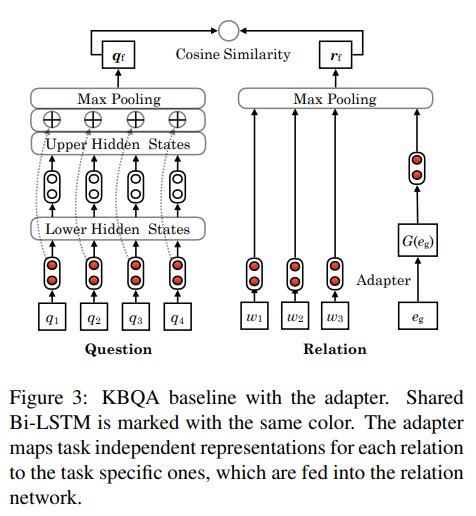
和 (Yu et al.,2017) 类似,我们使用一个问句网络来编码问句,使用关系网络来编码关系,最后使用余弦相似度计算其距离,得到关系检测的结果。与之不同的是,我们在关系的全局表示中加入之前提出的 Adapter,在测试时对于已登录和未登录关系均使用 Adapter 映射后得到的表示。Adapter 的输入我们采用 JointNRE(Han et al., 2018)训练得到的表示,因为他能够将关系和词表示学习到同一空间。
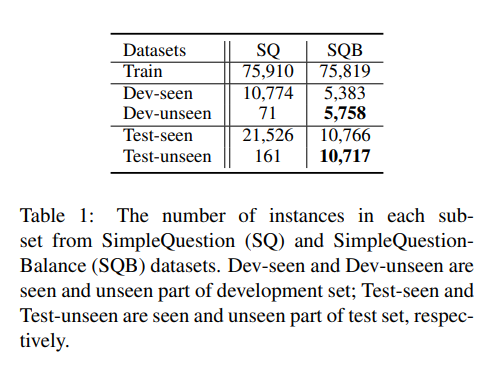
由于 SimpleQuestion 不能很好的评估未登录关系检测,我们重新组织了 SimpleQuestion 的训练,开发,测试集,得到新的数据集 SimpleQuestion-Balance(SQB)。新数据集的开发集和测试集中已登录和未登录关系的比例大致相当。同时,我们也保持了和原有 SimpleQuestion 相同的数据集划分比例。
实验分析
我们的实验在上文提出的SQB数据集,使用微平均(Micro average)和宏平均(Macro average)的精确度(Accuracy) 来分别评价已登录和未登录关系的性能。为了避免偶然性,我们接下来的实验报告了 10 折交叉验证的均值和方差。
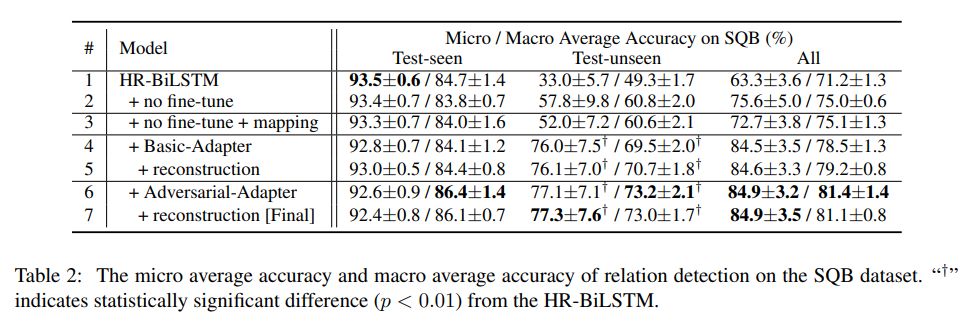
可以看出,基线模型(HR-BiLSTM)在已登录关系上达到很高的性能,但是对于未登录关系模型的检测能力很弱。不微调关系表示(第 2 行)可以初步提升模型对于未登录关系检测的性能,仅仅增加一层线性映射(第 3 行)不能很好的提升未登录关系上的性能。这些结果都验证了我们的动机。
在已登录关系上保持和目前最好的模型相当的性能的同时,使用 Adapter 的模型在未登录关系上都实现了极大的提升。这说明我们提出 Adapter 的有效性,使用对抗和重构损失也获得了不同程度的提升,这证实了其有效性。
我们将提出的关系检测模型融入到 KBQA 的框架里,以此来证实提出的方法可以提高知识库问答的性能。实验结果如下表:
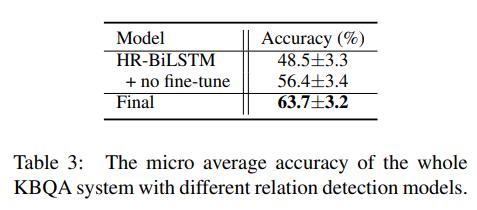
可以看出,我们的模型可以显著的提高知识库问答的精度。和之前的结果对比,我们发现确实是关系检测性能的提升导致知识库问答的提升。
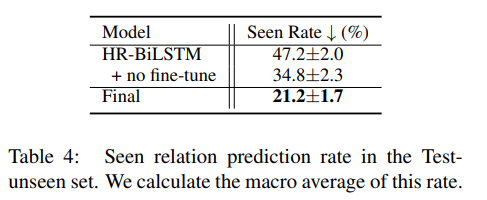
我们也考察了模型对于未登录关系错误的选择已登录关系的比例(seen rate),从下表中可以看出,提出的Adapter 可以减弱模型选择已登录关系的趋势,帮助模型在已登录和未登录关系之间进行公平的选择。
最后我们可视化了JointNRE,HR-BILSTM,和 Adapter 生成的关系表示(下图a,b,c)。可以看出 JointNRE 中已登录和未登录关系分布均匀,而HR-Bilstm 会使得已登录和未登录关系之间存在明显的界限,使用 Adapter 得到的表示可以保留这种均匀的分布。我们也注意到图 a 中有一些关系存在明显的聚集现象,这可能由于训练 JointNRE 时,存在一些未被语料覆盖的关系。对此,我们使用提出的 Adapter 从 TransE 表示映射到 JointNRE 表示,进而得到这部分未登录关系的表示,称其为 JointNRE*,使用这一表示训练的基线模型和 Adapter 则为 HR-BiLSTM*和 Final*。其可视化表示为下图的d,e,f。可以看出JointNRE*得到的关系表示更加均匀。从下表也可以看出,该表示训练得到的 Adapter 可以进一步提高 未登录关系上的性能。


结论
本文我们讨论了知识库问答中未登录关系检测,其核心问题在于未登录关系表示的缺失。我们提出了 Adapter 模型将通用表示映射到任务特定表示上,进而得到未登录关系所应该具有的表示。我们还重新组织了已有的数据集,使之能更好地反映和评价未登录关系检测的性能。实验表明我们提出的方法可以显著提升未登录关系检测的性能。
我们后续将会开源我们的代码和数据集,具体可以关注ACL最终正式版的论文内容。
南大NLP研究组介绍

张钹院士:人工智能的魅力就是它永远在路上 | CCAI 2019

点击“阅读原文” 加入 ACL 顶会交流小组