【强化学习】通过自动强化学习(AutoRL)进行远程机器人导航 | 强化学习系列
仅在美国就有300万人因行动不便而无法离开家门。可以自动长距离导航的服务机器人可以提高行动不便人员的独立性,例如,通过为他们提供杂货,药品和包裹。研究表明,深度强化学习(RL)擅长将原始感官输入映射到动作,例如学习掌握物体和机器人运动,但RL 代理通常缺乏对长距离导航所需的大型物理空间的理解,并且很难适应新的空间。
在最近的三篇论文中,“ 使用AutoRL学习导航行为端到端 ”,“ PRM-RL:通过结合强化学习和基于采样的规划来实现远程机器人导航任务 ”,以及“ 使用PRM进行远程室内导航” RL “,我们通过将深度RL与远程规划相结合来研究易于适应的机器人自治。我们培训当地规划人员执行基本的导航行为,安全地穿越短距离而不会与移动的障碍物发生碰撞。当地规划人员采用嘈杂的传感器观测,例如一维激光雷达提供到障碍物的距离,并输出机器人控制的线性和角速度。我们使用AutoRL训练本地计划员进行模拟,AutoRL是一种自动搜索RL奖励和神经网络架构的方法。尽管它们的范围有限,只有10到15米,但是当地的规划者可以很好地转移到真正的机器人和新的,以前看不见的环境。这使我们能够将它们用作大空间导航的构建块。然后,我们构建路线图,其中节点是位置的图形,只有当本地规划人员能够可靠地模拟真实机器人及其噪声传感器和控制时,边缘才能连接节点。
自动化强化学习(AutoRL)
在我们的第一篇论文中,我们在小型静态环境中培训当地规划人员。然而,使用标准深度RL算法(例如深度确定性策略梯度(DDPG))进行训练会带来一些挑战。例如,当地规划者的真正目标是达到目标,这代表了稀疏的奖励。在实践中,这需要研究人员花费大量时间来迭代和手动调整奖励。研究人员还必须在没有明确接受的最佳实践的情况下对神经网络架构做出决策。最后,像DDPG这样的算法是不稳定的学习者,并且经常表现出灾难性的遗忘。
为了克服这些挑战,我们自动化深度强化学习(RL)培训。AutoRL是一个围绕深度RL的演化自动化层,它使用大规模超参数优化来搜索奖励和神经网络架构。它分两个阶段,奖励搜索和神经网络架构搜索。在奖励搜索期间,AutoRL会在几代人的同时训练一群DDPG代理人,每个人都有一个稍微不同的奖励函数,优化当地规划者的真正目标:到达目的地。在奖励搜索阶段结束时,我们会选择最能引导代理人到达目的地的奖励。在神经网络架构搜索阶段,我们重复这个过程,这次使用选定的奖励并调整网络层,优化累积奖励。
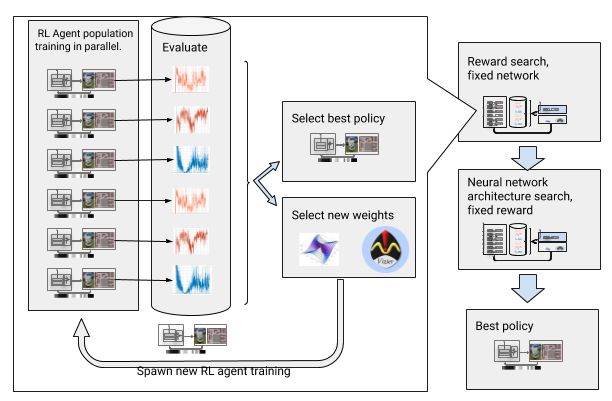
但是,这个迭代过程意味着AutoRL不具有样本效率。培训一名代理人需要500万个样本; 对10代100个代理商进行AutoRL培训需要50亿个样本 - 相当于32年的培训!好处是,在AutoRL之后,手动培训过程是自动化的,DDPG不会遇到灾难性的遗忘。最重要的是,由此产生的政策质量更高 - AutoRL政策对传感器,执行器和本地化噪声具有鲁棒性,并且可以很好地适用于新环境。在我们的测试环境中,我们的最佳策略比其他导航方法成功26%。
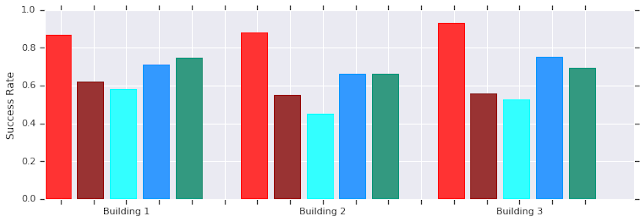
AutoRL(红色)在几个看不见的建筑物中短距离(最多10米)成功。与手动调节的DDPG(深红色),人工势场(浅蓝色),动态窗口法(蓝色)和行为克隆(绿色)相比。
AutoRL本地计划员策略转移到真实的非结构化环境中的机器人(视频1min19s)
虽然这些策略仅执行本地导航,但它们可以很好地移动障碍物并很好地转移到真实机器人,即使在非结构化环境中也是如此。虽然他们只接受静态障碍物的模拟训练,但他们也可以有效地处理移动物体。下一步是将AutoRL政策与基于抽样的计划相结合,以扩大其覆盖范围并实现远程导航。
使用PRM-RL实现远程导航
基于抽样的规划人员通过近似机器人运动来解决远程导航问题。例如,概率路线图(PRM)样本机器人构成并将它们与可行的过渡连接起来,创建路线图,捕捉机器人在大空间中的有效运动。我们的第二篇论文中获得了ICRA 2018的服务机器人技术最佳论文中,我们将PRM与手动调整的基于RL的本地规划人员(不使用AutoRL)相结合,在本地训练机器人,然后将其适应不同的环境。
首先,对于每个机器人,我们在通用模拟训练环境中训练本地计划者策略。接下来,我们在部署环境的平面图上构建一个与该策略相关的PRM,称为PRM-RL。对于我们希望在每个机器人+环境设置中一次在建筑物中部署的任何机器人,可以使用相同的平面图。
为了构建PRM-RL,我们只有在基于RL的本地规划器(它能很好地表示机器人噪声)能够可靠且一致地在它们之间导航时才连接采样节点。这是通过蒙特卡洛完成的模拟。生成的路线图适用于特定机器人的能力和几何形状。具有相同几何形状但不同传感器和执行器的机器人的路线图将具有不同的连接性。由于代理可以在拐角处导航,因此可以包括没有清晰视线的节点。而由于传感器噪声,靠近墙壁和障碍物的节点不太可能连接到路线图中。在执行时,RL代理从路线图航点导航到航路点。
使用每个随机选择的节点对进行3次蒙特卡罗模拟构建路线图。
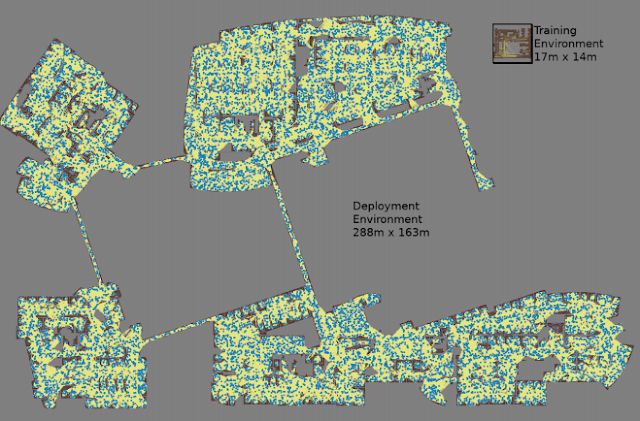
最大的地图是288米乘163米,包含近700,000条边缘,在4天内收集了300名工人,需要11亿次碰撞检查。
在第三个篇文章中,我们对原先的PRM-RL进行了几项改进。首先,我们用经过AutoRL培训的本地规划人员取代手动调整的DDPG,从而改善远程导航。其次,它增加了机器人在执行时使用的同步定位和映射(SLAM)地图,作为构建路线图的来源。由于SLAM地图噪音很大,这一变化弥补了“sim2real gap”,这是机器人技术中的一种现象,模拟训练的代理在转移到真实机器人时表现不佳。我们的模拟成功率与机器人实验相同。最后,我们添加了分布式路线图构建,从而产生了包含多达700,000个节点的超大规模路线图。
我们使用我们的AutoRL代理评估了该方法,使用比训练环境大200倍的办公室楼层地图构建路线图,在20次试验中接受至少90%成功的边缘。我们将PRM-RL与各种不同方法进行了比较,距离可达100米,远远超出了当地的规划范围。PRM-RL的成功率是基线的2到3倍,因为节点已根据机器人的能力进行了适当的连接。
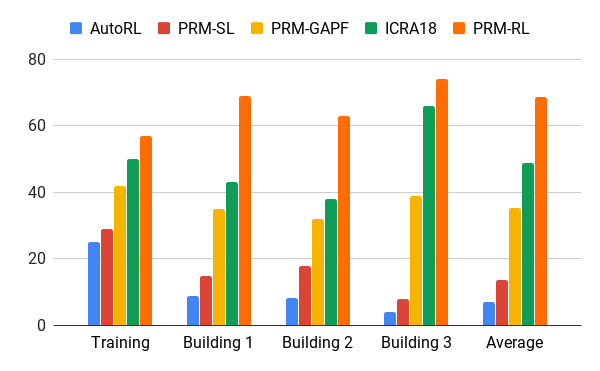
在几座建筑物中导航超过100米的成功率。第一篇论文 --AutoRL仅限本地策划人(蓝色); 原始PRM(红色); 路径引导的人工势场(黄色); 第二篇论文(绿色); 第三篇论文 - 使用AutoRL(橙色)的PRM。
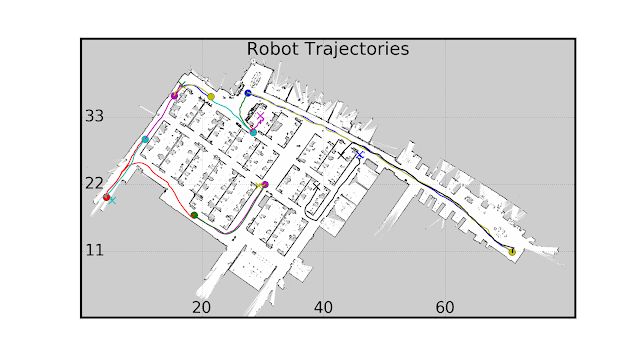
我们在多个真实机器人和真实建筑工地上测试了PRM-RL。一组测试如下所示; 机器人非常强大,除了在凌乱的区域附近和SLAM地图的边缘。
结论
自主机器人导航可以显着提高行动不便人群的独立性。我们可以通过开发易于适应的机器人自治来实现这一目标,包括可以使用已有的信息在新环境中部署的方法。这是通过使用AutoRL自动学习基本的短程导航行为并将这些学习的策略与SLAM地图结合使用来构建路线图来完成的。这些路线图由通过边缘连接的节点组成,机器人可以一致地遍历这些节点。结果是,经过培训的策略可以在不同的环境中使用,并且可以生成针对特定机器人定制的路线图。

工业互联网
产业智能官 AI-CPS
加入知识星球“产业智能研究院”:先进产业OT(工艺+自动化+机器人+新能源+精益)技术和新一代信息IT技术(云计算+大数据+物联网+区块链+人工智能)深度融合,在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的机器智能认知计算系统;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。
版权声明:产业智能官(ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源,涉权烦请联系协商解决,联系、投稿邮箱:erp_vip@hotmail.com。


